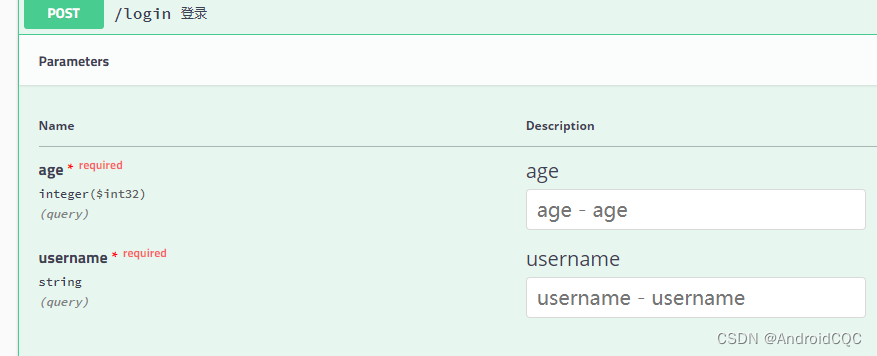
Capturing Omni-Range Context for Omnidirectional Segmentation(捕获全范围上下文进行全方位分割)
目录
一、论文出发点
二、论文核心思想
三、论文工作中主要问题
四、方法论
五、实验
六、结论
一、论文出发点
大多数用于分析城市环境的分割模型都是针对普通的、狭小的视场图像。将这些模型从它们设计的领域转移到360 °全景图像,它们的性能急剧下降。以此作为出发点希望能够构建出一种能捕获全向图像特征的分割模型。
二 、论文核心思想
1.为了弥补图像域之间在FoV和结构分布方面的差距,引入了高效并发注意力网络(ECANets),直接捕获全向(omni directional)图像中固有的长距离依赖关系。
2.由于缺乏足够的全景图像标注,引入多源全监督学习,将未标记的全景图像集成到训练中,使模型能够学习丰富的上下文先验。
3.并且提出并评估了一种全新的全景图像分割数据集:Wild PAnoramic Semantic Segmentation ( WildPASS ),如下图为WildPASS标注展示:

底部图像:在不同角度方向上展开的像素类关联的类分布。
三、论文工作中主要问题
问题1:如何提取全景图像中全景上下文先验?
解决思路:提出了一个高效的并发注意力模块。可以在突出水平驱动的dependencies同时,收集全局上下文信息用于宽FoV分割。这里指的是ECANets。

问题2:没有合适的全向图像分割数据集
解决思路:提出了Wild PASS数据集,该数据集包含来自60多个城市和多个大洲的360 °图像,鼓励更真实地评估全景分割性能。

四、方法论
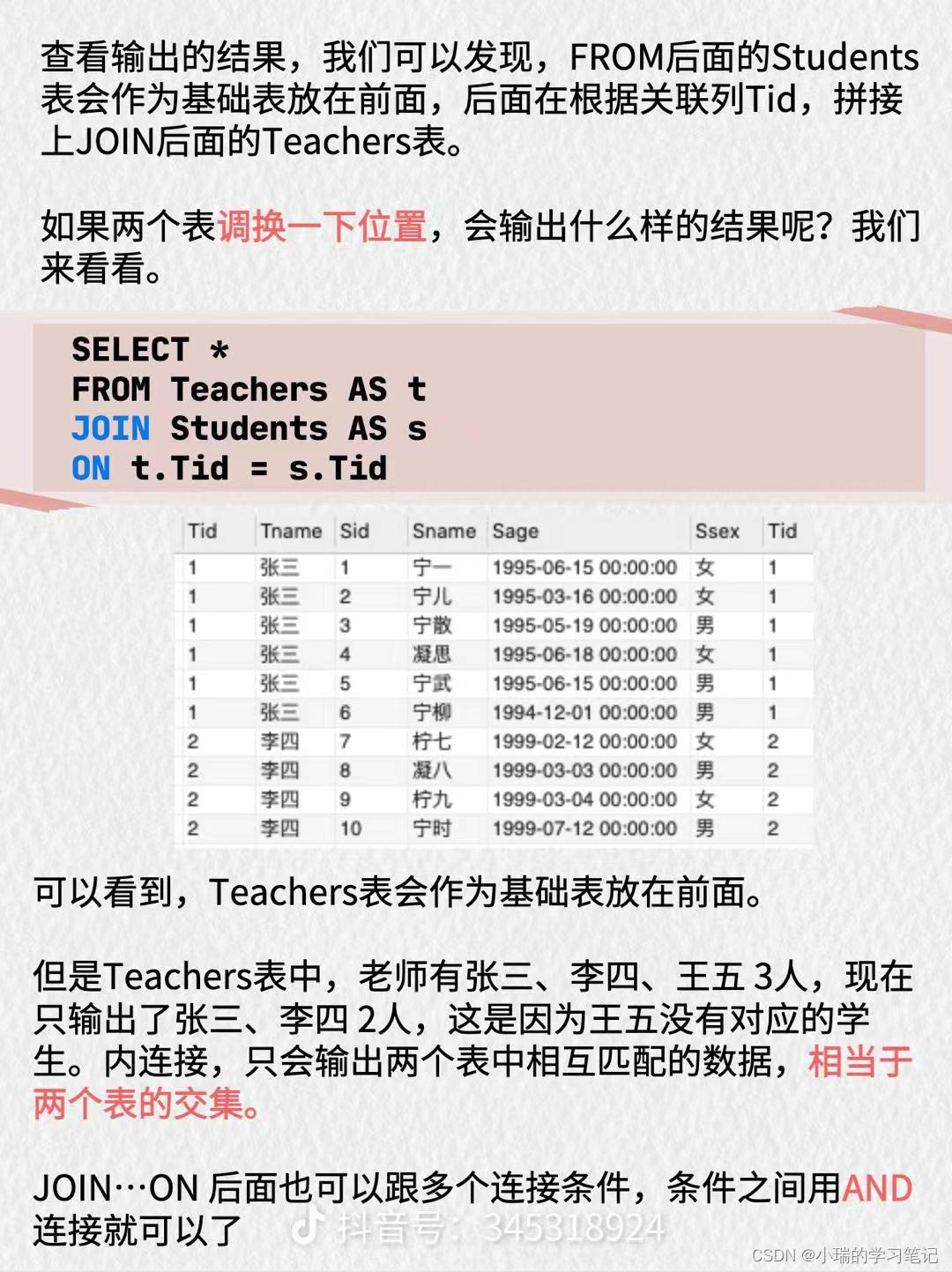
(1)ECANets模型具体实现过程:
ECANet使用了水平部分注意力( HSA )模块和金字塔空间注意力( PSA ) 模块来进行有效的上下文聚合,同时相对于非局部基线在很大程度上减少了计算负担。将关注的特征图通过不同尺度的PSA,然后与HSA和主干特征图进行拼接。最后,将得到的特征图通过卷积层和上采样层进行转换,得到语义图。
(2)HSA模块的实现过程:
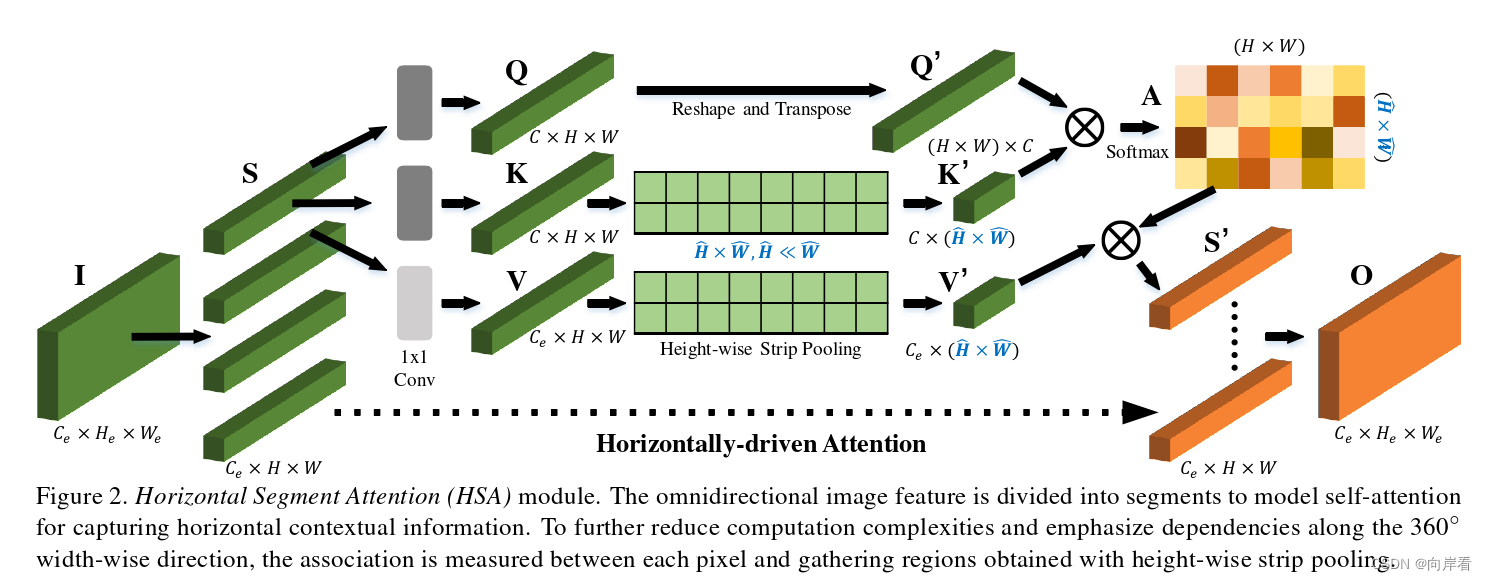
(引入HSA目的:建立自我注意模型,以捕捉广泛的FoV依赖性)
1.首先将输入特征图沿H维度划分为N段(图中N = 4),送入卷积层生成Query Q、Key K和Value V的特征图进行自注意力。
2.进一步地,为了提取360 °区域先验和大幅度降低计算负担,对特征K和特征V进行Height-wise Strip Pooling(长条池化)得到特征K'和V'。然后,由重新整形的特征Q'和K'计算得到注意力图A,计算公式如下:
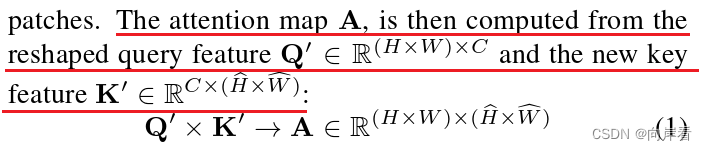
(这样,就可以将每个像素与带状池化区域之间的关联起来,这直接使学习关系沿着横轴跨越360 °。)
将softmax函数应用于注意力图A,并对其进行转置得到,由
和V'计算得到S',计算公式如下:

3.最后,将所有分段S'沿垂直维度H拼接,得到水平驱动输出特征O。
(通过拼接,最后得到在拥有每个分割方向的水平上下文信息的自我注意力特征图)
(3)PSA模块的实现过程:
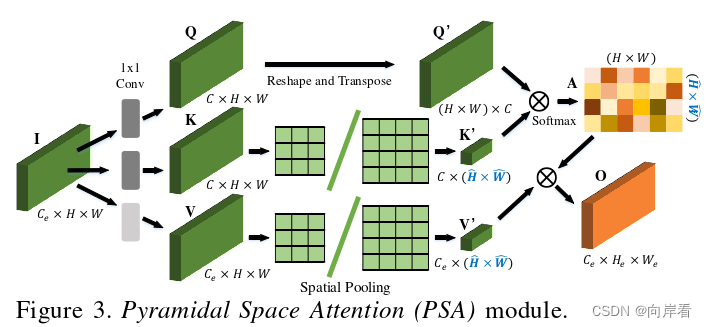
(为了捕捉全局上下文,引入了PSA模块,通过空间池化将每个像素与全局分布的区域联系起 来)
PSA模块与HSA模块的实现过程基本一致,但是不同之处在于:没有对输入特征图进行水平分割,因此使用的是Spatial Pooling(空间池化)进行的下采样,最后直接就能得到每个像素与全局分布的区域关联起来的特征图O。
(4)多源全监督学习:
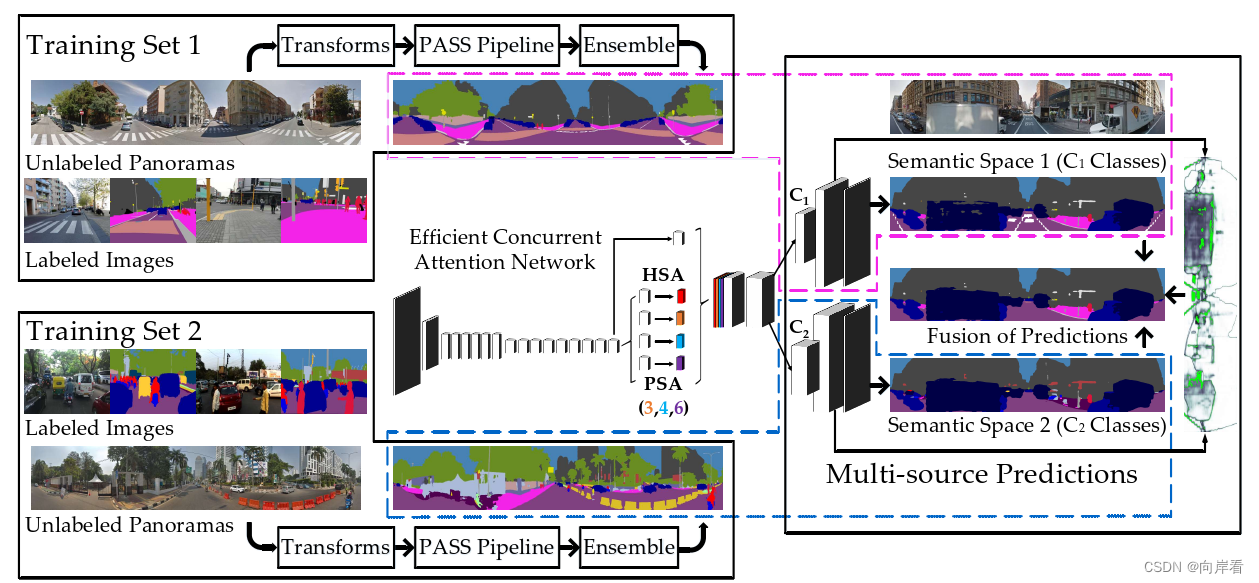
1.首先使用pass piplines在针孔集上预训练的复杂架构在未标记的全景图上创建标注。
2.再通过多空间融合,对HSA和PAS模块输出的预测进行融合。避免标签重叠的公式,如下图所示:

五、实验
使用数据集:1.PASS数据集( 400张环形图像) 2.Wild PASS全景数据集(使用PSPNet50进行创建全景标注)
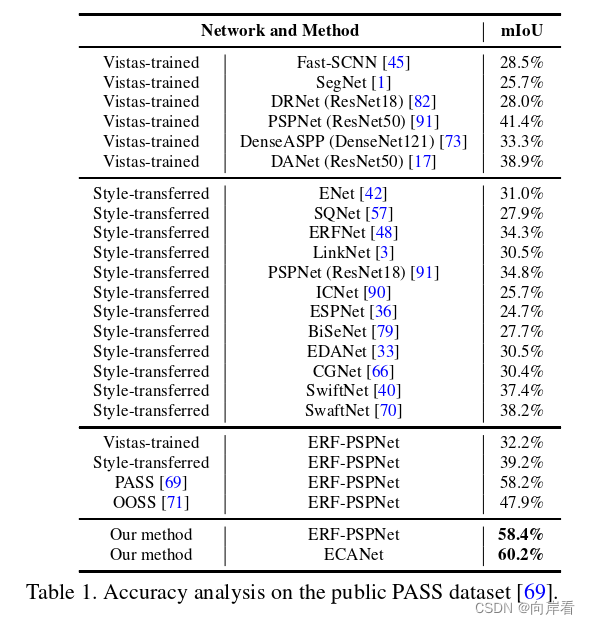
(1)在PASS数据集结果:
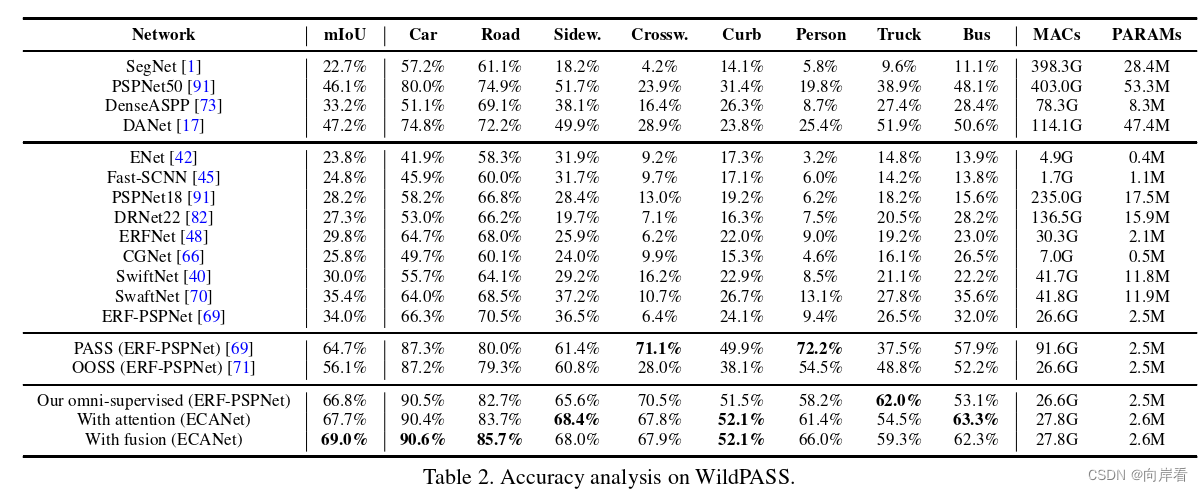
(2)在Wild PASS数据集结果:
六、结论
文章新颖的提出了如何在360 °全景图像上提取上下文先验的问题,并创造性的提出了两种新模块的设计HAS和PAS模块,有效的提高了模型在全景图像分割的精确度。