文章:M^2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
作者:Enze Xie, Zhiding Yu, Daquan Zhou, Jonah Philion, Anima Anandkumar, Sanja Fidler, Ping Luo, Jose M. Alvarez
编辑:点云PCL
主页:https://xieenze.github.io/projects/m2bev/
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。
公众号致力于点云处理,SLAM,三维视觉,高精地图等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系dianyunpcl@163.com。未经作者允许请勿转载,欢迎各位同学积极分享和交流。
摘要
本文提出了M^2BEV(Multi-Camera Multi-Modal Bird's Eye View)框架,它在多摄像头图像输入的鸟瞰图空间中联合进行3D物体检测和地图分割。与大多数先前的工作单独处理检测和分割不同,M^2BEV使用统一的模型推断两个任务,并提高了效率。M^2BEV将多视角的2D图像特征有效地转换为以自车坐标系为基础的3D鸟瞰图特征,这种鸟瞰图表示很重要,因为它使不同任务能够共享一个编码器,该框架还包含四个重要设计,既提高了准确性又提高了效率:
(1)一种有效的鸟瞰图编码器设计,减小了体素特征图的空间维度。
(2)一种动态框分配策略,使用学习匹配来将真值3D框分配给锚点。
(3)一种鸟瞰图中心性重新加权方法,对更远的预测加权更大。
(4)大规模2D检测预训练和辅助监督。
我们展示了这些设计在缺乏深度信息的基于摄像头的3D感知任务中的显著效果。M^2BEV具有高效的内存使用,允许输入更高分辨率的图像,并具有更快的推断速度,在nuScenes数据集上的实验表明,M^2BEV在3D物体检测和鸟瞰图分割两个任务中取得了最先进的结果,其中最佳单模型分别达到了42.5的mAP和57.0的mIoU。

主要贡献
多摄像头自动驾驶感知的两种解决方案。top:多个任务特定网络在各自的2D视图上运行,无法跨任务共享特征,并输出视图特定的结果,需要进行后处理才能融合成最终的、与世界一致的输出。bottom:M^2BEV采用统一的鸟瞰图(BEV)特征表示,支持单个网络进行多视角多任务学习。我们认为统一的鸟瞰图(BEV)特征表示对于360度多任务自动驾驶感知至关重要。本文通过有效的特征转换获得BEV表示,其中BEV表示是通过将多视角2D图像特征沿光线重构到3D体素中得到的。如图2所示,统一的BEV表示使我们能够以最小的额外计算成本轻松支持多个任务,如检测和分割。
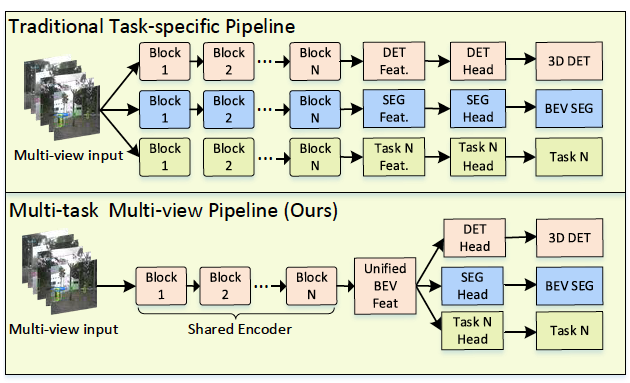
图2:多摄像头AV感知的两种解决方案
这使得我们的工作与简单地顺序堆叠单独的任务特定网络不同。本文的贡献可以总结如下:
提出了一个统一的框架,将多摄像头图像转换为鸟瞰图(BEV)表示,用于多任务自动驾驶感知,包括3D物体检测和BEV分割。据我们所知,这是第一个在单一框架中针对这两个具有挑战性的任务进行预测的工作。
提出了几个新颖的设计,如高效的BEV编码器、动态框分配和BEV中心性。这些设计有助于提高GPU内存效率,并显著提高了两个任务的性能。
展示了大规模的2D注释(如nuImage)和2D辅助监督的预训练可以显著提高3D任务的性能,并有益于标签效率。因此,我们的方法在nuScenes上在3D物体检测和BEV分割两个任务上取得了最先进的性能,表明BEV表示在下一代自动驾驶感知中具有很大的潜力。
主要内容
M^2BEV的整体流程如图3 ,给定时间戳T处的N个图像以及相应的内参和外参相机参数作为输入,编码器首先从多视图图像中提取2D特征,然后将这些2D特征投影到3D车辆坐标系中生成鸟瞰图(BEV)特征表示,最后,采用任务特定的头部来预测3D物体和地图。
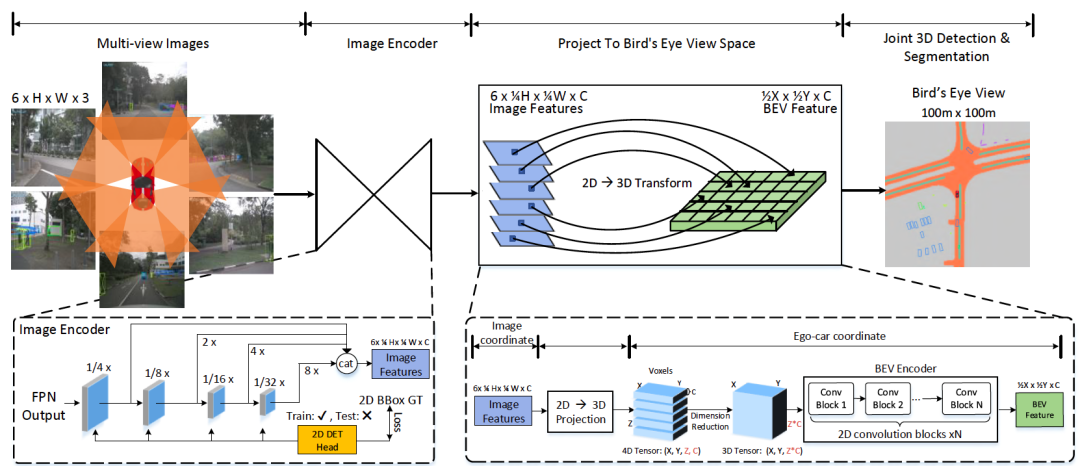
图3:M2BEV的整体流程
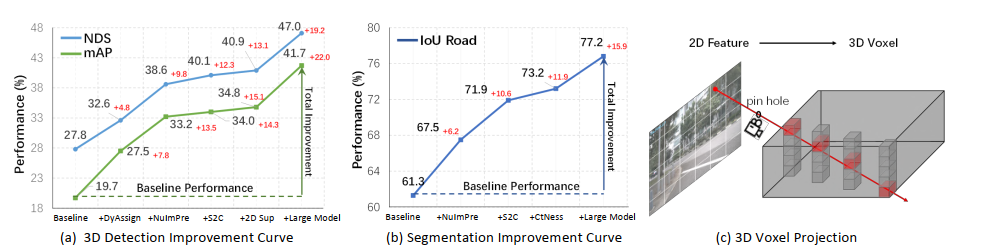
图4:(a)、(b)展示了我们的基准线相比于3D检测和BEV分割上的显著性能改进,这意味着这些设计是非常重要的。(c)展示了在M2BEV中高效的2D→3D特征投影,它将2D特征沿着射线投影到3D体素中。
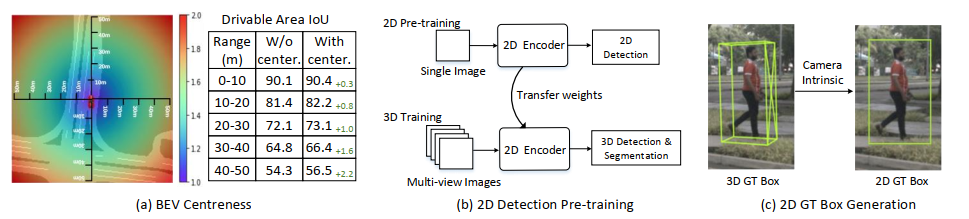
图5:一些改进设计的细节。(a) 不同范围内的BEV中心度和IoU改进;(b) 2D检测预训练。我们首先在2D检测任务上预训练模型,然后将骨干网络的权重转移到3D任务上;(c) 通过将自车空间中的3D GT框投影到2D图像空间中生成2D GT框。
实验结果
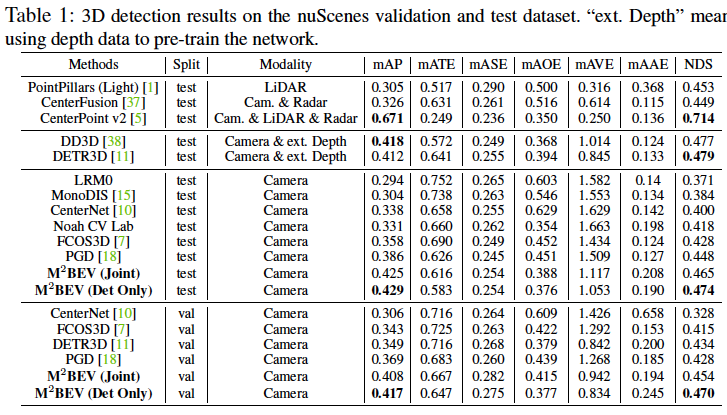
M^2BEV在nuScenes数据集上在3D物体检测和BEV分割两个任务上均取得了最先进的结果。此外,由于采用了统一的BEV表示,M^2BEV在运行时比仅进行检测或分割的方法更加高效。
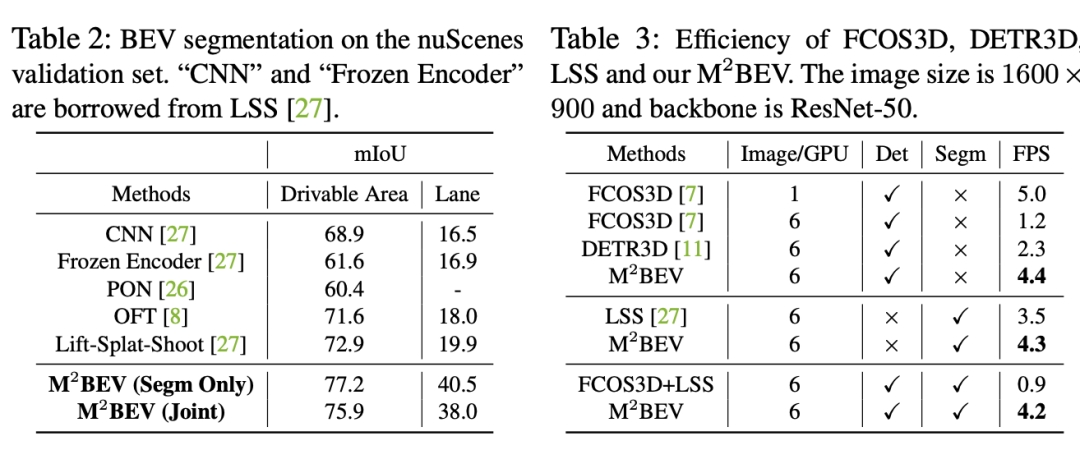
联合3D物体检测和地图分割的定性结果如图7,红色圆圈表示一些失败案例,我们的模型可以在复杂的道路条件下检测到密集的3D物体并分割地图。然而,在车道分割和超大物体检测方面,预测的质量仍然不够完美。未来应该在这些情况下投入更多的努力来提高预测质量。

图7,联合3D物体检测和地图分割的定性结果
总结
3D物体检测和地图分割是多摄像头自动驾驶感知中最重要的两个任务,本文提出了一种在一个网络中完成这两个任务的框架,关键思想是将多视角特征从图像平面投影到鸟瞰图(BEV)空间中,创建统一的BEV表示,然后,检测和分割分支在BEV表示上进行操作,还展示了在廉价的2D数据上进行预训练可以提高3D任务的标签效率。
更多详细内容后台发送“知识星球”加入知识星球查看更多。
3D视觉与点云学习星球:主要针对智能驾驶全栈相关技术,3D/2D视觉技术学习分享的知识星球,将持续进行干货技术分享,知识点总结,代码解惑,最新paper分享,解疑答惑等等。星球邀请各个领域有持续分享能力的大佬加入我们,对入门者进行技术指导,对提问者知无不答。同时,星球将联合各知名企业发布自动驾驶,机器视觉等相关招聘信息和内推机会,创造一个在学习和就业上能够相互分享,互帮互助的技术人才聚集群。
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入知识星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享与合作方式:微信“cloudpoint9527”(备注:姓名+学校/公司+研究方向) 联系邮箱:dianyunpcl@163.com。
点赞吧!






![C嘎嘎~~[构造函数提升篇]](https://img-blog.csdnimg.cn/a4272c63566c460dba27cbad649e3433.png)