目录索引
- ==scrapy框架的介绍:==
- ==scrapy第三方包的下载:==
常见的换源网址:
- ==scrapy的图示原理:==
或者:或者:
- ==scrapy原理流程:==
详细介绍:流程描述:scrapy中的三个内置对象:scrapy中每个模块的作用:
- ==Scrapy项目搭建:==
详情:
- ==scrapy的爬虫文件说明 :==
给headers增加对应值:
- ==运行框架的两种方式:==
- <code>第一种命令启动:
- *忽略日志文件:*
- <code>第二种命令启动(推荐):
scrapy框架的介绍:
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
- 框架就是把之前简单的操作抽象成一套系统,这样我们在使用框架的时候,它会自动的帮我们完成很多工作,我们只需要完成一部分
- scrapy使用了Twisted异步网络框架,加快我们的下载速度
- 在各种请求的时候,它底层的逻辑是多线程执行,所以请求效率非常高(但要小心,过快的请求很容易被封ip)
- 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便,框架是代码的半成品,提高效率
scrapy第三方包的下载:
- pip install scrapy -i 换源安装ip地址
- pip install pypiwin32 windows电脑最好下载一下
安装报错处理方案:
报错内容:
包含Twisted的异常:指的是这个库安装报错,无法通过pip进行安装
执行流程:
1.访问https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
2.找到对应的解释器下载版本
Twisted‑20.3.0‑cp37‑cp37m‑win_amd64.whl 这是python3.7的版本
Twisted‑20.3.0‑cp38‑cp38‑win_amd64.whl 这是python3.8的版本
3.下载之后,在该文件路径打开CMD窗口
4.执行pip install Twisted‑20.3.0‑cp... 即可
5.继续执行pip install scrapy
常见的换源网址:
豆瓣:http://pypi.douban.com/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
华为云:https://repo.huaweicloud.com/repository/pypi/simple
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple
中科大:https://pypi.mirrors.ustc.edu.cn/simple/
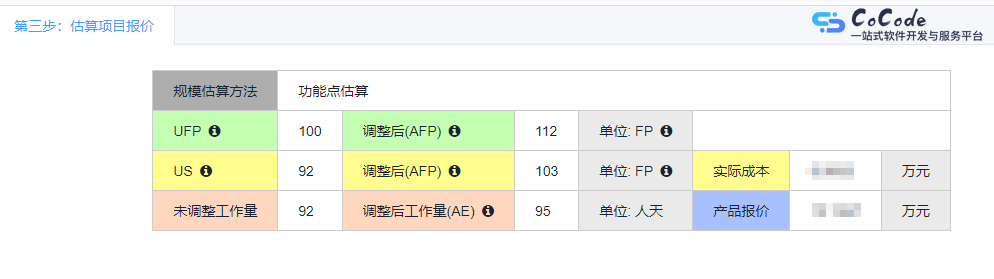
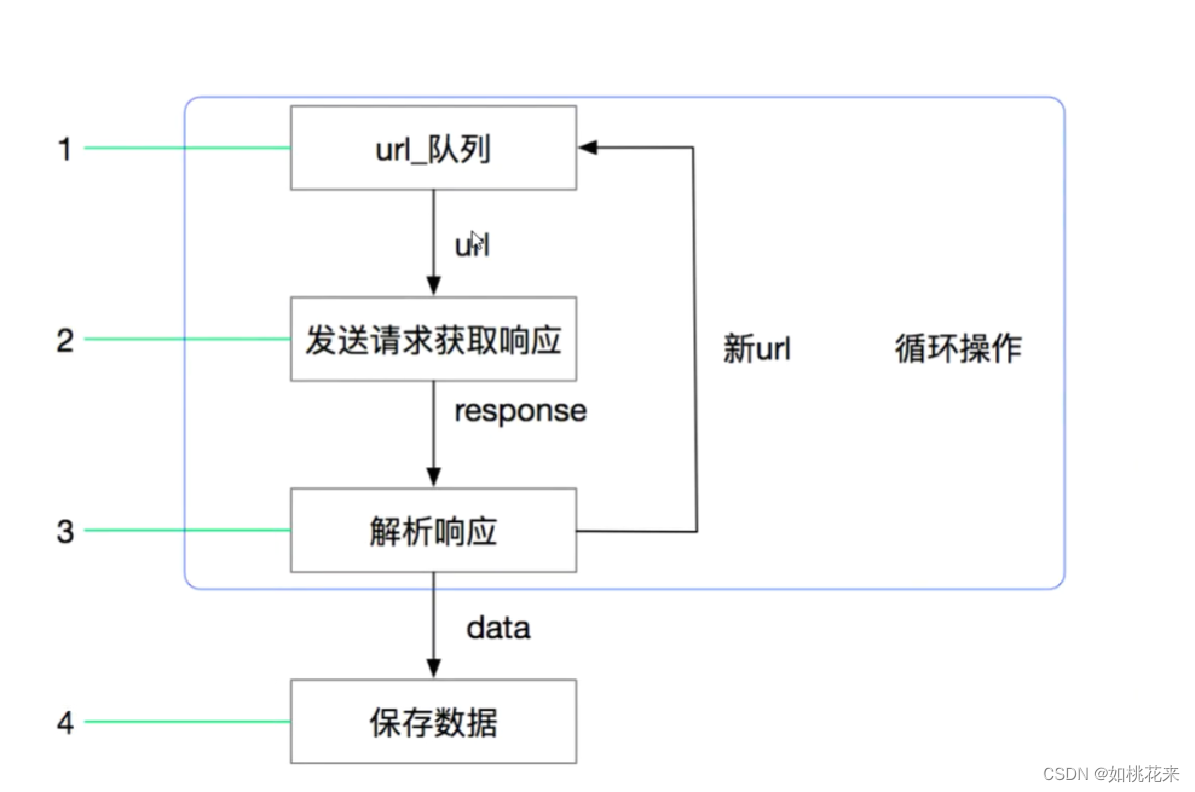
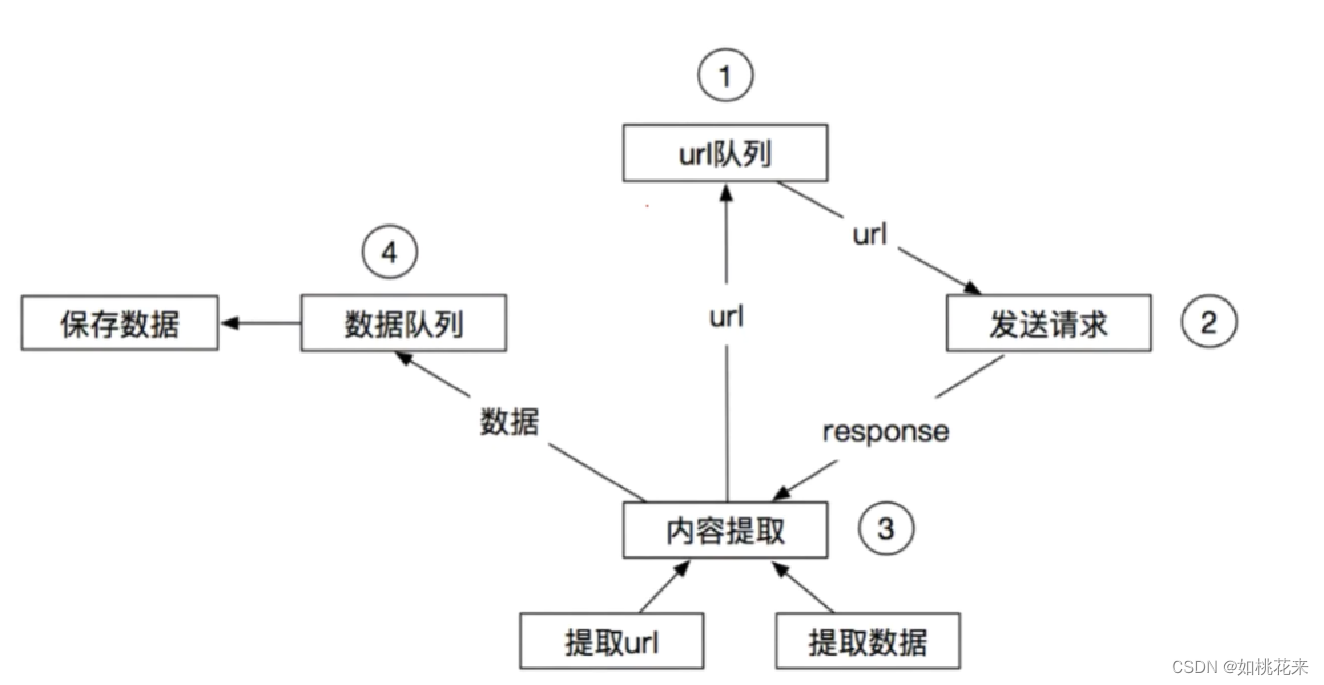
scrapy的图示原理:
或者:
或者:
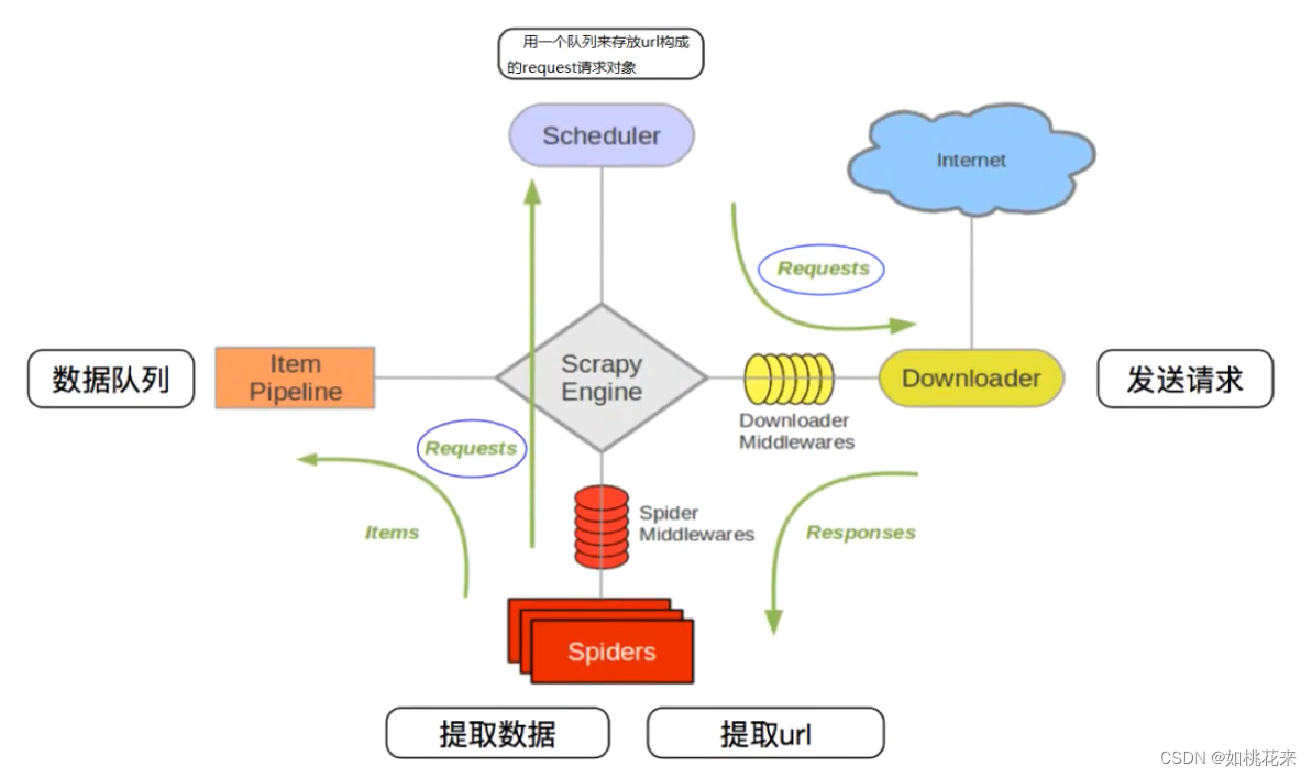
scrapy原理流程:
# 1.spider将起始的地址请求对象由引擎(engine)传给调度器(Scheduler)存放排列入队<去重,过滤重复对象>,当引擎需要时传递给引擎(有时候会无法去重)
# 2.引擎将请求对象传递给下载器(发送请求),传递经过下载中间件(随机ua,添加代理等)
# 3.下载器获取的响应response交还给引擎由其交给spider
下载器--引擎:经过下载中间件:拦截响应对象(数据预处理,状态码异常校验,请求对象重构)
引擎--spider:经过爬虫中间件:自定扩展和操作引擎和Spider中间通信的功能组件
(比如进入Spider的Responses;和从Spider出去的Requests)
# 4.spider解析响应
@解析需要继续跟进的地址url:构造请求对象,传递给引擎,由其交给调度器存放入队(相当于从老url里面取出新的url,然后接着发送请求)
@解析出item中定义的数据:传递给引擎,由其交给管道(pipeline),保存
# 5.item文件是用来数据建模的,所有保存的数据都需要先在item文件中进行数据建模,变量名必须相同,否则就会报错。
# 6.传回的响应全都是用response这个变量来接收,它的底层逻辑是多任务,所以说我们直接用就可以了,框架会自行处理
详细介绍:
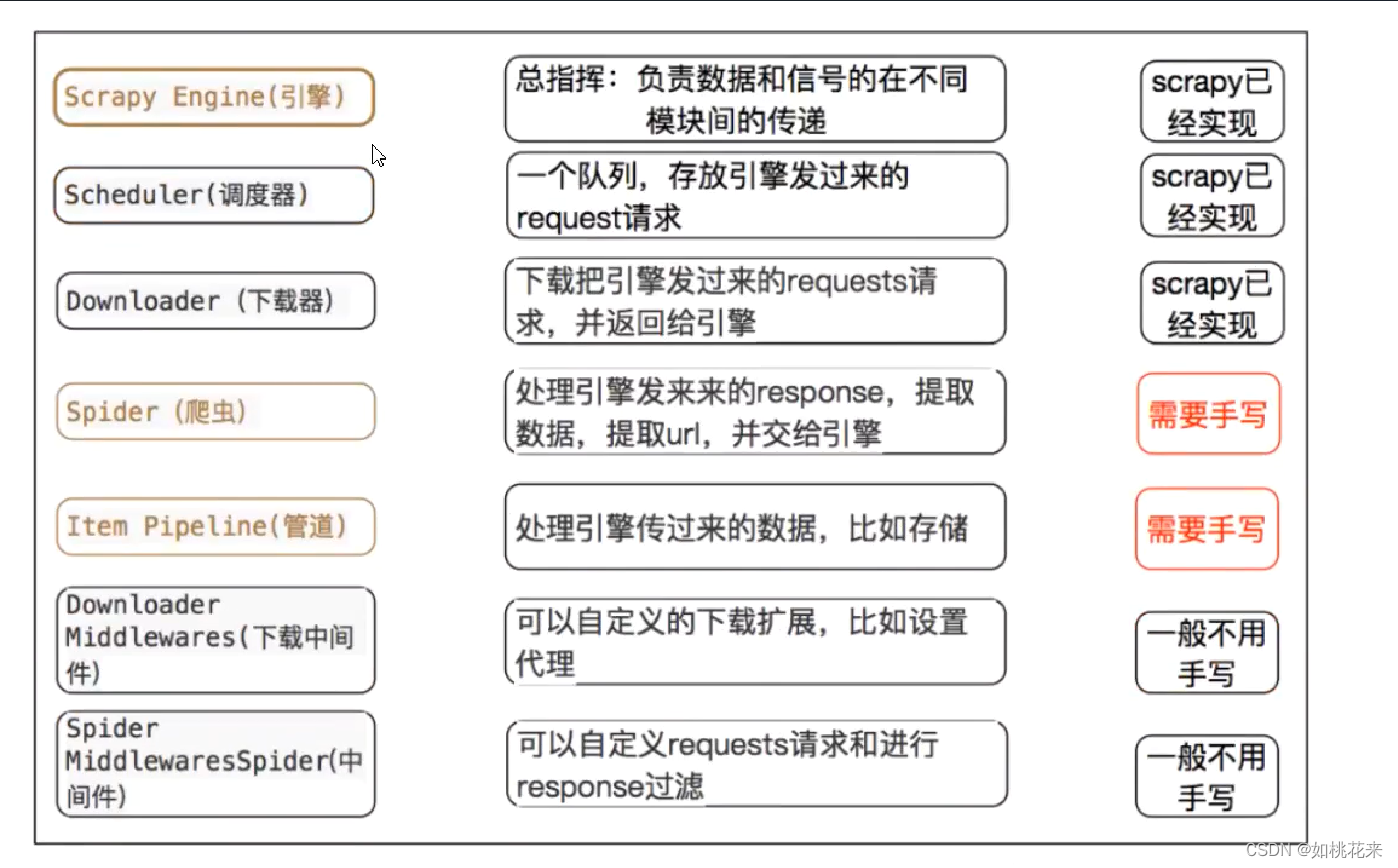
- crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
流程描述:
1.爬虫中起始的url构造成 request对象--->爬虫中间件-->引擎--->调度器
2.调度器把 request--->引擎-->下载中间件-->下载器
3.下载器发送请求,获取 responsel响应-->下载中间件-->引擎-->爬虫中间件--->爬虫
4.爬虫提取url地址,组装成 request对象-->爬虫中间件-->引擎--->调度器,重复步骤2
5.爬虫提取数据--->引擎--->管道处理和保存数据
scrapy中的三个内置对象:
request请求对象:由 url method post data headers等构成
response响应对象:由 url body status headers等构成
item数据对象:本质是个字典
scrapy中每个模块的作用:
Scrapy项目搭建:
Scrapy是作为一个项目启动的,要启用指令创建,里面会为你自动搭建好基础框架。
# 点开pycharm下方的Terminal
# 新建scrapy项目
# 爬虫项目创建
# scrapy startproject 爬虫项目名
# cd 爬虫项目名文件夹
# scrapy genspider 爬虫名称 爬虫的域
# 爬虫名 开启/运行 爬虫的时候,需要通过爬虫名称开启爬虫
# 爬虫域 域名,告诉爬虫,我这个项目,只爬取属于什么域的内容
注意:爬虫项目名 与 爬虫名 不可同名
""
1.项目文件下的项目名下的py文件就是你要书写的爬虫文件
2.items.py用于数据建模, 爬取的目标内容必须在此建模 (不要写中文注释)
3.middlewares.py 是下载模块 是爬虫中间件和下载中间件 暂时不用
4.pipelines.py 做管道保存,所有数据保存的代码写在此处,框架要求这样
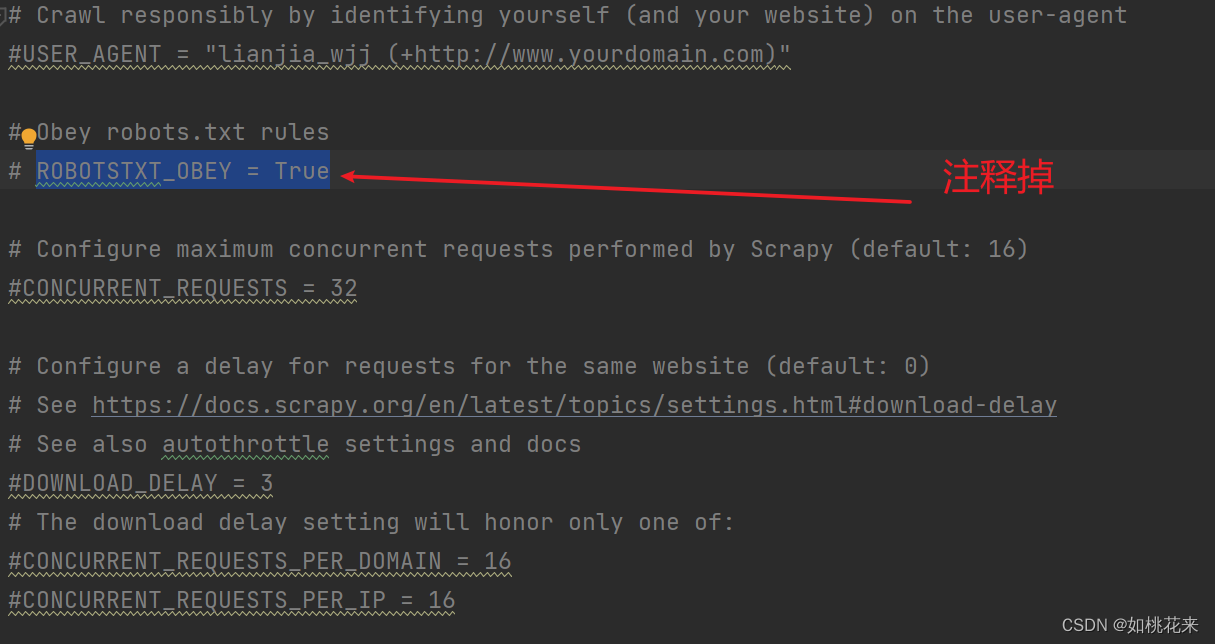
5.settings.py 是配置文件 默认20行 roboots协议是开启的,启动项目后先设为FALSE,或者直接注释掉 后面如果要开启管道的时候需要在66行开启
6.settings和items里面不要写中文注释
""
详情:
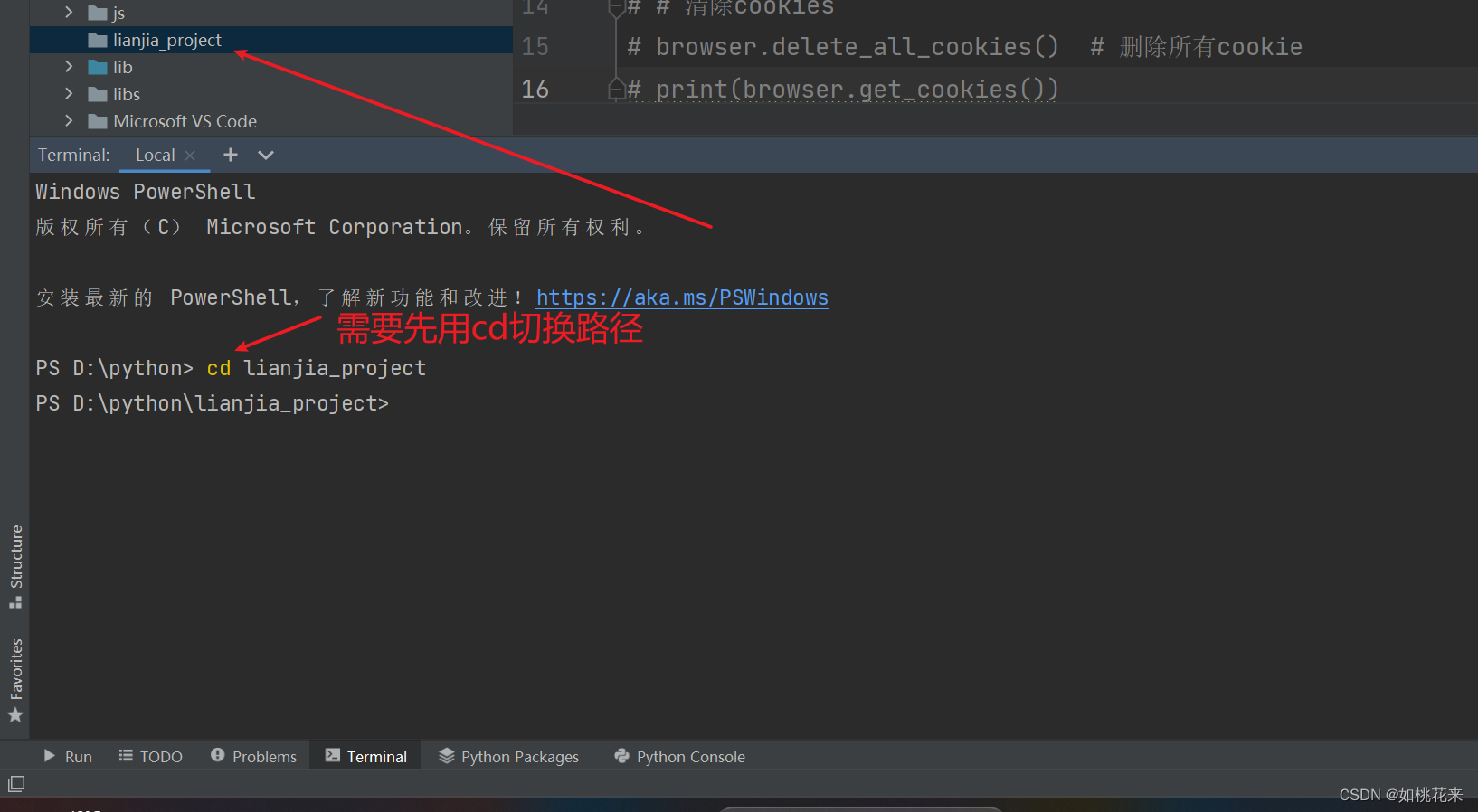
1.
切换到你要创建项目的指定文件夹下
2.
执行创建命令
scrapy startproject 爬虫项目名

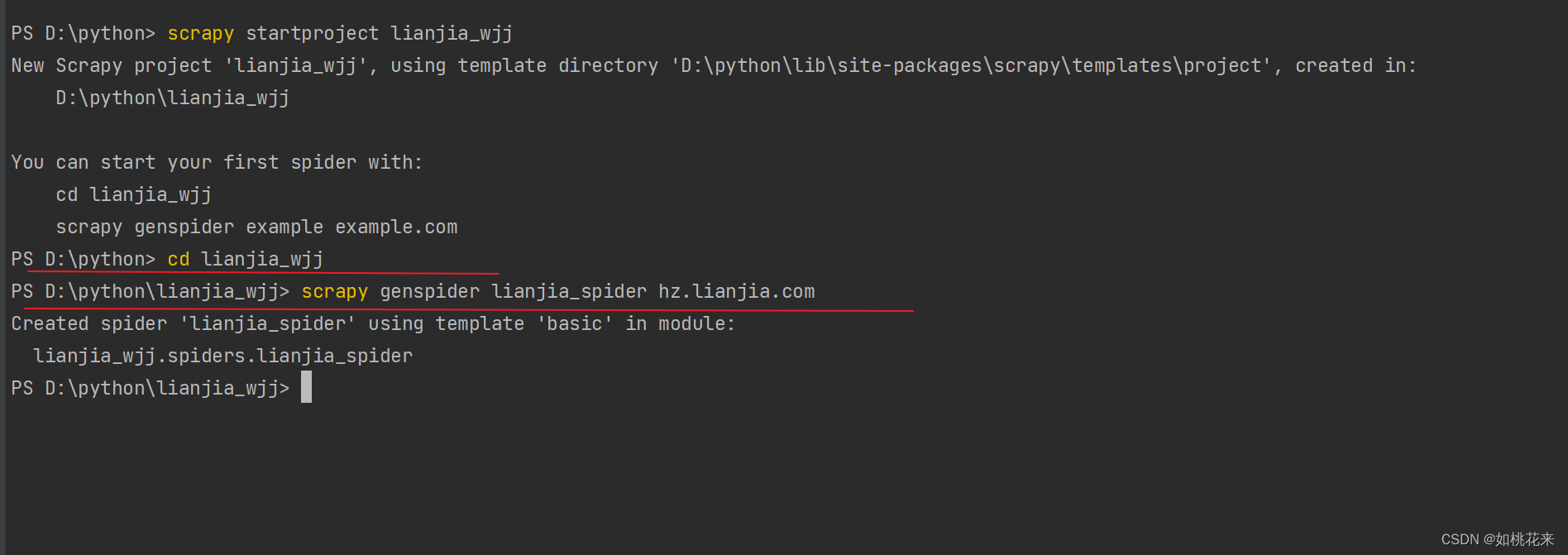
3.
继续cd切换到爬虫项目名下的文件下路径,然后创建爬虫名和爬虫域

注意:
- 爬虫项目名与爬虫名不可同名
- 爬虫域就是https后面和包括com的那一串
- 很多按钮、跳转的网页都会在爬虫域下面进行,所以说域跟网址是不一样的
scrapy的爬虫文件说明 :
我们举个例子用来说明
这是在lianjia_spider.py下面自动生成的代码
import scrapy
class LianjiaSpiderSpider(scrapy.Spider):
#下方都是自动创建的
#爬虫名
name = "lianjia_spider"
#爬虫域
allowed_domains = ["hz.lianjia.com"]
#起始url
start_urls = ["http://hz.lianjia.com/"]
def parse(self, response):
#我们写爬虫逻辑就写在parse下面,名字不可以改
print(response.text)
- 记得要修改起始url
start_urls ["https://hz.lianjia.com/zufang/"]
- 将租房界面作为起始url
- 我们写爬虫逻辑就写在parse下面
- 运行之后,会交给下载器发送请求。然后得到的响应会返回给response
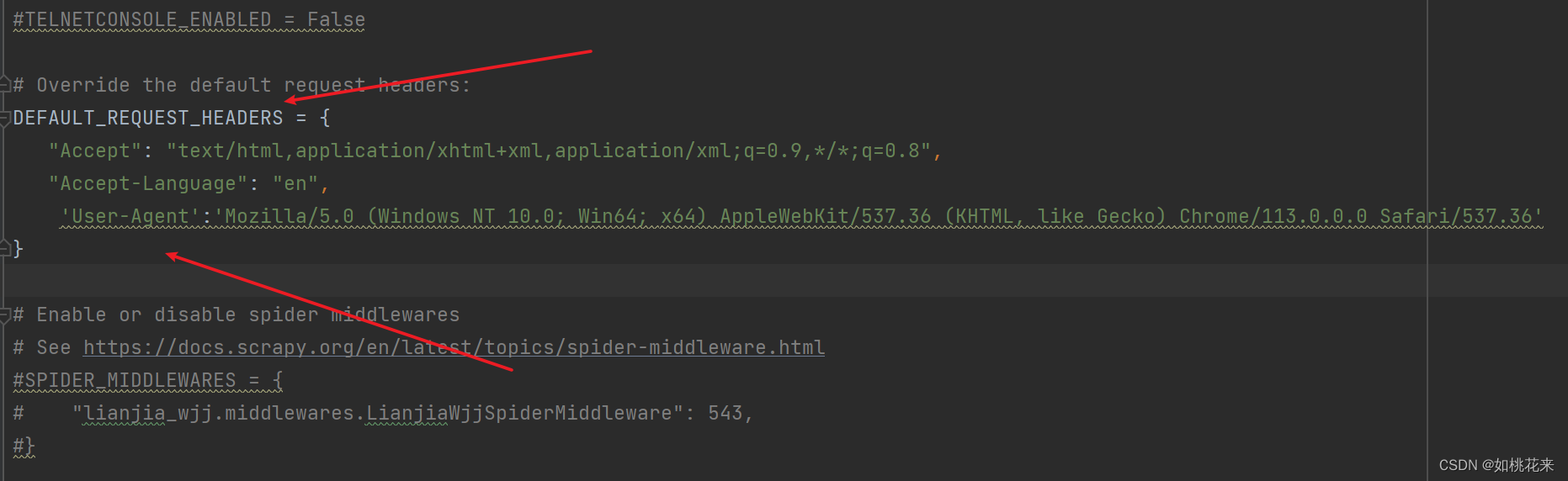
给headers增加对应值:
手动拿到的数据需要赋值到settings里面
或者:
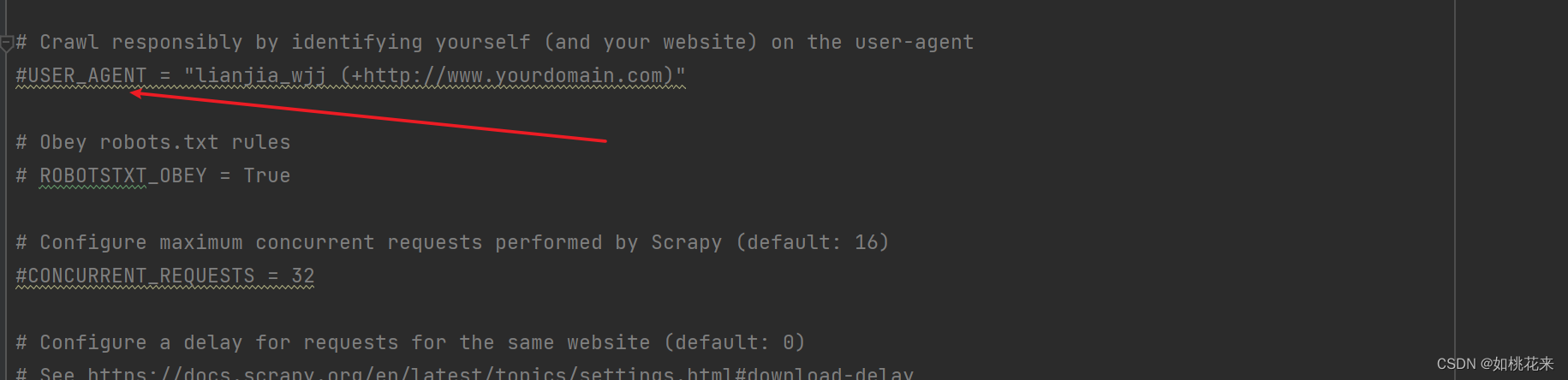
运行框架的两种方式:
第一种命令启动:
- 切换到项目路径里面的文件夹路径
- 输入指令:scrapy crawl 爬虫.py的名称
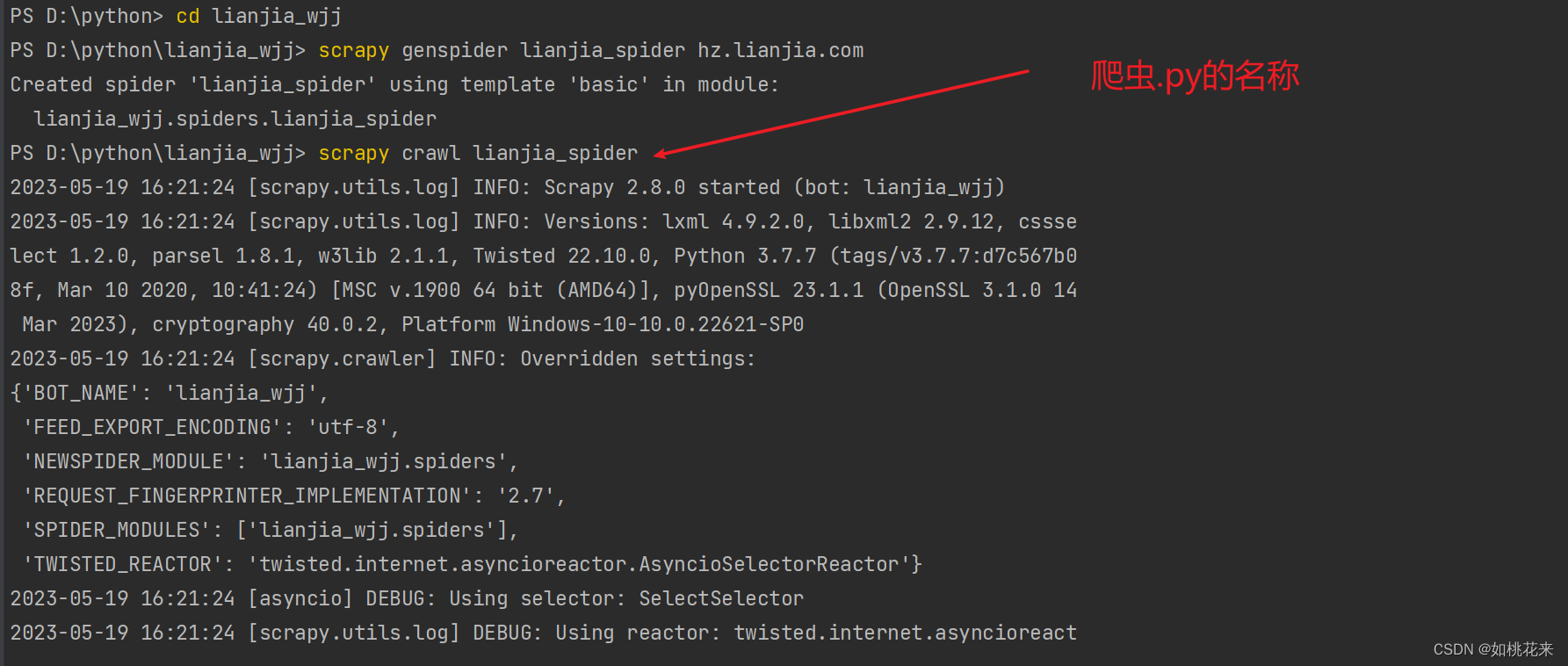
前面会有一些启动的日志文件
忽略日志文件:
输入命令:
#后方加入一个--nolog即可
scrapy crawl lianjia_spider --nolog
第二种命令启动(推荐):
- 在自动创建的文件夹下方创建一个start.py文件,跟cfg文件同级别
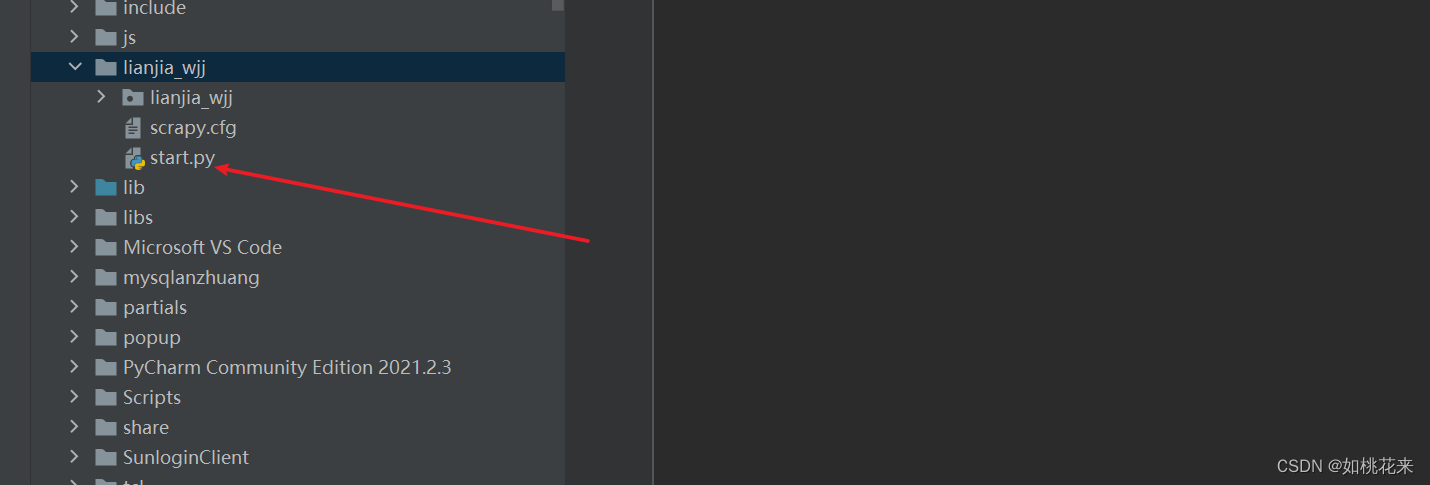
在start文件下方写入模块:
from scrapy import cmdline
#一定要以列表形式传入
cmdline.execute(["scrapy","crawl","lianjia_spider","--nolog"])
直接在start文件下运行就可以了




![Rasa 3.x 学习系列-Rasa [3.5.8] -2023-05-12新版本发布](https://img-blog.csdnimg.cn/a9437d24cb0d48f78e2f4b0bc016212d.png)