Part-1部分的博客可见下:
机器学习项目实战-能源利用率 Part-1(数据清洗)
这部分进行的是探索性数据分析。
探索性数据分析
Exploratory Data Analysis
简单的说,就是画图来分析数据。
分析标签数据
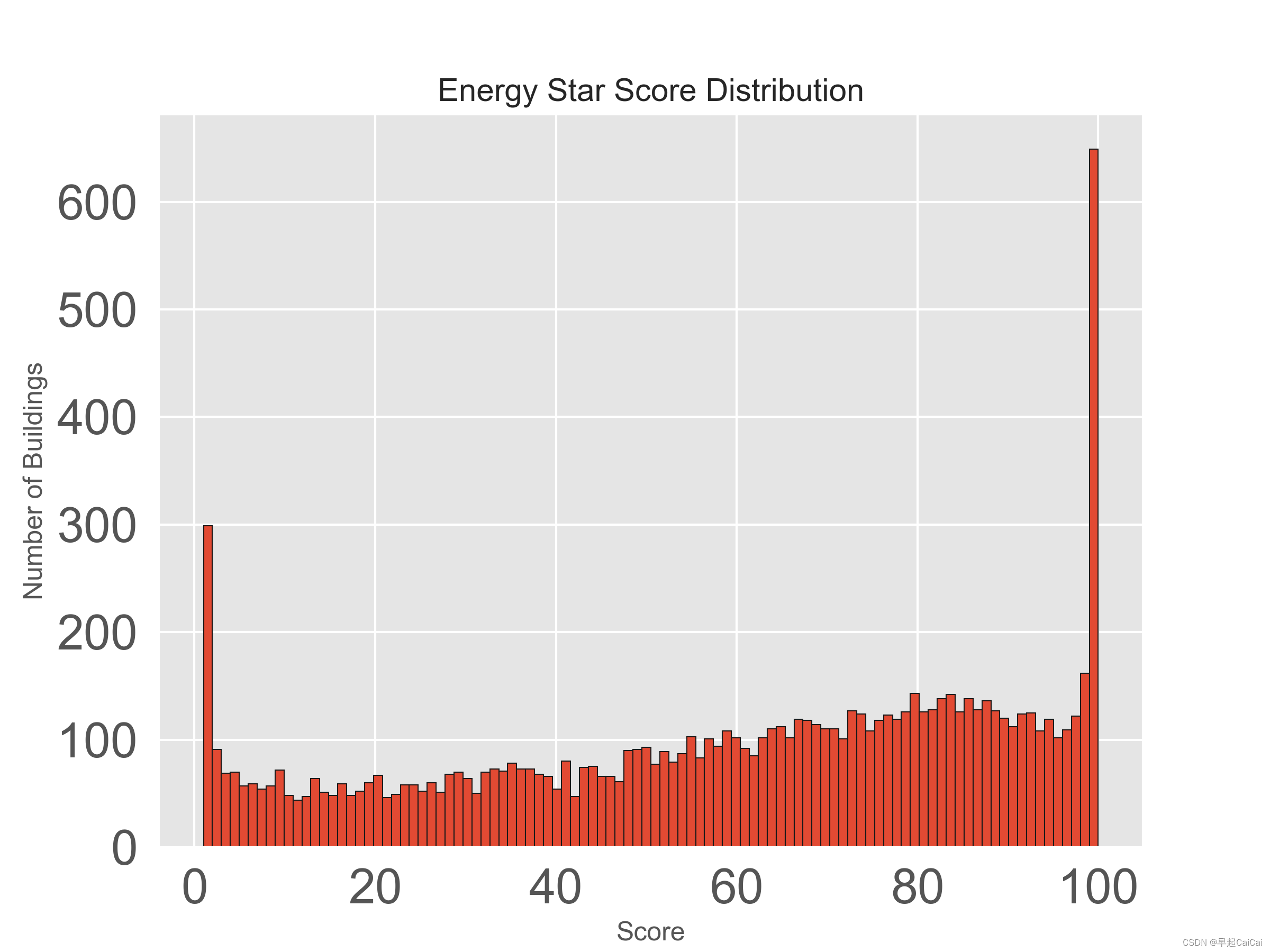
data = data.rename(columns = {'ENERGY STAR Score': 'score'})
plt.figure(figsize = (8, 6))
plt.style.use('ggplot')
plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k')
plt.xlabel('Score'); plt.ylabel('Number of Buildings')
plt.title('Energy Star Score Distribution')
这段代码首先将 data 数据集中名为 'ENERGY STAR Score' 的列重命名为 'score',然后利用 Matplotlib 库绘制了 'score' 列的直方图。在绘制直方图时,使用了 plt.hist() 函数,其中参数 bins 指定了直方图的柱数,edgecolor 指定了柱边缘的颜色。函数 plt.xlabel() 和 plt.ylabel() 分别设置了 x 轴和 y 轴的标签,plt.title() 则设置了直方图的标题。最后,plt.style.use() 函数指定了绘图风格为 'ggplot'。
Site EUI 特征处理
“Site EUI Distribution” 意思是 “场地能源使用强度分布”,通常是指在一个特定的时间段内,一个建筑单位面积(如每平方英尺或每平方米)所消耗的能源的数量。因此,Site EUI Distribution 描述了一组建筑物的能源效率水平,以及这些建筑物的能源消耗分布情况。
plt.style.use('ggplot')
plt.figure(figsize(8, 6))
plt.hist(data['Site EUI (kBtu/ft²)'].dropna(), bins = 20, edgecolor = 'black')
plt.xlabel('Site EUI'); plt.ylabel('Count'); plt.title('Site EUI Distribution')
这段代码使用了matplotlib库绘制一个直方图,展示了数据集中’Site EUI (kBtu/ft²)'这一列的分布情况。具体解释如下:
plt.style.use('ggplot')设置画图风格为’ggplot’风格,这是一种常用的美观风格。plt.figure(figsize(8, 6))创建一个画布对象,大小为8x6英寸。plt.hist(data['Site EUI (kBtu/ft²)'].dropna(), bins = 20, edgecolor = 'black')绘制直方图,data['Site EUI (kBtu/ft²)'].dropna()选择’Site EUI (kBtu/ft²)'这一列的非空值作为数据,bins=20表示将数据分成20个区间,edgecolor='black'表示边界颜色为黑色。plt.xlabel('Site EUI')设置x轴标签为’Site EUI’。plt.ylabel('Count')设置y轴标签为’Count’。plt.title('Site EUI Distribution')设置图表标题为’Site EUI Distribution’。

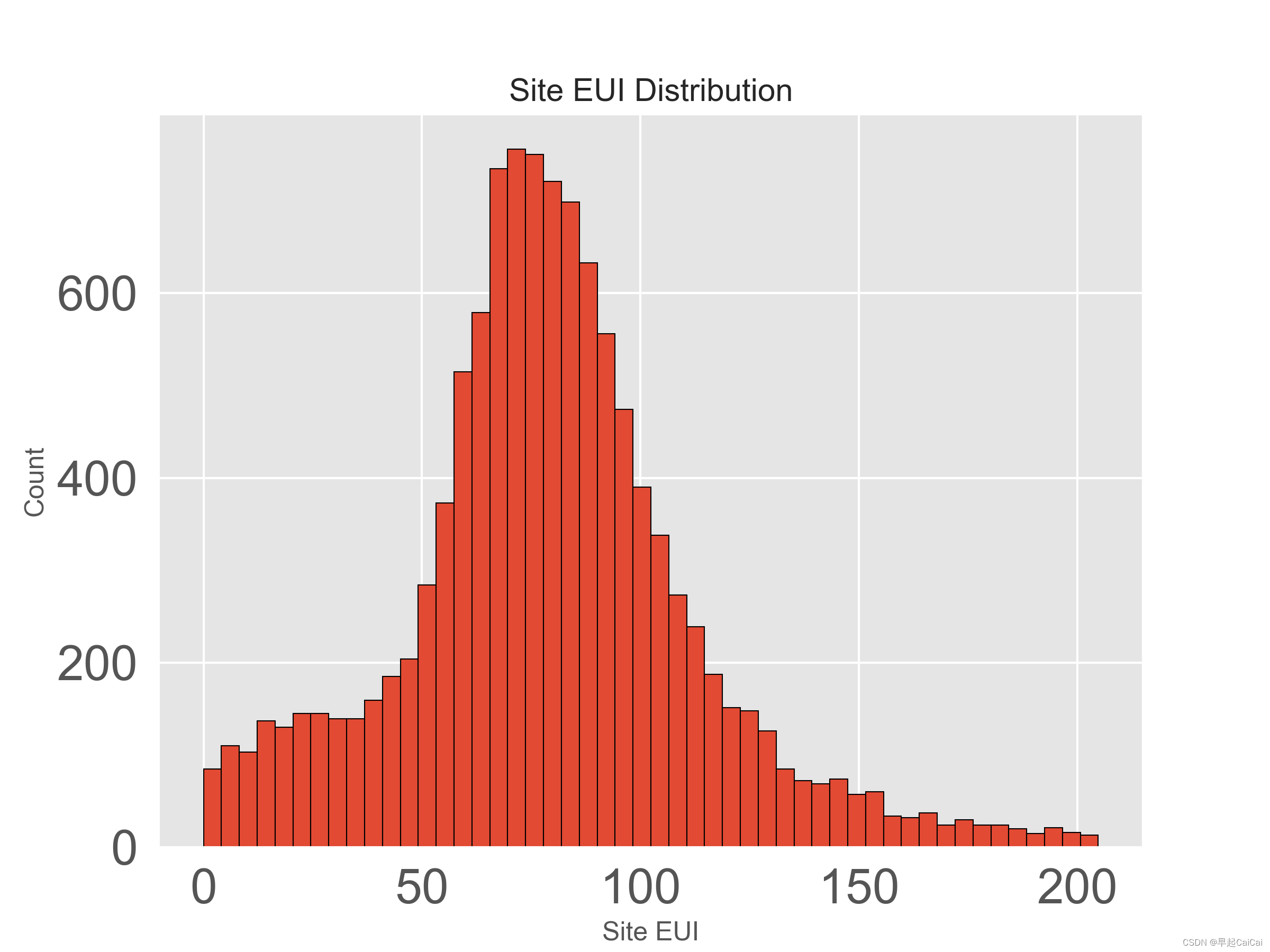
这里面存在着一些特别大的值,这些可能是离群点或记录错误点,对我们结果会有一些影响的。
详细看这个特征
data['Site EUI (kBtu/ft²)'].describe()

看这个特征最大的10个数,的确可以看到分布不均的情况
存在着一些特别大的值,这些可能是离群点或记录错误点,对我们结果会有一些影响的。
data['Site EUI (kBtu/ft²)'].dropna().sort_values().tail(10)

删除离群点
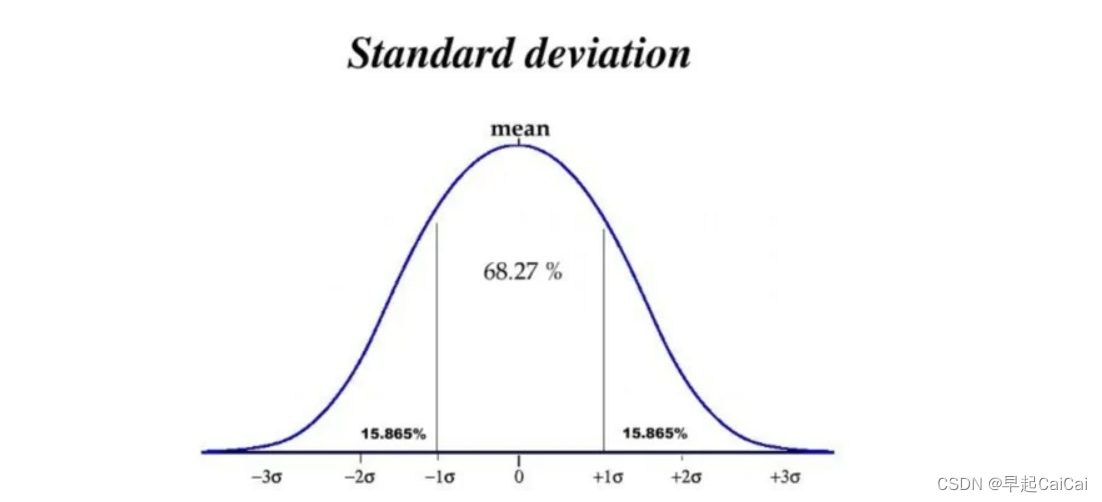
离群点的选择可能需要再斟酌一些,这里选择的方法是extreme outlier。
- First Quartile − 3 ∗ Interquartile Range
- First Quartile + 3 ∗ Interquartile Range
类似于 3Sigma 原理
first_quartile = data['Site EUI (kBtu/ft²)'].describe()['25%']
third_quartile = data['Site EUI (kBtu/ft²)'].describe()['75%']
iqr = third_quartile - first_quartile
data = data[(data['Site EUI (kBtu/ft²)'] > (first_quartile - 3 * iqr)) &
(data[['Site EUI (kBtu/ft²)'] < (third_quartile + 3 * iqr))]
plt.figure(figsize = (8, 6))
plt.hist(data['Site EUI (kBtu/ft²)'].dropna(), bins = 50, edgecolor = 'black')
plt.xlabel('Site EUI'); plt.ylabel('Count'); plt.title('Site EUI Distribution')
这段代码的作用是去除Site EUI(建筑能源使用强度)中的异常值,然后绘制Site EUI分布直方图。首先,通过使用.describe()方法,计算Site EUI列的第一四分位数、第三四分位数和四分位数间距(IQR),其中IQR是上四分位数与下四分位数之间的距离。然后使用这些统计量和3倍的IQR来确定Site EUI的上下界,并筛选掉超出这些边界的行。最后,使用绘图函数.hist()绘制Site EUI的分布直方图,其中直方图的bin数设置为50,边缘颜色为黑色。
分析哪些变量会对结果产生影响
Lput = data.dropna(subset = ['score'])['Largest Property Use Type'].value_counts()
Lput = list(Lput[Lput.values > 80].index)
plt.figure(figsize = (12, 10))
for lput in Lput:
subset = data[data['Largest Property Use Type'] == lput]
sns.kdeplot(subset['score'].dropna(), label = lput, fill = False, alpha = 0.8)
plt.xlabel('Energy Star Score', fontsize = 18)
plt.ylabel('Density', fontsize = 18)
plt.title('Density Plot of Energy Star Scores by Building Type', size = 24)
plt.legend()
这段代码的目的是绘制不同建筑类型的能源之星分数(Energy Star Score)的密度图(Density Plot)。首先,代码使用 value_counts() 方法计算每个最大物业使用类型(Largest Property Use Type)的计数。然后,使用 list() 和条件语句将计数大于80的最大物业使用类型列表存储在变量 Lput 中。接下来,代码使用 Seaborn 库中的 kdeplot() 方法,为 Lput 中的每个最大物业使用类型绘制密度图。最后,代码使用 xlabel()、ylabel() 和 title() 方法为图表添加轴标签和标题。
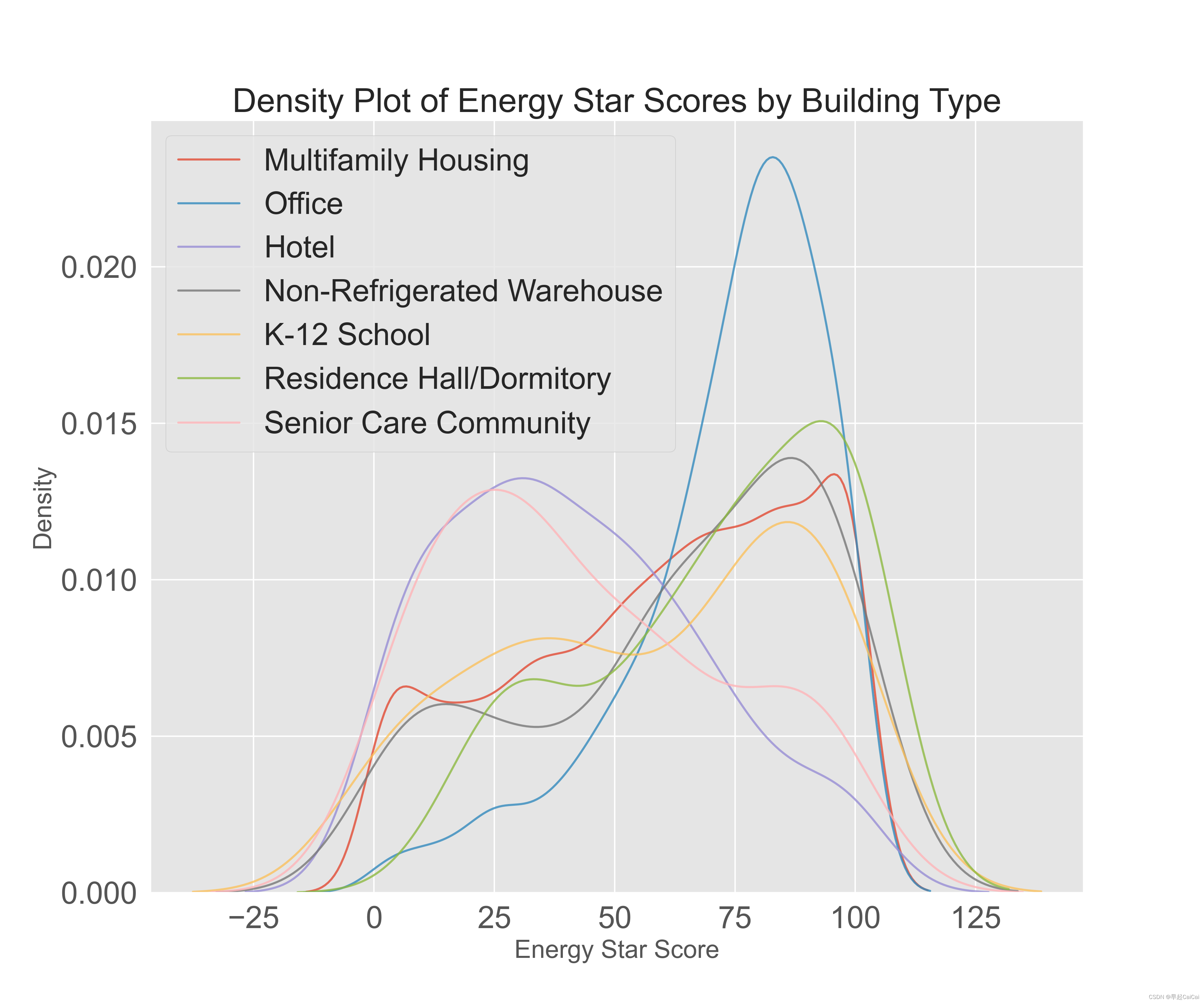
上图分析(横坐标是Energy Star Score的分布,纵坐标是密度的分布),不同类型的建筑看起来对结果的影响是不一样的。这个变量对我们后续的分析很有帮助
boroughs = data.dropna(subset = ['score'])['Borough'].value_counts()
boroughs = list(boroughs[boroughs.values > 150].index)
plt.figure(figsize = (12, 10))
for borough in boroughs:
subset = data[data['Borough'] == borough]
sns.kdeplot(subset['score'].dropna(), label = borough)
plt.xlabel('Energy Star Score', fontsize = 18)
plt.ylabel('Density', fontsize = 18)
plt.title('Density Plot of Energy Star Scores by Borough', fontsize = 24)
plt.legend()
这段代码的主要目的是为了可视化不同区域(Borough)建筑物的能源星级得分(Energy Star Score)的分布情况。首先,代码通过dropna()方法删除得分为空的数据行,然后使用value_counts()方法统计每个区域的建筑物数量,并且只保留建筑物数量超过150个的区域,这些区域将被视为绘制分布图的目标区域。接下来,代码循环遍历目标区域列表boroughs,并从数据中选择相应区域的子集,使用kdeplot()方法绘制能源星级得分的密度曲线,并在曲线旁边标注区域名称。最后,通过设置横纵坐标标签和标题,以及添加图例来完善可视化效果。
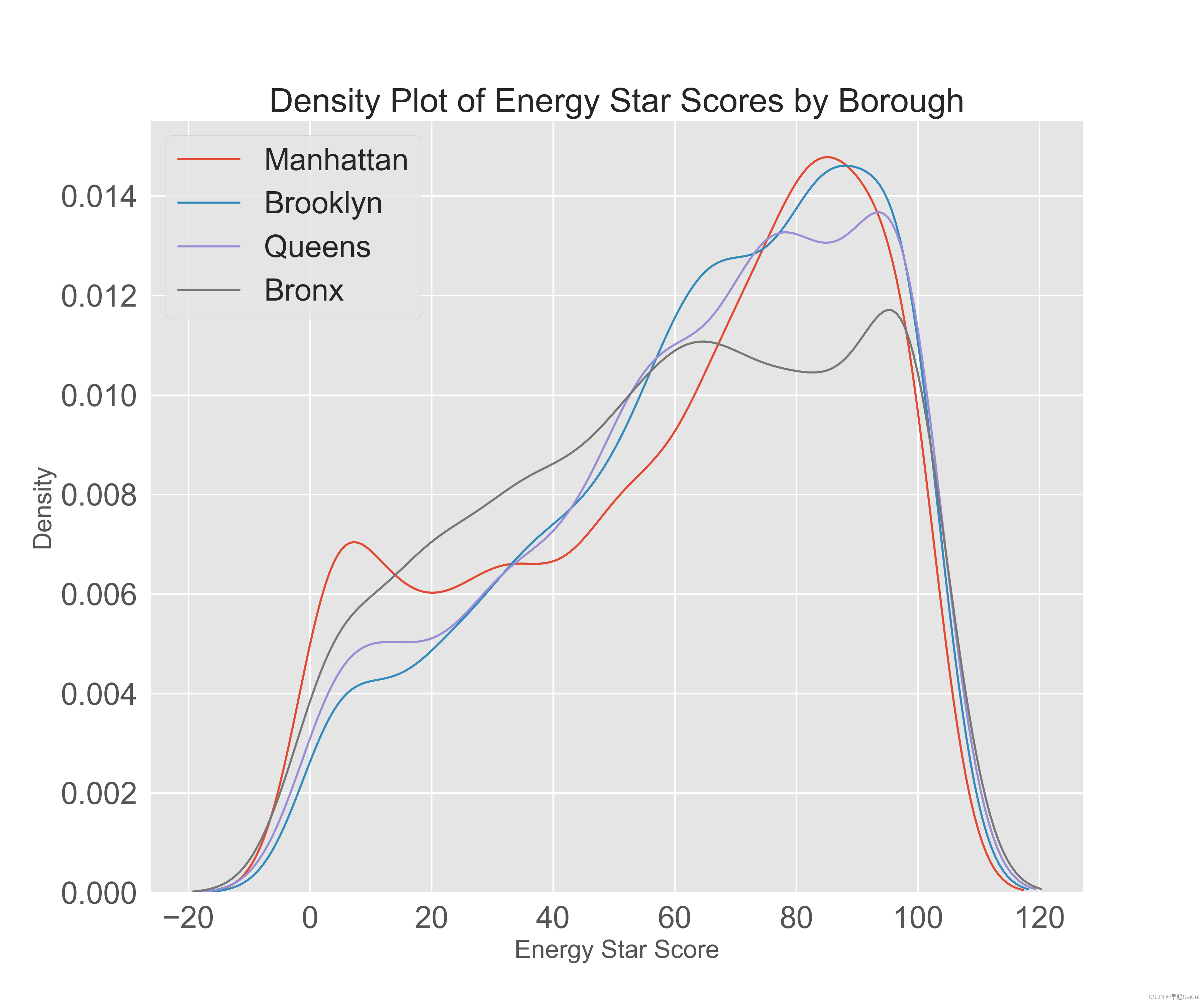
对于镇区这个特征来说看起来影响就不大,因为这几条线都差不多
分析特征之间的相关性
可以根据相关系数,帮助我们来筛选特征
下面这个图,就非常经典
corr_data = data.corr()['score'].sort_values()
print(corr_data.head(15), '\n')
print(corr_data.tail(15))
分别去看相关性最高的15个参数,以及相干性最小的15个参数

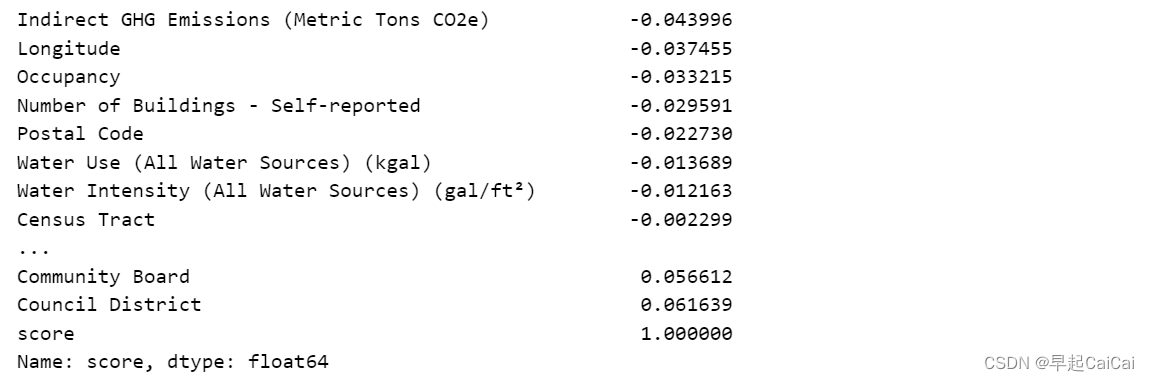
Site EUI (kBtu/ft²)和Weather Normalized Site EUI (kBtu/ft²)呈现出明显的负相关,单位用电量越多,能源利用得分越低。
Site EUI (kBtu/ft²)表示建筑物的能源使用效率,即每平方英尺建筑面积每年消耗的能源量。这个指标以能源使用强度 (energy intensity) 的形式表示,以单位面积每年消耗的热量 (kBtu/ft²/yr) 表示。这个指标可以用于比较不同建筑之间的能源使用情况,以及评估建筑的能源效率。
Weather Normalized Site EUI (Energy Use Intensity)是指建筑物的能源消耗强度,以每平方英尺的建筑面积为单位,并考虑了当地气象条件对能耗的影响。 Weather Normalized Site EUI使用美国能源管理局的Weather Normalized Energy Consumption Index(NECI)来对建筑物进行标准化,以便比较不同地点和时间段的能耗数据,同时消除天气对能耗的影响。
还需要在考虑下非线性变换的特征,比如平方,log等等,都可以来试试,对于类别变量还可以用one-hot encode来转换下。
特征变换与 one-hot encode
numeric_subset = data.select_dtypes('number') # 选择数值型列
for col in numeric_subset.columns: # 对数值型列开平方根和对数, 创建新的列
if col == 'score':
next
else:
numeric_subset['sqrt_' + col] = np.sqrt(abs(numeric_subset[col])+0.01)
numeric_subset['log_' + col] = np.log(abs(numeric_subset[col])+0.01)
categorical_subset = data[['Borough', 'Largest Property Use Type']] # 选择类别型列
categorical_subset = pd.get_dummies(categorical_subset) # One hot encode
features = pd.concat([numeric_subset, categorical_subset], axis = 1) # concat两个类型数据
features = features.dropna(subset = ['score']) # 删除标签列中的缺失值行
correlations = features.corr()['score'].dropna().sort_values() # 标签的相关系数
print(correlations.head(15))
print(correlations.tail(15))
这段代码实现了以下几个功能,代码解释见下:
- 从数据中选择数值型列,并对每一列进行开平方根和对数的操作,创建新的列。
- 从数据中选择类别型列,并进行 One hot encode 操作,将每个类别转化为一个新的二元列。
- 将上述两个处理后的数据合并为一个数据集。
- 删除标签列中的缺失值行。
- 计算特征和标签之间的相关系数,并按照相关系数从小到大排序。
其中,最后两行代码分别输出了相关系数最小的前15个和相关系数最大的后15个特征。


双变量绘图
plt.figure(figsize = (12, 10))
features['Largest Property Use Type'] = data.dropna(subset =['score'])['Largest Property Use Type']
# 提取建筑类型特征
features = features[features['Largest Property Use Type'].isin(Lput)]
# Limit to building types with more than 80 observations
sns.lmplot('Site EUI (kBtu/ft²)', 'score', hue = 'Largest Property Use Type',
data = features, scatter_kws = {'alpha':0.7, 's':50}, fit_reg = False,
height = 12, aspect = 1.2)
plt.xlabel('Site EUI', fontsize = 24)
plt.ylabel('Energy Star Score', fontsize = 24)
plt.title('Energy Star Score vs Site EUI', fontsize = 30)
这段代码生成一个散点图,用于观察不同建筑类型的能源利用强度(Site EUI)与能源星级评分(Energy Star Score)之间的关系。其中,features['Largest Property Use Type'] = data.dropna(subset =['score'])['Largest Property Use Type'] 提取了建筑类型这一特征列,features = features[features['Largest Property Use Type'].isin(Lput)] 则用 isin() 方法过滤了建筑类型样本数量大于 80 的建筑类型。最后,sns.lmplot() 方法用于绘制散点图,并指定了 Site EUI 与 Energy Star Score 分别在 x、y 轴上,并用不同颜色的点表示不同建筑类型的数据。scatter_kws 参数用于指定散点图点的透明度(alpha)和大小(s)。fit_reg 参数设为 False,表示不进行线性回归。最后,plt.xlabel(), plt.ylabel(), plt.title() 分别用于指定 x 轴标签、y 轴标签和标题。
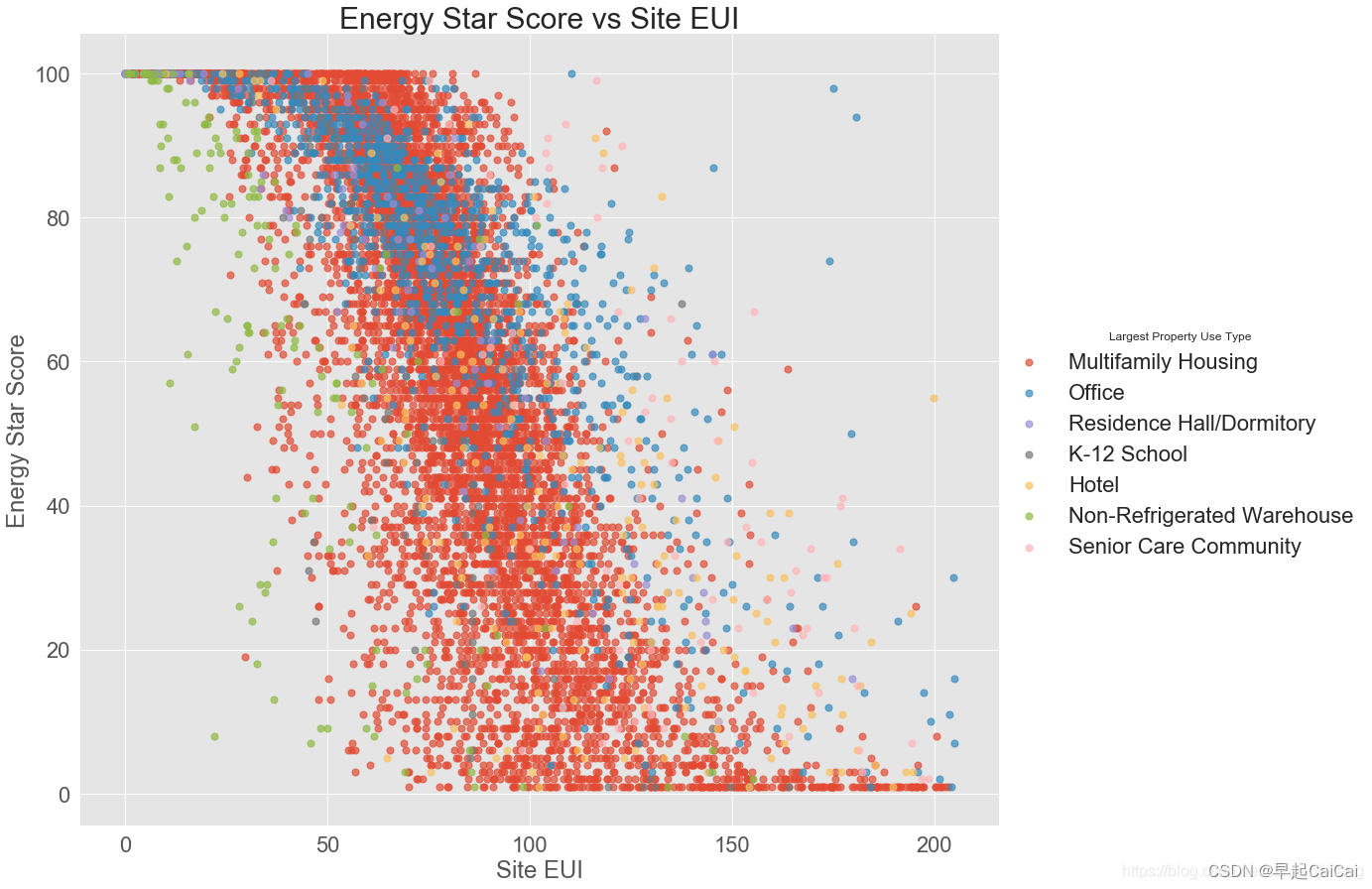
PASS:这个案例有点问题,估计 seaborn 后面改版了
但不影响总的分析
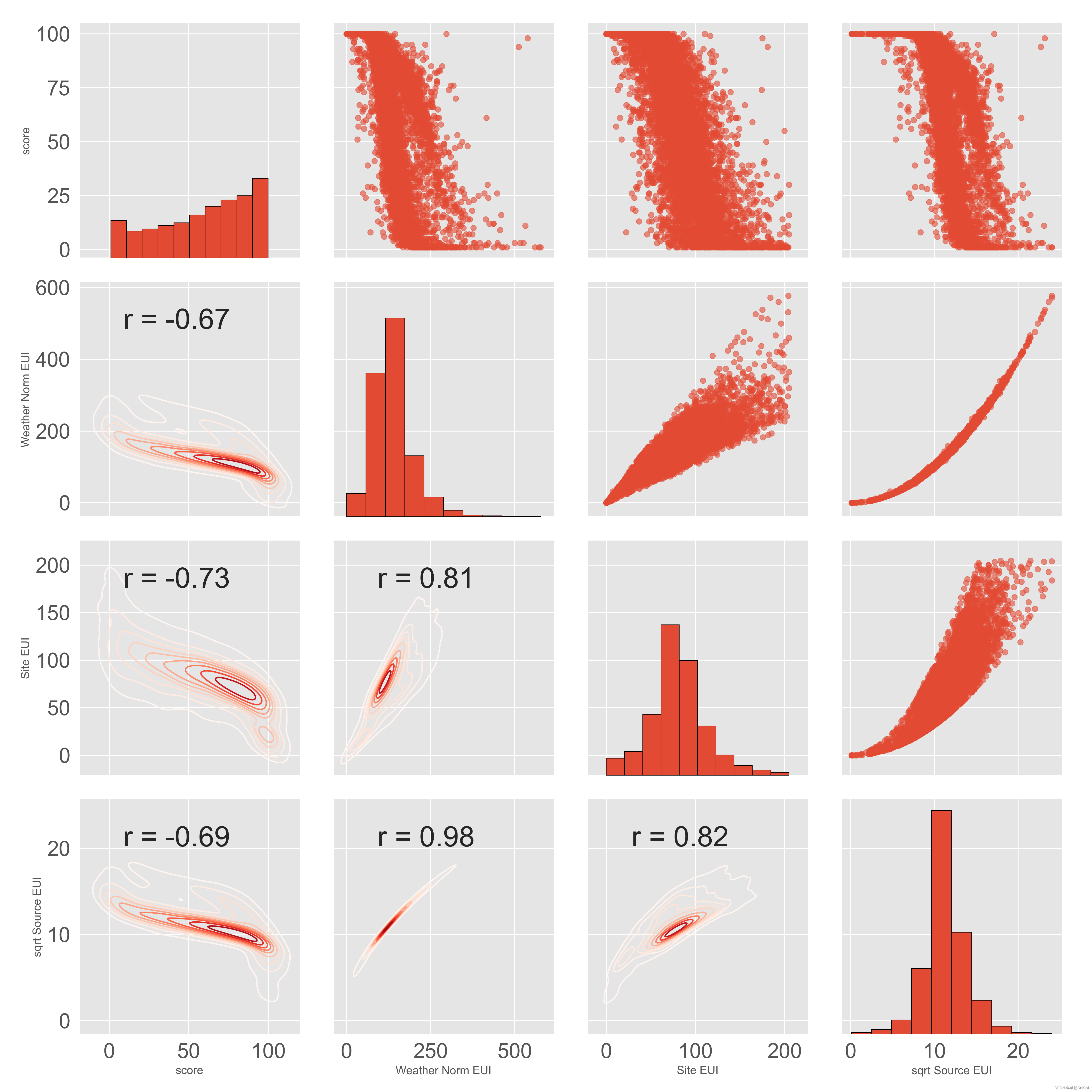
Pairs Plot
plot_data = features[['score', 'Weather Normalized Source EUI (kBtu/ft²)',
'Site EUI (kBtu/ft²)', 'sqrt_Source EUI (kBtu/ft²)']]
plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan}) # 无穷大和负无穷大替换为nan
plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI',
'sqrt_Source EUI (kBtu/ft²)': 'sqrt Source EUI',
'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI'})
plot_data = plot_data.dropna()
def corr_func(x, y, **kwargs):
r = np.corrcoef(x, y)[0][1] # x和y的皮尔逊相关系数
ax = plt.gca()
ax.annotate('r = {:.2f}'.format(r), xy = (.2, .8), xycoords=ax.transAxes, size=30)
grid = sns.PairGrid(data = plot_data, height = 4)
grid.map_upper(plt.scatter, alpha = 0.6)
grid.map_diag(plt.hist, edgecolor = 'black')
grid.map_lower(corr_func)
grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds)
plt.suptitle('Pairs Plot of Energe Data', fontsize = 28, y = 1.05)
这段代码主要进行了以下操作:
- 从数据集中选取了包含四个特征列的子集,并给它们重命名。
- 用replace函数将无穷大和负无穷大替换为NaN。
- 使用dropna函数删除包含NaN值的行。
- 定义了一个名为corr_func的函数,它计算并注释了x和y的Pearson相关系数。
- 使用PairGrid函数创建一个网格,对角线上是直方图,上三角是散点图,下三角是相关系数和核密度估计图。
- 最后,使用suptitle函数添加一个大标题。
该代码的目的是探索能源数据之间的相关性,使用可视化的方式查看四个特征之间的关系。其中PairGrid函数可视化了每个特征对之间的关系,并注释了它们之间的Pearson相关系数,帮助我们快速了解每个特征之间的关系。
Reference
机器学习项目实战-能源利用率 Part-1(数据清洗)
机器学习项目实战-能源利用率1-数据预处理




![[云原生] 破局微服务通信:探索MegaEase服务网格的创新之路](https://img-blog.csdnimg.cn/6e7bd1e4bbbe44fbadb98a8f03969864.png)