LeNet & MNIST
LeNet是由Yann LeCun及其合作者于1998年开发的一种具有开创性的卷积神经网络架构。它的设计目的是识别手写数字并执行图像分类任务。MNIST是一个用于手写数字识别的大型数据库,常被用于训练图像处理系统。LeNet与MNIST的关系在于,LeNet经常被用于MNIST数据集的训练和测试。
AlexNet & CIFAR
AlexNet是由Alex Krizhevsky,Ilya Sutskever和Geoffrey Hinton在2012年开发的深度卷积神经网络架构。AlexNet包含多个卷积层、池化层、全连接层和激活函数,并引入了Dropout技术以减少过拟合现象。CIFAR是一个包含两个子数据集的图像分类数据库:CIFAR-10和CIFAR-100。尽管AlexNet最初是针对ImageNet数据集开发的,但它的架构和训练方法也可以应用于其他图像分类任务,如CIFAR数据集。
VGG Net
VGG Net是一种深度卷积神经网络架构,由Oxford University的Visual Geometry Group(VGG)团队于2014年开发。VGG Net在当年的ImageNet大规模视觉识别挑战(ILSVRC)中取得了优异成绩,以其简洁的结构和卓越的性能获得了广泛关注。VGG Net的核心思想是通过使用较小的卷积核(如3x3)和多个连续卷积层来增加网络深度,从而提高模型的表达能力。VGG Net有多个版本,如VGG-16和VGG-19,这些数字代表网络中包含的权重层(卷积层和全连接层)的数量。
GoogLeNet & Inception v1
GoogLeNet是一种深度卷积神经网络架构,由Google的研究人员于2014年开发。GGoogLeNet的核心创新是引入了一种名为Inception的模块结构,因此GoogLeNet有时也被称为Inception v1。Inception模块的主要思想是将多个卷积核大小的卷积层和池化层并行堆叠,从而在不同尺度上捕捉图像特征。具体而言,Inception模块包含1x1、3x3、5x5的卷积层(加入1x1卷积层进行降维以减少计算量)和3x3最大池化层。这些层在同一级别并行操作,然后将它们的输出连接起来,形成一个更丰富的特征表示。
ResNet
ResNet(Residual Network)是由Kaiming He, Xiangyu Zhang, Shaoqing Ren和Jian Sun于2015年提出的一种深度卷积神经网络架构。ResNet在2015年的ImageNet大规模视觉识别挑战(ILSVRC)中获得了冠军,同时在分类、定位、检测和分割等任务上取得了前所未有的成绩。ResNet的关键创新是引入残差连接(residual connections)来解决深度神经网络中的梯度消失和退化问题。
(188条消息) 【人脸检测】MTCNN网络解析_码上游的博客-CSDN博客
(188条消息) 【详解】卷积神经网络(CNN)概念及大体流程_卷积神经网络流程图_码上游的博客-CSDN博客
什么是卷积神经网络?
卷积神经网络结构包括:卷积层,池化层,全连接层。每一层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征,每个特征图有多个神经元。
卷积层:卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。
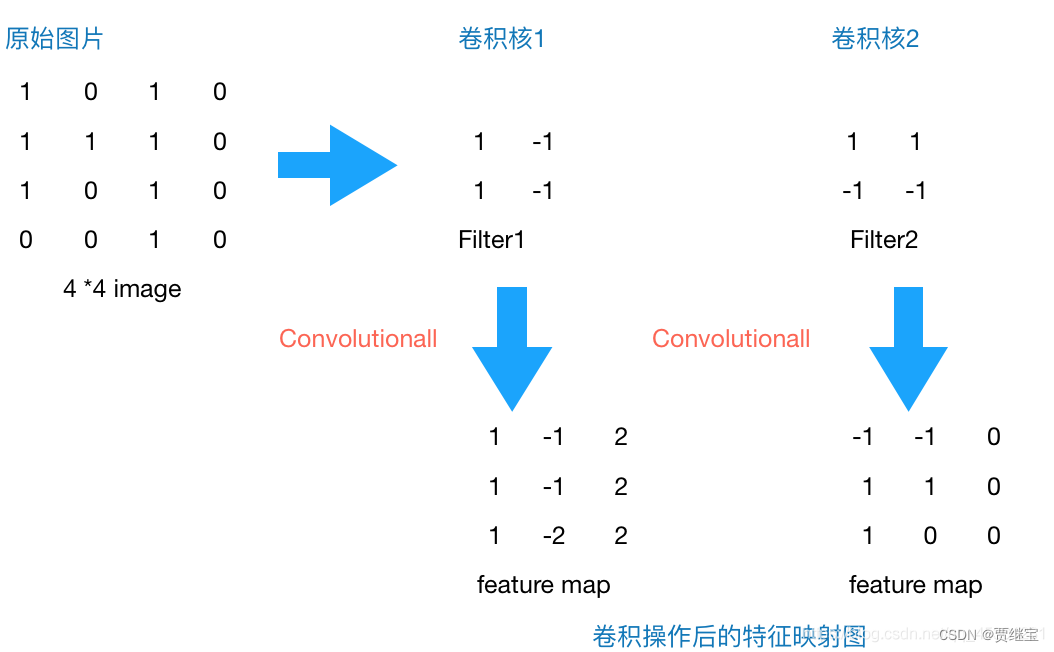
卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。比如我们看一张猫的图片,可能看到猫的眼镜或者嘴巴就知道这是张猫片,而不需要说每个部分都看完了才知道,啊,原来这个是猫啊。所以如果我们可以用某种方式对一张图片的某个典型特征识别,那么这张图片的类别也就知道了。这个时候就产生了卷积的概念。举个例子,现在有一个4*4的图像,我们设计两个卷积核(卷积核也称为特征提取器,或者过滤器),看看运用卷积核后图片会变成什么样。
激励层:对卷积层的输出结果进行一次非线性映射
常用的激励函数:Sigmoid函数、Tanh函数、ReLU函数.
CNN激励函数一般为ReLU,其特点为:收敛快、求梯度简单、较脆弱。
池化层: 池化层夹在连续的卷积层中间,有两个作用:
1、为了减少训练参数的数量,降低卷积层输出的特征向量的维度;
2、只保留最有用的图片信息,减少噪声的传递。
通常来说,池化方法一般有以下两种:
MaxPooling(最大池化):取滑动窗口里最大的值
AveragePooling(平均池化):取滑动窗口内所有值的平均值
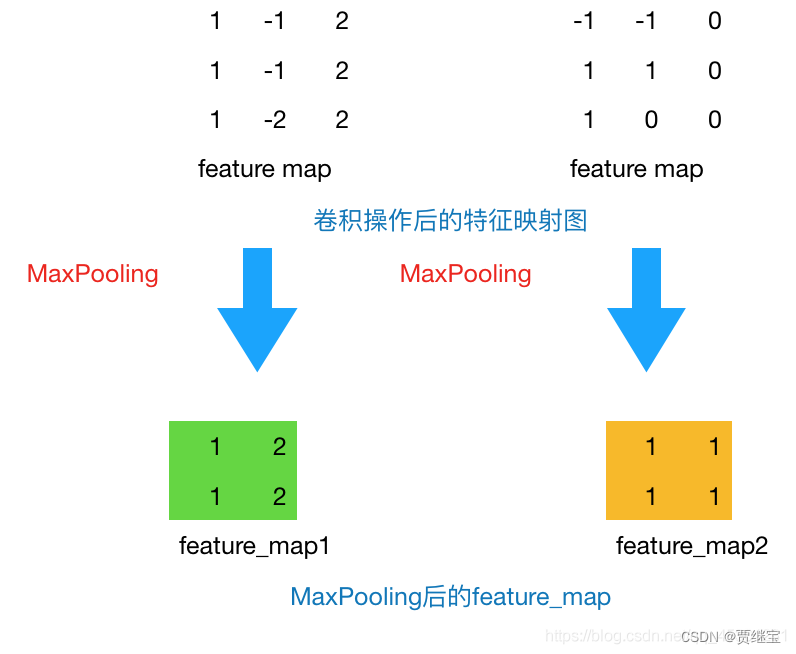
通过上一层2 * 2的卷积核操作后,我们将原始图像由4 * 4的尺寸变为了3 * 3的一个新的图片。池化层的主要目的是通过降采样的方式,在不影响图像质量的情况下,压缩图片,减少参数。简单来说,假设现在设定池化层采用MaxPooling,大小为2 * 2,步长为1,取每个窗口最大的数值重新,那么图片的尺寸就会由3 * 3变为2 * 2(计算公式:输出边长=(输入边长–卷积核边长)/步幅+ 1;(3-2)+1=2)。从上例来看,会有如下变换:
接下来说一下Zero Padding:到现在为止,我们的图片由4 * 4,通过卷积层变为3 * 3,再通过池化层变化2 * 2,这只是一层卷积,如果我们再添加几层,那么图片岂不是会越变越小?这个时候我们就会引出“Zero Padding”(补零),它可以帮助我们保证每次经过卷积或池化输出后图片的大小不变,如,上述例子我们如果加入Zero Padding,再采用3*3的卷积核,那么变换后的图片尺寸与原图片尺寸相同,如下图所示:

通常情况下,我们希望图片做完卷积操作后保持图片大小不变,所以我们一般会选择尺寸为3 * 3的卷积核和1的zero padding,或者5 * 5的卷积核与2的zero padding,这样通过计算后,可以保留图片的原始尺寸。那么加入zero padding后的feature_map尺寸 =( width + 2 * padding_size - filter_size )/stride + 1。
全连接层: 两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的。
作用:全连接层在整个卷积神经网络起到“分类器”的作用。提取特征、进行分类。
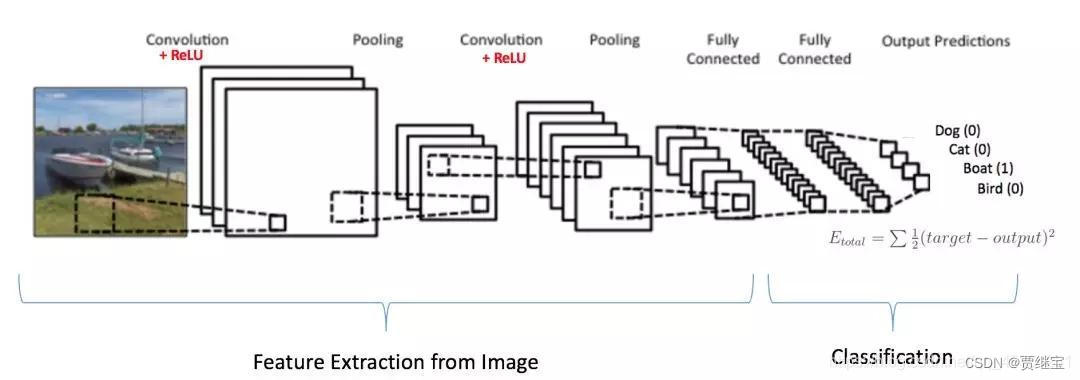
这就是一个完整的卷积神经网络,如果想要叠加层数,一般也是叠加“Conv-Pooing",通过不断的设计卷积核的尺寸,数量,提取更多的特征,最后识别不同类别的物体。做完Max Pooling后,我们就会把这些数据“拍平”,丢到Flatten层,然后把Flatten层的output放到full connected Layer里,采用softmax对其进行分类。
1.1总结
CNN基本流程图:
1.什么是MTCNN网络?
MTCNN(多任务卷积神经网络)将人脸区域检测与人脸关键点检测放在了一起,总体可分为P-Net、R-Net、和O-Net三层网络结构。
MTCNN是由中国科学院深圳研究院在2016年提出的专门用于人脸检测的多任务神经网络模型。该模型主要由3个级联网络组成,分别为可以快速生成候选框的P-Net网络、进行候选框过滤的R-Net网络和生成最终边界框并且标出人脸特征点的O-Net网络。该模型主要运用了图像金字塔、非极大抑制(NMS)和边框回归技术(Bounding-Box Regression)。
MTCNN实现人脸检测与对齐在一个网络里实现了人脸检测与五点标定的模型,主要是通过CNN模型级联实现了多任务学习网络。整个模型分为三个阶段,第一阶段通过一个浅层的CNN网络快速产生一系列的候选窗口(P-Net网络);第二阶段通过一个能力更强的CNN网络过滤掉绝大部分非人脸候选窗口(R-Net网络);第三阶段通过一个能力更加强的网络找到人脸上面的五个标记点(O-Net网络)。
2.内部实现原理?
首先输入原始图片集,图片在进入3个级联网络前会通过图像金字塔技术对图片进行尺寸重新划分,将原图缩放为不同的尺度,从而构成图像金字塔;然后将这些不同尺寸的图片送入3个级联网络进行训练,这是为了让网络可以检测到不同大小的人脸而进行的多尺度检测。
在完成图像金字塔后,生成的图像会进入MTCNN的第一个网络层,即P-Net网络层。P-Net全称为Proposal Network,该网络也是一个全连接网络,对于上一步输入的图像,通过全卷积网络(FCN)初步提取图像特征并且给出初步的标定边框,这时会出现许多标定边框,因为P-Net会通过一个人脸分类器将可能为人脸的部分都打上边框。在该网络的最后会通过Bounding-Box Regression与NMS对刚才生成的边框进行初步筛查,丢弃不符合标准的标定边框。P-Net网络结构如图所示。
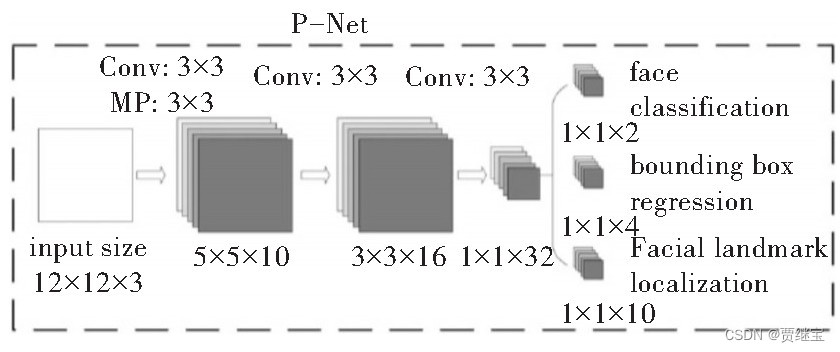
从P-Net网络输出的标定边框的人脸区域会进入下一个网络,即R-Net网络进行处理。
R-Net全称Refine Network,该层网络从结构上讲就是一个基本的卷积神经网络,比P-Net多了一层全连接层,这使得对脸部特征点和边框的筛选将更为严格。
对网络中输入的值进行更加细化的选择,并且舍去大部分错误,该层也会利用人脸关键点定位器对人脸关键点进行定位以及边框回归,最后利用Bounding-Box Regression与NMS对结果作进一步优化,将可信度较高的人脸区域输出给下一层网络,即O-Net网络。R-Net网络的网络结构如图所示。

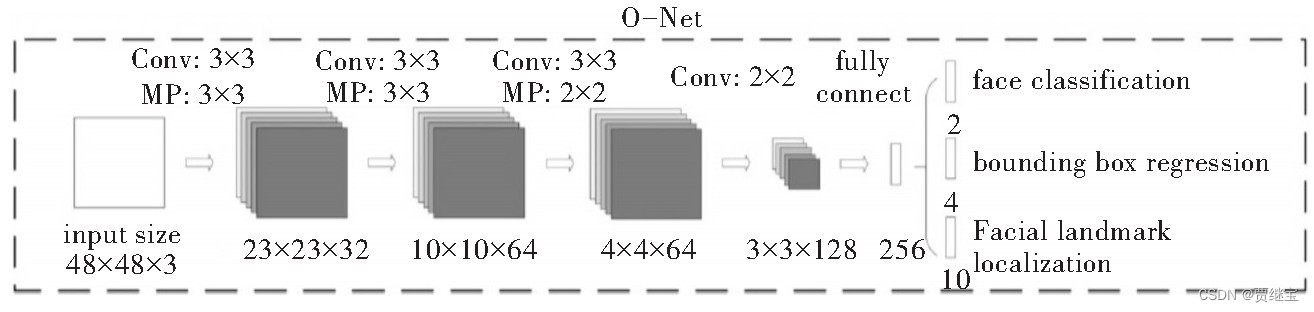
O-Net网络的全称为Output Network,该层网络基本结构与R-Net网络结构相似,多了一层卷积层,网络结构更加复杂,拥有更好的性能,模型优化也更好。在该层对输入图像进行人脸判别、人脸边框回归以及特征点定位,最后在图片中输出人脸区域的5个特征点。O-Net网络结构如图所示。
3.MTCNN网络实施流程?
将原始图片输入MTCNN网络,让MTCNN网络可以准确地识别出人脸和关键点。然后通过检测到的5个关键点,再根据“三庭五眼”理论将人脸的眼睛、嘴巴和耳朵分为了3个区域,定义了左、右眼中心点连线与水平方向的夹角为q,眼部区域宽度为W,高度为H=w/2。从鼻尖点位C向左右嘴角连线作垂线,记垂距为D。嘴部区域上、下沿分别取该垂线及其延长线上D/2和3D/2处。这样在检测时可将这3个部分分开检测,不同的区域、不同的动作会产生不同的结果。



![[云原生] 破局微服务通信:探索MegaEase服务网格的创新之路](https://img-blog.csdnimg.cn/6e7bd1e4bbbe44fbadb98a8f03969864.png)