文章目录
- 概述
- VariantAutoencoder.py文件实现
- 关闭eager execution
- 修改bottlenectk组件
- 修改loss损失函数
- VariantAutoencoder.py实现的全部代码
- train.py文件实现
- load_mnist模块
- train模块
- 完整代码
- 执行效果
- 总结
- Analysis代码
概述
- 之前的一篇文章中,介绍了如何实现autoencoder,这篇文章介绍的是如何将之修改为variant autoencoder,变分自动编码器。
- 这部分主要是在原来的autoencoder.py文件上,进行修改实现的,这部分包括了变分自动编码器的实现代码,以及训练代码。
- 比起原来的autoencoder.py,做了如下的修改
- 对于bottleneck,使用概率分布,替代了原来的点映射
- 修改损失函数为 α \alpha αRMSE +KL
- train.py文件的具体实现
VariantAutoencoder.py文件实现
- 这部分主要是介绍了,如何对autoencoder进行修改,将之转变为vatiant autoencoder,主要是修改了两个部分,还有一个开发模式
- 修改了损失函数,增加了KL散度,来控制分布的相似度
- 修改了bottleneck组件,增加了实现正态分布的结构
- 修改了开发模式,关闭了eager execution
关闭eager execution
- eager execution 的相关知识,链接添加链接描述
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
修改bottlenectk组件

注意
- 这里还是要结合正态分布的两个特征参数,将之映射为特征空间中一个特征点,同时为了保证特征点,关于mean value左右波动,所以需要将原来的协防差矩阵进行转换,右边的 ε \varepsilon ε还是在对应维度下的标准正态中随机抽样的点
上述这段,很重要,至少在代码生成中很重要,因为并没有现成的库给你调用!!下面就是具体的代码
def _add_bottleneck(self,x):
# 9、第九部分进行编写
# 4.1,如果要将自动编码器转为变分自动编码器,需要实现正态分布,并且能够随机从中选取特定的点
""" 首先将数据展平,然后在传入全链接层 """
self._shape_before_bottleneck = K.int_shape(x)[1:] # [batch_size,height,weight,channel],这里只需要后面三个的大小
x = Flatten()(x)
self.mu = Dense(self.latent_space_dim,name = "mu")(x)
self.log_variance = Dense(self.latent_space_dim,name ="log_variance")(x)
def sample_point_from_normal_distribution(args):
mu,log_variance = args
epsilon = K.random_normal(shape = K.shape(self.mu),mean = 0.,
stddev = 1.)
sample_point = mu + K.exp(log_variance / 2) * epsilon
return sample_point
x = Lambda(sample_point_from_normal_distribution,
name = "encoder_output")([self.mu,self.log_variance])
x = Dense(self.latent_space_dim,name = "encoder_output")(x)
return x
修改loss损失函数
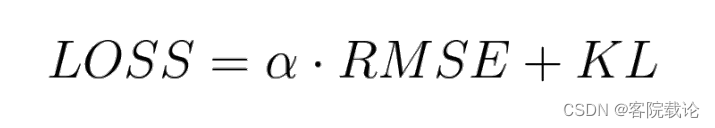
- KL散度,用来标准正态分布和正态分布之间的差异
- 对于那种方差和标准分布参数完全不同的分布进行矫正
- 因为只有不断向标准正态分布靠拢,才能不断确保最终的表示空间是零点对称的。
- 同时还能减少类与类之间的空白间隔的出现
-
α
\alpha
α是重建损失函数的权重,
- 太大,最终的效果和自动编码器的效果相同
- 太小,重建的图片和原图一点关系都没有
KL散度损失函数
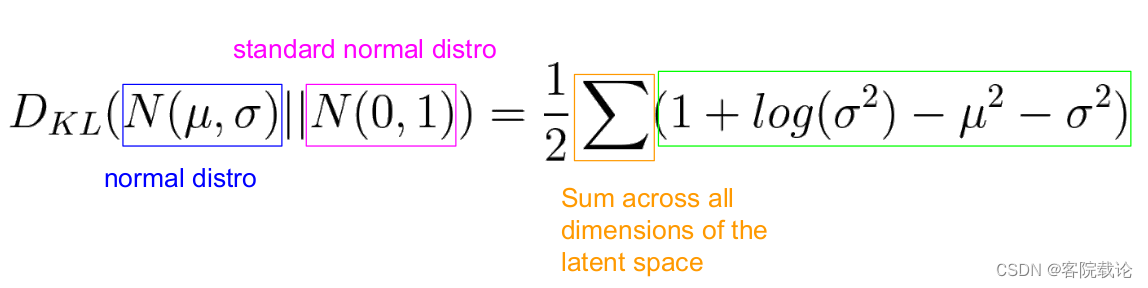
- 这个函数是用来衡量当前的正态分布和高斯正态分布之间的距离,使得当前的正态分布,不断向标准正态分布进行靠拢
- 具体的数学公式如下,这个损失函数并没有现成的库可以调用,所以需要根据公式进行自定义
 具体实现代码如下
具体实现代码如下
# 4.2 将两种损失函数进行综合
def _calculate_combined_loss(self,y_target,y_predict):
""" 两个损失函数进行汇总 """
reconstruction_loss = self._calculate_reconstruction_loss(y_target,y_predict)
kl_loss = self._calculate_kl_loss(y_target,y_predict)
combined_loss = self.reconstruction_weight * reconstruction_loss + kl_loss
return combined_loss
# 4.2 损失函数重建
def _calculate_reconstruction_loss(self,y_target,y_predict):
""" 模型重建损失函数,加上了对应alpha """
error = y_predict - y_target
reconstruction_loss = K.mean(K.square(error),axis = [1,2,3]) # 注意,这里只需要返回除了第一个图片序号的后两个维度
return reconstruction_loss
# 4.2 损失函数重建
def _calculate_kl_loss(self,y_target,y_predict):
""" KL散度,用来衡量当前的正态分布和标准正态分布之间的距离"""
kl_loss = -0.5 * K.sum(1 + self.log_variance - K.square(self.mu) - K.exp(self.log_variance),axis=1)
return kl_loss
VariantAutoencoder.py实现的全部代码
from tensorflow.keras import Model
# 一般进行版本更新都是改变的包的导向,或者改变包的方法名
from tensorflow.keras.layers import Input,Conv2D,ReLU,BatchNormalization,Flatten,Dense,\
Reshape,Conv2DTranspose,Activation,Lambda
# 引入backend,这个用来自己定义层,将一些函数定义成特定的层
from tensorflow.keras import backend as K
# 导入numpy,对三维数据进行操作
import numpy as np
# 导入对应优化器,注意,这里已经改变了包的地址
from tensorflow.keras.optimizers.legacy import Adam
# 导入损失函数
from tensorflow.keras.losses import MeanSquaredError
# 导入系统模块
import os
# 序列加载模块
import pickle
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
class VAE:
"""
Autoencoder: 变分自动编码器
这个是在原来的自动编码器上做了如下的修改
1、在原来的bottleneck部分,增加高斯分布
2、更新损失函数,加入KL散度以及修改原来的MSE
"""
# 1、当前类别的构造函数,
def __init__(self,
input_shape,
conv_filters,
conv_kernels,
conv_strides,
latent_space_dim
):
# 2、 将所有的属性都赋值给对应实体属性
self.input_shape = input_shape # [28,28,1]这里是使用minst手写数据集进行测试的
self.conv_filters = conv_filters # [2,4,8]
self.conv_kernels = conv_kernels # [3,5,3]
self.conv_strides = conv_strides # [1,2,2]
self.latent_space_dim = latent_space_dim # 潜在映射空间的维度,这里设置为2维度空间
# 3、这里的习惯就很好,将一个大模型拆解成两个小模型,编程的时候,只需要对应进行修改就行了
self.encoder = None
self.decoder = None
self.model = None
# 4、将部分变量声明为隐私变量,前置单下划线,私有变量
self._num_conv_layers = len(conv_filters)
# 5、设置build函数,这里是实例化类的时候进行调用
self._build()
# 9、后续添加的变量
self._shape_before_bottleneck = None
# 3.1 添加整体模型的输入,和encoder的输入是相同的
self._model_input = None
# 4.2 损失函数权重
self.reconstruction_weight = 0.5
# 这个方法在三个模块都是需要修改的
def summary(self):
""" 做测试,判定模型是否成功 """
self.encoder.summary()
self.decoder.summary()
self.model.summary()
# 3.2 增加编译函数
def compile(self,learning_rate = 0.0001):
""" 指定损失函数和优化器,并对模型进行优化 """
optimizer = Adam(learning_rate = learning_rate)
self.model.compile(
optimizer = optimizer,
loss = self._calculate_combined_loss,
)
# 3.3 增加训练函数
def train(self,x_train,batch_size,num_epochs):
self.model.fit(
x_train,
x_train,
batch_size = batch_size,
epochs = num_epochs,
shuffle = True
)
# 3.4 模型保存部分
def save(self,save_folder = "."):
""" 保存模型,需要创建文件,分别保存参数和权重"""
self._create_folder_if_not_exist(save_folder)
self._save_parameters(save_folder)
self._save_weights(save_folder)
# 3.5 模型加载部分,这部分要注意,是声明为类方法,不用实例化,直接可以调用
@classmethod
def load(cls,save_folder ="."):
""" 加载模型,包括模型的参数设置和模型的训练权重 """
parameters_path = os.path.join(save_folder,"parameters.pkl")
with open(parameters_path,"rb") as f:
parameters = pickle.load(f)
vae = VAE(*parameters)
weight_path = os.path.join(save_folder,"weights.h5")
vae.load_weights(weight_path)
return vae
def load_weights(self,weight_path):
self.model.load_weights(weight_path)
def reconstruct(self,image):
""" 重建图片,并返回生成之后的图片以及对应的特征空间 """
latent_space = self.encoder.predict(image)
reconstruct_image = self.decoder.predict(latent_space)
return reconstruct_image,latent_space
# 4.2 将两种损失函数进行综合
def _calculate_combined_loss(self,y_target,y_predict):
""" 两个损失函数进行汇总 """
reconstruction_loss = self._calculate_reconstruction_loss(y_target,y_predict)
kl_loss = self._calculate_kl_loss(y_target,y_predict)
combined_loss = self.reconstruction_weight * reconstruction_loss + kl_loss
return combined_loss
# 4.2 损失函数重建
def _calculate_reconstruction_loss(self,y_target,y_predict):
""" 模型重建损失函数,加上了对应alpha """
error = y_predict - y_target
reconstruction_loss = K.mean(K.square(error),axis = [1,2,3]) # 注意,这里只需要返回除了第一个图片序号的后两个维度
return reconstruction_loss
# 4.2 损失函数重建
def _calculate_kl_loss(self,y_target,y_predict):
""" KL散度,用来衡量当前的正态分布和标准正态分布之间的距离"""
kl_loss = -0.5 * K.sum(1 + self.log_variance - K.square(self.mu) - K.exp(self.log_variance),axis=1)
return kl_loss
# 3.4 分别实现上述方法
def _create_folder_if_not_exist(self,save_folder):
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 3.4 分别实现上述方法
def _save_parameters(self,save_folder):
""" 主要是保存模型对应的参数,包括每一层具体的设置 """
parameters = [
self.input_shape ,
self.conv_filters,
self.conv_kernels,
self.conv_strides,
self.latent_space_dim
]
save_path = os.path.join(save_folder,"parameters.pkl")
with open(save_path,"wb") as f:
pickle.dump(parameters,f)
# 3.4 实现save的子方法
def _save_weights(self,save_folder):
save_path = os.path.join(save_folder, "weights.h5")
self.model.save_weights(save_path)
# 6、具体实现相关的方法,这个是总的build函数,需要构建三个模块,分别是encoder、decoder和model
def _build(self):
self._build_encoder()
self._build_decoder()
self._build_VAE()
# 7、从上到下,逐个子方法进行实现
def _build_encoder(self):
# 8、按照网络的层次,将模型串联起来,按照模块进行组装
encoder_input = self._add_encoder_input()
conv_layers = self._add_conv_layers(encoder_input)
bottleneck = self._add_bottleneck(conv_layers)
self._model_input = encoder_input
self.encoder = Model(encoder_input,bottleneck,name="encoder")
# 8、从上到下,按照顺序,逐个实现_build_encoder模块中所有方法
def _add_encoder_input(self):
return Input(shape = self.input_shape,name= "encoder_input")
# 8、从上到下,按照顺序,逐个实现_build_encoder模块中所有方法
def _add_conv_layers(self,encoder_input):
""" 在编码器中增加卷积模块 """
x = encoder_input
# 9、这部分是按照层的顺序逐渐叠加网络层
for layer_index in range(self._num_conv_layers):
# 尽量将自己的模块封装在别的人的模块上
x = self._add_conv_layer(layer_index,x)
return x
# 8、从里到外,完成对应的卷积模块
def _add_conv_layer(self,layer_index,x):
""" 增加卷积模块,每一部分构成如下,conv2d + relu + batch normalization """
layer_num = layer_index + 1
conv_layer = Conv2D(
filters = self.conv_filters[layer_index],
kernel_size = self.conv_kernels[layer_index],
strides = self.conv_strides[layer_index],
padding = "same",
name = f"encoder_conv_layer_{layer_num}"
)
x = conv_layer(x)
x = ReLU(name = f"encoder_relu_{layer_num}")(x)
x = BatchNormalization(name = f"encoder_bn_{layer_num}")(x)
return x
# 8、从上到下,按照顺序,逐个实现_build_encoder模块中所有方法
def _add_bottleneck(self,x):
# 9、第九部分进行编写
# 4.1,如果要将自动编码器转为变分自动编码器,需要实现正态分布,并且能够随机从中选取特定的点
""" 首先将数据展平,然后在传入全链接层 """
self._shape_before_bottleneck = K.int_shape(x)[1:] # [batch_size,height,weight,channel],这里只需要后面三个的大小
x = Flatten()(x)
self.mu = Dense(self.latent_space_dim,name = "mu")(x)
self.log_variance = Dense(self.latent_space_dim,name ="log_variance")(x)
def sample_point_from_normal_distribution(args):
mu,log_variance = args
epsilon = K.random_normal(shape = K.shape(self.mu),mean = 0.,
stddev = 1.)
sample_point = mu + K.exp(log_variance / 2) * epsilon
return sample_point
x = Lambda(sample_point_from_normal_distribution,
name = "encoder_output")([self.mu,self.log_variance])
# x = Dense(self.latent_space_dim,name = "encoder_output")(x)
return x
# 7、从上到下,逐个子方法进行实现
# 2.1 完成解码器的大部分框架
def _build_decoder(self):
""" 创建解码器,输入层、全连阶层、恢复成三维、进行反卷积、输出层 """
decoder_input = self._add_decoder_input()
dense_layer = self._add_dense_layer(decoder_input)
reshape_layer = self._add_reshape_layer(dense_layer)
conv_transpose_layers = self._add_conv_transpose_layers(reshape_layer)
decoder_output = self._add_decoder_output(conv_transpose_layers)
self.decoder = Model(decoder_input,decoder_output,name = "decoder")
# 2.2 具体实现各个子函数,下述函数都是按照顺序完成并实现的
def _add_decoder_input(self):
""" 解码器的输入 """
return Input(shape = self.latent_space_dim,name = "decoder_input")
def _add_dense_layer(self,decoder_input):
""" 解码器的全连阶层,输出数据是二维的,这里并不知道怎么设置??"""
# 这部分设置神经元的数量,和输出的维度而数量相同
num_neurons = np.prod(self._shape_before_bottleneck) # 将数据恢复原始的数据[1,2,4]=>8,现在是将8转成三维的数组
dense_layer = Dense(num_neurons,name = "decoder_dense_layer")(decoder_input)
return dense_layer
def _add_reshape_layer(self,dense_layer):
""" 增加对应的调整形状层,将全链接层的输出,恢复成三维数组 """
# 这里并不知道调用什么层进行设计
reshape_layer = Reshape(self._shape_before_bottleneck)(dense_layer)
return reshape_layer
def _add_conv_transpose_layers(self,x):
""" 增加反卷积模块 """
# 按照相反的顺序遍历所有的卷积层,并且在第一层停下
for layers_index in reversed(range(1,self._num_conv_layers)):
# 理解:原来的卷积层标记[0,1,2],翻转之后的输出为[2,1,0]
x = self._add_conv_transpose_layer(x,layers_index)
return x
def _add_conv_transpose_layer(self,x,layer_index):
# 注意,这里的层序号是按照倒序来的,需要还原成正常序号
# 一个卷积模块:卷积层+ReLu+batchnormalization
layer_num = self._num_conv_layers - layer_index
conv_transpose_layer =Conv2DTranspose(
filters = self.conv_filters[layer_index],
kernel_size = self.conv_kernels[layer_index],
strides = self.conv_strides[layer_index],
padding = "same",
name = f"decoder_conv_transpose_layer_{layer_num}"
)
x = conv_transpose_layer(x)
x =ReLU(name=f"decoder_ReLu_{layer_num}")(x)
x = BatchNormalization(name = f"decoder_BN_{layer_num}")(x)
return x
def _add_decoder_output(self,x):
""" 增加模型的输出层 """
# 这部分要和encoder是一个完全的逆过程,而且之前的反卷积模块是少了最后一层
# ,所以这里需要额外设置一层
conv_transpose_layer = Conv2DTranspose(
filters=1, # filters 对应图片中的channel.最终生成图片是一个[28,28,1]的灰度图片
kernel_size=self.conv_kernels[0],
strides=self.conv_strides[0],
padding="same",
name=f"decoder_conv_transpose_layer_{self._num_conv_layers}"
)
x = conv_transpose_layer(x)
output_layer = Activation("sigmoid",name = "sigmoid_layer")(x)
return output_layer
# 3.1 实现整个模型而自动编码器
# 7、从上到下,逐个子方法进行实现
def _build_VAE(self):
""" 对于自动编码器的识别,链接编码器和解码器 """
model_input = self._model_input
model_output = self.decoder(self.encoder(model_input))
self.model = Model(model_input,model_output,name = "VAE")
if __name__ == '__main__':
VAE = VAE(
input_shape= [28,28,1],
conv_filters = [32,64,64,64],
conv_kernels = [3,3,3,3],
conv_strides= [1, 2, 2, 1],
latent_space_dim=2
)
VAE.summary()
train.py文件实现
- 这部分主要是加载已经提取出来的特征频谱图,同时调用对应的模型进行训练。
load_mnist模块
def load_mnist():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype("float32") / 255
x_train = x_train.reshape(x_train.shape + (1,))
x_test = x_test.astype("float32") / 255
x_test = x_test.reshape(x_test.shape + (1,))
return x_train, y_train, x_test, y_test
- 加载对应的数据集mnist图片,并且将像素点映射到0到255的范围之内,同时在图片的维度之前,再加上一个维度,形成(数据的index,width,height,channel)
train模块
def train(x_train, learning_rate, batch_size, epochs):
autoencoder = VAE(
input_shape=(28, 28, 1),
conv_filters=(32, 64, 64, 64),
conv_kernels=(3, 3, 3, 3),
conv_strides=(1, 2, 2, 1),
latent_space_dim=2
)
autoencoder.summary()
autoencoder.compile(learning_rate)
autoencoder.train(x_train, batch_size, epochs)
return autoencoder
- 这个主要是根据以前的模型制定相关参数,并创建对应的模型,然后开始训练
完整代码
from tensorflow.keras.datasets import mnist
from autoencoder import VAE
LEARNING_RATE = 0.0005
BATCH_SIZE = 32
EPOCHS = 100
def load_mnist():
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype("float32") / 255
x_train = x_train.reshape(x_train.shape + (1,))
x_test = x_test.astype("float32") / 255
x_test = x_test.reshape(x_test.shape + (1,))
return x_train, y_train, x_test, y_test
def train(x_train, learning_rate, batch_size, epochs):
autoencoder = VAE(
input_shape=(28, 28, 1),
conv_filters=(32, 64, 64, 64),
conv_kernels=(3, 3, 3, 3),
conv_strides=(1, 2, 2, 1),
latent_space_dim=2
)
autoencoder.summary()
autoencoder.compile(learning_rate)
autoencoder.train(x_train, batch_size, epochs)
return autoencoder
if __name__ == "__main__":
x_train, _, _, _ = load_mnist()
autoencoder = train(x_train[:10000], LEARNING_RATE, BATCH_SIZE, EPOCHS)
autoencoder.save("model")
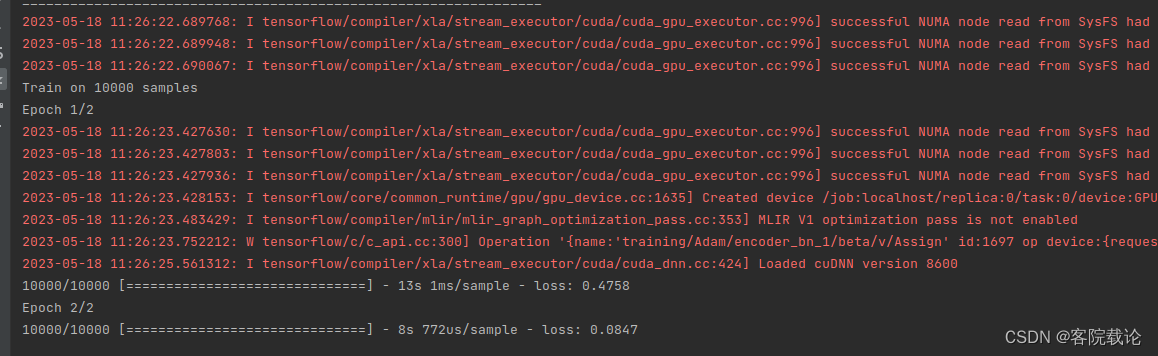
执行效果
总结
- 这部分还是学到了很多东西,至少对于作者的代码编写习惯更加了解。
- 学会了如何将自动编码器修改为变分自动编码器,为了展示,这里将潜在特征空间表示为二维空间,这样便于表示,这里在加上作者写好的analysis代码,可以直观的看到潜在特征空间的分布情况。这里就训练了两个epoch,所以效果比较差,不过还是可以看看的。
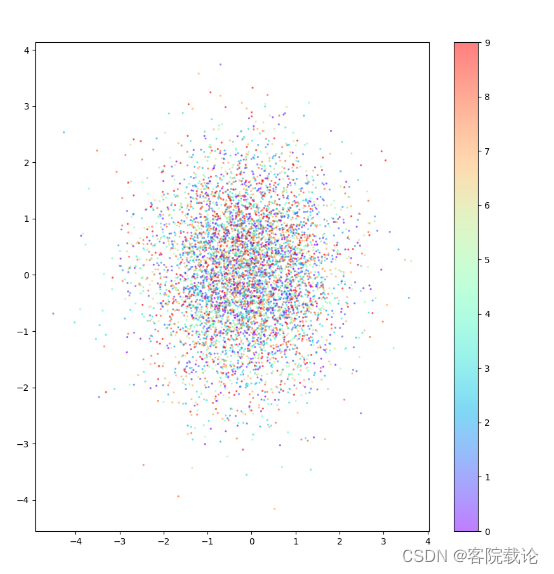
Analysis代码
- 这里就是单纯用来查看特征空间的分布情况,并不需要具体了解具体的功能,这短代码会在特征空间中随机才点,并和原来的图片进行对比,然后在画出特征空间的分布图。
import numpy as np
import matplotlib.pyplot as plt
from vae import VAE
from train import load_mnist
def select_images(images, labels, num_images=10):
sample_images_index = np.random.choice(range(len(images)), num_images)
sample_images = images[sample_images_index]
sample_labels = labels[sample_images_index]
return sample_images, sample_labels
def plot_reconstructed_images(images, reconstructed_images):
fig = plt.figure(figsize=(15, 3))
num_images = len(images)
for i, (image, reconstructed_image) in enumerate(zip(images, reconstructed_images)):
image = image.squeeze()
ax = fig.add_subplot(2, num_images, i + 1)
ax.axis("off")
ax.imshow(image, cmap="gray_r")
reconstructed_image = reconstructed_image.squeeze()
ax = fig.add_subplot(2, num_images, i + num_images + 1)
ax.axis("off")
ax.imshow(reconstructed_image, cmap="gray_r")
plt.show()
def plot_images_encoded_in_latent_space(latent_representations, sample_labels):
plt.figure(figsize=(10, 10))
plt.scatter(latent_representations[:, 0],
latent_representations[:, 1],
cmap="rainbow",
c=sample_labels,
alpha=0.5,
s=2)
plt.colorbar()
plt.show()
if __name__ == "__main__":
autoencoder = VAE.load("Vae/model")
x_train, y_train, x_test, y_test = load_mnist()
num_sample_images_to_show = 8
sample_images, _ = select_images(x_test, y_test, num_sample_images_to_show)
reconstructed_images, _ = autoencoder.reconstruct(sample_images)
plot_reconstructed_images(sample_images, reconstructed_images)
num_images = 6000
sample_images, sample_labels = select_images(x_test, y_test, num_images)
_, latent_representations = autoencoder.reconstruct(sample_images)
plot_images_encoded_in_latent_space(latent_representations, sample_labels)