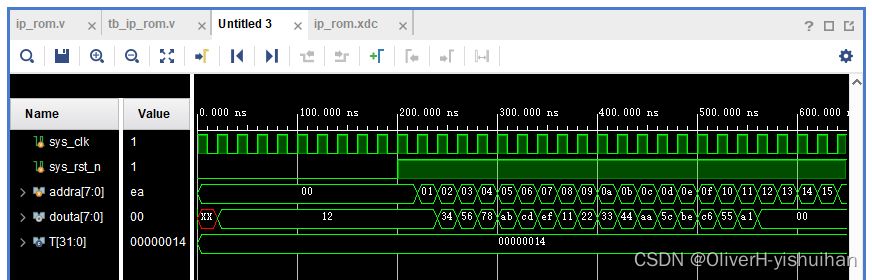
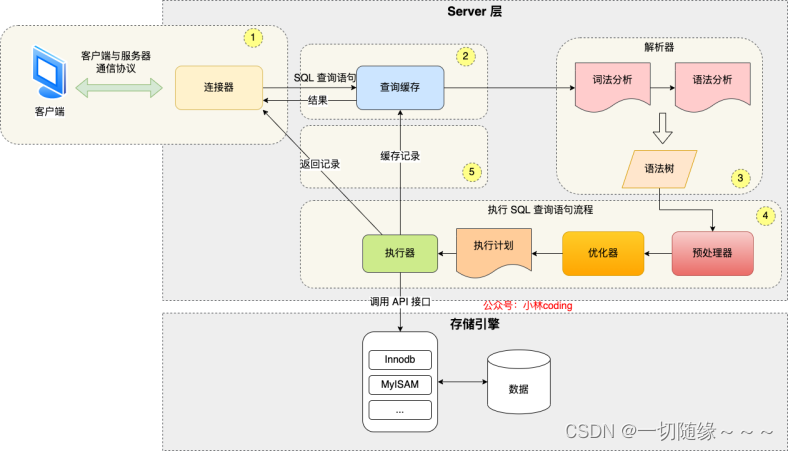
先谈谈MySQL的架构,这样自然就搞清楚一条语句是怎么执行的了
首先,MySQL分为客户端,服务端,存储引擎
客户端:
● Java程序啊,可视化连接工具 Navicat啊等等,就是客户端;
服务端,里面的组件比较多:
● 连接器:验证密码,管理权限,负责客户端与服务端之间的连接的,有一个连接池
● 查询缓存:MySQL 8.0 删除了。因为一旦涉及到缓存,我们就要考虑缓存失效的问题,如果数据表存在数据(表数据,表结构以及索引)的变更,那么这张表的查询缓存就要被清除。
● 分析器:词法分析,语法分析
● 优化器:生成具体的执行计划(比如说,选择哪个索引啊…),但是不一定就是最优的,可能出错,选择的索引并不是效率最高的。出错的情况,就需要我们人为的去更正了,比如说索引选择错了,我们可以使用 force index 来强制选择正确的索引。走了索引,不是一定就快的。
● 执行器:调用存储引擎接口,执行优化器生成的具体的执行计划。
存储引擎:
● 可插拔式的
● innodb(常用的),支持事务,行锁
● myisam,不支持事务,会记录表的行数,最小粒度的锁是表锁
● memory,内存型的
一条更新语句是怎么执行的?
● 更新语句的执行过程和查询语句的执行过程,类似。
● 首先会写 undo log,记录老版本的数据,并更新记录的回滚指针和事务id,便于形成MVCC版本链和实现回滚等操作
● 更新之前,也是要先查询到数据,找的过程就区分两种:一种数据页刚好在内存,一种要去磁盘找。
● 如果本行的数据页在 Buffer Pool 中,直接修改数据页。
● 如果不在内存中,就需要去磁盘中读取(如果是唯一索引字段,会有一些不同)
○ 如果是普通索引,会将更新操作记录在 change buffer 中,等下一次查询将数据页读取到 Buffer Pool 中,再进行 change buffer 里相关的更新操作,然后再刷回磁盘。这样一来,在写多读少的情况下,就减少了磁盘IO的次数。
○ 如果是唯一索引,由于要判断唯一性,只能从磁盘中读取,相当于要去该唯一索引树上面查询一下,有没有这个字段值了,如果已经有了,则更新失败。
● 普通索引的话,是写到 change buffer 中,然后统一刷回磁盘。
● 不同于查询语句的是,还需要记录日志。因为MySQL是 Write Ahead Log,写之前,先写日志。
● 其实是修改Buffer Pool 中的数据页,也不是立刻刷回磁盘的,有很多的刷盘策略
在说的底层一点,其实是先到 Buffer Pool 里面查,看看要查的数据页是不是已经存在于 Buffer Pool中了,如果不存在再去磁盘IO
删除语句,插入语句。执行过程也类似