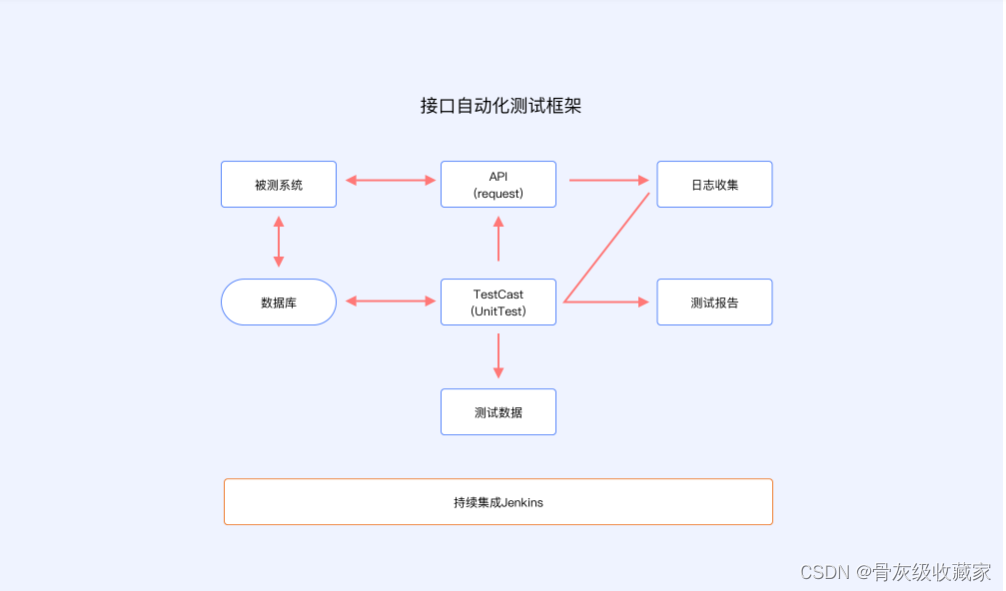
先回顾一下编译知识
将一个程序的编译分为两个大的阶段:编译阶段和链接阶段
编译阶段又分为三个步骤:预编译,编译(此编译和上面程序的编译不是同一个意思… 上面那个是指宽泛的编译)和汇编
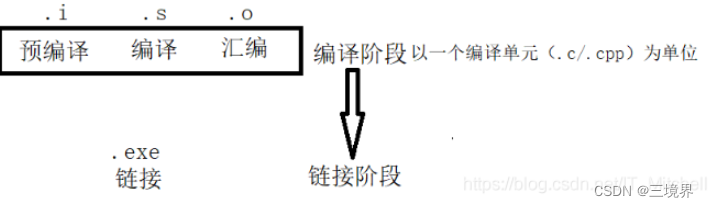
编译阶段经过预编译、编译和汇编处理后生成一个.o文件(以Linux系统为例),编译器编译源代码后生成的文件叫做目标文件。则目标文件就是源代码编译后但未进行链接的那些中间文件(windows下的.obj和Linux下的.o),它跟可执行文件的内容和结构很相似,所以一般和可执行文件采用同一种格式存储。也就是从结构上来说,目标文件是已经编译后的可执行文件,只是没有经过链接阶段,其中有些符号或者地址没有被调整。
详细看看编译阶段和链接阶段具体做了哪些事情:
预编译 --> .i
宏替换(删除#define,并且展开所有的宏定义)
递归展开头文件(处理#include预编译指令,将包含的文件插入到该预编译指令的位置)
删除预编译指令(处理所有的条件预编译指令,例如"#if",“#endif”,“#ifdef”,“dlif”,“#else"的等)
删除注释(删除”//“和”/**/")
添加行号和文件标识
保留#progma
编译 --> .s
词法分析
语法分析
语义分析
代码优化
汇编 --> .o
将代码翻译为二进制指令后生成目标文件,包含编译后的机器指令代码、数据。除了这些内容外,目标文件中还包含了链接时所需要的一些信息,例如符号表、调试信息、字符串等。一般目标文件将这些信息按照不同的属性按“段”的形式进行存储。
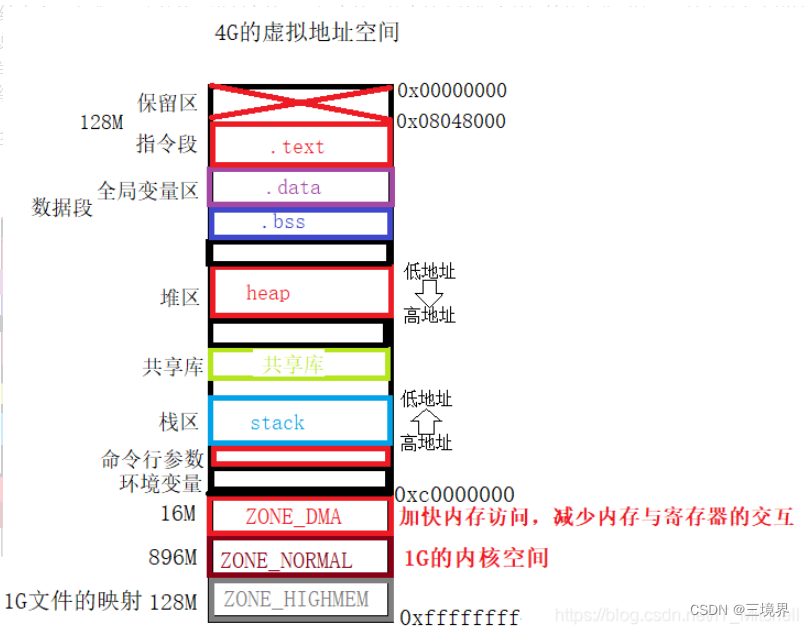
程序源代码编译后的机器指令经常被放在代码段里,即“.text”中。
全局变量和局部静态变量数据经常放在数据段,即".data"中。
未初始化的全局变量和局部静态变量放零初始化段中,即.bss段中。
在编译阶段结束会,生成可重定位的二进制文件即目标文件,将文件中的指令数据等信息分别按照属性存储在虚拟地址空间中(这里是最重要的,存放的起始位置是虚拟地址,所以应用程序开发商无需关心放置地址),数据区域对进程来说是可读写的,而指令段对与进程而言只是可读的,所以这两个区域的权限是可读写和只读。这样就会防止指令被有意无意的篡改,同时当程序运行多个该程序的副本时,它们的指令是相同的,所以内存中只须要保存一份该程序的指令部分。并且分开存储有利于提高CPU的缓存命中率。
还有一些事情没有做:
弱符号位置未进行处理
虚拟地址以及虚拟位移未进行处理
符号表中的外部符号进行处理
链接 --> .exe / .bin
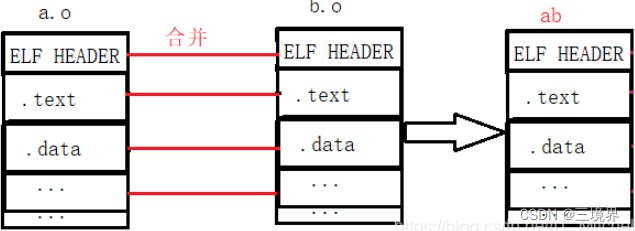
合并段(相同段之间)和符号表
进行符号解析:在符号引用的地方找到符号定义的地方
分配地址和空间
符号的重定位:处理虚假偏移量
符号表和段的合并:将相同性质的段合并到一起
运行
在编译链接阶段结束后,也就是生成了 可执行的二进制文件;但该文件并不能直接进行运行,因为此时的文件并未在内存中,也就是说,操作系统在运行一个程序时,需要指令和数据,并且必须将所要执行的程序加载到内存上;
那么,在运行时,需要做以下的事情:
创建虚拟地址和物理内的映射结构体;按照段页式进行映射,以4K大小对齐;
LOAD加载器,将指令和数据加载到内存中;
将第一行指令的地址写入PC寄存器中;
arm-linux-ld用于将多个文件,库文件链接成可执行文件