一、存储过程
1.1理解
含义:
存储过程stored procedure,思想是一组经过预先编译的SQL语句的封装。
存储过程预先存储在MySQL服务器上,需要执行的时候,客户端向服务器端发出调用存储过程的命令,服务器段把这组SQL执行。
好处:
①简化操作,提高sql语句的重用性。
②减少操作过程中的失误,提高效率
③减少网络传输量,因为客户端不需要把所有的SQL语句通过网络发给服务器
④减少SQL语句网上暴露的风险,提高数据查询的安全性
使用
存储过程直接操作底层数据库,存储过程创建出来后,直接调用存储过程名就可以,存储过程没有返回值。
1.2分类

①没有参数:无参数无返回
②in类型:有参数无返回
③out类型:无参数有返回
④inout类型:有参数有返回
⑤in类型和out类型:有参数有返回
2.创建存储过程
2.1语法分析
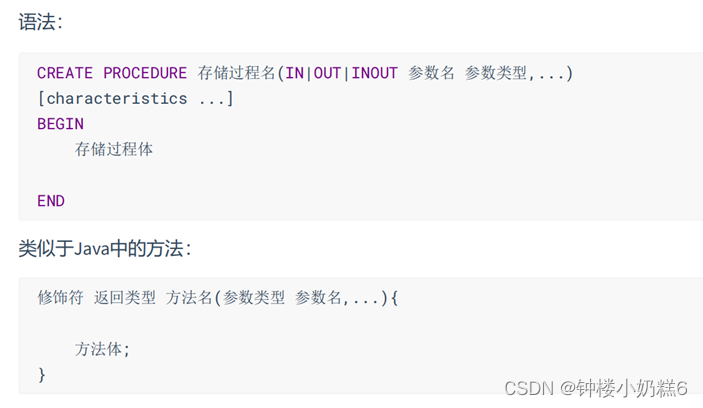
2.2设置新的结束标记
delimiter 新的结束标记
说明
MySQL默认结束是分号’;’,为了避免冲突,需要用delimiter设置新的结束标记。
举例
delimiter $ #结束标志是$
create procedure 存储过程名字()
begin
SQL语句;
end $
delimiter ; #改为结束标志是;2.3代码实现
举例1:创建存储过程select_all_data(),查看 emps 表的所有数据
delimiter $
create procedure select_all_data()
begin
select * from emps;
end $
delimiter ;
调用
call select_all_data();
举例2:创建存储过程avg_employee_salary(),返回所有员工的平均工资
delimiter $
create procedure avg_employee_salary()
begin
select avg(salary) avg_employee_salary
from emps
end $
delimiter ;
举例3:创建存储过程show_max_salary(),用来查看“emps”表的最高薪资值。
delimiter $
create procedure show_max_salary()
begin
select max(salary) from emps;
end $
delimiter ;
举例4:创建存储过程show_min_salary(),查看“emps”表的最低薪资值。并将最低薪资通过OUT参数“ms”输出
delimiter $
create procedure show_min_salary(out ms double)
begin
select min(salary) into ms
from emps;
end $
delimiter ;
调用
call show_min_salary(@ms);
select @ms;
举例5:创建存储过程show_someone_salary(),查看“emps”表的某个员工的薪资,并用IN参数empname输入员工姓名。
delimiter $
create procedure show_someone_salary(in ename varchar(25))
begin
select salary
from emps
where last_name=ename;
end $
delimiter ;
调用
call show_someone_salary('Abel')
举例6:创建存储过程show_someone_salary2(),查看“emps”表的某个员工的薪资,并用IN参数empname输入员工姓名,用OUT参数empsalary输出员工薪资。
delimiter $
create procedure show_someone_salary2(in ename varchar(20),out ms double)
begin
select salary into ms
from emps
where last_name=ename;
end $
delimiter ;
调用
set @ename=’Abel’;
call show_someone_salary2(@ename,@ms);
select @ms;
举例7:创建存储过程show_mgr_name(),查询某个员工领导的姓名,并用INOUT参数“empname”输入员工姓名,输出领导的姓名。
delimiter $
create procedure show_mgr_name1(inout ename varchar(20))
begin
select last_name into ename
from emps
where employee_id = (
select manager_id
from emps
where last_name = ename
);
end $
delimiter ;
调用
set @ename='Abel';
call show_mgr_name1(@ename);
select @ename;
2.4 调用格式
①调用in模式的参数:
call 存储过程名(‘值’)
②调用out模式的参数:
set @name;
call 存储过程名(@name);
select @name;
③调用inout模式的参数:
set @name=值;
call 存储过程名(@name);
select @name;
二、存储函数
1.语法分析

创建存储函数报错you might want to use the less safe log_bin_trust_function_creators variable的方法:
①加上函数特性deterministic(确定)
和contains sql(包含sql)|no sql(不包含sql)|reads sql data (读sql数据)|modifies sql data(改sql数据)
②mysql> SET GLOBAL log_bin_trust_function_creators = 1;
2.调用函数
select 函数名(实参列表)
3.代码举例
举例1:
创建存储函数,名称为email_by_name(),参数定义为空,该函数查询Abel的email,并返回,数据类型为字符串型。
delimiter $
create function email_by_name()
returns varchar(25) # 返回类型
deterministic # 确定的
contains sql # 包含sql
reads sql data # 读sql
begin
return(
select email from emps where last_name='Abel'
);
end $
delimiter ;
调用select email_by_name();
举例2:
创建存储函数,名称为email_by_id(),参数传入emp_id,该函数查询emp_id的email,并返回,数据类型为字符串型。
delimiter $
create function email_by_id(emp_id int)
returns varchar(25)
begin
return (select email from emps where employee_id=emp_id);
end $
delimiter ;
调用
set @id = 101;
select email_by_id(@id)
举例3
创建存储函数count_by_id(),参数传入dept_id,该函数查询dept_id部门的员工人数,并返回,数据类型为整型。
delimiter $
create function count_by_id(depid int)
returns int
begin
return (
select count(*)
from emps
where department_id = depid
);
end $
delimiter ;
调用
select count_by_id(80)
4.对比存储函数和存储过程

存储函数可以在查询语句中使用,存储过程不可以。存储过程的功能更加强大,可以对表的操作和事务操作。
三、存储过程和函数的查看、修改、删除
查看
1.查看存储过程和存储函数的创建信息
show create procedure|function 名称
2.使用show status 语句查看存储过程和函数的状态信息
show procedure status like 'show_max_salary'
show function status
3.从information_schema.Routines表中查询存储过程和函数的信息
select *
from information_schema.ROUTINES
where ROUTINE_NAME='count_by_id'
修改
1.只是修改特性,不影响功能

2.举例
举例1
修改存储过程CountProc的定义。将读写权限改为MODIFIES SQL DATA,并指明调用者可以执行,代码如下:
alter procedure CountProc
modifies sql data
sql security invoker;结果:
select *
from information_schema.ROUTINES
where ROUTINE_NAME='CountProc '
举例2
修改存储函数CountProc的定义。将读写权限改为READS SQL DATA,并加上注释信息“FIND NAME”,代码如下:
alter function CountProc
reads sql data
comment ‘FIND NAME’
删除
drop procedure|function 名字
四、存储过程阿里开发规范
禁止使用存储过程,难以调试和扩展,没有移植性。经典白学啊哈哈哈~
五、练习
存储过程
#0.准备工作
CREATE DATABASE test15_pro_func;
USE test15_pro_func;
#1. 创建存储过程insert_user(),实现传入用户名和密码,插入到admin表中
CREATE TABLE admin(
id INT PRIMARY KEY AUTO_INCREMENT,
user_name VARCHAR(15) NOT NULL,
pwd VARCHAR(25) NOT NULL
);
delimiter $
create procedure insert_user(in name varchar(15),in pwd varchar(25))
begin
insert into admin(user_name,pwd)
values (name,pwd);
end $
delimiter ;
测试
call insert_user('wang','1234')
#2. 创建存储过程get_phone(),实现传入女神编号,返回女神姓名和女神电话
CREATE TABLE beauty(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(15) NOT NULL,
phone VARCHAR(15) UNIQUE,
birth DATE
);
INSERT INTO beauty(NAME,phone,birth)
VALUES
('朱茵','13201233453','1982-02-12'),
('孙燕姿','13501233653','1980-12-09'),
('田馥甄','13651238755','1983-08-21'),
('邓紫棋','17843283452','1991-11-12'),
('刘若英','18635575464','1989-05-18'),
('杨超越','13761238755','1994-05-11');
SELECT * FROM beauty;
delimiter $
create procedure get_phone2(in id int,out name varchar(15),out phone varchar(15))
begin
select b.name,b.phone into name,phone
from beauty b
where b.id=id;
end $
delimiter ;
测试
call get_phone2(1,@name,@phone);
select @name,@phone;
#3. 创建存储过程date_diff(),实现传入两个女神生日,返回日期间隔大小
delimiter $
create procedure date_diff(in date1 date,in date2 date)
begin
select DATEDIFF(date1,date2) from dual;
end $
delimiter ;
测试
call date_diff2('1999-03-22','1994-08-19')
#4. 创建存储过程format_date(),实现传入一个日期,格式化成xx年xx月xx日并返回
delimiter $
create procedure format_date(in date date)
begin
select concat(YEAR(date),'年',MONTH(date),'月',DAY(date),'日') from dual;
#或SELECT DATE_FORMAT(mydate,'%y年%m月%d日')from dual;
end $
delimiter ;
测试
call format_date('2022-5-4')
#5. 创建存储过程beauty_limit(),根据传入的起始索引和条目数,查询女神表的记录
delimiter $
create procedure beauty_limit(in pageNo int,in pageSize int)
begin
select id,name,phone,birth
from beauty
limit pageNo,pageSize;
end $
delimiter ;
测试
call beauty_limit(0,5)
#创建带inout模式参数的存储过程
#6. 传入a和b两个值,最终a和b都翻倍并返回
delimiter $
create procedure retdouble(inout a int,inout b int)
begin
set a=a*2;
set b=b*2;
end $
delimiter ;
调用
set @a=2,@b=5;
call retdouble(@a,@b);
select @a,@b
#7. 删除题目5的存储过程
drop procedure beauty_limit
show procedure status
#8. 查看题目6中存储过程的信息
show create procedure 'retdouble';
show procedure status like 'retdouble';
存储函数
#0. 准备工作
USE test15_pro_func;
CREATE TABLE employees
AS
SELECT * FROM atguigudb.`employees`;
CREATE TABLE departments
AS
SELECT * FROM atguigudb.`departments`;
#无参有返回
#1. 创建函数get_count(),返回公司的员工个数
delimiter $
create function get_count()
returns int
begin
return (select count(*) from employees);
end $
delimiter ;
测试
select get_count()
#有参有返回
#2. 创建函数ename_salary(),根据员工姓名,返回它的工资
delimiter $
create function ename_salary(ename varchar(25))
returns double
begin
return (select salary from employees where last_name=ename);
end $
delimiter ;
测试
select ename_salary('Abel');
#3. 创建函数dept_sal() ,根据部门名,返回该部门的平均工资
delimiter $
create function dept_sal1(dname varchar(20))
returns double
begin
return (
select avg(salary)
from employees e
join departments d on e.department_id=d.department_id
where d.department_name=dname
);
end $
delimiter ;
调用
SELECT dept_sal1('Marketing');
#4. 创建函数add_float(),实现传入两个float,返回二者之和
delimiter $
create function add_float(a float,b float)
returns float
begin
return (select a+b from dual);
end $
delimiter ;
调用
select add_float(2,3);


![vector容器 [上]](https://img-blog.csdnimg.cn/b65b7ee01de141059a6716fcc9f4cbfd.png)