文章目录
- 前言
- 一、数组
- 二、链表
- 三、栈
- 四、队列
- 五、哈希表--散列表
- 六、堆
- 七、树
- 八、图
- 参考与感谢
前言
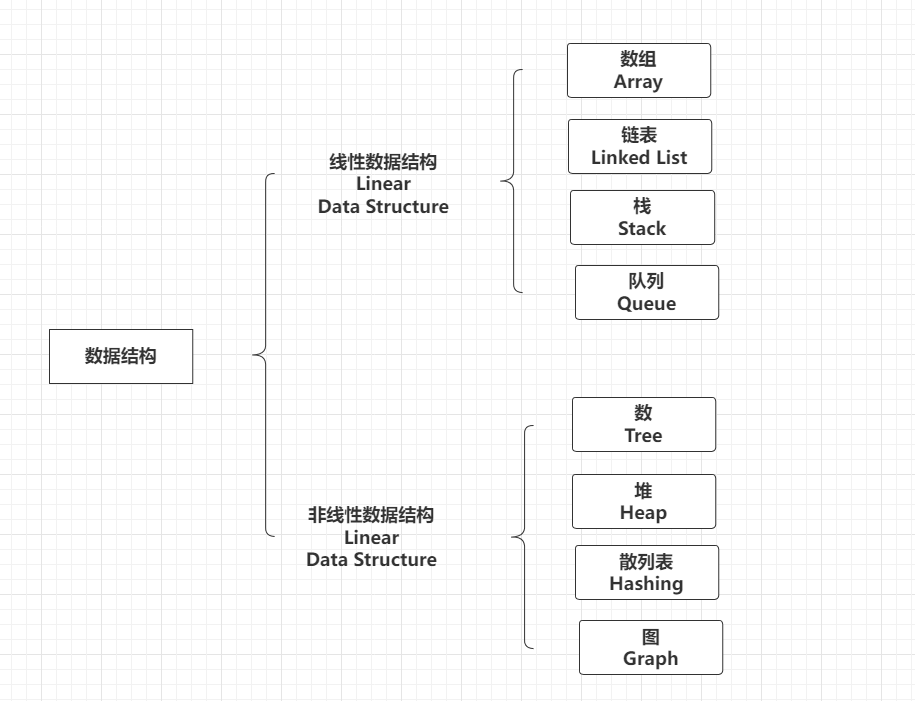
数据结构是计算机存储、组织数据的方式。一种好的数据结构可以带来更高的运行或者存储效率。数据在内存中是呈线性排列的,但是我们可以使用指针等道具,构造出类似“树形”的复杂结构。下面介绍八个常见的数据结构。
一、数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
详细请看我之前写的文章
- 线性表–数组
二、链表
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。
详细请看我之前写的文章
- 什么是链表?并用代码手动实现一个单向链表
- 单向循环链表(增加元素、删除元素、打印循环链表等功能)
- 什么是双向链表?并用代码手动实现一个双向链表
- 什么是双向循环链表?以及实现过程
三、栈
栈也是一种数据呈线性排列的数据结构,不过在这种结构中,我们只能访问最新添加的数
据。从栈顶放入元素的操作叫入栈,取出元素叫出栈。
详细请看我之前写的文章
- 数据结构与算法学习——栈结构
四、队列
队列中的添加和删除数据的操作分别是在两端进行的。队列可以在一端添加元素,在另一端取出元素,也就是:先进先出(First In First Out,简称FIFO)
详细请看我之前写的文章
- 线性表–栈和队列(Stack & Queue)【详解】
五、哈希表–散列表
哈希表,也叫散列表,是根据关键码和值 (key和value) 直接进行访问的数据结构,通过key和value来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素。例如,下列键(key)为人名,value为性别。
详细请看我之前写的文章
- 散列表(哈希表)
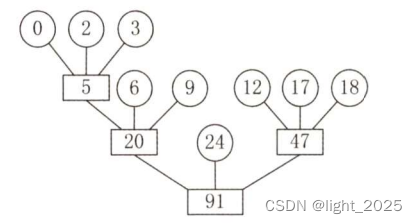
六、堆
堆是一种图的树形结构,被用于实现“优先队列”(priority queues)。优先队列是一种数据结构,可以自由添加数据,但取出数据时要从最小值开始按顺序取出。在堆的树形结构中,各个顶点被称为“结点”(node),数据就存储在这些结点中。
详细请看我之前写的文章
- 【数据结构】堆
七、树
它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
详细请看我之前写的文章
- 树(Tree)【详解】
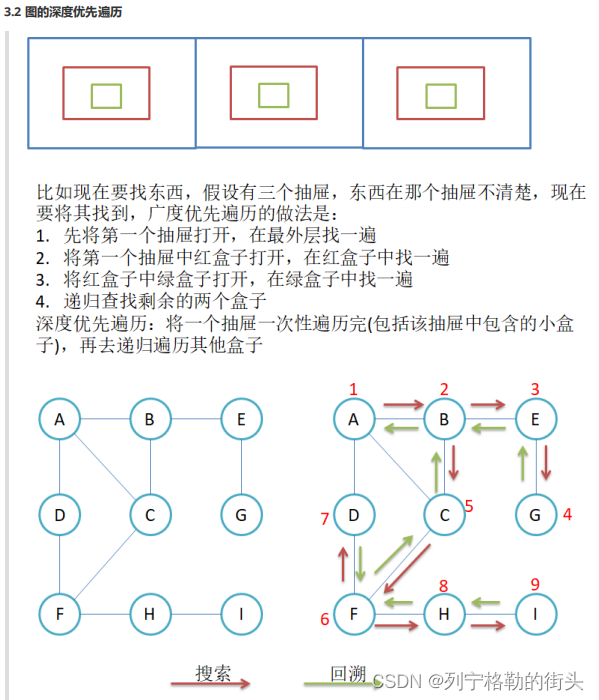
八、图
图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
详细请看我之前写的文章
- 图(Graph)【详解】
参考与感谢
- 《我的第一本算法书》