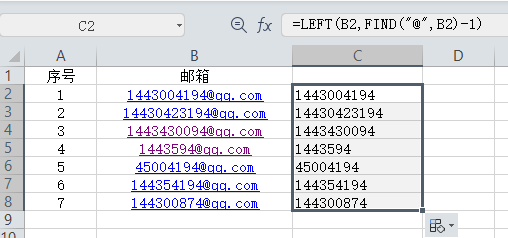
一)搭建主从架构:
单节点Redis的并发能力是有限的,所以说要想进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离,因为对于Redis来说大部分都是读多写少的场景,更多的要进行读的压力,最基本都要是三台机器,一主两从;
计划是在一个linux服务器上面开启3个Redis实例来进行模拟主从集群
在真实的开发环境中,可以是IP地址不相同,但是端口号可以相同


一)要在同一台linux服务器开启个实例,必须要准备三份不同的配置文件和目录,配置文件所在的目录就是工作目录,下面我们就在tmp目录下面的temp目录下面创建了三个目录
7001 7002 7003
二)关闭AOF持久化方式,启用RDB持久化方式
三)拷贝redis.conf配置文件到每一个实例目录
四)修改每一个实例的端口和工作目录
修改每一个文件夹下面的配置文件,将端口号修改成7001 7002 7003,将RDB文件保存位置都修改为自己的文件所在的目录
五)打开三个窗口,分别启动redis
六)搭建主从节点,在两个从结点之间执行命令
info replication来去检查主节点的连接信息




Redis主从第一次同步是全量同步,会将内存生成快照,整体发送给salve,下面来解析一下全量同步的过程
1)从节点要执行一个replicaof命令,建立连接,并且指定master的IP地址和端口号,一旦建立成功slave就可以向master发送请求了,来进行请求数据同步;
2)主节点会进行判断你是否是第一次来,如果你是第一次来,那么主节点会把所有的数据返回给从节点,如果你不是第一次来,那么只是会返回部分的数据,你缺多少,我给你多少
3)如果是第一次来,那么主节点会向从节点发送自己的版本信息,然后从节点会将这个版本的信息记录;
4)如果主节点判断是全量同步,那么主节点的主线程会执行bgsave命令,生成一个子进程来生成一个RDB文件,这样对于主进程没有什么影响,主进程继续去处理用户请求;
5)RDB文件里面记录了完整的内存信息,然后主进程会发送这个RDB信息发送给我们的从节点,从节点拿到这个RDB文件就是相当于是拿到了主节点的全部数据了,然后从节点会把本地的RDB文件进行清空,然后会进行加载发送过来的RDB文件,这样master和slave节点基本一致;
6)因为在bgsave异步执行的过程中,那么主进程还是会进行处理用户的请求的,那么会有新的数据写入到主节点的内存中,但是这些新的数据并没有发送给主节点,所以master的主进程除了要进行处理新的数据之外,主进程还会把这些命令记录到repl_backlog这样的内存缓冲区中,repl_backlog这样的缓冲区会进行记录在bgsave期间收到的新的命令,只要未来从节点成功收到了bgsave的RDB文件再来执行repl_backlog中的所有命令,就是master节点的完整数据;
7)主节点会将repl_backlog中的所有的命令发送给从节点,从节点去执行接收到的命令,从而保证master和slave节点中的数据是完全一致的,后续再来有独立进程将这些repl_backlog中的命令发送给slave节点
8)全量同步速度比较慢,只有在第一次建立连接才去做;
由此可知master是如何来进行判断slave是不是第一次来进行同步数据呢?
1)Replication ID:简称为是replid,是数据集的标记,ID相同则说明是同一数据集,每一个master都具有唯一的ID,后续的salve会进行继承master节点的repliID
2)offset:也被称之为是偏移量,随着记录在repl_backlog中的数据增多而逐渐增大,slave在完成同步的时候也会进行记录当前同步的offset,如果slave的offset小于master节点的offset,说明slave数据落后于master,需要进行数据的更新,slave中的offset是永远小于master中的offset的,因为从节点的offset是从主节点中拷贝过来的,如果主节点的offset值等于从节点的offset值,说明主从数据一致
3)因此slave在做数据同步的时候,必须向master声明自己的replication ID和offset(判断进度),master才可以进行判断自己到底要同步哪些数据;
master是如何来进行判断slave节点是不是第一次来做同步的?
1)直接判断offset是否为0即可;
2)难道说主要offset大于0就一定是第一次做同步吗?就一定不是第一次来吗?假设你的offset很大,但是此时发送过来的主节点的Replication ID和主节点ReplicationID不相同,你是从其他的master节点拷贝过来的,所以此时的offset是无意义的;
3)总结:因为每一个节点都存在着唯一的Replication ID,所以判断从节点是否是第一次来进行更新数据的依据是,如果主节点的Replication ID和从节点的Replication ID相同,那么说明不是第一次,如果Replication ID不相同,则说明是第一次;
全量同步的流程:
1)从节点向主节点请求增量同步
2)master节点会进行判断从节点的Replication ID是否和主节点自己的Replication ID是否一致,如果不同,说明要进行全量同步,拒绝增量同步;
3)master的主进程会开启一个分进程将完整的内存数据生成RDB文件,然后将这个RDB文件发送给slave节点
4)接下来从节点会清空本地数据,会进行加载master中的RDB文件;
5)主节点的主进程会将RDB期间的命令记录在repl_backlog,并会开启一个新的进程将log中的命令发送给slave;
6)slave会不断的执行log中的命令;
主从第一次同步是全量同步,但是如果slave重启之后进行同步,那么一定是执行增量同步,那么在slave再重启的这一段时间,主节点是一定会进行执行用户输入的命令的
1)从节点会向主节点发送Replication ID和offset,主节点判断过了Replication ID和从节点的ReplicationID是相同的,那么主节点会直接向从节点返回一个continue;
2)那么此时主节点想从节点发送数据的时候,就不用写RDB文件了,只不过是从节点在重启的时候丢失了一部分数据,这部分数据就在主节点的repl_backlog里面;
3)既然从节点向主节点发送了一个offset数据,那么主节点只需要定位到repl_backlog中的offset为止(从节点发送过来的offset值)再继续向后读取就可以了,也就是hirepl_backlog中去除掉offset之后的数据,此时从节点只需要执行这些命令就可以把剩下的数据给补上了;
4)hirepl_backlog的结构就类似于是一个环形链表,如上图所示,红色的区域是主节点的master,主节点的master表示当前主节点记录到的链表的位置在哪里,绿色的部分表示从节点做主从同步操作同步数据更新到哪里,后续出节点发生宕机,绿色到红色之间的部分就是从节点在宕机之后错过的数据,所以我们要进行传递的就是从slave的offset到master最新的的offset之间的数据,但是slvae的offset和master的offset不要超过这个环形链表的存储上限,那么是永远可以在这个环中找到你所需要补齐的数据,永远可以做到增量同步,但是slave中的offset和master的offset之间的差异已经超过存储上线了,那么就永远无法再做增量同步了;
5)此时原来的绿色部分是从节点的offset,剩下的红色部分就是master在slave宕机之后,新增的新命令,可以看到,如果这个时候从节点还不来做增量同步,那么主节点新增的数据一定会将slave区域覆盖;
6)这个时候主节点不光将绿色区域给覆盖了,还将slave尚未同步的数据进行了覆盖,因为slave的offset在环里面被覆盖,这时只能做全量同步;
7)repl_backlog的大小是有上限的,写满之后会覆盖最早的数据,如果从节点断开时间过久,导致没有进行备份的数据被覆盖,那么是无法基于log做增量同步的,只能做全量同步



可以从下面几个方面来进行优化Redis主从集群:
1)在master中redis.conf配置repl-diskless-sync yes开启无磁盘复制,避免全量同步时候的磁盘IO,当我要进行写RDB文件的时候,不把它写到磁盘中,而是使用网络直接发送给从节点,适用于磁盘比较慢,但是网络带宽比较快;
2)master单节点上面的内存占用不要太大,减少RDB导致的磁盘IO
3)适当提高back_log的大小,在发现slave宕机的时候能够尽快的实现故障恢复,避免全量同步,增大主节点offset和从节点offset的差值
4)限制一个master节点上面的slave节点数量,如果有太多的slave节点,可以采用主-从-主这样的链式结构,来减轻master的压力


一)简述全量同步和增量同步的区别:
全量同步:master将完整的内存数据生成RDB文件,发送RDB文件到slave,后续命令将记录在repl_backlog中,逐个发送给slave节点
增量同步:slave提交自己的offset到master,master获取到repl_backlog中从offset之后的命令给从节点
二)什么时候执行全量同步?
slave节点第一次连接到master结点的时候做全量同步
slave节点断开太久,repl_backlog中的offset已经被覆盖的时候
三)什么时候执行增量同步?
slave节点断开又恢复,并且在repl_backlog中可以找到对应的offset值的时候
哨兵模式
1)在主从集群中,如果slave从节点发生了宕机,根本不需要担心,只要从节点重启,那么从节点就可以从主节点那里获取到完整的数据
2)在Redis中提供了哨兵机制来实现主从集群的自动故障恢复,哨兵的结构和作用如下
2.1)监控:Sentinel会不断地进行检查您的master节点和slave节点是否正常工作
2.2)如果master出现了故障,那么Sentinel会将一个slave升级为master,当然故障恢复之后也会以新的master为主,如果salve宕机了,那么Sentinel也会立即尝试重启slave节点
2.3)通知:JAVA客户端也就是StringRedisTemplate在去寻找主从地址的时候,不是直接去redis中寻找,StringRedisTemplate甚至于说都不知道主从节点的地址,而是直接去寻找Sentinel,由Sentinel来告诉JAVA客户端主从地址是什么,那么将来一旦主从节点发生了切换,Sentinel会立即将服务的状态变更,通知JAVA客户端,这样JAVA客户端就知道新的主节点和新的从节点是谁了,就会改变自己节点访问的地址了,Sentinel此时就充当了JAVA客户端服务发现节点的来源了,也就是说Sentinel会充当Redis客户端的服务发现来源,当集群出现故障转移的时候,会将最新消息推送给JAVA的客户端

服务状态监控:
Sentinel是基于心跳机制来实现检测服务状态,每隔1S钟会向集群中的每一个实例发送ping命令
1)主观下线:如果某一个Sentinel发现某一个实例没有在规定时间内响应,那么说明是该实例主观下线,主观下线就是我个人认为你下线了,但是不一定真的下线了,因为这里是超时未响应,有可能网络阻塞没有及时得到结果,有可能是好的;
2)客观下线:如果超过指定数量的Sentinel(quorum)都认为该实例主观下线,那么该实例客观下线,quorum值最好超过Sentinel数量的一半,其实就是一个投票,认为是主观下线就是真的宕机;

选取新的master节点来充当主节点
一旦我们发现了master出现了故障,那么sentinel会需要从salve节点中选取一个节点来进行充当新的master节点,下面是选择依据:
1)首先会进行判断slave节点和master节点的断开时间的长短,如果超过指定值(down-after-millseconds*10)那么会直接排除该从节点
2)然后会进行判断slave节点的salve-priority值,刚一开始都是相同的,如果这个值越小说明优先级越高,如果是0说明永远不参与选举
3)如果是slave-priority的值相同,那么就进行判断slave节点的offset的值,offset的值越大说明数据越新,优先级越高,offset的值反映了主节点和从节点之间数据更新的进度,offset值越大,说明和master的值越接近,因为要优先保证数据的完整性;
4)最后是进行判断slave节点的运行ID大小,越小说明优先级越高,RunID是在slave启动的时候自动生成的;
基于哨兵机制实现故障转移:
1)Sentinel会先给备选的slave节点发送slaveof no one命令,让该节点成为master
2)接下来Sentinel会给其他slave节点发送slave of将要成为主节点的IP地址和将要成为主节点的端口号,让这些slave节点成为新master的从节点,并开始从新的master上面进行同步数据;
3)标记故障文件:最后Sentinel将故障节点标记成slave节点,Sentinel强制修改它的配置文件,就是在配置文件中强制加上slave of 新主节点的IP地址+端口号,那么一旦旧的主节点进行重启之后,一定会认新的主节点为从节点;
搭建哨兵集群:
1)计划搭建一个三节点组成的Sentinel集群,来进行监管之前的Redis主从集群
2)这三个Sentinel的集群是搭建在同一台linux服务器的,所以他们的IP地址都是相同的
3)创建3个文件夹为s1和s2和s3,我们还需要进行准备三份不同的配置文件和目录,配置文件所在的目录就是工作目录
4)我们先在s1目录下面创建一个sentinel.conf文件,来添加以下的内容
port 端口号(也就是Sentinel的端口号,多个Sentinel有不同的端口号) daemonize no bind 127.0.0.1 logfile "/userData1.log" #sentinel的工作目录 dir "/tmp/temp/s1" sentinel auth-pass mymaster 12503487 sentinel monitor mymaster 127.0.0.1 7001 2 #声明监控信息,mymaster是集群的名称,先监控master,监控master以及从节点的信息 #后面的2表示quorum的值,也就是说超过quorum数量的sentinal认为该节点主观下线,那么该节点客观下线 #就是master真的下线 sentinel down-after-milliseconds mymaster 30000 #这个信息是slave和master断开之后的最长超时时间 sentinel failover-timeout mymaster 180000 #这个是表示slave故障恢复的超时时间5)启动sentinal
redis-sentinal /tmp/temp/s1sentinal.conf


![[云原生] 破局微服务通信:探索MegaEase服务网格的创新之路](https://img-blog.csdnimg.cn/6e7bd1e4bbbe44fbadb98a8f03969864.png)






![C嘎嘎~~[构造函数提升篇]](https://img-blog.csdnimg.cn/a4272c63566c460dba27cbad649e3433.png)