随着近两年来对视觉Transformer模型(ViT)的深入研究,ViT的表达能力不断提升,并已经在大部分视觉基础任务 (分类,检测,分割等) 上实现了大幅度的性能突破。
然而,很多实际应用场景对模型实时推理的能力要求较高,但大部分轻量化ViT仍无法在多个部署场景 (GPU,CPU,ONNX,移动端等)达到与轻量级CNN(如MobileNet) 相媲美的速度。
为了实现对ViT模型的实时部署,来自微软和港中文的研究者从三个维度分析了ViT的速度瓶颈,包括多头自注意力(MHSA)导致的大量访存时间,注意力头之间的计算冗余,以及低效的模型参数分配,进而提出了一个高效ViT模型EfficientViT。它以EfficientViT block作为基础模块,每个block由三明治结构 (Sandwich Layout) 和级联组注意力(Cascaded Group Attention, CGA)组成。此外,作者进一步进行了参数重分配(Parameter Reallocation)以实现更高效的channel, block, 和stage数量权衡。该方法在ImageNet数据集上实现了 77.1% 的 Top-1 分类准确率,超越了MobileNetV3-Large [1] 1.9%精度的同时,在NVIDIA V100 GPU和Intel Xeon CPU上实现了40.4% 和 45.2%的吞吐量提升,并且大幅领先其他轻量级ViT的速度和精度。代码已开源。

论文链接:
https://arxiv.org/abs/2305.07027
代码链接:
https://github.com/microsoft/Cream/tree/main/EfficientViT
轻量级CNN和ViT模型吞吐量和精度对比的展示

图1 NVIDIA V100上的Throughput和ImageNet-1K分类性能对比

一、问题分析
1.1 访存时间瓶颈
在ViT中,多头自注意力(MHSA)和前馈神经网络(FFN)通常是不可或缺的两个组成模块且交替排列。然而,MHSA中的大量操作如reshape,element-wise addition,normalization是非计算密集的,因此较多时间浪费在了在数据读取操作上,导致推理过程中只有很小一部分时间用来进行张量计算,如下图所示:

图2 运行时间分析
尽管有一些工作提出了简化传统自注意力 [2, 3] 以获得加速,但是模型的表达能力也受到了一定的影响导致性能下降。因此,本文作者从探索最优的模块排列方式入手,以求减少低效的MHSA的模块在模型中的使用。
首先,作者通过减少MHSA和FFN block的方式,构建了多个比Swin-T和DeiT-T加速1.25和1.5倍的子网络,每个子网络有着不同的MHSA block比例。对这些子网络进行训练后,作者发现原始Transformer的MHSA和FFN的1:1设计范式并不能实现最优速度-精度权衡,而有着更少的MHSA模块比例(20%~40%)的子网络却可以达到更高的精度。
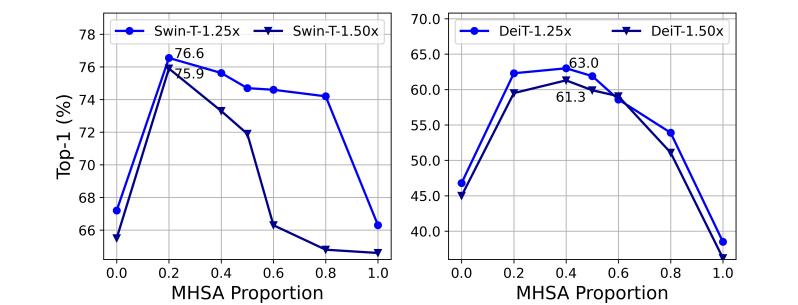
图3 不同MHSA比例的模型性能对比
1.2 计算冗余瓶颈
Transformer中的多头自注意力将输入序列在多个子空间中分别计算注意力,以获得更多样化的特征表达。然而,注意力计算非常耗时,而且已有研究表明并不是所有的头都对结果有显著贡献 [4, 5]。
为了度量ViT在轻量化后是否也会出现头部的计算冗余,作者构建了宽度更小的Swin-T和DeiT-T模型,并计算不同头映射特征的余弦相似度。如图4,许多头部学习到了类似的模式而产生大量计算冗余。作者认为这一现象与给每个头部输入的是同样的完整特征有关。因此,为了显式地解耦不同头部映射的模式,作者尝试只给每个注意力头提供一部分输入特征(w/ Head Splits),以减小不同头部映射的相似度,并发现这一操作确实使相似度和冗余得到了一定程度的降低。
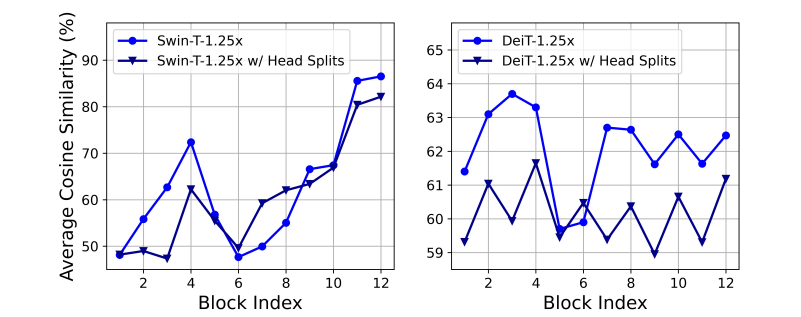
图4 注意力头的平均余弦相似度
1.3 参数分配瓶颈
作者注意到,为了实现高效推理,轻量化CNN如MobileNet通常有着不同于ResNet等通用网络的宽度和层数设计,而现有的轻量化ViT大多遵循DeiT、Swin的参数分配策略,如给Q,K,V相同的特征维度,Head数目随着网络加深而逐渐增加,宽度在每个stage加倍等,这种方式可能无法实现ViT的最优效率。受Rethinking Channel Pruning [6] 和NViT [7] 启发,本文作者采用Taylor Structured Pruning [8] 自动寻找Swin-T中的重要成分,并探索参数分配的最有效方式。如下图所示,模型在浅层保留了更多的维度,而在深层保留的更少;Q、K和FFN的维度被大量修剪,而V的维度几乎被全部保留,只在最后几个block处出现了轻微减少。因此,传统的ViT通道配置可能在深层产生大量冗余,且Q,K的的冗余度比V大得多,而V的维度倾向于与输入接近。
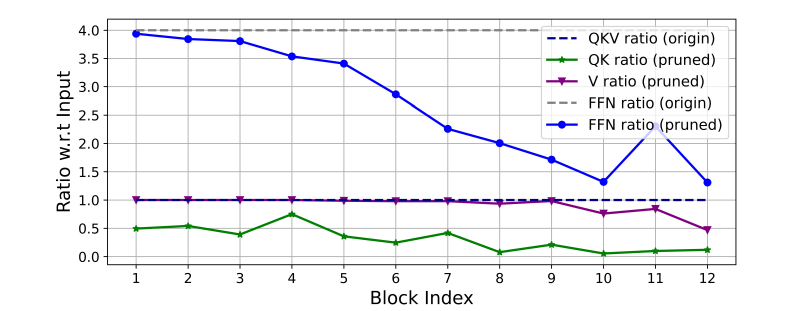
图5 Swin-T修建前后的通道对比
二 、模型构建

基于上述分析,作者构建了如上图所示的EfficientViT。其核心为EfficientViT block,每个EfficientViT block的输入特征先经过N个FFN,再经过一个级联组注意力CGA,再经过N个FFN层变换得到输出特征。这一基础模块减少了注意力的使用,缓解了注意力计算导致的访存时间消耗问题。同时,作者在每个FFN之前加入了一层DWConv作为局部token之间信息交互并帮助引入归纳偏置。
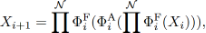
对于CGA模块,作者采用了将输入特征拆分,只给每个注意力头提供一部分输入特征的方式以减小计算冗余。同时,注意力计算采用了逐个头级联的方式,在不增加额外参数的情况下提升了轻量级网络的深度和表达能力。
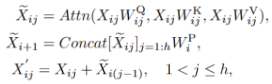
最后,作者基于上述参数重要性分析对网络的组成成分进行了参数重排,给 Q 和 K 更小的维度,并调整了 V 的维度保证其与每个头的输入维度一致,并使用了expansion ratio为2的FFN。
模型的设计还包括其他细节。具体来说,EfficientViT用了overlap patch embedding以增强模型的low-level视觉表征能力。由于BN可以与线性层和卷积层在推理时融合以实现加速,网络中的归一化层采用了BN来替换LN。类似MobileNetV3 [1]和LeViT [9],网络在大尺度下层数更少,并在每个stage用了小于2的宽度扩展系数以减轻深层的冗余。

表1 EfficientViT系列模型
三 、实验结果
作者在ImageNet分类,下游分类,检测任务和实例分割任务上验证了EfficientViT的性能。在下表2中,EfficientViT的性能领先于轻量级CNN和ViT模型,并在NVIDIA GPU,Intel CPU,和部署为ONNX模型的场景下有着显著的速度优势。
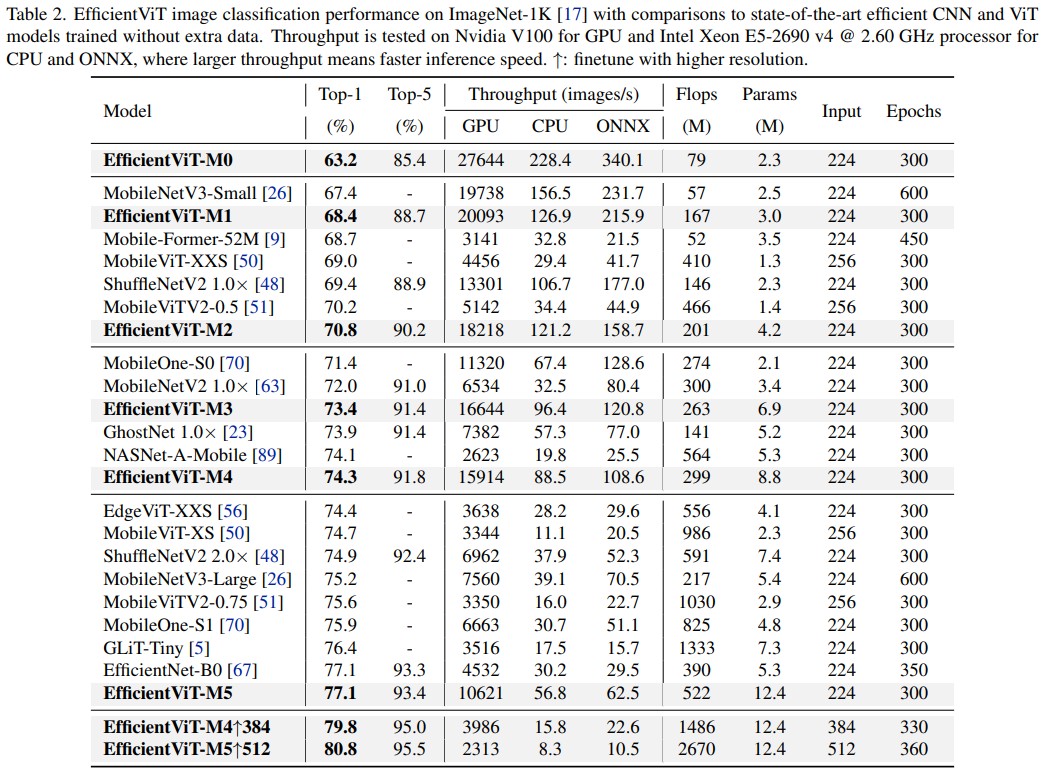
表2 ImageNet-1k分类性能
下表3展示了EfficientViT和通用ViT模型的对比,以及在下游分类任务上的性能。EfficientViT在轻量化和实时推理的同时仍有良好的迁移能力。
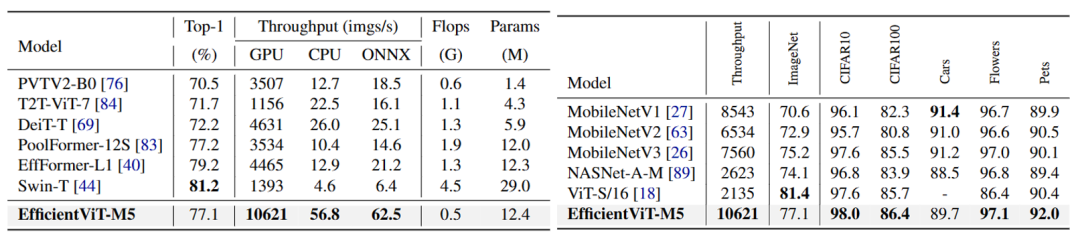
表3 ImageNet-1k和下游分类任务性能
下表4展示了在检测和实例分割框架下,EfficientViT依然保持性能优势。
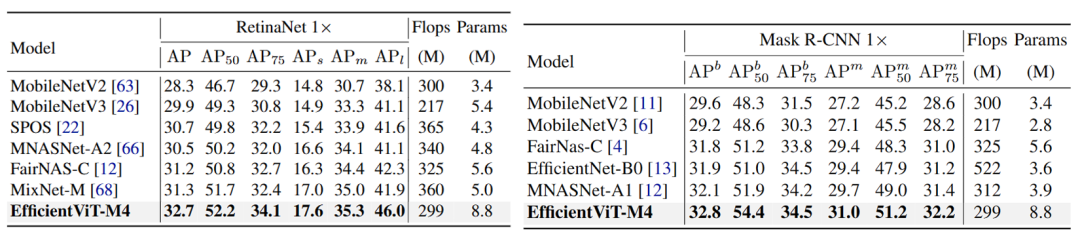
表4 检测和实例分割性能
作者在消融实验中详尽的分析了每个模块的作用,并比较了在不同的超参设计和训练策略下模型的性能变化。
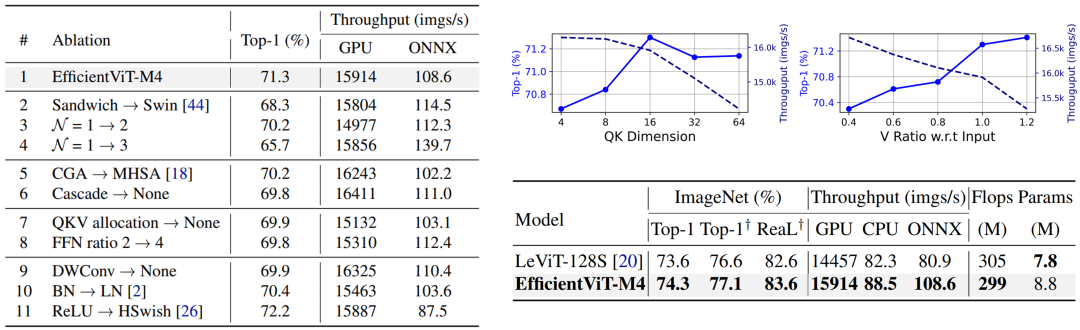
表5 消融实验
四 、结语
本文详细分析了现有ViT的推理速度瓶颈,提出了EfficientViT以实现不同部署场景下的实时推理,其基本模块由三明治结构和级联组注意力构成。在多个任务和数据集上的实验展示了模型的性能和速度。随着各个领域的研究人员对ViT的深入探索,模型的潜力正在被不断发掘。研究者希望通过本文能给ViT轻量化和在有实时性要求的场景下广泛应用提供灵感。在未来工作中,研究者将尝试通过网络结构搜索进一步提高效率,减少模型参数,以及探索如何扩展到不同任务和数据模态下的Transformer中。
参考文献
[1] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In ICCV, 2019
[2] Sachin Mehta and Mohammad Rastegari. Separable self-attention for mobile vision transformers. arXiv preprint arXiv:2206.02680, 2022
[3] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In ICLR, 2020.
[4] Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one? NeurIPS, 32, 2019
[5] Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In ACL, pages 5797–5808, 2019
[6] Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. In ICLR, 2018.
[7] Huanrui Yang, Hongxu Yin, Pavlo Molchanov, Hai Li, and Jan Kautz. Nvit: Vision transformer compression and parameter redistribution. arXiv preprint arXiv:2110.04869, 2021.
[8] Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, and Jan Kautz. Importance estimation for neural network pruning. In CVPR, pages 11264–11272, 2019.
[9] Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Herv ́e J ́egou, and Matthijs Douze. Levit: a vision transformer in convnet’s clothing for faster inference. In ICCV, 2021
Illustration by IconScout Store from IconScout
-The End-
点击阅读原文