文章目录
- 一、关于mysql表中数据重复
- 二、聚合函数min(id)+not in
- 二、窗口函数row_number()
- 四、补充:常见的窗口函数
一、关于mysql表中数据重复
关于删除mysql表中重复数据问题,本文中给到两种办法:聚合函数、窗口函数row_number()的方法。
(注意:MySQL从8.0开始支持窗口函数)
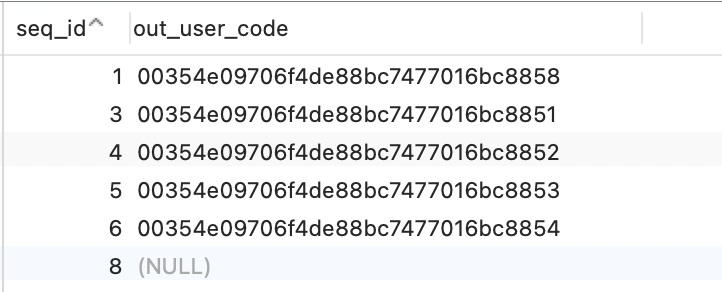
测试数据准备:首先创建一个测试表test,插入一些测试数据,模拟一些重复数据(最终目标:删除重复数据,但不处理null行)

先查询下重复数据,确认待处理数据的数量,然后开始处理:
SELECT
seq_id,
out_user_code,
COUNT( out_user_code ) count
FROM
test
WHERE
is_deleted = 0
AND out_user_code IS NOT NULL
GROUP BY
out_user_code
HAVING
count( out_user_code )> 1

二、聚合函数min(id)+not in
思路:首先通过子查询取出 id 最小的不重复行,然后通过 not in 删除重复数据
1、首先查询一下 id 最小的不重复行(我们留下最早插入的数据,后面的重复数据都删除):
SELECT
min(seq_id) seq_id,
out_user_code,
COUNT( out_user_code ) count
FROM
test
GROUP BY
out_user_code

2、通过查询结果可知,重复的数据行seq_id为2、7的数据过滤掉了,接下来NOT IN 操作应该删除2、7重复数据行。那按照假设想法执行NOT IN:
DELETE from test where r.seq_id not in (
SELECT
min(t.seq_id) seq_id
FROM
test t
GROUP BY
t.out_user_code
) r
会发现报错:
1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'r' at line 8, Time: 0.007000s
原因:不能先select出同一表中的某些值,再update这个表(在同一语句中),即不能依据某字段值做判断再来更新某字段的值。
解决方案:可将SELECT出的结果再通过中间表SELECT一遍。
3、最终处理sql:
DELETE from test where seq_id not in (
SELECT r.seq_id from (
SELECT
min(t.seq_id) seq_id
FROM
test t
GROUP BY
t.out_user_code
) r
) and out_user_code is not null
换种写法(保证相关字段有索引):
DELETE from test
where
out_user_code in (select * from (select out_user_code from test del group by out_user_code HAVING count(out_user_code) >1)a)
and seq_id not in(select * from (select min(seq_id) id from test del group by out_user_code HAVING count(out_user_code) >1)b
)f
提醒:能逻辑删除尽量不要物理删除。
二、窗口函数row_number()
思路:通过 PARTITION BY 对列进行分区排序并生成序号列,然后将序号大于 1 的行删除,row_number() over partition by。
1、分区查询:
SELECT
ROW_NUMBER() OVER ( PARTITION BY out_user_code ORDER BY seq_id ) num,
out_user_code
FROM
test
WHERE
out_user_code IS NOT NULL

知识补充:
1、ROW_NUMBER:对结果集的输出进行编号,是运行查询时计算出的临时值。 具体来说,返回结果集分区内行的序列号,每个分区的第一行从 1 开始。
2、ROW_NUMBER() 具有不确定性。除非以下条件成立,否则不保证在每次执行时,使用 ROW_NUMBER() 的查询所返回行的顺序都完全相同。
1)分区列的值是唯一的。
2)ORDER BY 列的值是唯一的。
3)分区列和 ORDER BY 列的值的组合是唯一的。
2、直接尝试删除num>1的数据:
DELETE a
FROM (
SELECT
ROW_NUMBER() OVER (PARTITION BY out_user_code ORDER BY seq_id) num
FROM test
where out_user_code IS NOT NULL
) a
WHERE num>1
会发现报错:
1288 - The target table a of the DELETE is not updatable, Time: 0.007000s
原因同上,同样的我们换个方式处理一下。给窗口指定别名:WINDOW w AS (PARTITION BY 字段1 ORDER BY 字段2)
3、最终处理sql:
DELETE
FROM test
WHERE seq_id in (
SELECT seq_id
FROM(
SELECT *
FROM (
SELECT ROW_NUMBER() OVER w AS row_num,seq_id
FROM test where out_user_code is not null
WINDOW w AS (PARTITION BY out_user_code ORDER BY seq_id)
)t
WHERE row_num >1
)e
)
四、补充:常见的窗口函数
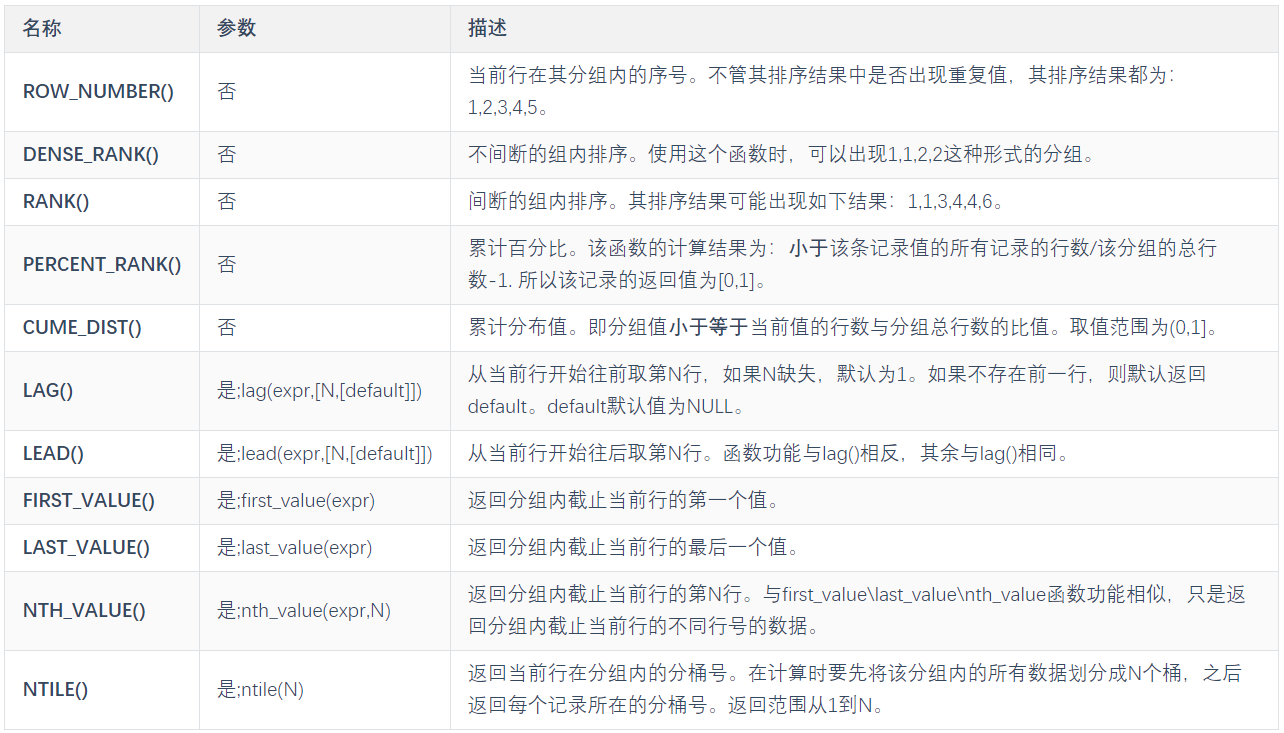
注:‘参数’列说明该函数是否可以加参数。“否”说明该函数的括号内不可以加参数。
expr即可以代表字段,也可以代表在字段上的计算,比如sum(col)等。
窗口函数的一个概念是当前行,当前行属于某个窗口,窗口由over关键字用来指定函数执行的窗口范围,如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,窗口函数基于所有行进行计算;如果不为空,则有三个参数来设置窗口:
- partition by子句:按照指定字段进行分区,两个分区由边界分隔,窗口函数在不同的分区内分别执行,在跨越分区边界时重新初始化。
- order by子句:按照指定字段进行排序,窗口函数将按照排序后的记录顺序进行编号。可以和partition by子句配合使用,也可以单独使用。
- frame子句:当前分区的一个子集,用来定义子集的规则,通常用来作为滑动窗口使用。



![Midjourney|文心一格prompt教程[Text Prompt(上篇)]:品牌log、App、徽章、插画、头像场景生成,各种风格选择:科技风、运动风](https://img-blog.csdnimg.cn/img_convert/4d06f7942e86e7dde73e717e85ea69c3.png)