说明:机器学习总结
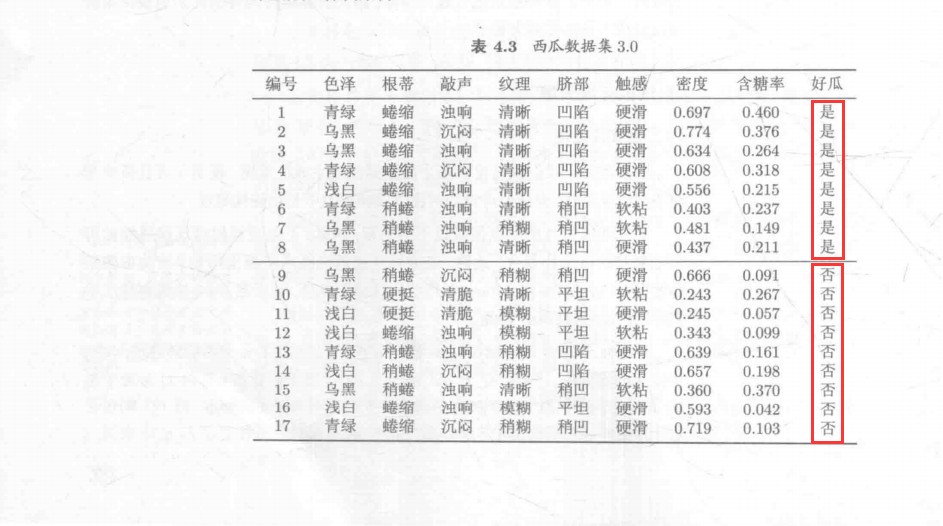
0、数据集
1、贝叶斯分类器
(一)计算题
所有样本分为两类(c ):好瓜=是、好瓜=否
(1)计算先验概率:P(c )
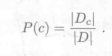
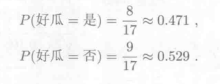
(2)计算每个属性的条件概率:P(xi | c)
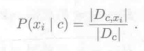

(3)代入朴素贝叶斯公式:
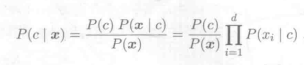

(4)结论:

(5)拉普拉斯修正(平滑处理,可选)
上面的公式中出现连乘现象,这会导致对于0特别敏感,比如出现一个0,就会直接导致最终结果直接为0

其中:
N——所有类别数,这里一个有两类,所以N=2
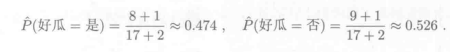
Ni——第i个属性可能的取值数,也就是某个属性的取值可能有多少个

(二)概念题
(1)EM算法
EM算法是一种
迭代式的、常用的估计参数隐变量的方法,常用于高斯混合模型参数的学习。
``
E步:期望步,利用当前估计的参数值,来计算对数似然的期望值,用作下一步的输入。
M步:最大化步,寻找能够使得似然期望最大化的参数值
然后不断迭代,直到达到终止条件。
不断迭代,E步的值不断用于M步。
2、SVM支持向量机(Support Vector Machine)
是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
使用的是最优化方法的相关理论,所以通过引入【
松弛变量】的方法克服过拟合。
支持向量机的求解通常是借助于凸优化技术,如何提高效率,使SVM能适用于大规模数据一直是研究重点.
对线性核SVM已有很多成果,例如基于割平面法(cutting plane algorithm)的 SVMperf具有线性复杂度
基于随机梯度下降的 Pegasos速度甚至更快,而坐标下降法则在稀疏数据上有很高的效率。
3、决策树
(一)计算题
(1)计算【色泽】这个属性的信息熵:Ent
公式比较好记:类别累加
比如二分类任务(只有两个类比,比如好瓜=是、好瓜=否)
核心公式:
好瓜比例*log(好瓜比例) + 坏瓜比例*log(坏瓜比例)
别忘取负值
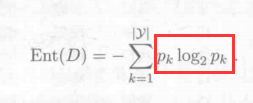
总体的信息熵:

各个属性的信息熵:

(2)计算信息增益:Gain
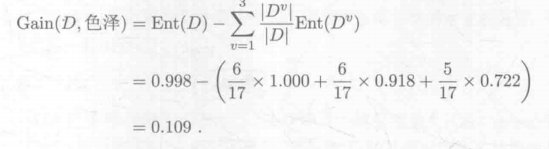
(3)计算其他信息增益,比较得出结点应该是哪一个:
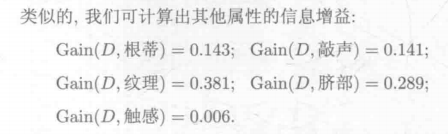

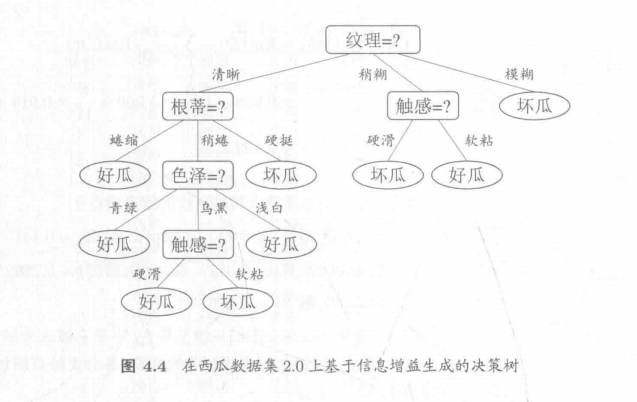
随后,忽略已经确定为结点的属性(比如纹理已经确定)
再依次以纹理下面的数据集为基础计算,从而确定下一个结点应该用哪一个属性

(二)概念题
(1)决策树优化
决策树是一种强大而灵活的机器学习算法。尽管它有一些局限性,但通过剪枝、集成方法、选择合适的决策树变种,可以在很大程度上克服这些缺点。
剪枝(Pruning):剪枝是为了防止决策树
过拟合的一种常用技术。剪枝的过程是在决策树生成后,对其进行简化。主要有预剪枝和后剪枝两种方法。
预剪枝是在生成决策树的过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点。
后剪枝则是先从训练集生成一颗完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能提高决策树的泛化性能,则将该子树替换为叶节点。
随机森林(Random Forest):随机森林是由
多个决策树组成的集成模型。在训练时,随机森林会随机抽取样本和特征来生成多个决策树,然后通过投票或平均的方式集成各个决策树的预测结果。这种方法能够显著提高模型的泛化性能,并且能够提供特征的重要性评估。
决策树的变种:如CART(Classification and Regression Tree)、ID3、C4.5、C5.0等都是决策树的不同变种,它们在特征选择、树的生成和剪枝等方面有所不同,适用于不同的场景。
4、集成学习
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类:
个体学习器间存在强依赖关系、必须串行生成的序列化方法,
个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表是
Boosting,Boosting族算法最著名的代表是AdaBoost
后者的代表是Bagging和“随机森林”(Random Forest).
1、
Boosting是一族可将弱学习器提升为强学习器的算法,一种串行集成学习策略,Boosting中的每个模型都试图纠正其前一个模型的错误。
这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合.
Boosting族算法最著名的代表是AdaBoost,还有梯度提升(Gradient Boosting)和XGBoost等。
·
个人理解:串行学习策略:每一个模型都试图纠正其前一个模型的错误,所以形成了依赖、串行的形式
2、
Bagging(自举汇聚法):Bagging是并行集成学习的一种策略。它通过在原始数据上使用自举样本(即带有替换的随机样本)训练多个基模型,并将它们的预测结果进行投票(分类问题)或平均(回归问题)来提高预测性能。随机森林是最常用的Bagging算法。
·
个人理解:随机森林是决策树的 集成,树是并行的。并行的方式最后需要一个汇总,也就是投票或者平均。
5、关联规则
(一)计算题
(1)关联规则XY的支持度support、置信度Confidence
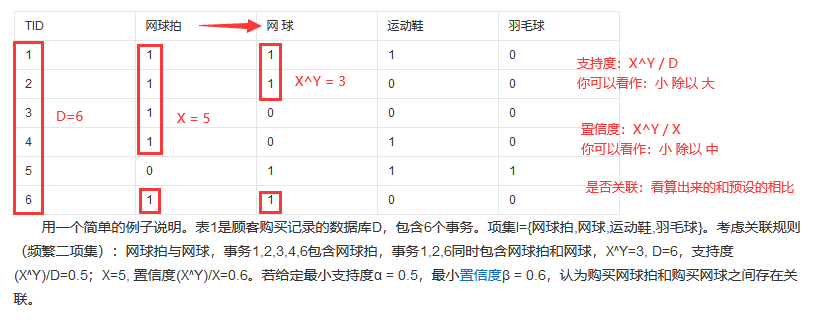 因为支持度本身就是出现频率(分母都是D),所以一般可以直接从图中直接看出来。
因为支持度本身就是出现频率(分母都是D),所以一般可以直接从图中直接看出来。
而支持度是跟【频繁项集】判断相关。
置信度跟【强关联规则】判断相关
(二)概念题
(1)Apriori算法:
假设有一个超市,这个超市正在尝试了解哪些产品经常被一起购买,以便于可以更好地放置产品,或者提供优惠以增加销售。他们拥有以下五笔购物数据(事务):
{牛奶, 鸡蛋, 面包}
{牛奶, 面包, 黄油}
{面包, 鸡蛋}
{牛奶, 鸡蛋, 黄油}
{面包, 黄油}
现在,他们想找出最常被一起购买的商品对。Apriori算法就可以用来解决这个问题。
为了简化,我们这里设最小支持度(即最小频繁度)为2。
-------------------------------------------------------------
步骤1:首先,我们从k=1,也就是单项集开始考虑
我们计算所有单个商品的支持度(在所有事务中出现的次数)。得到的结果如下:
牛奶: 3
鸡蛋: 3
面包: 4
黄油: 3
这些都大于我们的最小支持度2,所以都是频繁项集。
-------------------------------------------------------------
步骤2:我们生成候选的2-项集,并计算他们的支持度(X且Y同时出现的次数,也就是频率)。
{牛奶, 鸡蛋}: 2
{牛奶, 面包}: 2
{牛奶, 黄油}: 2
{鸡蛋, 面包}: 2
{鸡蛋, 黄油}: 1
{面包, 黄油}: 2
{鸡蛋, 黄油}的支持度低于我们设定的最小支持度2,因此我们将其剔除。
-------------------------------------------------------------
步骤3:然后我们会根据2-项集生成3-项集,但在这个例子中所有的3-项集在事务中的出现次数都小于最小支持度2,
所以都被剔除。具体过程如下:
在上一步,我们找出了所有支持度大于等于2的2-项集,分别是:
{牛奶, 鸡蛋}
{牛奶, 面包}
{牛奶, 黄油}
{鸡蛋, 面包}
{面包, 黄油}
现在,我们来生成可能的3-项集。这里我们会使用到Apriori的一个重要性质:如果一个项集是频繁的,那么它的所有子集也必须是频繁的。这意味着,如果一个3-项集是频繁的,那么它的所有2-项子集也必须是频繁的。
在生成3-项集的过程中,我们只需要将两个有公共元素的2-项集合并,然后检查生成的3-项集的所有2-项子集是否都在我们的频繁2-项集中。
下面是所有可能的3-项集及其支持度:
{牛奶, 鸡蛋, 面包}: 1
{牛奶, 鸡蛋, 黄油}: 1
{牛奶, 面包, 黄油}: 1
{鸡蛋, 面包, 黄油}: 0
可以看到,所有的3-项集的支持度都小于最小支持度2,因此没有频繁的3-项集。
所以,在这个例子中,最常被一起购买的商品对仍然是:{牛奶, 鸡蛋}、{牛奶, 面包}、{牛奶, 黄油}、{鸡蛋, 面包}和{面包, 黄油}。
所以,最常被一起购买的商品对(k>=2)是:
{牛奶, 鸡蛋}、
{牛奶, 面包}、
{牛奶, 黄油}、
{鸡蛋, 面包}、
{面包, 黄油}。
这就是Apriori算法在市场篮子分析中的一个简单例子。
Apriori算法是一种用于发现频繁项集的经典关联规则挖掘算法。它基于一种称为"Apriori原理"的观念,该原理认为在一个
频繁项集中的任何子集都必须是频繁的。Apriori算法通过迭代的方式逐步生成频繁项集,从而发现数据集中的关联规则。
以下是Apriori算法的步骤:
1、初始化:首先,算法扫描数据集,确定所有单个项的支持度(出现频率)。然后,根据一个预设的最小支持度阈值,筛选出满足支持度要求的频繁1项集。
2、生成候选项集:根据频繁k-1项集生成候选k项集。具体而言,算法通过连接操作将频繁k-1项集的项组合起来,生成候选k项集。
3、剪枝步骤:在生成的候选k项集中,删除不满足"Apriori原理"的项集。即,如果一个候选项集的任何k-1项子集不是频繁k-1项集,则该候选项集也不会是频繁k项集。
4、计算支持度:对于剪枝后的候选k项集,算法重新扫描数据集,计算每个候选项集的支持度。
5、筛选频繁项集:根据预设的最小支持度阈值,筛选出满足支持度要求的频繁k项集。这些频繁k项集将成为下一轮迭代的基础,用于生成候选k+1项集。
重复步骤2至步骤5,直到没有更多的频繁项集生成。在每一轮迭代中,Apriori算法逐步生成更高阶的频繁项集,直到无法生成更多的频繁项集为止。
通过这些步骤,Apriori算法能够发现频繁项集,并基于频繁项集构建关联规则,
其中规则的置信度可以通过支持度进行计算。这些关联规则可以用于分析数据集中的相关性和依赖关系。
项集:最基本的模式是项集,它是指若干个项的集合。
1、支持度相关:频繁项集(简称频集):所有支持度大于最小支持度的项集的集合
2、置信度相关:强关联规则:置信度大于最小置信度的关联规则
首先找出所有的频集,这些项集出现的频繁性至少和预定义的
最小支持度一样。
然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。
·
然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义。
一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。为了生成所有频集,使用了递归的方法。
6、聚类
(1)K-means聚类算法的工作原理
假设我们有一组二维点(即每个点有两个属性或特征),如下:
(1, 1)
(1.5,2)
(3, 4)
(5, 7)
(3.5,5)
(4.5,5)
(3.5,4.5)
我们想把这些点聚为两类。以下是K-means算法的执行步骤:
步骤1:初始化(聚类中心,也就是【质心】)
首先,我们随机选择两个点作为初始的聚类中心。假设我们选择点1(1,1)和点4(5,7)作为初始的聚类中心。
---------------------------------------------------------------------
步骤2:分配点到最近的聚类中心
我们计算每个点到两个聚类中心的距离,并把每个点分配到最近的聚类中心。计算距离的常用方式是欧氏距离。现在我们得到两个聚类:
聚类1(中心点为1):(1,1), (1.5,2)
聚类2(中心点为4):(3,4), (5,7), (3.5,5), (4.5,5), (3.5,4.5)
具体步骤:
我们有两个聚类中心,分别是点1(1,1)和点4(5,7)。
接下来我们将计算每个点到这两个聚类中心的距离,
并将它们分配到最近的聚类中心。
使用欧氏距离公式(高中最简单的两点间距离公式):距离 = sqrt((x2-x1)^2 + (y2-y1)^2)
对于点(1,1):
距离聚类中心1:0(点(1,1)本身就是聚类中心1)
距离聚类中心2:sqrt((5-1)^2 + (7-1)^2) = sqrt(16 + 36) = sqrt(52)
结论:点(1,1)距离聚类中心1更近,所以被分配到聚类1
点(1.5,2):
对于点(1.5,2):
距离聚类中心1:sqrt((1.5-1)^2 + (2-1)^2) = sqrt(0.25 + 1) = sqrt(1.25)
距离聚类中心2:sqrt((5-1.5)^2 + (7-2)^2) = sqrt(3.5^2 + 5^2) = sqrt(12.25 + 25) = sqrt(37.25)
结论:点(1.5,2)距离聚类中心1更近,所以被分配到聚类1
点(3,4):
......
---------------------------------------------------------------------
步骤3:重新计算聚类中心
我们计算每个聚类中所有点的平均值,得到新的聚类中心:
聚类1的新中心点:((1+1.5)/2, (1+2)/2) = (1.25, 1.5)
聚类2的新中心点:((3+5+3.5+4.5+3.5)/5, (4+7+5+5+4.5)/5) = (3.9, 5.1)
---------------------------------------------------------------------
步骤4:重复步骤2和3,直到聚类中心不再变化,或者达到终止条件
我们重复步骤2和3,直到聚类中心不再变化,或者变化很小。在这个例子中,如果我们继续执行算法,聚类中心可能会在下一步变为:
聚类1的新中心点:(1.25, 1.5)
聚类2的新中心点:(4, 5)
最终,我们的结果是两个聚类:
聚类1:(1,1), (1.5,2)
聚类2:(3,4), (5,7), (3.5,5), (4.5,5), (3.5,4.5)
这就是K-means聚类算法的一个简单例子。
7、其他
监督学习:在这种学习模式中,机器学习算法从标记的训练数据中学习,即每个数据样本都有一个相应的标签或结果。例如,一个分类算法会学习从一组数据特征到一个或多个定义的类别标签的映射。
常见的监督学习算法包括线性回归、逻辑回归、决策树、随机森林、支持向量机等。
无监督学习:与监督学习不同,无监督学习算法处理的是未标记的数据。这类算法试图在数据中发现隐藏的结构和关系。
常见的无监督学习算法包括K-means聚类、层次聚类、DBSCAN、主成分分析(PCA)等。









![Midjourney|文心一格prompt教程[Text Prompt(上篇)]:品牌log、App、徽章、插画、头像场景生成,各种风格选择:科技风、运动风](https://img-blog.csdnimg.cn/img_convert/4d06f7942e86e7dde73e717e85ea69c3.png)
