NLG | CLIP | Diffusion Model
GAN | AIGC | Stable Diffusion
随着CLIP、DALL·E、Diffusion Model、Magic3D、Stable Diffusion等技术的快速发展,AIGC在全球各大科技巨头间可谓是高频词汇,连带着AI这个老生常谈的话题也一并火热起来。
去年三月,OpenAI发布了人工智能绘画产品DALL·E,后来升级到DALL·E 2。谷歌和Meta紧随其后,并且进一步发展出文字转视频功能。今年8月,Stable Diffusion正式开源。而在日前,英伟达也宣布加入AIGC的赛道,发布了Magic3D。
那么AIGC是怎么突然火起来的?又是否是更通用的AI的起点?会不会和原创工作者“抢饭碗”?
注:由于篇幅有限需要更多 AIGC 详细资料,请在公众号末尾留下您的邮箱,小编会将PDF文件发您邮箱,共同进步学习。

AIGC高性能计算一体机
深度学习与AIGC
AIGC使用人工智能技术来生成内容。2021年之前,AIGC主要生成文字,新一代模型可以处理的格式内容包括:文字、语音、代码、图像、视频、机器人动作等。AIGC被认为是继专业生产内容PGC、用户生成内容UGC之后的一种新的内容创作方式,可以充分发挥其在创意、表现力、迭代、传播、个性化等方面的技术优势。2022年,AIGC以惊人的速度发展。年初还处于技艺生疏阶段,几个月后达到专业水平,足以以假乱真。与此同时,AIGC的迭代速度呈指数级爆发,其中深度学习模型的不断完善、开源模型的推广以及大模型商业化的可能,成为AIGC发展的“加速度”。
一、深度学习模型是AIGC加速普及的基础
视觉信息在网络中一直具有很强的传播力且易被大众感知,具有跨平台、跨领域、跨人群的优势,自然容易被记住和理解。同时视觉信息应用场景广泛,因此生成高质量的图像成为当前AI领域的一个现象级功能。
2021年,OpenAI团队将开源跨模态深度学习模型CLIP(对比语言-图像预训练,以下简称“CLIP”)。CLIP模型可以将文字和图像关联起来,比如文字“狗”和狗的图像进行关联,并且关联特征非常丰富。所以CLIP模型有两个优点:
1、可以同时理解自然语言和分析计算机视觉,实现图文匹配。
2、为有足够多的有标记的“文本-图像”进行训练,CLIP模型大量使用互联网上的图片,这些图片一般携带各种文本描述,成为CLIP的天然训练样本。
据统计,CLIP模型在网络上收集了超过40亿的“文本-图像”训练数据,为AIGC的后续应用,尤其是输入文本生成图像/视频落定奠定了基础。
GAN(Generative Adver Serial Network)虽然是很多AIGC的基础框架,但它有三个缺点:
1、对输出结果的控制能力弱,容易产生随机图像;
2、生成的图像分辨率低;
3、由于需要使用鉴别器来判断生成的图像是否与其他图像属于同一类别,因此生成的图像是对已有作品的模仿,而非创新。所以依靠GAN模型很难生成新的图像,也无法通过文本提示生成新的图像。

AIGC相关深度学习模型汇总表
随后出现的Diffusion扩散化模型,真正让文本生成图像的AIGC应用为大众所熟知,也是2022年下半年Stable Diffusion应用的重要推手。Diffusion有两个特点:
1、在图像中加入高斯噪声,通过破坏训练数据进行学习,然后找出如何逆转这个噪声过程来恢复原始图像。训练后,模型可以从随机输入中合成新数据。
2、Stable Diffusion通过数学变换将模型的计算空间从像素空间降低到一个势空间的低维空间,大大减少了计算量和时间,大大提高了模型训练的效率。这种算法模式的创新直接推动了AIGC技术的突破性进展。

总的来说,AIGC在2022年实现了突破,主要是在深度学习模型上取得了很大的进步:首先基于海量互联网图片训练了CLIP模型,推动AI绘画模型结合创新;其次,Diffusion扩散化模型实现算法创新;最后,利用潜在空间的降维方法降低Diffusion模型内存和时间消耗大的问题。所以,AIGC绘画之所以能帮助大众画出各种充满想象力的画,有赖于大量深度学习模型的不断完善。
二、 “开源模式”成为AIGC发展催化剂
在算法模型方面,AIGC的发展离不开开源模型的推动。以深度学习模型CLIP为例,开源模型加速了CLIP模型的广泛应用,使其成为目前最先进的图像分类人工智能,让更多的机器学习从业者将CLIP模型嫁接到其他AI应用中。与此同时,AIGC绘画最受欢迎的应用稳定扩散(Stable Diffusion)已经正式开源(包括模型权重和代码),这意味着任何用户都可以使用它来建立特定文本到图像的创作任务。稳定扩散的开源直接引发了2022年下半年AIGC的广泛关注。短短几个月,大量二次开发出现,从模型优化到应用扩展,大大降低了用户使用AIGC进行创作的门槛,提高了创作效率,长期占据GitHub热榜第一。
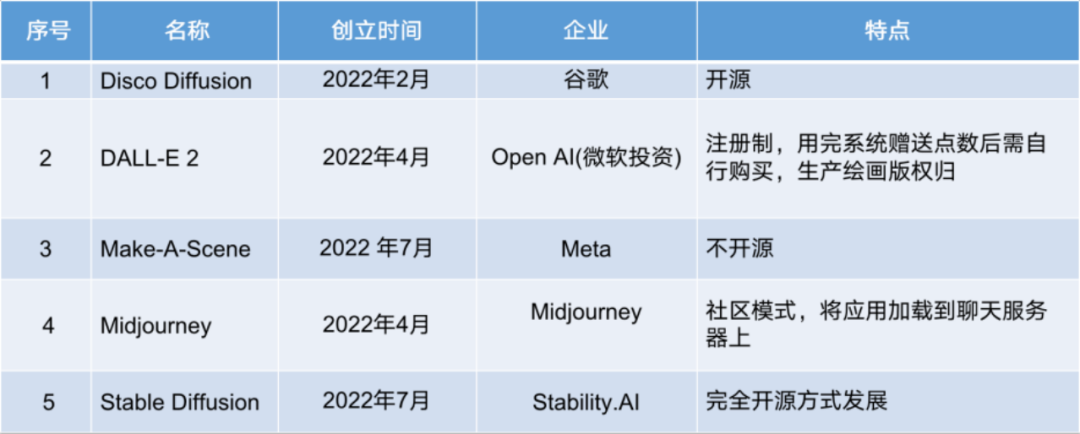
AIGC绘画应用系统汇总表
在训练数据集方面,机器学习离不开大量的数据学习。作为全球非营利性机器学习研究机构,LAION于2022年3月开放了最大的开源跨模态数据库LAION-5B,使近60亿个“文本-图像”对可供训练,从而进一步加速了AI图像生成模型的成熟,帮助研究人员加速从文字到图像的模型生成。正是CLIP和LAION的开源模型构建了当前AI图像生成应用的核心。未来,随着模型的稳定,开源将成为AIGC走向成熟的催化剂。源模型有望使相关模型成为海量应用、网络和服务的基础,应用层面的创造力有望迎来拐点。
AIGC发展历程与概念
1950年,艾伦·图灵在论文《计算机器与智能》中提出了著名的“图灵测试”,给出了一种确定机器是否具有“智能”的测试方法,即机器能否模仿人类的思维方式“生成”内容,然后与人进行交互。某种程度上,从那时起,人工智能就被期待用于内容创作。经过半个多世纪的发展,随着数据的快速积累、算力性能提升和算法效力增强,今天的人工智能不仅可以与人类进行交互,还可以进行写作、编曲、绘画、视频制作等创意工作。2018年,人工智能生成的画作在佳士得拍卖行以43.25万美元成交,成为全球首个售出的人工智能艺术品,受到各界关注。随着人工智能在内容创作中的应用越来越多,人工智能生成内容(AIGC)的概念悄然兴起。
一、AIGC 发展历程
结合人工智能的演进,AIGC的发展大致可以分为三个阶段,即早期萌芽阶段(20世纪50年代至90年代中期)、沉淀积累阶段(20世纪90年代中期至21世纪10年代中期)、快速发展阶段(21 世纪 10 年代中期至今)。
1、早期萌芽阶段(1950s-1990s)
受当时科技水平限制,AIGC仅限于小规模实验。1957年,Lejaren Hiller和LeonardIsaacson通过将计算机程序中的控制变量改为音符,完成了历史上第一部由计算机创作的音乐作品——弦乐四重奏《依利亚克组曲》。1966年,约瑟夫·韦岑鲍姆(Joseph Weizenbaum)和肯尼斯·科尔比(Kenneth Colbv)共同开发了世界上第一个机器人“伊莉莎(Eliza)”,可以通过关键字扫描和重组来完成交互式任务。20世纪80年代中期,IBM基于隐马尔可夫模型创造了声控打字机“Tangora”大概能处理两万字。从80年代末至 90年代中,由于高昂的系统成本无法带来可观的商业变现,各国政府减少了在人工智能领域的投入,AIGC也没有取得重大突破。
2、沉淀积累阶段(1990s-2010s)
AIGC从实验性向实用性逐渐转变。2006年,深度学习算法取得重大突破。与此同时,图形处理单元(GPU)和张量处理器(TPU)等计算设备的性能持续提升。互联网使得数据规模迅速扩大,为各类人工智能算法提供了海量的训练数据,使人工智能的发展取得了重大进展。然而,AIGC仍然受到算法瓶颈的限制,无法很好地完成创作任务应用仍然有限,效果有待提升。2007 年,纽约大学人工智能研究员罗斯·古德温装配的人工智能系统通过对公路旅行中的一切所见所闻进行记录和感知,撰写出小说《1The Road》。作为世界上第一部完全由人工智能创作的小说,其象征意义远大于实际意义,整体可读性不强,拼写错误、修辞空洞、逻辑缺失明显。2012年,微软公开展示了全自动同声传译系统。基于深度神经网络通过语音识别、语言翻译、语音合成等技术等技术生成中文语音。
3、快速发展阶段(2010s-至今)
2014年以来,随着以生成式对抗网络(GAN)为代表的深度学习算法的提出和迭代更新,AIGC迎来了一个新的时代。生成内容百花齐放,效果逐渐逼真至人类难以分辨。2017年,微软人工智能少女“小冰”推出全球首个由人工智能创作的100%诗集《阳光失去了玻璃窗》。2018年,Nvidia发布的StyleGAN机型可以自动生成图片,现在已经升级到第四代机型StyleGAN-XL,其生成的高分辨率图片,人眼很难分辨真假。2019年,DeepMind发布了生成连续视频的DVD-GAN模型,在草原、广场等清晰场景中表现突出。2021年,OpenAI推出了DALL-E和一年后的升级版DALL-E-2,主要用于生成文本和图像之间的交互内容。用户只需输入简短的描述性文字,DALL-E-2就能创作出相应的高质量的卡通、写实、抽象画。

AIGC发展历程
二、AIGC的概念和内涵
目前,AIGC的概念还没有统一规范的定义。AIGC对国内产学研的理解是“继专业生成内容(PGC)和用户生成内容(UGC)之后,利用人工智能技术自动生成内容的新型生产方式”。国际上对应的术语是“人工智能合成媒体(AI-generated Media 或 Synthetic Media)”,其定义是“通过人工智能算法对数据或媒体进行生产、操纵和修改的统称”。综上所述,我们认为AIGC既是从内容生产者视角进行分类的一类内容,又是一种内容生产方式,还是用于内容自动化生成的一类技术集合。
为了帮助不同领域的受众群体更好地了解AIGC,现在从发展背景、技术能力、应用价值三个方面深入剖析了它的概念。
1、发展背景
AIGC的兴起源于深度学习技术的快速突破和数字内容供给需求的不断增加。
1)技术进步推动了AIGC可用性的提高
在人工智能发展的初期,虽然在AIGC上进行了一些初步的尝试,但由于各种因素,相关算法大多基于预定义的规则或模板,远没有达到智能创造的水平。近年来,基于深度学习算法的AIGC技术快速迭代,彻底打破了模板化、公式化、小范围的限制,可以快速灵活地生成不同模式的数据内容。
2)海量需求牵引 AIGC 应用落地
随着数字经济与实体经济融合的不断深入,以及Meta、微软、字节跳动等平台巨头的数字场景向元宇宙的转型,人类对数字内容总量和丰富度的整体需求不断增加。数字内容的生产取决于想象力、制造能力和知识水平;传统的内容生产方式受限于人力资源有限的制造能力,逐渐无法满足消费者对数字内容的需求,供给侧产能瓶颈日益凸显。基于以上原因,AIGC已被广泛应用于各个行业,其市场潜力也逐渐显现。
2、技术能力
根据面向对象和实现功能的不同,AIGC可以分为三个层次。
1)智能数字内容孪生
其主要目标是建立从现实世界到数字世界的映射,并将物理属性(如大小、纹理、颜色等)和社会属性(如主体行为、主体关系等)在现实世界中高效且可感知进行数字化。
2)智能数字内容编辑
其主要目的是建立数字世界与现实世界的双向交互。基于数字内容孪生的基础上,从现实世界控制和修改虚拟数字世界中的内容。同时利用数字世界高效率仿真和低成本试错的优势,为现实世界的应用提供快速迭代能力。
3)智能数字内容创作
其主要目标是让人工智能算法具备内容创作和自我演化的能力,由此形成的AIGC产品具备类似甚至超越人类的创作能力。以上三个层面的能力共同构成了AIGC的能力闭环。
3、应用价值
AIGC将有望成为数字内容创新发展的新引擎,为数字经济发展注入新动能。
1)AIGC 能够以优于人类的制造能力和知识水平承担信息挖掘、素材调用、复刻编辑等基础性机械劳动,从技术层面实现以低边际成本、高效率的方式满足海量个性化需求;同时能够创新内容生产的流程和范式,为更具想象力的内容、更加多样化的传播方式提供可能性,推动内容生产向更有创造力的方向发展。
2)AIGC可以支撑数字内容与其他产业的多维度互动、融合渗透,从而孕育新的商业模式,打造经济发展的新增长点,为千行百业的发展提供新动能。此外,从2021年开始,元宇宙呈现出超乎想象的爆发式发展;作为数字与现实融合的“终极”数字载体,元宇宙将具有持久性、实时性、创造性等特征。它还将加速物理世界的再生产,并通过AIGC创造无限的内容,从而实现自发的有机增长。
三、AIGC关键技术落地实施
目前AIGC生成正在完成从简单的降本增效(以生成金融/体育新闻为代表)向创造额外价值(以提供绘画创作素材为代表)转移,跨模态/多模态内容成为关键的发展节点。
技术视角下,以下场景将成为未来发展的重点:文本-图像 视频的跨模态生成、2D到3D生成、多模态理解结合生成。后文将对以上技术场景的技术原理、现有进展、关键瓶颈等进行展开。
商业视角下、未来3年内,虚拟人生成和游戏AI这两种综合性的AIGC场景将趋于商业化成熟。
1、文本生成
以结构性新闻撰写、内容续写、诗词创作等细分功能为代表。基于NLP技术的文木生成可以算作是AIGC中发展最早的一部分技术,也已经在新闻报道、对话机器人等应用场景中大范围商业落地。
一方面,2020年,1750亿参数的GPT-3在问答、摘要、翻译、续写等语言类任务上均展现出了优秀的通用能力。证明了“大力出奇迹”在语言类模型上的可行性。自此之后,海量数据、更多参数、多元的数据采集渠道等成为国内清华大学、智源研究院、达摩院、华为、北京大学、百度等参与者的关注点。
目前,大型文本预训练模型作为底层工具,商业变现能力逐渐清晰。以GPT-3为例,其文木生成能力已被直接应用于Writesonic、Conversion.ai、SnazzyAl、Copysmith、Copy.ai、Headlime等文本写作/编辑工具中。同时也被作为部分文本内容的提供方,服务于Al dungeon等文本具有重要意义的延展应用领域。
另一方面,以Transformer架构为重要代表,相关的底层架构仍在不断精进。研究者们正通过增加K-adapter、优化Transformer架构,合理引入知识图谱及知识库、增加特定任务对应Embeddina等方式,增加文本对于上下文的理解与承接能力、对常识性知识的嵌入能力、中长篇幅生成能力、生成内容的内在逻辑性等。
1)应用型文本生成
应用型文本大多为结构化写作,以客服类的聊天问答、新闻撰写等为核心场景。2015年发展至今,商业化应用已较为广泛,最为典型的是基于结构化数据或规范格式,在特定情景类型下的文本生成,如体育新闻、金融新闻、公司财报、重大灾害等简讯写作。据分析师评价,由AI完成的新闻初稿已经接近人类记者在30分钟内完成的报道水准。Narrative Science 创始人甚至曾预测,到 2030 年, 90%以上的新闻将由机器人完成。
在结构化写作场景下,代表性垂直公司包括Automated Insights(美联社Wordsmith)、Narrative Science、textengine.io、AX Semantics、Yseop、Arria、Retresco、Viable、澜舟科技等。同时也是小冰公司、腾讯、百度等综合性覆盖AIGC领域公司的重点布局领域。
2)创作型文本生成
创作型文本主要适用于剧情续写、营销文本等细分场景等,具有更高的文本开放度和自由度,需要一定的创意和个性化,对生成能力的技术要求更高。
我们使用了市面上的小说续写,文章生成等AIGC工具。发现长篇幅文字的内部逻辑仍然存在较明显的问题、且生成稳定性不足,尚不适合直接进行实际使用。据聆心智能创始人黄民烈教授介绍,目前文字生成主要捕捉的是浅层次,词汇上统计贡献的问题。但长文本生成还需要满足语义层次准确、在篇章上连贯通顺的要求,长文本写作对于议论文写作、公文写作等等具有重要意义。未来四到五年,可能会出现比较好的千字内容。
除去本身的技术能力之外,由于人类对文字内容的消费并不是单纯理性和基于事实的,创作型文本还需要特别关注情感和语言表达艺术。我们认为,短期内创作型文本更适合在特定的赛道下,基于集中的训练数据及具体的专家规则进行场景落地。
在创作型文本领域,代表性的国内外公司包括Anyword、Phrasee、Persado、Pencil、Copy.ai、Friday.ai、Retresco、Writesonic、Conversion.ai、Snazzy Al、Rasa.io、LongShot.AI、彩云小梦等。
3)文本辅助生成
除去端到端进行文本创作外,辅助文本写作其实是目前国内供给及落地最为广泛的场景。主要为基于素材爬取的协助作用,例如定向采集信息素材、文本素材预处理、自动聚类去重,并根据创作者的需求提供相关素材。尽管目前能够提升生产力,但我们认为相对于实现技术意义上的AI生成,能否结合知识图谱等提供素材联想和语句参考等更具有实用意义。
这部分的国内代表产品包括写作猫、Gilso写作机器人、Get写作、写作狐、沃沃AI人工智能写作。
4) 重点关注场景
长期来看,我们认为闲聊型文本交互将会成为重要潜在场景,例如虚拟伴侣、游戏中的NPC个性化交互等。2022年夏季上线的社交AlGC叙事平台Hidden Door以及基干GPT.3开发的文木探索类游戏Aldunaeon均已获得了不错的消费者反馈。随着线上社交逐渐成为了一种常态,社交重点向转移AI具有其合理性,我们预估未来1-2年内就会出现明显增长。目前较为典型的包括小冰公司推出的小冰岛,集中在精神心理领域的聆心智能、开发了AI dungeon的Latitude.io等。

2、音频及文字一音频生成
整体而言,此类技术可应用于流行歌曲、乐曲、有声书的内容创作,以及视频、游戏、影视等领域的配乐创作,大大降低音乐版权的采购成本。我们目前最为看好的场景是自动生成实时配乐、语音克隆以及心理安抚等功能性音乐的自动生成。
1)TTS(Text-to-speech)场景
TTS在AIGC领域下已相当成熟,广泛应用于客服及硬件机器人、有声读物制作、语音播报等任务。例如倒映有声与音频客户端“云听”APP合作打造AI新闻主播,提供音频内容服务的一站式解决方案,以及喜马拉雅运用TTS技术重现单田芳声音版本的《毛氏三兄弟》和历史类作品。这种场景为文字内容的有声化提供了规模化能力。
目前技术上的的关键,在于如何通过富文本信息(如文本的深层情感、深层语义了解等)更好的表现其中的抑扬顿挫以及基于用户较少的个性化数据得到整体的复制能力(如小样本迁移学习)。基于深度学习的端到端语音合成模式也正在逐步替代传统的拼接及参数法,代表模型包括WaveNet、Deep Voice及Tacotron等。
目前的垂直代表公司包括倒映有声、科大讯飞、思必驰(DUl)、Readspeaker、DeepZen和Sonantic。
随着内容媒体的变迁,短视频内容配音已成为重要场景。部分软件能够基于文档自动生成解说配音,上线有150+款包括不同方言和音色的AI智能配音主播。代表公司有九锤配音、加音、XAudioPro、剪映等。
该技术目前被应用于虚拟歌手演唱、自动配音等,在声音IP化的基础上,对于动画、电影、以及虚拟人行业有重要意义。代表公司包括标贝科技、Modulate、overdub、replika、Replica Studios、Lovo、Voice mod. Resemble Ai、Respeecher、DeepZen、Sonantic、VoicelD、Descript。
2)乐曲/歌曲生成
AIGC在词曲创作中的功能可被逐步拆解为作词(NLP中的文本创作/续写)、作曲、编曲、人声录制和整体混音。目前而言,AIGC已经支持基于开头旋律、图片、文字描述、音乐类型、情绪类型等生成特定乐曲。
其中,Al作曲可以简单理解为“以语言模型(目前以Transformer为代表,如谷歌Megenta、OpenAI Jukebox、AIVA等)为中介,对音乐数据进行双向转化(通过MIDI等转化路径)”。此方面代表性的模型包括MelodvRNN、Music Transformer。据Deepmusic介绍,为提升整体效率,在这一过程中,由于相关数据巨大往往需要对段落、调性等高维度的乐理知识进行专业提取,而节奉、音高、音长等低维度乐理信息由AI自动完成提取。
通过这一功能,创作者即可得到AI创作的纯音乐或乐曲中的主旋律。2021年末,贝多芬管弦乐团在波恩首演人工智能谱写完成的贝多芬未完成之作《第十交响曲》,即为AI基于对贝多芬过往作品的大量学习,进行自动续写。
Al编曲则指对AI基于主旋律和创作者个人的偏好,生成不同乐器的对应和弦(如鼓点、贝斯、钢琴等),完成整体编配。在这部分中,各乐器模型将通过无监督模型,在特定乐曲/情绪风格内学习主旋律和特定要素间的映射关系,从而基于主旋律生成自身所需和弦。对于人工而言,要达到乐曲编配的职业标准,需要7-10年的学习实践。
人声录制则广泛见于虚拟偶像的表演现场(前面所说的语音克隆),通过端到端的声学模型和神经声码器完成可以简单理解为将输入文本替换为输入MIDI数据的声音克隆技术。混音指将主旋律、人声和各乐器和弦的音轨进行渲染及混合,最终得到完整乐曲。该环节涉及的AI生成能力较少。
该场景下的代表企业包括Deepmusic、网易-有灵智能创作平台、Amper Music、AIVA、Landr、IBM WatsonMusic、Magenta、Loudly、Brain.FM、Splash、Flow machines。其中,自动编曲功能已在国内主流音乐平台上线,并成为相关大厂的重点关注领域。以QQ音乐为例,就已成为Amper music的API合作伙伴。
对这一部分工作而言,最大的挑战在于音乐数据的标注。在标注阶段,不仅需要需要按时期、流派、作曲家等特征,对训练集中乐曲的旋律、曲式结构、和声等特征进行描述,还要将其有效编码为程序语言。此外,还需要专业人员基于乐理进行相关调整润色。以Deepmusic为例,音乐标注团队一直专注在存量歌曲的音乐信息标注工作上,目前已经形成了全球最精确的华语歌曲音乐信息库,为音乐信息检索(MIR)技术研究提供数据支持。
3)场景推荐
以乐曲二创,辅助创作等场量为代表,Al编曲将在短期内成为A音频生成中的快速成长赛道。特别是由于可以指定曲目风格、情绪、乐器等,AIGC音乐生成对于影视剧、游戏等多样化、乃至实时的背景音乐生成有重要意义。
3、视频生成
视频生成将成为近期跨模态生成领域的中高潜力场景。其背后逻辑是不同技术带来的主流内容形式的变化。本部分主要包括视频属性编辑、视频自动剪辑、视频部分编辑。
1) 视频属性编辑
例如视频画质修复、删除画面中特定主体、自动跟踪主题剪辑、生成视频特效、自动添加特定内容、视频自动美颜等。代表公司包括RunwayML、Wisecut、Adobe Sensei、Kaleido、帝视科技、CCTV AIGC、影谱科技、 Versa(不咕剪辑)、美图影像研究院等。
2)视频自动剪辑
基于视频中的画面、声音等多模态信息的特征融合进行学习,按照氛围、情绪等高级语义限定,对满足条件片段进行检测并合成。目前还主要在技术尝试阶段。典型案例包括Adobe与斯坦福共同研发的AI视频剪辑系统、IBM Watson自动剪辑电影预告片、以及Flow Machine。我国的影谱科技推出了相关产品,能够基于视频中的画面、声音等多模态信息的特征融合进行学习,按照氛围、情绪等高级语义限定,对满足条件片段进行检测并合成。
3)视频部分生成(以Deepfake为典型代表)技术原理
视频到视频生成技术的本质是基于目标参像或视频对源视频进行编辑及调试,通过基于语音等要素逐帧复刻,能够完成人脸替换,人脸再现(人物表情或面部特征的改变)、人脸合成(构建全新人物)甚至全身合成、虚拟环境合成等功能。
其原理本质与图像生成类似,强调将视频切割成帧,再对每一帧的图像进行处理。视频生成的流程通常可以分为三个步骤,即数据提取,数据训练及转换。以人脸合成为例,首先需要对源人物及目标人物的多角度特征数据提取,然后基于数据对模型进行训练并进行图像的合成,最后基于合成的图像将原始视频进行转换,即插入生成的内容并进行调试,确保每一帧之间的流程度及真实度。目前的技术正在提升修改精准度与修改实时性两方面。

4、图像、视频、文本间的跨模态生成
模态是指不同的信息来源或者方式。目前的模态,大多是按照信息媒介所分类的音频、文字、视觉等。而事实上在能够寻找到合适的整体之后,很多信息,诸如人的触觉、听觉、情绪、生理指标,甚至于不同传感器所对应的点云、红外线、电磁波等都能够变为计算机可理解可处理的模态。
对人工智能而言,要更为精准和综合的观察并认知现实世界,就需要尽可能向人类的多模态能力靠拢,我们将这种能力称为多模态学习MM(Multi-modall earnina),其中的技术分类及应用均十分多样,我们可以简单将其分为跨模态理解(例如通过结合街景和汽车的声音判断交通潜在危险、结合说话人的唇形和语音判定其说话内容)和跨模态生成(例如在参考其他图画的基础上命题作画:触景生情并创作诗歌等)。
1)Transformer架构的跨界应用成为跨模态学习的重要开端之一
Transformer架构的核心是Self-Attention机制,该机制使得Transformer能够有效提取长序列特征,相较于CNN能够更好的还原全局。而多模态训练普遍需要将图片提取为区域序列特征,也即将视觉的区域特征和文本特征序列相匹配,形成Transformer架构擅长处理的一维长序列,对Transformer的内部技术架构相符合。与此同时. Transformer架构还具有更高的计算效率和可扩展性,为训练大型跨模态模型奠定了基础。
Vision Transformer将Transformer架构首次应用于图像领域。该模型在特定大规模数据集上的训练成果超出了ResNet。随后,谷歌的VideoBERT尝试了将Transformer拓展到“视频-文木”领域。该模型能够完成看图猜词和为视频生成字幕两项功能,首次验证了Transformer+预训练在多模态融合上的技术可行性。基于Transformer的多模态模型开始受到关注,VILBERT、LXMERT、UNITER、Oscar等纷纷出现。
2)CLIP模型的出现,成为跨模态生成应用的一个重要节点
CLIP,ContrastiveLanguage-Image Pre-training,由OpenAl在2021年提出,图像编码器和文本编码器以对比方式进行联合训练,能够链接文本和图片。可以简单将其理解为,利用CLIP测定图片和文本描述的贴切程度。
自CLIP出现后,“CLIP+其他模型”在跨模态生成领域成为一种较为通用的做法。以Disco Diffusion为例,该模型将CLIP模型和用于生成图像的Diffusion模型进行了关联。CLIP模型将持续计算Diffusion模型随机生成噪声与文本表征的相似度,持续迭代修改,直至生成可达到要求的图像。
AIGC发展面临的挑战
Gartner预测,到2025年,生成式人工智能将占所有生成数据的10%。根据《Generative AI :A Creative New World》的分析,AIGC有潜力产生数万亿美元的经济价值。AIGC吸引了全世界的关注同属,知识产权、技术伦理将面临许多挑战和风险。同时,AIGC距离一般人工智能还有很大差距。
一、AIGC引发“创造性”归属争论
在传统印象中,人工智能在创造性工作领域无法与人类抗衡,主要擅长计算、挖掘,聚焦在海量数据分析领域。人类更擅长创新,比如诗歌、设计、编程等需要创造性的事物上。相比AI下棋,AI进行绘画创作对大众的影响更明显:棋类游戏具有明确的规则和定义,不需要AI具备创造性。但AIGC尤其是通过文字输入可以进行绘画、视频,让没有相关专业能力的人也能做出以假乱真的专业级作品,这就让人对其“创造力”产生了担忧。AI不会取代创作者,但可能会取代不懂AI工具的创作者。

二、知识产权引起创作者的担忧
由于算法模型的进一步完善和成本的快速下降,AIGC大规模商业化成为现实。过去遥不可及的专业能力已经具备从实验室飞入寻常百姓家的可能。同时,AIGC的快速发展和商业应用不仅对创作者产生影响,也对大量以版权为主要收入的企业产生影响。具体来说:
1、AIGC很难被称为“作者”
根据我国《著作权法》的规定,作者只能是自然人、法人或非法人组织。显然AIGC不是法律认可的权利主体,所以不能成为著作权的主体。然而,AIGC应用程序对生成图像的版权持有不同的观点。图片到底属于平台,完全开源还是生成者,目前还没有形成统一意见。
2、AIGC的“作品”仍有争议
根据我国《著作权法》和《著作权法实施条例》的规定,作品是指文学、艺术、科学领域中具有独创性并能以某种有形形式复制的智力成果。AIGC作品具有很强的随机性和算法主导型,能够准确证明AIGC作品侵权的可能性较低。同时,AIGC是否具有原创性也很难一概而论,个案之间差异较大。由于创作者每次新的创作都在无形中对AIGC进行免费培训,这让众多版权机构产生巨大担忧。目前已经有大量的艺术家和创作者宣布禁止AI学习自己的作品,从而保护自己的知识产权。Getty Images、Newgrounds等网站也宣布禁止上传和出售AIGC的作品。
三、距离通用人工智能还有很大差距
虽然现在流行的AIGC系统可以快速生成图像,但这些系统是否能真正理解绘画的意义,从而根据这些含义进行推送和决策,还是一个未知数。
一方面,AIGC系统不能完全将输入文本与生成的图像相关联。例如,当用户测试AIGC系统并输入“骑着马的宇航员”和“骑着宇航员的马”内容时,相关的AIGC系统很难准确生成相应的图像。因此,当前的AIGC系统还没有深刻理解输入文本和输出图像之间的关系。另一方面,AIGC系统很难理解生成图像背后的世界。理解图像背后的世界是判断AIGC是否拥有通用人工智能的关键。目前,AIGC系统仍难以满足相关要求。比如在Stable Diffusion中,输入“画一个人,并把拿东西的部分变成紫色”,在接下来的九次测试,只有一次成功完成,准确率不高。显然,Stable Diffusion不理解人的手是什么。
知名人工智能专家的调查也证实了同样的观点,86.1%的人认为当前的AIGC系统不太了解世界。
四、创作伦理问题尚未有效解决
部分开源AIGC项目对生成图像的监管程度较低。一方面,部分数据集系统使用私人用户的照片进行AI训练,侵权人像图片进行训练的现象屡禁不止。这些数据集是AIGC等图像生成模型的正式训练集之一。比如一些数据集在网上抓取大量患者的医学照片进行训练,不做任何打码模糊处理,对用户的隐私保护堪忧。另一方面,用户使用AIGC生成非法图片,如伪造的名人照片等违禁图片,甚至制作暴力和性相关的绘画,LAION-5B数据库包含色情、种族、恶意等内容,目前海外已经出现了基于Stable Diffusion模型的色情图片生成网站。
由于AI本身还不具备价值判断能力,一些平台已经开始从伦理上进行限制和干预。比如DALL·E2已经开始加强干预,减少性别偏见的产生,防止训练模型产生逼真的个人面孔。然而,相关法律法规的空白和AIGC应用开发者本身的重视程度不足,会引起对AI创造伦理的担忧。
AIGC应用领域
在全球新冠肺炎疫情延宕反复的背景下,各行业对数字内容的需求呈井喷态势,数字世界内容的消耗与供给之间的缺口亟待弥合。凭借其真实性、多样性、可控性和组合性,AIGC有望帮助企业提高内容生产效率,为其提供更丰富多元、动态且可交互的内容或将在传媒、电商、影视、娱乐等数字化程度高、内容需求丰富的行业率先做出重大创新发展。
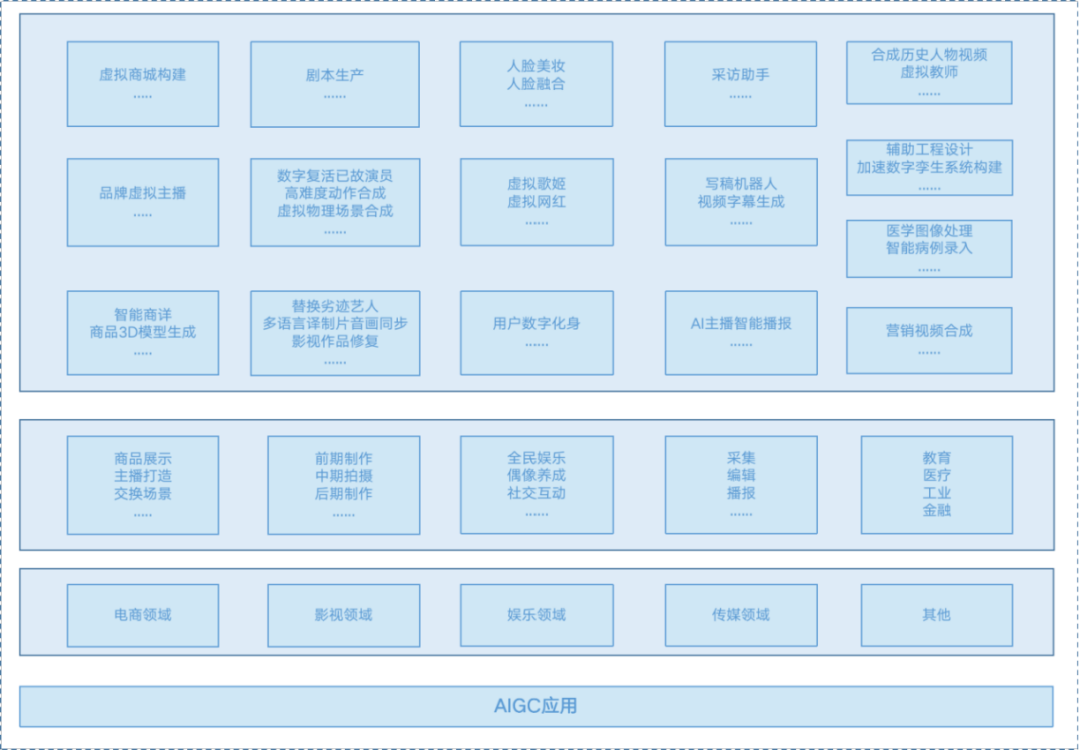
AIGC应用视图
一、AIGC+传媒:人机协同生产,推动媒体融合
近年来,随着全球信息化水平的加快,人工智能与传媒产业的融合发展不断升级。AIGC作为一种新的内容生产方式,充分赋能媒体的内容生产。写作机器人、采访助手、视频字幕生成、语音播报、视频集锦、人工智能合成主播等相关应用不断涌现,并渗透到采集、编辑、传播等的各个环节,深刻改变着媒体的内容生产方式,成为推动媒体融合发展的重要力量。
1、采编环节
1)实现采访录音语音转写,提升传媒工作者的工作体验
借助语音识别技术,将录制的语音转换成文字,有效压缩了稿件制作过程中录音整理的重复工作,进一步保证了新闻的时效性。在2022年冬奥会期间,科大讯飞的智能录音笔通过跨语种的语音转写助力记者2分钟快速出稿。
2)实现智能新闻写作,提升新闻资讯的时效
基于算法自动编译新闻,将部分劳动性的采编工作自动化,帮助媒体更快、更准、更智能地生产内容。例如,2014年3月,洛杉矶时报网站的机器人记者Ouakebot在洛杉矶地震发生后仅3分钟就撰写并发布了相关新闻。美联社使用的智能写作平台Wordsmith每秒可写2000篇报道;中国地震台网写作机器人九寨沟地震后7秒内完成相关新闻的采编;第一财经“DT稿王”一分钟可写出 1680 字。
3)实现智能视频剪辑,提升视频内容的价值
通过使用智能视频编辑工具,如视频字幕生成、视频集锦、视频拆条和视频超分等,可以有效地节省人力和时间成本,并最大限度地发挥版权内容的价值。2020年全国两会期间,人民日报利用“智能云剪辑师”快速生成视频,实现自动匹配字幕、人物实时跟踪、图像抖动修复、快速横屏转竖屏等技术操作,满足多平台分发需求。2022年冬奥会期间,央视视频利用AI智能内容制作编辑系统,高效制作发布冬奥会冰雪项目视频集锦,为体育媒体版权内容价值的深度开发创造了更多可能。
2、传播环节
AIGC的应用主要集中在以AI合成主播为核心的新闻播报等领域。AI合成主播开创了新闻领域实时语音和人物动画合成的先河。只需输入需要播报的文字内容,计算机就会生成相应的AI合成主播播报的新闻视频,并保证视频中人物的音频、表情、嘴唇动作自然一致,呈现出与真人主播一样的信息传递效果。纵观AI合成主播在媒体领域的应用,呈现三方面的特点。
1)应用范围不断拓展
目前,新华社、中央广播电视总台、人民日报等国家级媒体及湖南卫视等省市媒体,已经开始积极部署应用AI合成主播,陆续推出“新小微”、“小C”等虚拟新闻主播,推动其在新闻联播、记者报道、天气预报等更广泛的场景中应用,从而深度赋能全国人大、冬奥会、冬残奥会等重大活动传播。
2)应用场景不断升级
除了常规的新闻播报,AI合成主播开始陆续支持多语种播报和手语播报。2020年全国两会期间,多语种虚拟主播使用中、韩、日、英等多种语言报道新闻,实现一音多语播报,将中国新闻传递到世界,顺应了信息化时代信息共享的发展潮流。2022年冬奥会期间,百度、腾讯等企业推出手语播报数字人,为数百万听障用户提供手语解说,进一步推动了观赛无障碍进程。
3)应用形态日趋完善
在形象方面,从2D逐渐拓展到3D;在驱动范围上,开始从口型延伸到面部表情、肢体、手指、背景内容素材;在内容构建上,从支持SaaS平台工具建设到智能化生产进行探索。如腾讯3D手语数智人“聆语”,实现了唇动、面部表情、肢体动作、手指动作等内容的生成,并配备了可视化动作编辑平台,支持手语动作进行精修。
AIGC对传媒机构、传媒从业者和传媒受众都产生深刻影响。对传媒机构来说,AIGC通过参与新闻产品的生产过程,大大提高了生产效率,带来了全新的视觉和交互体验;丰富新闻报道形式,加快媒体数字化转型,推动传媒向智媒转变。对传媒从业者来说,AIGC可助力生产更具人文关怀、社会意义和经济价值的新闻作品:将部分劳动性的采编播工作自动化,使其更加专注于需要深度思考和创造力的工作内容,如新闻特写、深度报道和专题报道等,这些都是需要发挥人类在准确分析事物和妥善处理情感元素方面优势的细分领域。对传媒受众来说,AIGC的应用可以使其在更短的时间内以更丰富多样的形式获取新闻内容,提高其获取新闻信息的时效性和便捷性;降低传媒行业的技术门槛,促进媒体受众有更多参与内容生产的机会,大大增强他们的参与感。

二、AIGC+电商:推进虚实交融,营造沉浸体验
随着数字技术的发展和应用,消费的升级和加速,沉浸式购物体验成为电商领域的发展方向。AIGC正加速商品 3D 模型、虚拟主播乃至虚拟货场的构建。通过结合AR、VR等新技术,AIGC可以实现音频、视频等多感官交互的沉浸式购物体验。
1、生成商品 3D 模型用于商品展示和虚拟试用,提升线上购物体验
基于不同角度的商品图片,通过视觉生成算法自动生成商品的3D几何模型和纹理,辅以“看、试、穿、穿”的在线模拟,提供贴近实物的差异化网购体验,帮助高效提升用户转化。百度、华为等公司推出了商品自动化的3D建模服务,支持分钟级进行商品的3D拍摄和生成,精度可达毫米级。与传统的2D展示相比,3D模型可以720°展示商品主体的外观,可以大大减少用户选择和沟通的时间,提升用户体验,快速促进商品成交。
同时,生成的3D产品模型还可以用于线上试衣,高度还原了产品或服务的试衣体验,让消费者有更多机会接触到产品或服务的绝对价值。比如阿里在2021年4月推出天猫家装城3D版。通过为商家提供3D设计工具和产品3D模型AI生成服务,帮助商家快速搭建3D购物空间,支持消费者自助做家装,为消费者提供沉浸式的“云购物”体验。数据显示,3D购物平均转化率为70%,高于行业平均水平9倍。与去年同期相比,正常引导客户单价增长超过200%,商品退货率明显下降。
此外,不少品牌企业也开始在虚拟试衣方向进行探索和尝试,如优衣库虚拟试衣、阿迪达斯虚拟试衣鞋、周大福虚拟试衣珠宝、Gucci 虚拟试戴手表和眼、宜家虚拟家具搭配、保时捷虚拟试驾等虽然目前仍然采用传统的手工建模方式,但随着AIGC技术的不断进步,预计未来将会出现更多的消费工具,从而逐步降低3D建模的门槛和成本,帮助虚拟试穿应用大规模商业化。
2、打造虚拟主播,赋能直播带货
基于视觉、语音、文字生成技术,打造虚拟主播为观众提供24小时不间断的商品推荐和在线服务能力,降低了商家直播的门槛。与直播相比,虚拟主播有三大优势:
1)虚拟主播可以填补真人主播直播间隙,让直播间不断轮播,不仅为用户提供了更灵活的观看时间和更便捷的购物体验,也为合作商家创造了更大的商业增量。如欧莱雅、飞利浦、完美日记等品牌的虚拟主播一般会在凌晨0点上线,直播近9个小时与真人主播形成24小时无缝直播服务。
2)虚拟化的品牌主播更能加速店铺或品牌年轻化进程,拉近与新消费者的距离,塑造元宇宙时代的店铺形象,未来可以应用到元宇宙中更多的虚拟场景,实现多卷层传播。比如彩妆品牌“卡姿兰”推出自己的品牌虚拟形象,并作为其天猫旗舰店的日常虚拟主播导购引入直播间。同时,拥有虚拟品牌IP形象的传统企业,可直接利用现有形象快速转型为虚拟品牌主播。比如2020年5月海尔直播大促期间,知名的海尔兄弟虚拟IP来到直播间,与主持人和粉丝互动,播放量达到数千万。
3)虚拟主播人设更稳定可控。在头部主播有限并且可能“人设崩塌”的情况下,虚拟主播人设、言行等由品牌方掌握,比真人明星的可控性、安全性更强。品牌不必担心虚拟形象人设崩塌,为品牌带来负面新闻、差评及资金损失。
3、赋能线上商城和线下秀场加速演变,为消费者提供全新的购物场景
从2D影像重建场景的3D几何结构,实现虚拟货场的快速、低成本、规模化建设,将有效降低商家搭建3D购物空间的门槛和成本,为一些原本高度倚重线下门店的行业打开线上线下融合的想象空间,为消费者提供线上线下融合的全新消费体验。目前,一些品牌已经开始尝试建立虚拟空间。例如,奢侈品公司Gucci在百年品牌庆典中将线下的Gucci Garden Archetypes展览搬到了游戏Roblox上,并推出了为期两周的虚拟展览,5个主题展厅的内容与现实展览相互对应。2021年7月,阿里巴巴首次展示了其虚拟现实计划“Buy+”,并在购物现场提供360°虚拟开放购物体验。2021年11月,Nike 和Roblox 合作推出虚拟世界Nikeland,面向所有Roblox用户开放。随着基于图像的三维重建技术在Google Maps的沉浸式视图功能中的成功应用,虚拟货场的自动构建将在未来得到更好的应用和发展。

三、AIGC+影视:拓展创作空间,提升作品质量
随着影视行业的快速发展,从前期创作、中期拍摄到后期制作的流程问题也随之显露。有一些开发痛点,比如高质量剧本相对缺乏,制作成本高,部分作品质量有待提高,急需升级。AIGC技术的应用可以激发影视剧本创作的思路,拓展影视角色和场景创作的空间,大幅提升影视产品的后期制作质量,有助于影视作品文化价值和经济价值的最大化。
1、AIGC为剧本创作提供新思路
通过对海量剧本数据的分析总结,按照预设的风格快速制作剧本,创作者进行二次筛选加工,以此激发创作者灵感,拓宽创作思路,缩短创作周期。早在2016年6月,由纽约大学利用人工智能编写的电影剧本《Sunspring》拍摄制作入围48小时(Sci-FiLondon)48小时挑战赛前十名。2020年,美国查普曼大学的学生使用OpenAl的大模型GPT-3创作了一个剧本并制作短片《律师》。国内部分垂直科技公司开始提供智能剧本制作相关服务,如海马轻帆推出的“小说转剧本”智能写作功能,服务了包括《你好,李焕英》《流浪地球》等爆款作品在内的3万多集戏剧剧本,8000多部电影/网络电影剧本,500多万部网络小说。
2、AIGC 扩展角色和场景创作空间
1)通过人脸、语音等相关内容的人工智能合成,实现“数字复活”已故演员、替换“劣迹艺人”、多语言译制片音画同步、演员角色年龄的跨越、高难度动作合成等,减少由于演员自身局限对影视作品的影响。比如在央视纪录片《创新中国》中,央视和科大讯飞利用人工智能算法,学习已故配音演员李易过往纪录片的声音数据,根据纪录片手稿合成配音,最后通过后期剪辑优化,让李易的声音重现。2020年播出的《了不起的儿科医生》中,主要人物的教育事件影响了影视作品的宣传和发行。作品采用智能影视变脸技术替换主要角色,减少影视作品创作过程中的损失。2021年,英国公司Flawless推出可视化工具TrueSync,解决多语言翻译影片中人物唇型不同步的问题。它可以通过AI深度视频合成技术精准调整演员的五官,让演员的口型与不同语言的配音或字幕相匹配。
2)通过人工智能合成虚拟物理场景,可以生成实际拍摄不到或成本过高的场景,大大拓宽了影视作品的想象边界,给观众带来更好的视觉效果和听觉体验。比如2017年的《热血长安》,剧中大量场景都是人工智能技术虚拟生成的。前期工作人员收集了大量的场景数据,通过特效人员的数字建模,制作出模拟的拍摄场景,演员在绿屏工作室进行表演。结合实时抠像技术,将演员的动作与虚拟场景融合,最终生成视频。
3、AIGC 赋能影视剪辑,升级后期制作
1)实现影视图像的修复和还原,提高图像数据的清晰度,保证影视作品的画质。如中影数字制作基地和中国科技技术大学联合开发的基于AI的图像处理系统“中影·神思”,成功修原《厉害了,我的国》《马路天使》等多部电视剧。使用AI神思系统,修复一部电影的时间可以缩短四分之三,成本可以降低一半。同时,爱奇艺、优酷、西瓜视频等流媒体平台已经开始探索AI修复经典影视作品作为新的增长领域。
2)实现电影预告片的生成。IBM旗下的人工智能系统 Watson 在学习了数百部惊悚片预告片的视听技术后,从90分钟的《Morgan》电影中挑选出符合惊悚预告片特点的电影镜头,并制作出一段6分钟的预告片。虽然这部预告片还需要制作方修改才能最终完成,但却将预告片的制作周期从一个月左右缩短到了24小时。
3)实现视频内容从2D到3D的自动转换。聚力推出的人工智能3D内容自动制作平台“郑融”支持影视作品的维度转换,将影院级3D转换效率1000倍以上。

四、AIGC+娱乐:扩展辐射边界,获得发展动能
在数字经济时代,娱乐不仅拉近了产品服务与消费者之间的距离,也间接满足了现代人对归属感的渴望,其重要性与日俱增。借助AIGC技术,娱乐产业可以通过创造有趣的图像或音视频、打造虚拟偶像、开发C端用户的数字头像等方式,迅速扩大辐射边界,以更容易被消费者接受的方式获得新的发展动力。
1、实现有趣的冬季图像或音视频的生成,激发用户参与热情
在图像和视频生成方面,以AI换脸为代表的AIGC应用极大地满足了用户猎奇的需求,成为打破圈子的利器。比如FaceAPp、ZAO、Avatarifv等图片视频合成应用一经推出,立刻在网上引发热潮,登上了App Store免费下载榜的榜首;国庆70周年,人民日报新媒体中心推出互动生成56张国家照片和人像的应用屏幕朋友圈,合成照片总数超过7.38亿张;2020年3 月,腾讯推出化身游戏中的“和平精英”与火箭少女 101 同框合影的活动,这些互动的内容极大地激发出了用户的情感,带来了社交传播的迅速破圈。在语音合成方面,变声增加互动娱乐性。比如QQ等社交软件,和平精英等游戏都集成了变声功能,支持用户体验大叔、萝莉等不同声音,让交流成为一种好玩的游戏。
2、打造虚拟偶像,释放IP价值
1)实现与用户共创合成歌曲,不断加深粉丝黏性。以初音未来和洛天依为代表的“虚拟歌姬”,都是基于 VOCALOID 语音合成引擎软件为基础创造出来的虚拟人物,由真人提供声源,再由软件合成人声,都是能够让粉丝深度参与共创的虚拟歌手。以洛天依为例,任何人通过声库创作词曲,都能达到“洛天依演唱一首歌”的效果。从 2012年 7月 12 日洛天依出道至今十年的时间内,音乐人以及粉丝已为洛天依创作了超过一万首作品,通过为用户提供更多想象和创作空间的同时,与粉丝建立了更深刻联系。
2)通过AI合成音视频动画,支持虚拟偶像在更多样化的场景中实现内容。随着音视频合成、全息投影、AR、VR等技术的成熟,虚拟偶像实现场景逐渐多元化。目前可以通过演唱会、音乐专辑、广告代言、直播、周边衍生产品来实现。同时随着虚拟偶像的商业价值被不断发掘,品牌与虚拟 IP 的联动意愿也会增加。如由魔珐科技与次世文化共同打造的网红翎 Ling于2020年5月出道至现在已先后与VOGUE、特斯拉、GUCCI等品牌展开合作。
3、开发 C端用户数字化身,布局消费元宇宙
自2017年苹果手机发布Animoii以来,“数字化身”技术的迭代经历了从单一的卡通动物头像到AI的发展,用户拥有了更多的创作自主权和更生动的图像库。各大科技巨头都在积极探索“数字化身”的相关应用,加速布局“虚拟数字世界”与现实世界大融合的“未来”。例如,百度在2020年世界互联网大会上展示了基于3D虚拟图像生成和虚拟图像驱动等AI技术设计动态虚拟角色的能力。只要在现场拍一张照片,就能在几秒钟内迅速生成一个能模仿“我”的表情和动作的虚拟形象。2021年云起大会开发者展区,阿里云展示了最新技术——卡通智能绘画项目,吸引了近2000名体验者,成为大会爆款。阿里云智能绘画采用隐变量映射的技术方案,通过探索输入人脸图片的显著特征,如眼睛大小、鼻型等,自动生成具有个人特征的虚拟图像。同时,还可以跟踪用户的面部表情,生成实时动画,让普通人也能有机会创造自己的卡通形象。在可预见的未来,“数字虚拟人”作为虚拟世界中用户个人身份和互动的载体,将进一步与人们的生产生活相结合,并将带动虚拟商品经济的发展。

五、AIGC+其他:推进数实融合,加快产业升级
除以上行业之外,教育、金融、医疗、工业等各行各业的 AIGC 应用也都在快速发展。
1、教育领域,AIGC 赋予教育材料新活力
相比阅读和讲座等传统方式,AIGC为教育工作者提供了新的工具,让原本抽象、扁平的教科书具体化、立体化,以更生动、更有说服力的方式向学生传递知识。例如,制作历史人物直接与学生对话的视频,可以为一个没有吸引力的演讲注入新的活力:合成逼真的虚拟教师,使数字化教学更具互动性和趣味性等。
2、金融领域,AIGC 助力实现降本增效
一方面AIGC可以实现金融资讯和产品介绍视频内容的自动化制作,提高金融机构的内容运营效率;另一方面,AIGC可以用来创建一个具有音频和视频两个通道的虚拟数字客户服务,这可以使金融服务更加有温度。医疗领域,AIGC赋能诊疗全流程。在辅助诊断方面,AIGC可用于提高医学影像质量,录入电子病历等,解放医生的智力和精力,让医生的资源集中在核心业务上,从而提高医生的专业能力。在康复方面,AIGC可以为失声者合成语音音频,为残疾人提供肢体投影,为精神病患者提供医疗陪伴等,通过人性化的方式安抚患者,可以缓解其情绪,加快其康复。
3、工业领域,AIGC提升产业效率和价值
一是融入到CAD(计算机辅助设计)中,大大缩短了工程设计周期。AIGC可以通过自动化工程设计中重复、耗时和低级的任务自动化,将过去需要数千小时的工程设计缩短到几分钟。同时支持衍生设计的生成,为工程师或设计师提供灵感。此外,它还支持在设计中引入变化,以实现动态模拟。例如,宝马通过AIGC在其BMW VISION NEXT 100概念车中开发了动态功能性外观和内饰。二是加快数字孪生系统建设。通过将基于物理环境形成的数字几何图形快速转换成实时参数化的3D建模数据,可以高效地创建现实世界中的工厂、工业设备和生产线的数字孪生系统。总的来说,AIGC正在向与其他产业的深度融合发展,其相关应用正在加速渗透到经济社会的方方面面。
AIGC发展展望
一、核心技术持续演进
1、从真实可控向多样组合发展
从技术上看,目前AIGC的相关算法已经具备了真实再现和创作某一类给定内容的能力,相关模型在简单场景的内容生成上也取得了不错的成绩。然而,面对多样性变化和复杂场景内容生成的挑战,现有的AIGC算法仍需进一步改进。例如,目前AIGC在图像生成和编辑方面取得了惊人的成就,如生成高清人脸图像或数字人头像,相关算法已经能够以假乱真。相比较而言,动画视频的动态复杂性和可能复杂程度以几何倍数增长,高质量的视频创作还有巨大的提升空间。同时,仅仅依靠单个生成器的内容生成,是远远不足以构建一个理想的数字世界甚至元宇宙的。AIGC科技的下一个发展方向将是通过不同制作者之间的互动进行内容创作。通过整体的、多模态的复杂场景创作,AIGC将有望实现更多的知性内容,进而反哺核心及相关领域,促进共同发展。
2、从本地化集中式向大规模分布式发展
1)AIGC离不开大规模分布式深度学习技术和多智能体强化学习技术
大规模分布式AIGC的开发将有助于高效利用GPU算力,将计算流程拆解到一系列计算平台和边缘计算设备上,通过多设备分布式计算加快内容生产进程,提高生成效率和质量。目前,以Google、微软为代表的人工智能公司已经开始布局下一代超大规模人工智能模型的分布式计算平台,如Pathways、DeepSpeed等。,以解决大规模模型训练中计算能力不足、资源利用率低、无法高效制作模型等问题。
2)在分布式计算的框架下,大规模的多智能体网络可以通过合作和竞争来完成个体无法完成的任务
AIGC作为构建数字世界乃至元宇宙的重要生产工具,需要模拟现实世界中复杂的大规模多智能体网络系统,如动物群体、社会网络、城市综合体等。通过对大规模分布式多智能体算法的研究,探索多智能体的扩展性、安全性、稳定性和迁移性将是未来的重点方向之一。
二、关键能力显著增强
随着AIGC核心技术的不断发展,其内容孪生、内容编辑和内容创作三大基础能力将显著增强。
1、随着渲染技术、仿真加速、XR suite和开发组件等技术的提升,基于内容孪生的数字孪生能力可以更真实地将现实世界复制到虚拟世界,再现人物更丰满、物体更逼真、细节更丰富的虚拟图像,并依托新一代传感器和云边缘进行协作进行实时动态更新。
2、依托内容编辑的数字陪伴能力,将进一步打通现实世界与虚拟世界的双向通道。通过现实世界和虚拟世界的双向交流,将现实世界中的物理问题进行抽象和数字化,然后转化为虚拟世界中的计算问题,将计算的最优解以物理形式输出到现实世界。未来,依托虚拟优化、智能控制、可信认证等关键技术的提升,数字伴侣将进一步拓展在现实世界中发现和解决问题的能力,同时降低成本,提高产量。
3、基于内容创作的数字原生能力潜力将得到真正释放。随着未来AIGC数字原生能力的大幅提升,基于更先进算法的人工智能技术将使AIGC摆脱对专业生成内容(PGC)和用户生成内容(UGC)的依赖,完全自主创作内容,充分释放其创作潜力。内容将以高质量、多样性、高自由度持续输出,填补目前专业生成内容(PGC)和用户生成内容(UGC)的容量和监管空白。尤其是随着人工智能技术的不断发展和代选,AIGC将实现从辅助内容生成到独立内容生成的跨越,这将极大满足未来消费者对内容数量和质量的双重刚性需求。
三、产品类型逐渐丰富
近年来,随着元宇宙概念的兴起和科学技术的快速发展,数字人是未来AIGC应用的一个重要细分领域。数字人作为现实与虚拟世界的交互媒介,可以通过其独特的人格、性格、思维、职业等辅以专属的创意内容,打破传统的物理和时空界限,通过VR、AR等技术和新一代智能终端设备,为用户带来丰富的沉浸式体验。能够自主生成内容的数字人将是构建人机融合、数实融合的未来世界的最佳载体,也将是未来人类构建“自生成、自更新”的新元宇宙世界的必由之路。
随着AI相关技术的不断发展,数字人发展的自由度将大大提高,不同个人和企业的数字人将更具可识别性和独立性,开发成本将大大降低以促进数字人的普遍发展。同时,具有独立内容生成能力的“智能化”乃至“智慧化”的数字人,意味着无限的内容创作。元宇宙将为人类提供一个自由探索的广阔空间,人类将不再受真实时空的束缚。基于AIGC的超宇宙将不再依赖于现实世界的投射和剪辑,而是脱离现实世界进行自我生成、自我发展和自我更新。
随着人工智能的不断发展和进步,AIGC模式将不再局限于文本、音频和视觉。多重信息感知和认知能力,如嗅觉、触觉、味觉、感觉咸味等将以数字形式传输,并将指导人工智能进行内容创作。在未来的某一天,人工智能能否创造出除了苦乐参半之外的另一种味道,还是个未知数。
四、场景应用趋于多元
目前,AIGC已经广泛应用于金融、媒体、娱乐、电子商务等多个领域,未来其应用场景将进一步多样化。比如在“AIGC+数据科学”领域,可以自动生成具有安全性、标签化、预处理的标准数据以满足日益饥渴的人工智能模型。
目前人工智能产生的数据在所有数据中占比不到1%。根据Gartner的预测,到2025年,人工智能产生的数据将占10%;在“AIGC+游戏”领域,通过训练,AI可以生成针对不同玩家阶层的游戏指南和教学手册,并且无重复自动打造不同难度、高互动性、高可玩性的剧情和关卡,无需重复;在“AIGC+医学”领域,相关模型可以克服医学数据的稀缺性,自动搜索具有特定性质的分子结构,从而大大降低新药研发和临床试验的研究成本。
根据Gartner的预测,到2025年,超过30%的药物和材料将通过生成式人工智能(AIGC的工具之一)被发现;在“AIGC+安防”领域,在公共场所或活动中,人工智能会自动生成用户头像,保护用户的数据安全和个人隐私;在“AIGC+艺术”领域,除目前流行的NFT(非同质化代币),AIGC还可以涉及绘画、作曲、演唱、编剧、设计等,不同于这些子领域辅助内容生成的现状。未来,这些领域的自生成内容经过人工智能创作后将达到人类水平,无需人工优化即可投放市场。
除了应用场景的横向扩展,场景之间的融合和交互也是未来的发展趋势之一。比如,通过“文旅+游戏”,以高度沉浸式的体验深度挖掘传统文化旅游产业的新特征,用新颖、不重复、极具吸引力的互动游戏吸引年轻消费者深度挖掘传统文化旅游的深刻内涵,激发传统文化旅游产业的新活力;通过“教育+政务”,AIGC可以根据政策导向,为不同年龄、不同学历、不同职业、不同地域的人群生成不同类型的教育和科普内容,极大地均衡教育资源,更好地普及全民教育,营造全民科学氛围,提高全民科学素养;通过“商业+艺术”,AIGC可以创造更具人文关怀和当代意义的数字馆藏。数字收藏将从缺乏实质性内涵的虚拟物品转化为具有特定纪念意义的虚拟化身,从而深度挖掘艺术的商业潜力,进而反哺和推动未来艺术的高质量发展。
五、生态建设日益完善
随着 AIGC 的不断成熟,以标准规范、技术研发、内容创作、行业应用、资产服务为核心的生态体系架构将日趋完善,无论是以 AIGC 赋能产业升级还是以 AIGC 自主释放价值都将在此框架下健康有序发展。标准规范为 AIGC 生态构建了从技术、内容、应用、服务、监管的全过程一体化标准体系,促进 AIGC 在合理合规合法的框架下良
性发展。
同时,在核心技术持续演进和关键能力显著增强的背景下,性能更强大、逻辑更智能的人工智能算法将被应用于 AIGC,技术研发的不断创新将强有力地推动内容创作,提高生成内容质量,使内容更接近人类智力水平和宙美标准,同时应用于各类行业各种场景。AIGC 的繁荣发展将促进资产服务快速跟进,通过对生成内容的合规评估、资产管理、产权保护、交易服务等构成 AIGC 的完整生态链,并进行价值重塑,充分释放其商业潜力。随着 5G、云计算、VR、AR 等前沿技术的快速发展和新一代智能终端设备的研发创新,完整的 AIGC生态链是未来释放数据要素红利、推动传统产业升级、促进数字经济发展、构建数实融合一体、创造元宇宙世界最重要的推动力之一。
蓝海大脑AIGC高性能计算一体机采用 Intel 、AMD处理器,突破传统风冷散热模式,采用风冷和液冷混合散热模式——服务器内主要热源 CPU 利用液冷冷板进行冷却,其余热源仍采用风冷方式进行冷却。通过这种混合制冷方式,可大幅提升服务器散热效率,同时,降低主要热源 CPU 散热所耗电能,并增强服务器可靠性;支持VR、AI加速计算;深受广大深度学习AICG领域工作者的喜爱。









![[附源码]Python计算机毕业设计Django动漫电影网站](https://img-blog.csdnimg.cn/eb33e9e83f9649808902d1da61073d9a.png)


![[附源码]Python计算机毕业设计Django高校实验室仪器设备管理系统](https://img-blog.csdnimg.cn/b2959c7668b0432c83171fcc1fa8fd1e.png)