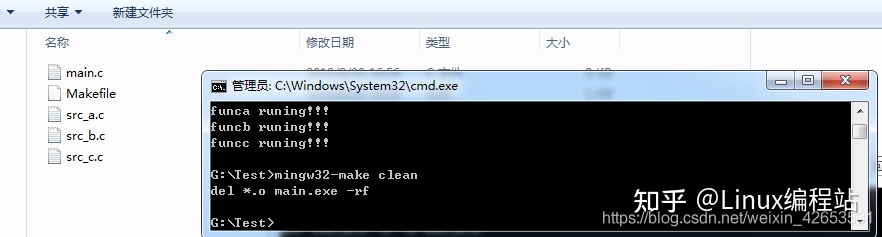
ML课刚学,发现更多是对线性代数的回顾。更进一步说,统计机器学习方法就是以高数、线代和概率论为基石构筑的“一栋大厦”。下面主要沿着老师ppt的思路讲讲对PCA方法的个人理解。

这里
u
1
T
x
(
i
)
u_1^Tx^{(i)}
u1Tx(i)是
x
(
i
)
x^{(i)}
x(i)在单位方向向量
u
1
u_1
u1上的投影长度,实际上
u
1
⋅
x
(
i
)
∣
u
1
∣
=
u
1
⋅
x
(
i
)
=
u
1
T
x
(
i
)
\frac{u_1\cdot x^{(i)}}{|u_1|}=u_1\cdot x^{(i)}=u_1^Tx^{(i)}
∣u1∣u1⋅x(i)=u1⋅x(i)=u1Tx(i).

求取投影后数据的方差,并通过协方差矩阵的形式表达:
1
N
∑
i
=
1
N
(
u
1
T
x
(
i
)
−
u
1
T
μ
)
2
=
1
N
∑
i
=
1
N
(
(
x
(
i
)
)
T
u
1
−
μ
T
u
1
)
2
=
1
N
∑
i
=
1
N
(
(
x
(
i
)
)
T
u
1
−
μ
T
u
1
)
T
(
(
x
(
i
)
)
T
u
1
−
μ
T
u
1
)
=
1
N
∑
i
=
1
N
u
1
T
(
(
x
(
i
)
)
T
−
μ
T
)
T
(
(
x
(
i
)
)
T
−
μ
T
)
u
1
=
1
N
∑
i
=
1
N
u
1
T
(
(
x
(
i
)
)
−
μ
)
(
(
x
(
i
)
)
−
μ
)
T
u
1
=
u
1
T
[
1
N
∑
i
=
1
N
(
(
x
(
i
)
)
−
μ
)
(
(
x
(
i
)
)
−
μ
)
T
]
u
1
=
u
1
T
S
u
1
\frac{1}{N}\sum_{i=1}^{N}(u_1^Tx^{(i)}-u_1^T\mu)^2\\ =\frac{1}{N}\sum_{i=1}^{N}((x^{(i)})^Tu_1-\mu^Tu_1)^2\\ =\frac{1}{N}\sum_{i=1}^{N}((x^{(i)})^Tu_1-\mu^Tu_1)^T((x^{(i)})^Tu_1-\mu^Tu_1)\\ =\frac{1}{N}\sum_{i=1}^{N}u_1^T((x^{(i)})^T-\mu^T)^T((x^{(i)})^T-\mu^T)u_1\\ =\frac{1}{N}\sum_{i=1}^{N}u_1^T((x^{(i)})-\mu)((x^{(i)})-\mu)^Tu_1\\ =u_1^T[\frac{1}{N}\sum_{i=1}^{N}((x^{(i)})-\mu)((x^{(i)})-\mu)^T]u_1\\ =u_1^TSu_1
N1∑i=1N(u1Tx(i)−u1Tμ)2=N1∑i=1N((x(i))Tu1−μTu1)2=N1∑i=1N((x(i))Tu1−μTu1)T((x(i))Tu1−μTu1)=N1∑i=1Nu1T((x(i))T−μT)T((x(i))T−μT)u1=N1∑i=1Nu1T((x(i))−μ)((x(i))−μ)Tu1=u1T[N1∑i=1N((x(i))−μ)((x(i))−μ)T]u1=u1TSu1
第一步变换,将点积表达为
u
1
T
x
(
i
)
u_1^Tx^{(i)}
u1Tx(i)和
(
x
(
i
)
)
T
u
1
(x^{(i)})^Tu_1
(x(i))Tu1是等价的。

优化目标为使投影数据的方差最大,根据最大方差理论:方差越大,信息量越大。以此为目标使投影保留的数据信息量最大,损失最小。使用拉格朗日乘子法求解:
这里要用到矩阵求导公式:
∇
X
X
T
A
X
=
(
A
+
A
T
)
X
\nabla_{X} X^TAX=(A+A^T)X
∇XXTAX=(A+AT)X.

求导后我们发现极值处,
λ
1
\lambda_1
λ1不就是协方差矩阵
S
S
S的特征值,
u
1
u_1
u1不就是对应的特征向量!左右同时乘上
u
1
T
u_1^T
u1T,得到
u
1
T
S
u
1
=
λ
1
u_1^TSu_1=\lambda_1
u1TSu1=λ1,等式左侧正是我们的优化目标,特征值
λ
1
\lambda_1
λ1就是数据投影至向量
u
1
u_1
u1上的方差。
因此,在算法步骤中,对
S
S
S进行特征值分解,将特征值从大到小排序
λ
1
,
λ
2
,
.
.
.
λ
n
\lambda_1,\lambda_2,...\lambda_n
λ1,λ2,...λn,对应的特征向量为
u
1
,
u
2
,
.
.
.
u
n
u_1,u_2,...u_n
u1,u2,...un,取前
K
K
K个作投影,将数据降至
K
K
K维。
PCA算法步骤:


前面提到损失最小,如何量化说明这点?通过降维后的数据重构原数据
x
~
(
i
)
\widetilde{x}^{(i)}
x
(i),看损失了多少,是不是最小。

∣
∣
x
(
i
)
−
u
u
T
x
(
i
)
∣
∣
2
=
(
x
(
i
)
−
u
u
T
x
(
i
)
)
T
(
x
(
i
)
−
u
u
T
x
(
i
)
)
=
(
(
x
(
i
)
)
T
−
(
x
(
i
)
)
T
u
u
T
)
(
x
(
i
)
−
u
u
T
x
(
i
)
)
=
(
x
(
i
)
)
T
x
(
i
)
−
2
(
x
(
i
)
)
T
u
u
T
x
(
i
)
+
(
x
(
i
)
)
T
u
u
T
u
u
T
x
(
i
)
=
(
x
(
i
)
)
T
x
(
i
)
−
2
(
x
(
i
)
)
T
u
u
T
x
(
i
)
+
(
x
(
i
)
)
T
u
u
T
x
(
i
)
=
(
x
(
i
)
)
T
x
(
i
)
−
(
x
(
i
)
)
T
u
u
T
x
(
i
)
||x^{(i)}-uu^Tx^{(i)}||^2\\ =(x^{(i)}-uu^Tx^{(i)})^T(x^{(i)}-uu^Tx^{(i)})\\ =((x^{(i)})^T-(x^{(i)})^Tuu^T)(x^{(i)}-uu^Tx^{(i)})\\ =(x^{(i)})^Tx^{(i)}-2(x^{(i)})^Tuu^Tx^{(i)}+(x^{(i)})^Tuu^Tuu^Tx^{(i)}\\ =(x^{(i)})^Tx^{(i)}-2(x^{(i)})^Tuu^Tx^{(i)}+(x^{(i)})^Tuu^Tx^{(i)}\\ =(x^{(i)})^Tx^{(i)}-(x^{(i)})^Tuu^Tx^{(i)}
∣∣x(i)−uuTx(i)∣∣2=(x(i)−uuTx(i))T(x(i)−uuTx(i))=((x(i))T−(x(i))TuuT)(x(i)−uuTx(i))=(x(i))Tx(i)−2(x(i))TuuTx(i)+(x(i))TuuTuuTx(i)=(x(i))Tx(i)−2(x(i))TuuTx(i)+(x(i))TuuTx(i)=(x(i))Tx(i)−(x(i))TuuTx(i)
而
m
i
n
∑
(
(
x
(
i
)
)
T
x
(
i
)
−
(
x
(
i
)
)
T
u
u
T
x
(
i
)
)
⟺
m
a
x
∑
(
(
x
(
i
)
)
T
u
u
T
x
(
i
)
)
min\sum((x^{(i)})^Tx^{(i)}-(x^{(i)})^Tuu^Tx^{(i)})\\ \iff max\sum((x^{(i)})^Tuu^Tx^{(i)})
min∑((x(i))Tx(i)−(x(i))TuuTx(i))⟺max∑((x(i))TuuTx(i))
进一步变换,利用
u
T
x
(
i
)
=
(
x
(
i
)
)
T
u
u^Tx^{(i)}=(x^{(i)})^Tu
uTx(i)=(x(i))Tu,
⟺
m
a
x
∑
(
(
(
x
(
i
)
)
T
u
)
(
u
T
x
(
i
)
)
)
⟺
m
a
x
∑
(
(
u
T
x
(
i
)
)
(
(
x
(
i
)
)
T
u
)
)
⟺
m
a
x
∑
(
u
T
x
(
i
)
(
x
(
i
)
)
T
u
)
⟺
m
a
x
u
T
∑
(
x
(
i
)
(
x
(
i
)
)
T
)
u
\iff max\sum(((x^{(i)})^Tu)(u^Tx^{(i)}))\\ \iff max\sum((u^Tx^{(i)})((x^{(i)})^Tu))\\ \iff max\sum(u^Tx^{(i)}(x^{(i)})^Tu)\\ \iff max\ u^T\sum(x^{(i)}(x^{(i)})^T)u
⟺max∑(((x(i))Tu)(uTx(i)))⟺max∑((uTx(i))((x(i))Tu))⟺max∑(uTx(i)(x(i))Tu)⟺max uT∑(x(i)(x(i))T)u
最后发现这和前面方差最大的优化目标时相等价,印证了最大方差理论。
![[附源码]Python计算机毕业设计Django高校实验室仪器设备管理系统](https://img-blog.csdnimg.cn/b2959c7668b0432c83171fcc1fa8fd1e.png)

![[附源码]计算机毕业设计springboot青栞系统](https://img-blog.csdnimg.cn/24cd620699b34fde958ed69f48a0fa9b.png)
![[附源码]JAVA毕业设计工程车辆动力电池管理系统(系统+LW)](https://img-blog.csdnimg.cn/223111ab239c4149aa7e6a35f7e035f9.png)