一. hive概述
1. hive的产生背景
mapreduce程序大部分解决的问题是结构化数据,而解决结构化数据最佳方案是一条sql语句
hive出现的主要原因是解决mapreduce开发成本高的问题。但hive不能完全替代mr,只能处理mr中的结构化数据。
2. hive是什么
hive提供另一种语言用于编写MapReduce程序,即HQL。
Hive的本质是将 SQL 语句转换为 MapReduce 任务运行,所以底层运行的仍然是mapreduce。
hive高度依赖hadoop,业务数据都存储在HDFS上。
3. 数据仓库和数据库的区别
hive是基于hadoop的数据仓库工具。这里对比下数据仓库和数据库的区别
1)应用场景上:
数据仓库:属于olap,即On line Analysis Processing联机分析处理,擅长于数据分析,即query。hive不支持delete、update 支持insert,但效率极低。
数据库:属于oltp,即On line Transaction Processing 联机事务处理,擅长于处理事务,不擅长数据分析。
2)模式上:
数据仓库:数据读取时,会按照表的结构进行数据校验;
数据库:数据写入时,会按照表的结构进行数据校验。
3)事务支持上:数据库有事务概念,数据仓库不支持事务。
4. hive优缺点
优点:延展性强:271个内置函数,并可自定义函数
缺点:
hive不支持delete和update操作;不支持事务;不支持实时查询,适合离线任务。
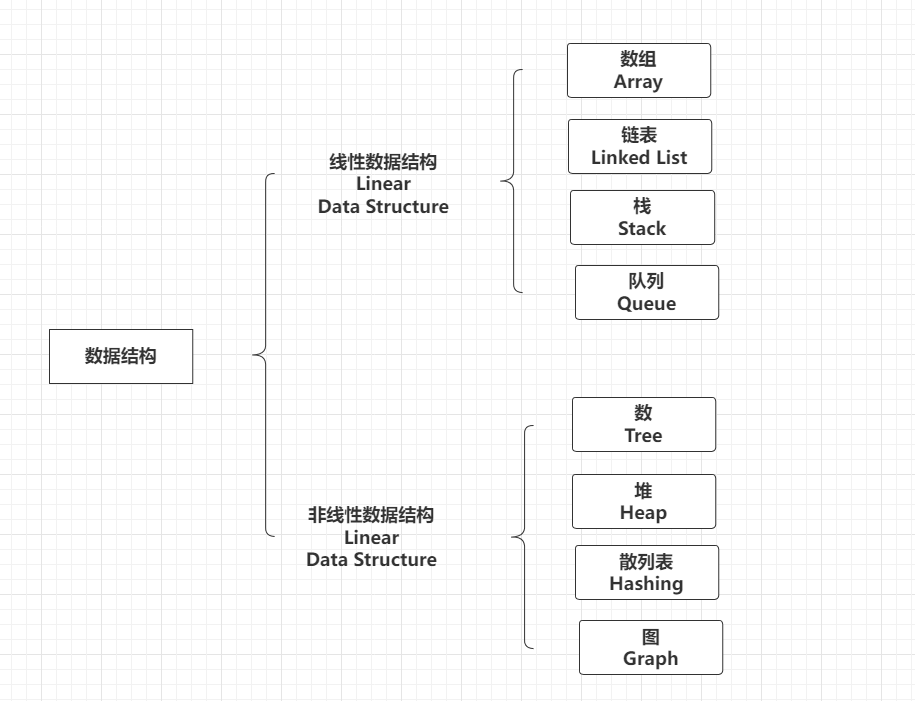
二. Hive 架构
Hive 作为 Hadooop 生态的数据仓库,主要能力是对 HiveQL 进行编译、解析,生成并执行相应的作业。
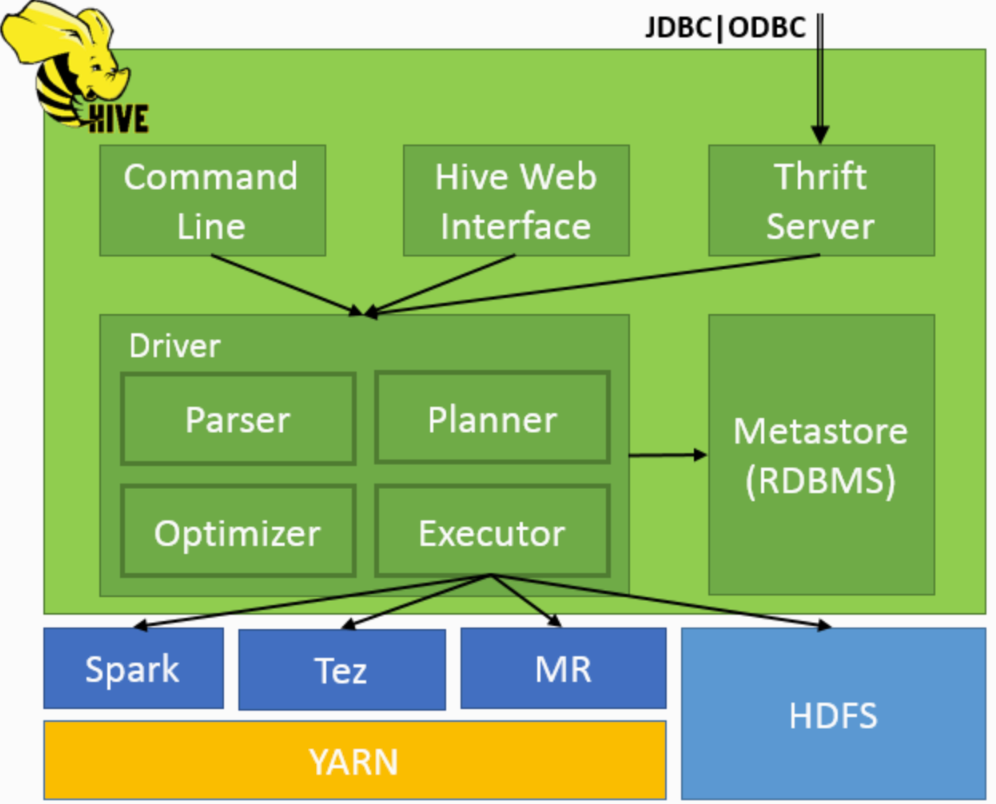
Hive主要由以下四个模块组成:
1.用户接口模块
用来实现对hive的访问,有CLI、HWI、JDBC、Thrift Server等
-
Cli(Command Line Interface):即命令行操作,类似sql
-
web ui(界面基本不用)
-
通过jdbc/odbc进行连接:一般地hive连接:
jdbc:hive2://(hive所在节点的)主机名:10000;
从上面的架构图可以看到,通过JDBC、ODBC连接,先会经过Thrift Server,然后再到Driver;其他通过command line和hive web interface则直接和Driver进行交互。
2. thrift server
即跨语言服务层:它将其他语言(java,c,python)转化为hive可识别的语言可以让不同的编程语言调用Hive的接口。
其中hive提供的Thrift 接口可以让用户通过JDBC连接发送HiveQL请求到thrift接口,然后交由 Driver,最后Thrift将执行结果返回客户端。
3. Driver
Hive执行的核心流程:
解释器:将Hql语句转化为抽象的语法树(提取关键字);
编译器:将抽象语法树编译成mapreduce任务;
优化器:对编译结果进行优化(任务的合并);
执行器:最后由 Executor 执行器进行执行。
4. Meta Store
1)hive元数据可以存储在mysql中。默认元数据存储在一个自带的关系型数据库derby,但因为是单用户企业不适用。
2)hive元数据的储存内容:表数据的字段信息(字段名,字段类型,字段顺序)、表名信息表、以及和hdfs目录对应的关系。
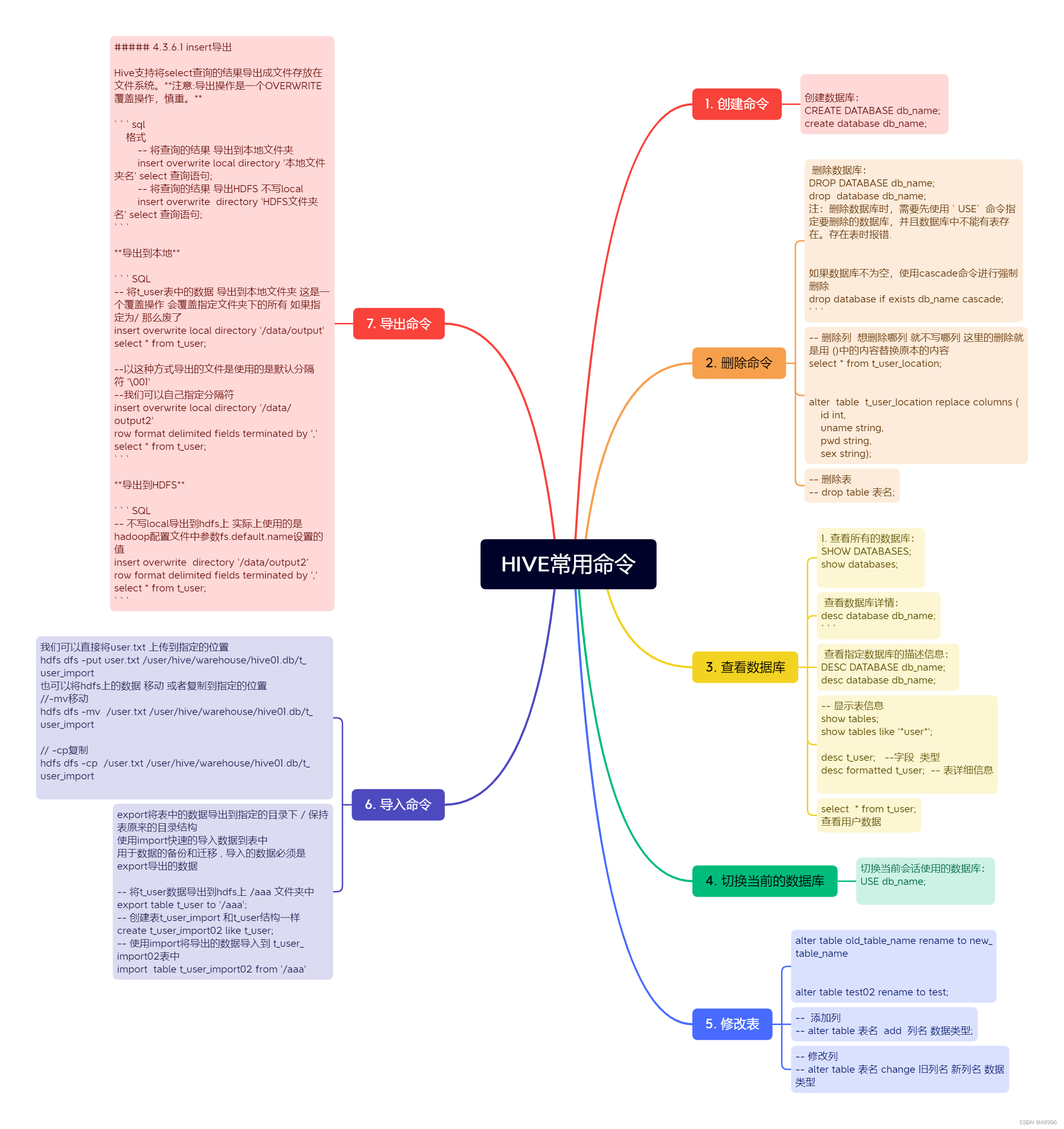
三. hive的知识目录
1.hive的安装、运维等
2.数据类型与文件格式
3.hiveQL的使用:
库表定义、数据操作、数据查询
视图、索引
4. hiveQL函数、自定义函数
5. 模式设计
6. 调优
7. 其他格式和压缩方法
8. 原理:hive的Thrift服务