1. 背景
之前介绍了如何在 RNN-T 流式模型上应用时延正则,以及在 Conformer 和 LSTM 上的实验结果。
本期公众号重点带大家回顾下具体的思路,以及如何类似地在 CTC 流式模型上应用时延正则。
有些内容可能有所重复,读者可适当跳过。
2. Delay penalty for RNN-T
标准 RNN-T
如图1所示,RNN-T lattice 包含了特征序列和标签序列之间所有可能的对齐路径,两个序列的长度通常不一致。在 lattice 中,从点 (t,u) 出发,向上走的边表示输出 yu+1,分数为 y(t,u);向右走的边表示输出 ∅,分数为 ∅(t,u)。
此处我们提及的 lattice 边上的分数,无特殊说明情况下,都是 log-probability。
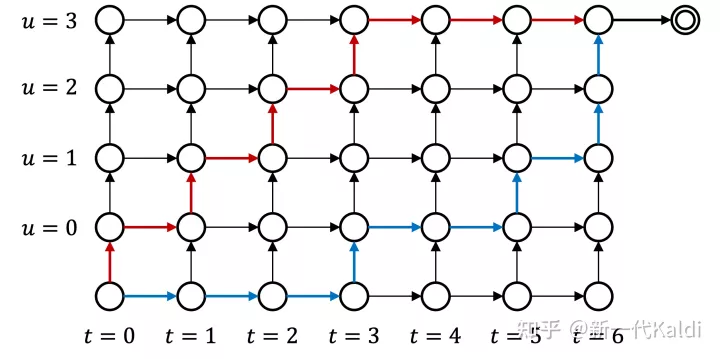
图1
假设 lattice 中路径 i 的 分数为 si,RNN-T 的目标函数 L 为最大化 lattice 中所有路径的分数之和:
L=log∑iexp(si)
我们通常使用动态规划算法 forward-backward[1] 来高效地计算目标函数 L,不需要显式计算每条路径的分数 si。具体地,令 α(t,u) 表示在 lattice 中在看到了特征 x0…t 的条件下,输出标签 y0…u 的分数。我们可以得到状态转移方程:
α(t,u)=LogAdd(α(t,u−1)+y(t,u−1),α(t−1,u)+∅(t−1,u)),
lattice 中所有路径的总分数 L,即状态转移的终点,可以计算为:
L=α(T−1,U)+∅(T−1,U)
我们可以发现,RNN-T 的目标函数 L 并没有考虑不同的路径所对应的时延。如图1所示,红色的路径更早地输出 symbol,时延较低;而蓝色的路径更晚地输出 symbol,时延较高。
与非流式模型不同,流式模型无法看到句子中所有的 context。流式模型为了看到更多的上下文,以达到更好的识别性能,会倾向于增强时延较高的路径, 如图1中蓝色的路径。如图2蓝色线所示,随着训练进行,没有时延正则的 RNN-T 流式模型的时延逐渐上升。
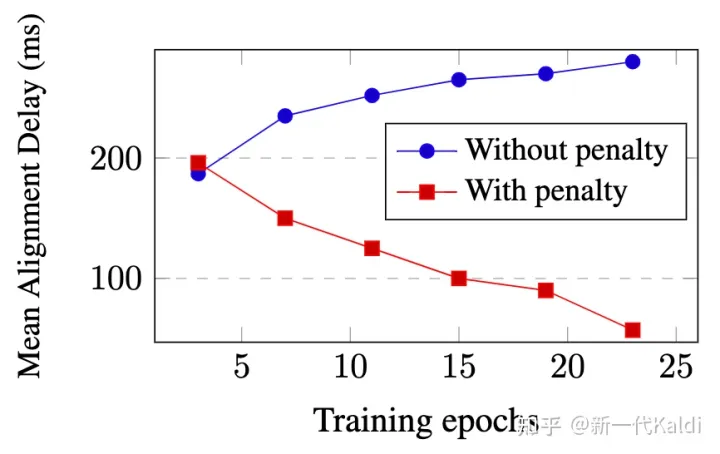
图2
Delay-penalized RNN-T
为了惩罚 RNN-T 模型的时延,我们的想法是在目标函数 L 上增加一个时延正则项 Ldelay,得到一个新的目标函数 Laug:
Laug=L+Ldelay
Ldelay 表示 lattice 中所有路径的平均时延分数(值越大,代表时延越低),定义为:
Ldelay=λ∑idiwi
其中,di 为路径 i 的时延分数,λ 是一个超参数,wi 为路径 i 的分数在整个 lattice 中的比重:
wi=∂L∂si=exp(si)∑iexp(si)
此处,di 的值越大,表示路径 i 的时延越低。
下文会具体讲解时延分数 di 的定义。
因此,通过引入时延正则项 Ldelay,RNN-T 会被约束着去增强那些时延较低(di 较大)的路径 i,为他们赋予一个更高的分数 si。
上文提到,我们在优化 L 的过程中,并没有显式计算各个路径 i 的分数 si。那么问题来了,为了优化 Laug,难道我们还要去显示地求出各个路径 i 的分数 si,来计算 wi 吗?这无疑是一种极其低效且不优雅的做法。
此时,Daniel 抛出了一长串数学公式,证明了我们可以优雅地实现 Laug 的优化。
由于篇幅限制,我们不在此列出具体的证明过程。感兴趣的同学可以阅读论文 https://arxiv.org/pdf/2211.00490.pdf,保证学过高中数学的同学都能看懂。
简而言之,对于一个较小的超参数 λ,带时延正则的目标函数 Laug 对路径分数 si 的导数 ∂Laug∂si 可以近似为:
∂Laug∂si≈exp(λdi+si)∑iexp(λdi+si)
我们只需要在优化标准目标函数 L 的过程中,将 si 替换为 λdi+si,即可达到近似地优化 Laug 的效果:
si′=λdi+si
接下来我们来讲一下在 RNN-T lattice 中如何定义 di。令 π={πu}0U−1 为输出标签序列 y0...U−1 (即向上走的边)的帧索引。我们定义路径 i 的时延分数 di 为这些帧索引 πu 相对于句子中间帧的 offset:
di=∑u(T−12−πu)
此处,之所以要加上它们相对于中间帧的 offset,是为了使得引入时延正则后,loss 函数的数值不会和原来相差太大。
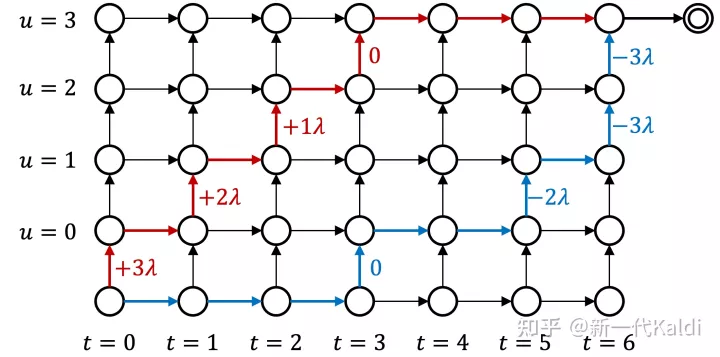
图3
如图3所示,为了实现 si′,我们只需要修改 lattice 中那些输出 symbol 的边(即向上走的边),加上与帧索引对应的 offset:
y′(t,u)=y(t,u)+λ×(T−12−t)
因此,在执行 forward-backward 算法之前,我们只需要将 y(t,u) 替换为 y′(t,u),即可以一种简单高效的方式,近似地优化带时延正则的目标函数 Laug。
如图2中红色的线所示,通过在 RNN-T 目标函数上添加时延正则项,随着训练的进行,我们可以逐步降低流式模型的时延。
代码可以参考 k2 的 PR https://github.com/k2-fsa/k2/pull/976 和 icefall 的 PR https://github.com/k2-fsa/icefall/pull/654。
3. Delay penalty for CTC
CTC 的目标函数[2]和 RNN-T 目标函数的公式一样,也是最大化 lattice 中所有可能的对齐路径分数之和 L:
L=log∑iexp(si)
我们希望可以像 RNN-T 一样,对于 lattice 中每条路径,根据时延对应地修改它的分数 si,即 si′=λdi+si,达到近似地优化带时延正则的目标函数 Laug 的效果。
下面将介绍如何使用 k2 fsa 巧妙地实现这个功能。
大家可以下载文件 https://github.com/k2-fsa/next-gen-kaldi-wechat/blob/master/pdf/LF-MMI-training-and-decoding-in-k2-Part-I.pdf,了解如何用 k2 fsa 实现计算 CTC 目标函数。

图4
假设特征序列的长度为5,标签序列为 Z,O,O。利用 k2 fsa 我们可以得到对应的 CTC lattice。在图4所示,在 CTC lattice 中,每条从起点到终点的路径为:特征序列和标签序列之间的合法对齐路径。每条边上有三个属性:(1)输入标签(label);(2)输出标签( aux_label);(3)分数,即 log_softmax(encoder_output)。
例如,以下三条对齐路径对应着不同的输入标签序列,他们的输出标签序列经过去除 ϵ 后,都可以得到 Z,O,O:
Z,O,∅,O,∅→Z,O,ϵ,O,ϵ
Z,Z,O,∅,O→Z,ϵ,O,ϵ,O
Z,∅,O,∅,O→Z,ϵ,O,ϵ,O
每条对齐路径的时延,取决于那些首次输出 symbol 的边的帧索引 π={πu}0U−1 ,如下面加粗的 symbol:
Z,O,∅,O,∅→Z,O,ϵ,O,ϵ
Z,Z,O,∅,O→Z,ϵ,O,ϵ,O
Z,∅,O,∅,O→Z,ϵ,O,ϵ,O
每条路径中,那些首次输出 symbol 的边的数量是相同的,为标签序列的长度 U。我们可以像上文 RNN-T 一样,定义每个路径 i 的时延分数 di 为:这些帧索引 πu 相对于句子中间帧的 offset。
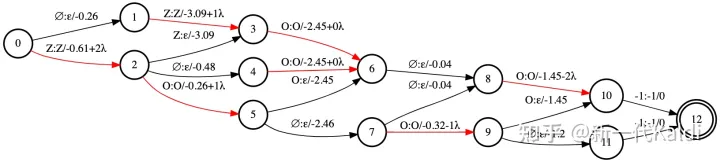
图5
如图5所示,为了在 CTC 中实现 si′,我们只需要修改 lattice 中首次输出 symbol 的边(标记为红色)上的分数 yt,加上与帧索引(相对于中间帧)的 offset:
yt′=yt+λ×(T−12−t)
因此,在执行动态规划算法求 CTC lattice 中所有路径总分数之前,我们只需要将 yt 替换为 yt′,即可以一种简单高效的方式,近似地优化带时延正则的目标函数 Laug。
在 k2-fsa CTC 实现过程中,利用
k2.Fsa.get_total_scores() 求得 lattice 所有路径总分数。
具体地,如何修改 lattice 上那些首次输出 symbol 的边的分数,可以参考 k2 的 PR https://github.com/k2-fsa/k2/pull/1086,和 icefall 的 PR https://github.com/k2-fsa/icefall/pull/669,里面有详细的注释。
4. 实验结果
RNN-T
如表1所示,在使用 RNN-T 训练的流式 Conformer(chunk=0.32s)和 LSTM 模型上,应用时延正则可以有效降低模型的时延。我们只需通过调节超参数 λ,即可控制 WER 和 symbol delay 之间的 trade-off。
关于 RNN-T 时延正则,大家可以阅读论文 https://arxiv.org/pdf/2211.00490.pdf 了解更详细的实验结果。
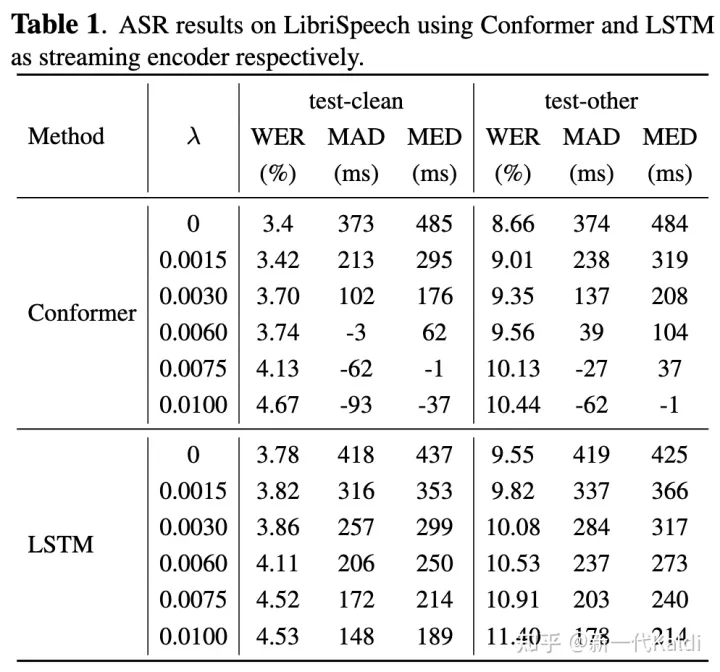
表1
CTC
表2展示了使用 CTC 训练的流式 Conformer 模型 (chunk=0.32s),应用了时延正则后,在 librispeech 数据集 test-clean 和 test-other 上的结果。可以看出,我们同样可以通过调节超参数 λ,即可控制 WER 和 symbol delay 之间的 trade-off。
由于模型只使用了 CTC 损失函数训练了 25 个 epoch,WER 较差,大家可忽略其绝对数值。
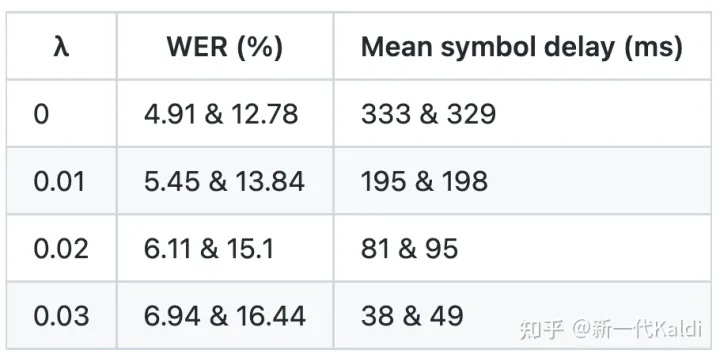
表2
5. 总结
最后,再附上论文地址 https://arxiv.org/pdf/2211.00490.pdf,感兴趣的同学可以阅读 Daniel 的详细证明过程。有疑问的同学欢迎通过 github issue 或者评论区和我们讨论。
参考资料
[1] forward-backward: https://arxiv.org/pdf/1211.3711.pdf
[2] CTC 的目标函数: https://www.cs.toronto.edu/~graves/



![[附源码]计算机毕业设计-菜篮子系统Springboot程序](https://img-blog.csdnimg.cn/f238c89d8253447cba4f5c4ba60f3c4d.png)