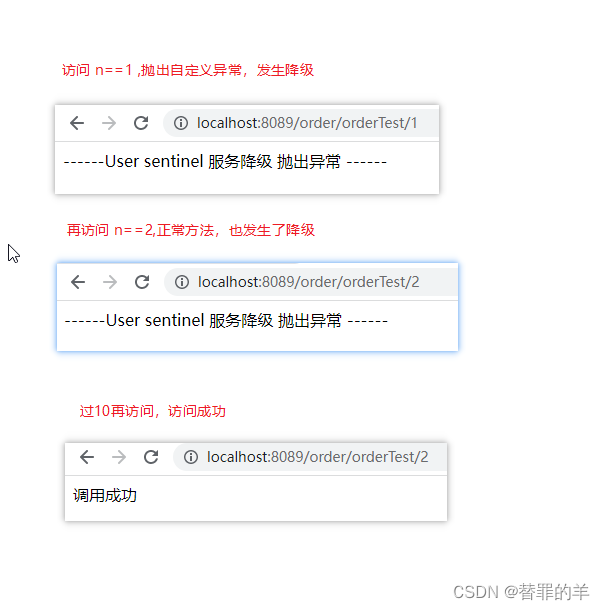
记录一下我看过的利用CNN实现知识推理的论文。
最后修改时间:2023.05.12
目录
1.ConvE
1.1.解决的问题
1.2.优势
1.3.贡献与创新点
1.4.方法
1.4.1 为什么用二维卷积,而不是一维卷积?
1.4.2.ConvE具体实现
1.4.3.1-N scoring
1.5.实验
1.5.1.数据集
1.5.2.实验设置
1.5.3.Inverse Model
1.6.实验结果
1.6.1.去不去除inverse relations
1.6.2.模型效率
1.6.3.消融实验
1.6.4.Indegree和PageRank分析
1.7.总结与感想
2.ConvKB
2.1.解决的问题
2.2.优势
2.3.贡献与创新点
2.4.方法
2.4.1方法介绍
2.4.2.ConvKB与TransE的转换推导
2.5.实验
2.5.1.数据集
2.5.2.实验细节
2.6.实验结果
2.7.总结与感想
1.ConvE
论文:Convolutional 2D Knowledge Graph Embeddings
会议/期刊:2018 AAAI
1.1.解决的问题
(1)以往的模型都太浅了,虽然可以快速用于大型数据集,但是学到的特征表达能力比较差;
(2)另一个比较严重的问题是数据集的泄露问题“test set leakage”,也就是训练集出现过的关系三元组,取了反后,在测试集中又出现了一遍。比如,(A,妈妈,B)在训练集中出现过,(B,女儿,A)又在测试集中出现。这个问题导致一些很简单的rule-based模型也可以达到很好的效果。
1.2.优势
(1)采用多层神经网络,特征表达能力强;
(2)参数量很少,相同的实验效果,参数量比DistMult少8倍,比R-GCN少17倍;
(3)可以高效建模大型数据集常出现的入度高的节点。
1.3.贡献与创新点
(1)设计2D卷积模型,进行链接预测;
(2)设计1-N scoring步骤,提升训练和评估的速度;
(3)参数量少;
(4)随着知识图谱复杂性的提升,ConvE与一些shallow算法的差距成比例增大;
(5)分析了各数据集泄露的问题,并提出了不泄露的版本;
(6)sota。
1.4.方法
1.4.1 为什么用二维卷积,而不是一维卷积?
NLP任务中大多采用的是一维卷积,包括下面要提到的ConvKB算法,但是ConvE却创新的使用了二维卷积。因为二维卷积使得嵌入向量间的交互点变多了,模型的表达能力变强。举个栗子~
一维卷积:
两个一维嵌入分别为和
,两个嵌入concat后得到向量
。
一维卷积核大小为3,那么卷积的过程中,两个向量只有连接点处的值(比如或
)发生了交互,并且交互程度会随着卷积核大小的增加而变深。
二维卷积:
两个二维嵌入分别为和
,两个嵌入concat后得到嵌入
。
二维卷积核大小为3×3,卷积的过程中,卷积核可以建模concat边界线处的交互,特征交互更多。
换一个模式(将嵌入的几行调换一下位置),得到,那么可以发现交互的点更多了。
1.4.2.ConvE具体实现
链接预测算法一般由编码模块和打分模块构成,编码模块负责得到实体和关系的嵌入向量,打分模块负责为三元组打分。
ConvE由卷积层和全连接层构成。
下面是ConvE的算法流程图:
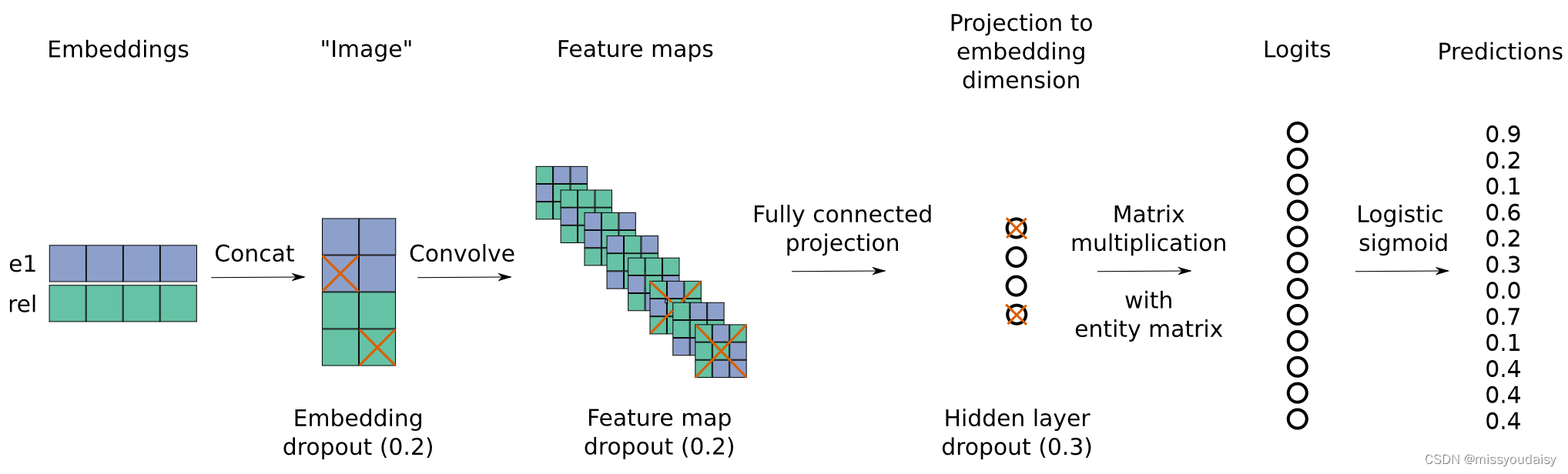
步骤:(可结合上图食用~)
(1)在所有的实体和关系的嵌入矩阵中,查找当前计算的实体和关系的嵌入向量和
;
(2)对嵌入向量做2D的reshape,得到嵌入矩阵和
,维度从
变为
;
(3)concat嵌入矩阵和
,并将结果作为卷积的输入,输出
个
的特征图;
(4)将特征图reshape成的向量,并利用全连接层将向量映射为
维;
(5)然后将该向量与实体嵌入向量做内积,进行匹配,得到分数。这里涉及到1-N scoring,后面会讲到。
(6)为了训练,对分数进行logistic sigmoid函数计算,得到最终分数。
打分函数:
![]()
是ReLU激活函数。
损失函数:
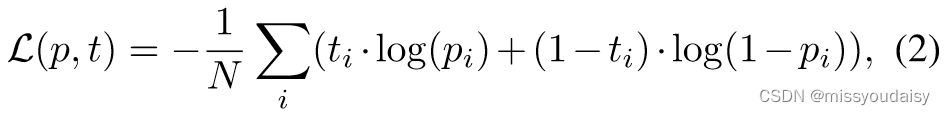
如果三元组存在,为1,否则,为0。最小化损失函数。
Dropout:
作者还使用了很多种dropout手段,包括对嵌入矩阵、卷积后的特征图和全连接层后的输出进行不同概率的dropout。(可以看一下上面的流程图)
1.4.3.1-N scoring
1-N scoring主要是为了算法加速,评估速度可以提升300倍。
1-1 scoring:对三元组(s,r,o)打分
1-N scoring:给定(s,r),然后尾实体取全部实体,同时进行打分。
并且作者说1-N scoring达到了batch normalization的效果。如果将N变为0.1N,那么计算速度变快,收敛速度变慢,这与降低batch的大小是一样的效果。
1.5.实验
1.5.1.数据集
WN18(WN18RR:去除WN18中的inverse三元组)、FB15k(FB15k-237:去除FB15k中的inverse三元组)、YAGO-3、Countries。
1.5.2.实验设置
参数采用网格搜索的方法获得。
作者还研究了对2D卷积做修改对结果的影响:(1)用全连接层代替2D卷积;(2)用1D卷积代替2D卷积。(3)不同filter大小。
1.5.3.Inverse Model
主要是为了证明inverse relation的危害。作者构建了一个之前讲过的简单的rule-based模型,只学习inverse relations,没有学习知识图谱具体的语义,称作inverse model。
怎么确定是不是inverse relations呢?(inverse model怎么做的呢?)
假定inverse relations量与总数据量的比例正比于训练集量与总数据量的比例。判断(s,r1,o)和(o,r2,s)同时出现的概率是否大于等于,其中
和
分别表示验证集和测试集占总数据量的比例,如果满足,则表明r1和r2互为inverse关系。
在测试inverse model的时候,验证测试样本在测试集外有没有inverse matches:如果找到了k个inverse matches,那么对这k个matches进行排名;如果没有找到match,那么随机为测试三元组生成排名。
(这里之前理解错了,感谢这位博主:论文浅尝 | Convolutional 2D knowledge graph embedding_开放知识图谱的博客-CSDN博客)
1.6.实验结果
采用filtered设置,即评估时只排序没在train、test、validate中出现过的三元组。
1.6.1.去不去除inverse relations


可以看到,如果不去除数据集中的inverse relations(WN18和FB15k),那么简单的inverse model可以得到很好的结果。inverse model在FB15k-237和YAGO3-10上的效果很差,因为没有inverse relations。但是为什么在WN18RR上的效果还行呢?因为生成WN18RR的时候,没有去掉对称关系,如“similar to”,这个被inverse model学到了。(这段应该是这个意思,如有错误,麻烦指出哈~)
1.6.2.模型效率

可以看出,ConvE仅凭0.23M的参数量就打败了DistMult。
1.6.3.消融实验
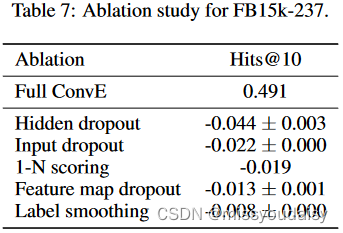
验证各个环节对ConvE模型的影响,其中隐藏层dropout(全连接层输出的dropout)的影响是最大的。
1.6.4.Indegree和PageRank分析
Indegree
ConvE在YAGO3-10、FB15k-237数据集上效果好,因为这些数据集具有相同的特点,就是节点有非常高的relation-specific indegree。比如,节点“美国”对于关系“出生于”的indegree超过10000。而这10000多个节点差异非常大,包括演员、作家、商人等,正是ConvE这种复杂模型才能建模这种差异。
WN18RR和WN18就是indegree低的数据集,对于这种数据集,shallow模型就足以表达了。
实验设定:
在四个数据集上做实验:low-WN18、high-FB15k、high-WN18(去掉indegree低的节点)、low-FB15k(去掉indegree高的节点)。
实验结论:
deeper模型,如ConvE,适合建模复杂的知识图谱(FB15k);shallow模型,如DistMult,适合建模简单一点的知识图谱(WN18)。
PageRank
PageRank度量有向图中节点的重要程度,通过迭代计算节点的indegree得到。一个节点的indegree值正比于该节点的indegree、邻居的indegree、邻居的邻居的indegree,以及所有其他节点的indegree。这里应该能感受到迭代计算的需要了吧。
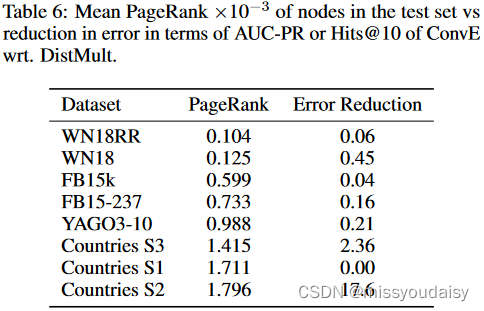
经统计,WN18中PageRank值最高的节点的PageRank比YAGO3-10和Countries中的最高PageRank值小一个数量级,比FB15k中的最高PageRank小4倍。
作者发现,DistMult和ConvE在Hits@10指标上的性能差异正比于测试集的平均PageRank值,可以看一下Table 6。
1.7.总结与感想
ConvE模型是首个用卷积神经网络解决知识推理问题的模型,看完这篇论文觉得受益匪浅。作为一个从视觉转NLP的人,一直也在思考二者结合和技术通用的问题。作者利用了视觉中常用的2D卷积,提升特征的表达能力。还使用了多种dropout方法、1-N scoring等。然后,我觉得作者特别好的一个点就是分析了数据集的问题,并且对问题做了修正。最后,我觉得作者的实验做的也非常的充分,实验环节设计的也非常合理。
2.ConvKB
论文:A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network
会议/期刊:Proceedings of NAACL-HLT 2018
2.1.解决的问题
没明确说。
2.2.优势
首先,作者先分析了一下ConvE的缺点:ConvE的输入只考虑了实体和关系两个嵌入向量间的局部关系,没有考虑整个三元组(头实体,关系,尾实体)(全局 global),并且忽略了transition-based模型中最重要的transitional特性。
2.3.贡献与创新点
(1)设计了ConvKB模型,用神经网络表示transition-based模型中的transitional特性;
(2)在WN18RR和FB15k-237数据集上验证算法,SOTA。
2.4.方法
2.4.1方法介绍
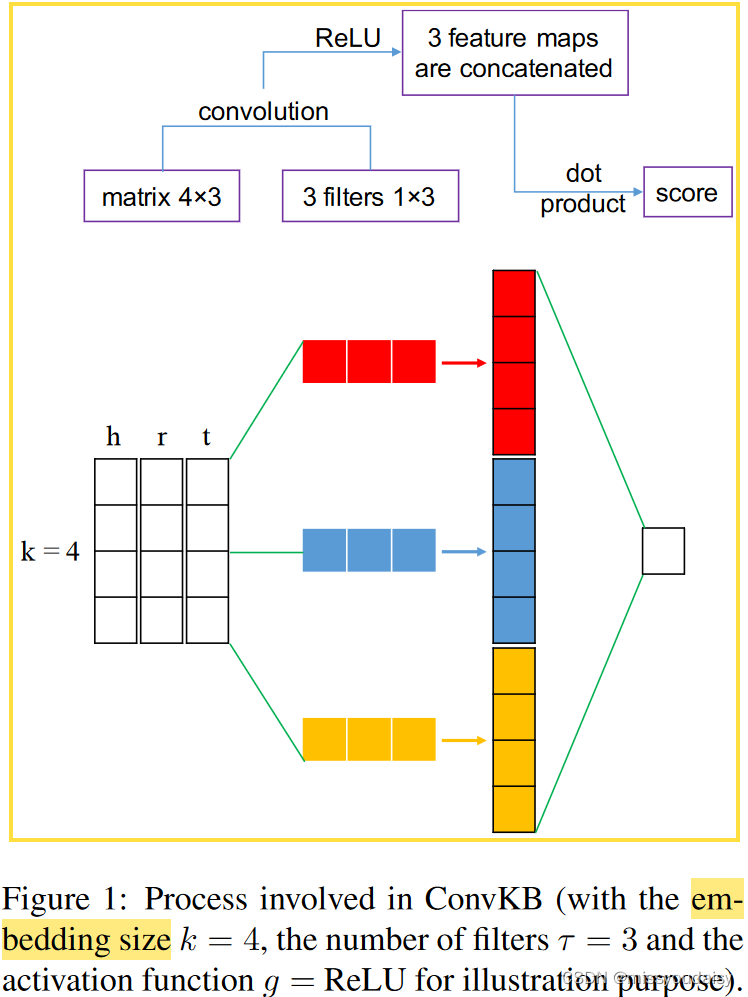
流程:
(1)求实体和关系
的
维嵌入向量,
、
、
;
(2)每个三元组的嵌入可表示为的矩阵,
;
(3)将矩阵输入卷积层,生成特征图:卷积层一共有个
的filters,每一个filter循环处理矩阵的每一维,得到
的特征图。最终得到
个
的特征图;
(4)将所有的特征图concat成单一的特征向量,也就是维;
(5)特征向量与权重向量做点积,得到当前三元组的分数,用来判断三元组是否valid。
第个特征图的计算公式:

ConvKB的打分函数为:
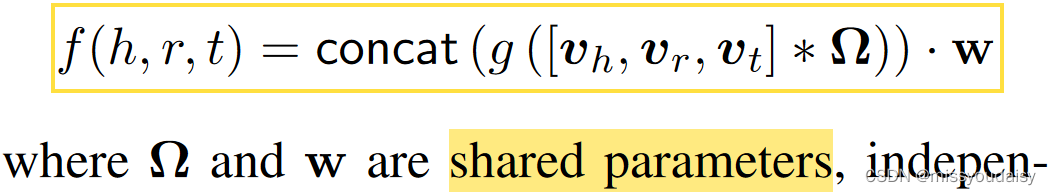
注意:这里的打分函数给出的是每个三元组的implausibility score,也就是三元组越假,分数就越高,三元组越真,分数就越低。这里与ConvE的是反的,ConvE应该是三元组越真,分数越高。
损失函数为:

问题:这里我按照正样本负样本的得分都是正的来推导,推不出minimize loss这个做法,难道负样本的得分其实是负的?取绝对值后大吗?下面贴一个原文对打分函数的解释:

2.4.2.ConvKB与TransE的转换推导
先附上一个各模型的打分函数表:

下面一段文字是ConvKB转换为TransE的参数设置:

推导一下~
所以,ConvKB可以看作是TransE的延申,可以建模全局关系。
2.5.实验
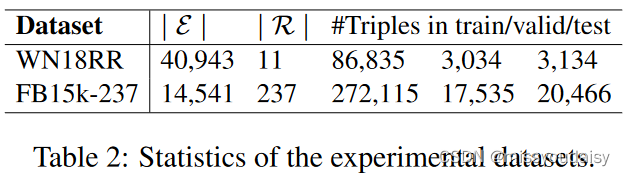
2.5.1.数据集
WN18RR和FB15k-237。
2.5.2.实验细节
按照伯努利分布采样corrupted样本中的头实体或尾实体。
利用TransE来初始化实体和关系的嵌入。
2.6.实验结果
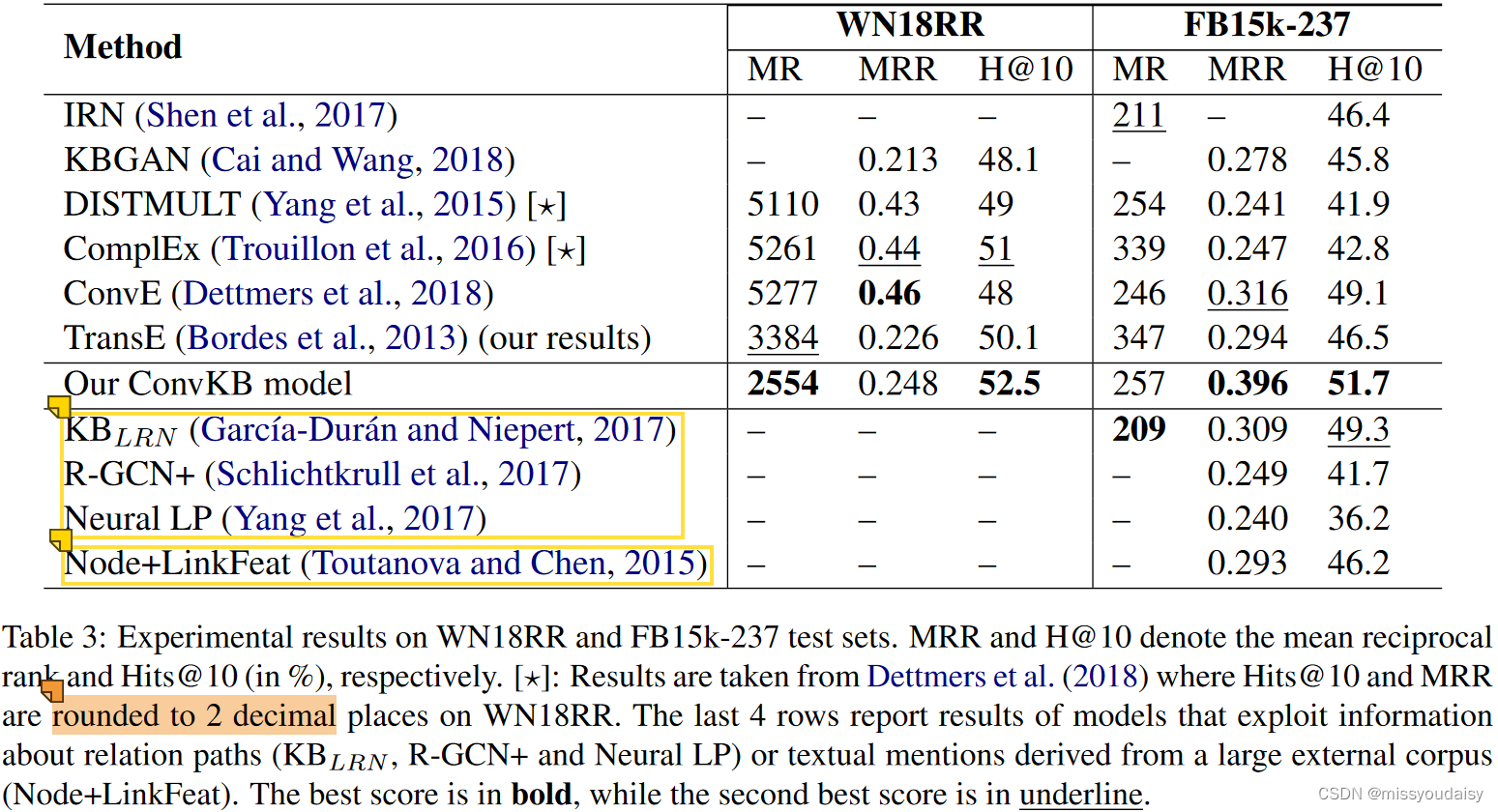
2.7.总结与感想
感觉与ConvE比,这篇的思想还是更常规一点,二者虽然都是从CNN的角度来解决知识表示问题,但是思路还是完全不一样的。

![[SWPUCTF] 2021新生赛之Crypto篇刷题记录(11)](https://img-blog.csdnimg.cn/d5dc9f95a3c345719652cfbb39455ccb.png)