问题现象
客户反馈有一个server端S, 两个client端C1, C2, S的iptables规则对C1, C2都是放通的,但是C2无法连接上S,客户很着急,催我们尽快解决。
这里解释一下,iptables规则是防火墙规则,是linux系统实现防火墙一个应用层配置工具,底层依赖是Linux内核网络子系统的netfiler框架。这里简单介绍一下问题的背景知识。
背景知识

netfilter是Linux内核内部的一个框架,该框架允许内核模块在Linux网络堆栈的不同位置注册回调函数。然后对于遍历Linux网络堆栈内各个挂钩的每个数据包,将调用已注册的回调函数。
netfilter / iptables能做什么?
- 建立基于无状态和有状态数据包过滤的Internet防火墙
- 部署高可用性的无状态和有状态防火墙集群
- 如果您没有足够的公共IP地址,请使用NAT和伪装来共享Internet访问
- 使用NAT来实现透明代理
- 协助tc和iproute2系统用于构建复杂的QoS和策略路由器
- 进行进一步的数据包处理(处理),例如更改IP标头的TOS / DSCP / ECN位
在内核协议栈位置大概是这样:
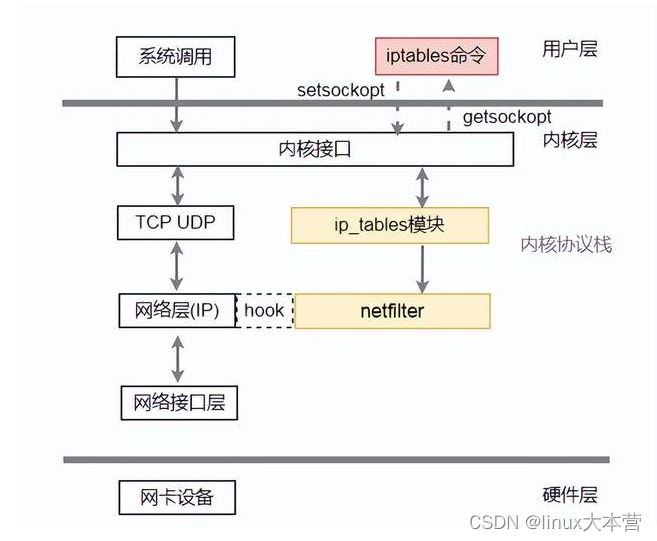
netfilter 注册HOOK函数位置:

5个HOOK点:
PREROUTING:数据包进入路由表之前
INPUT:通过路由表后目的地为本机
FORWARD:通过路由表后,目的地不为本机
OUTPUT:由本机产生,向外发送
POSTROUTIONG:发送到网卡接口之前。
每个HOOK点都会执行一些函数,大致分为下面几个表:
NAT表: 用于实现nat功能,端口映射,地址映射等
mangle表: 用来修改报文,例如更改IP标头的TOS / DSCP / ECN位
filter表:用来过滤报文
raw表:用来提前标记报文不走一些流程(比如不需要建会话)
如果不熟悉不要紧,只需知道在协议栈收发关键入口(进入,转发,发出)注册一些 hook函数,然后报文会经过hook里面函数处理,而这些hook的动作(函数)是需要一个iptables的工具下发配置生成的。
iptables是您下发规则的用户态工具。IP表中的每个规则都由多个分类器(iptables匹配项)和一个连接的动作(iptables目标)组成。命令格式可参考下图,详细可以参考man手册:

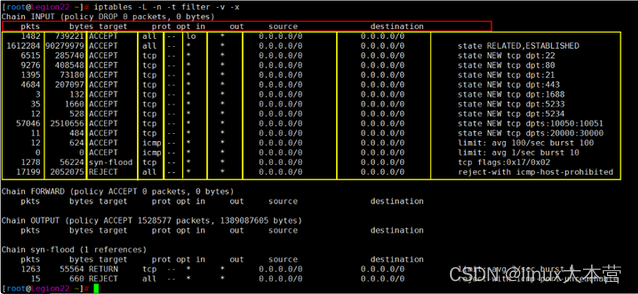
这里记住两个动作就行了,ACCEPT表示通过,DROP表示丢掉;
内核里面看到的规则大概是这个样子:
主要特点
- 无状态数据包过滤(IPv4和IPv6)
- 有状态的数据包过滤(IPv4和IPv6)
- 各种网络地址和端口转换,例如NAT / NAPT(IPv4和IPv6)
- 灵活可扩展的基础架构
- 第三方扩展的API
所以大多数公司会基于netfilter框架实现软件防火墙(安全组)和软件虚拟交换机(vswitch,类似ovs)。
好,背景简单介绍完了,如果不是很理解,后面会详细介绍的,来看一下这个客户实际问题。
相关视频推荐
相关视频推荐
剖析Linux内核《Netfilter架构》
深入理解Linux内核《网络协议栈架构》
4个小时搞懂tcp/ip协议栈,从tcp/ip协议栈原理到实现一个网络协议栈
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
分析过程
1.先了解网络拓扑
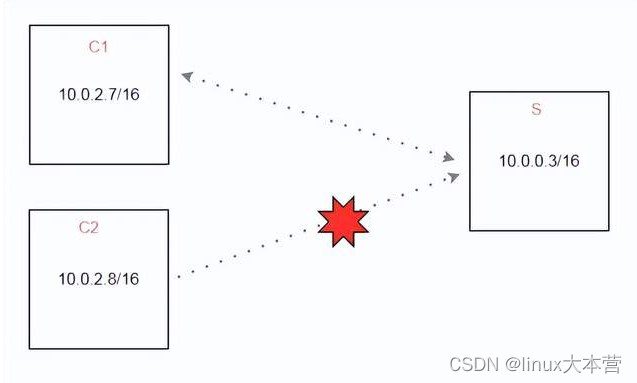
客户网络拓扑是相当的简单,就是同网段下client机器访问服务器,一台可以访问,一台不可以。
2. 查看配置是否丢失
由于是同网段,相当于局域网通信,C1都可以访问S,那在S上路由肯定是ok的。对于服务端 10.0.0.3 而言,两台客户端机器到本机的iptable规则都是一样的。但10.0.2.8到10.0.0.3 的20202端口的syn包被丢了,而10.0.2.7 到 10.0.0.3 的 20202 端口的访问是正常的。
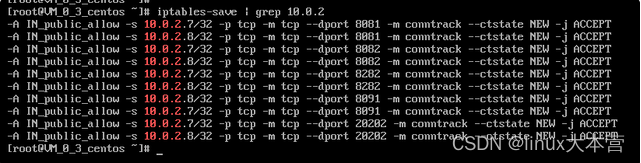
配置都在,需要进一步分析。
3. 抓包分析
client端发起telnet命令连接server, server按client ip抓包, 发现只有TCP SYN请求过来,并无回包,确实是本机OS内丢包导致无法正常连接:

通过netstat可以查看服务器TCP统计: 连接数不高,没有TCP队列丢包统计,结合10.0.2.7 client可以访问,进一步确认,放通安全组后,10.0.2.8 到 10.0.0.3 的 icmp 包也没有回,这个时候和TCP协议处理没有必然关系了。
4. 追踪内核丢包调用栈
报文如果被内核丢弃后,正常情况都会调用kfree_skb函数,内核通过kfree_skb释放skb,kfree_skb函数中已经埋下了trace点,并且通过__builtin_return_address(0)记录下了调用kfree_skb的函数地址并传给location参数,可以通过systemtap脚本,追踪kfree_skb这个trace point, 找到匹配ip的丢包并输出对应的堆栈:
/**
* kfree_skb - free an sk_buff
* @skb: buffer to free
*
* Drop a reference to the buffer and free it if the usage count has
* hit zero.
*/
void kfree_skb(struct sk_buff *skb)
{
if (unlikely(!skb))
return;
if (likely(atomic_read(&skb->users) == 1))
smp_rmb();
else if (likely(!atomic_dec_and_test(&skb->users)))
return;
trace_kfree_skb(skb, __builtin_return_address(0));
__kfree_skb(skb);
}
EXPORT_SYMBOL(kfree_skb);
/*
* Tracepoint for free an sk_buff:
*/
TRACE_EVENT(kfree_skb,
TP_PROTO(struct sk_buff *skb, void *location),
TP_ARGS(skb, location),
TP_STRUCT__entry(
__field( void *, skbaddr )
__field( void *, location )
__field( unsigned short, protocol )
),
TP_fast_assign(
__entry->skbaddr = skb;
__entry->location = location;
__entry->protocol = ntohs(skb->protocol);
),
TP_printk("skbaddr=%p protocol=%u location=%p",
__entry->skbaddr, __entry->protocol, __entry->location)
);systemtap脚本:
# cat mydropwatch.stp
#!/usr/bin/stap --all-modules
%{
#include <linux/kernel.h>
#include <linux/net.h>
#include <linux/textsearch.h>
#include <net/checksum.h>
#include <linux/dma-mapping.h>
#include <linux/netdev_features.h>
#include <linux/skbuff.h>
#include <uapi/linux/ip.h>
#include <uapi/linux/udp.h>
#include <uapi/linux/tcp.h>
%}
############################################################
# dropwatch2.stp
# An example script to mimic the behavior of the dropwatch utility
# Reports every 5 seconds with timestamp
# Usage: stap -g --all-modules mydropwatch.stp //-g for guru mode
############################################################
function get_packet_info:string(skb:long)
%{
int ret=-1;
unsigned int src_port = 0;
unsigned int dest_port = 0;
struct udphdr *udp_header;
struct tcphdr *tcp_header;
struct sk_buff *skb= (struct sk_buff *)STAP_ARG_skb;
struct iphdr *ip_header;
unsigned int src_ip=0,dest_ip=0;
if(!skb)
{
goto EXIT_F;
}
ip_header = (struct iphdr *)skb_network_header(skb);
if(!ip_header)
{
goto EXIT_F;
}
src_ip = (unsigned int)ip_header->saddr;
dest_ip = (unsigned int)ip_header->daddr;
#if 0
if (ip_header->protocol==17) {
udp_header = (struct udphdr *)skb_transport_header(skb);
src_port = (unsigned int)ntohs(udp_header->source);
} else if (ip_header->protocol == 6) {
tcp_header = (struct tcphdr *)skb_transport_header(skb);
src_port = (unsigned int)ntohs(tcp_header->source);
dest_port = (unsigned int)ntohs(tcp_header->dest);
}
printk(KERN_INFO "OUT packet info: src ip: %u, src port: %u; dest ip: %u, dest port: %u; proto: %u\n", src_ip, src_port, dest_ip, dest_port, ip_header->protocol);
#endif
// printk(KERN_DEBUG "IP addres = %pI4 DEST = %pI4\n", &src_ip, &dest_ip);
EXIT_F:
snprintf(STAP_RETVALUE, MAXSTRINGLEN, "%d.%d.%d.%d",(unsigned int)((unsigned char *)&src_ip)[0],(unsigned int)((unsigned char *)&src_ip)[1],(unsigned int)((unsigned char *)&src_ip)[2],(unsigned int)((unsigned char *)&src_ip)[3]);
%}
# Array to hold the list of drop points we find
global locations
# Note when we turn the monitor on and off
probe begin { printf("Monitoring for dropped packets\n") }
probe end { printf("Stopping dropped packet monitor\n") }
# increment a drop counter for every location we drop at
probe kernel.trace("kfree_skb") {
SrcIp=get_packet_info($skb)
//if(SrcIp=="10.0.2.8")//src ip of packet is "10.0.2.8"
// printf("srcip:%s\r\n",SrcIp)
if(SrcIp==@1)
{
locations[$location] <<< 1 //systemtap Statistical aggregate
if(symname($location)=="nf_hook_slow")//dump the backtrace if kfree_skb called by nf_hook_slow function
print_backtrace();
}
}
# Every 5 seconds report our drop locations
probe timer.sec(5)
{
// printf("\n=== %s ===\n", ctime(gettimeofday_s()))
foreach (l in locations-) {
printf("\n=== %s ===\n", ctime(gettimeofday_s()))
printf("%d packets dropped at %x (%s)\n",
@count(locations[l]), l, symname(l))
}
delete locations
}
### mydropwatch.stp ends ###执行方法:
stap -g -v --all-modules mydropwatch.stp 10.0.2.8
执行命令后,对应输出:
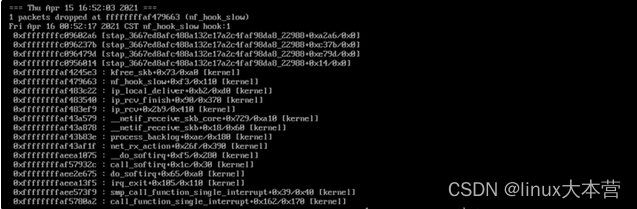
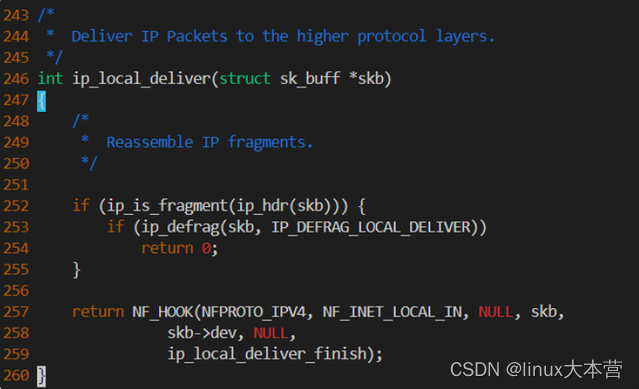
从调用栈可知是在ip_local_deliver函数时因为iptables规则导致的丢包,结合内核代码:
nf_hook_slow+0xf3 对于代码188行(先找到对应内核版本的源代码,用crash工具打开对应内核版本的vmlinux,反汇编函数查看指令偏移,定位到源代码行号):
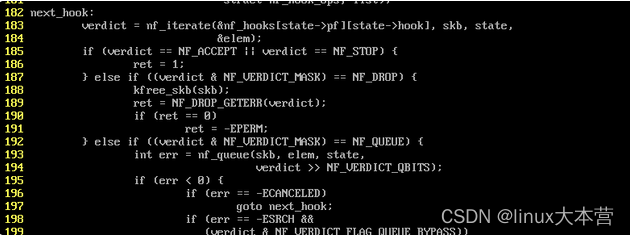
可知是在INPUT链丢的包, 但是检查了mangle, nat, filter等表的INPUT链,并无其他drop规则,默认policy均为ACCEPT, 所以这里有点奇怪。
为了确定是否真的匹配上了ACCEPT规则,我在规则前后添加了打印log规则,报文匹配后会打印log出来:

显示确认一下:

通过触发请求,匹配上了第一个打印log的规则,10.0.2.8白名单规则命中计数有新增,而第二log规则没有匹配上,说明报文命中了白名单规则,报文可以通过防火墙:

但为什么服务端没有回syn+ack呢,是不是某种场景触发了netfiler框架的bug,假装accept,实际上把报文悄悄地给丢了? 结合报文和系统环境,看了几遍netfiler代码后,没有看出啥问题,清空iptables规则,停了firewalld,依然丢了,还是丢在 nf_hook_slow,也进一步证明不是普通iptables规则导致的。
如果要继续排查,是不是得遍历下内核数据结构,看看是不是list坏掉了,由于时间比较紧迫,遍历内核数据结构有点麻烦,需要找到netfiler hook表起始地址,再结合数据结构算出偏移,一步一步遍历内存,由于客户机器可以重启(业务已经不正常了),客户相信,重启可以比我们更快解决问题,还是重启大法好,但不幸的是,机器重启完后没有恢复,问题依然存在,这个就有意思了。
5. 排查其他netfilter hook(钩子)函数
那么,有没有可能是有其他内核模块在INPUT链中注册了hook函数,drop了对应的包呢?我们使用crash调试内核来找一下:
背景知识
crash是redhat的工程师开发的,主要用来离线分析linux内核转存文件,它整合了gdb工具,功能非常强大。可以查看堆栈,dmesg日志,内核数据结构,反汇编等等。crash支持多种工具生成的转存文件格式,如kdump,LKCD,netdump和diskdump,而且还可以分析虚拟机Xen和Kvm上生成的内核转存文件。同时crash还可以调试运行时系统,直接运行crash即可,ubuntu下内核映象存放在/proc/kcore。
5.1. 从nf_hooks找到ipv4 INPUT链的hook列表
内核hook的组织:
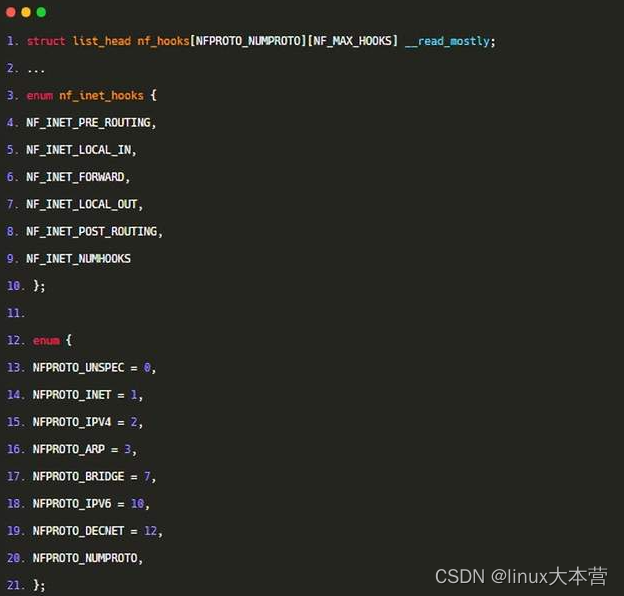
那么对于NFPROTO_IPV4协议的NF_INET_LOCAL_IN链,我们可以找到其链表地址:

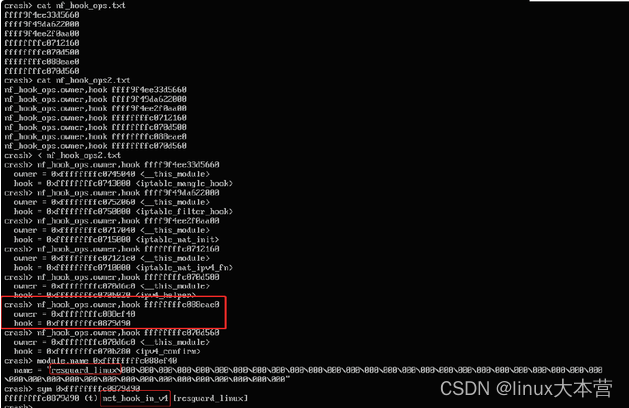
可以看到有一个非标模块resguard_linux引入了非标hook函数net_hook_in_v4,反汇编net_hook_in_v4函数,可知其有一些白名单/黑名单之类的检查:
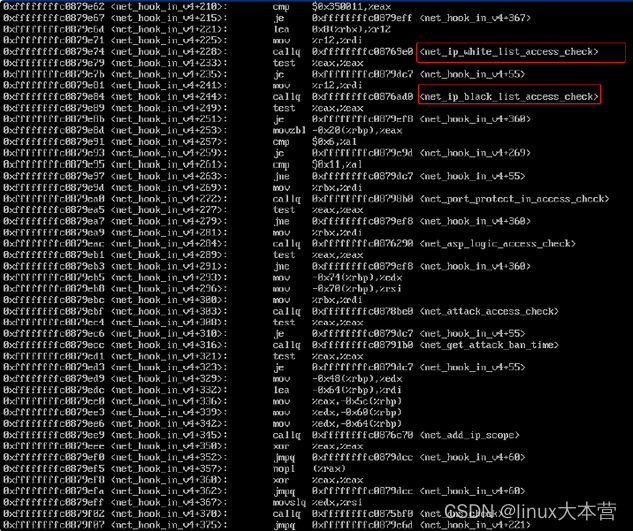
由此基本可以确定是这个模块的安全功能利用netfilter hook拦截了访问。
他大爷的,还真的注册了nf hook。
但要客户认账,还得证明这个包就是这个hook函数丢的,其实已经差不多了。
5.2. 如何证明是net_hook_in_v4返回NF_DROP(0x0)导致的丢包?
可以结合systemtap得到skb地址,然后通过perf probe抓取net_hook_in_v4和nf_iterate的返回值:
脚本:

运行结果:

由此可以看出bb2100结尾的这个skb是因为nf_hook_in_v4导致的丢包。
网上搜索可知该第三方安全模块疑似云锁这类软件提供,他可以通过ip黑白名单控制对网站的访问。
问题算是终于结束了,想着之前催得那么急,真想在线battle一下,然而客户是大爷,不敢想,不敢想。
可以学到什么
1. 大致了解Linux防火墙实现框架:netfilter+iptables;
2. 通过systemtap脚本追踪内核协议栈丢包堆栈信息;
3. 怎么通过堆栈函数和指令偏移找到源代码信息;
4. 一些丢包排查思路;
5. 了解一些工具使用,比如systemtap,crash,iptables,tcpdump等等;






![vector容器 [上]](https://img-blog.csdnimg.cn/b65b7ee01de141059a6716fcc9f4cbfd.png)