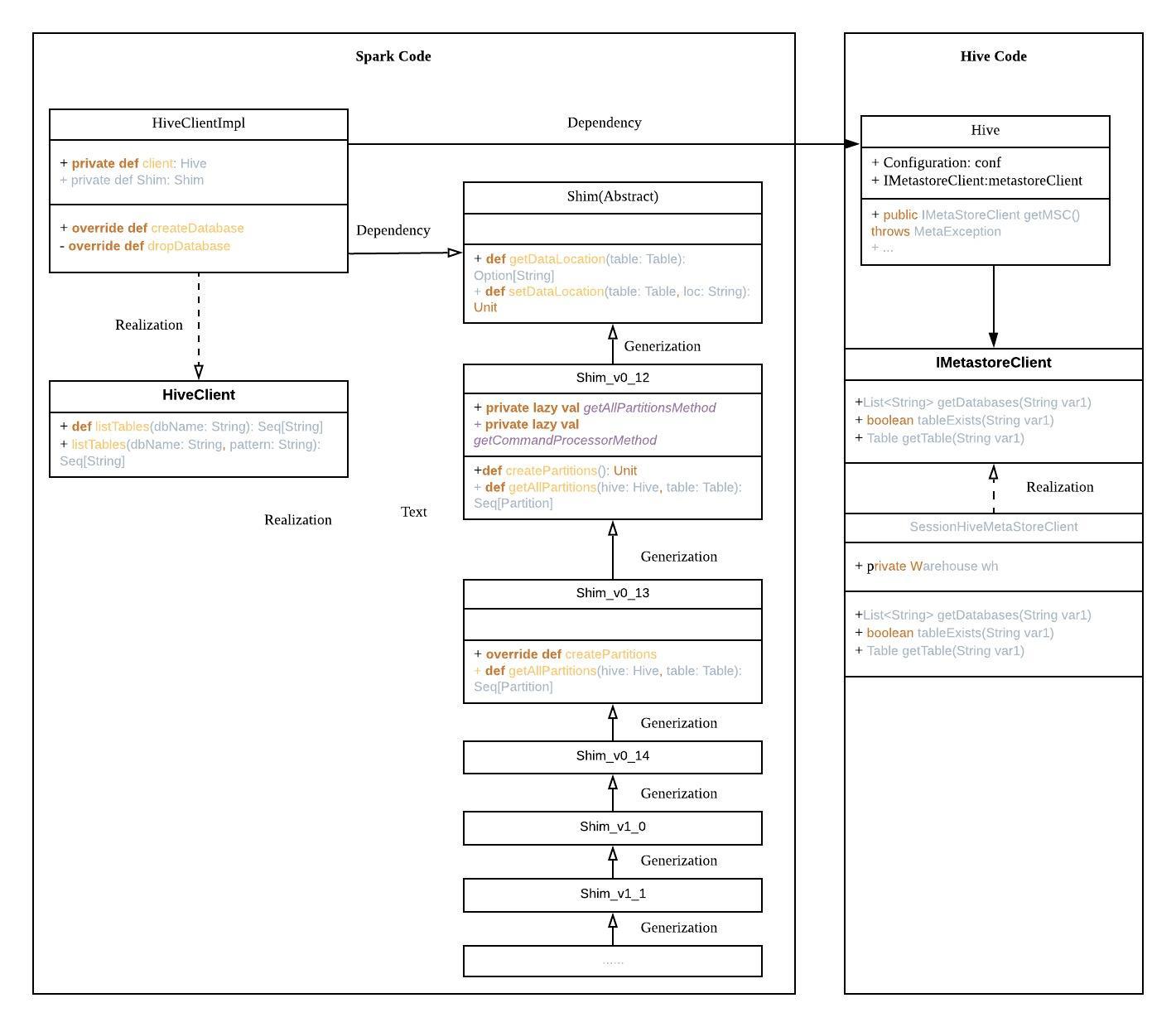
一、走进聊天机器人
目标
- 知道常见的bot的分类
- 知道企业中常见的流程和方法
1.1 目前企业中的常见的聊天机器人
- QA BOT (问答机器人) : 回答问题
1.代表:智能名服
2.比如: 提问和回答 - TASK BOT(任务机器人): 助人们做事情
1.代表: siri
2.比如:设五明天早上9点的闹钟 - CHAT BOT(聊天机器人): 通用、开放聊天
1.代表:微软小冰
1.2 常见的聊天机器人怎么实现的
1.2.1 问答机器人的常见实现手段
- 信息检素、搜素(简单,效果一般,对数据问答对的要求高)关键词: tfidf、SVM、朴素贝叶斯、RNN、CNN
- 知识图谱(相对复杂,效果好,很多论文)在图形数据库中存储知识和知识间的关系、把问答转化为查询语句、能够实现推理
1.2.2 任务机器人的常见实现思路
- 语音转文字
- 意图识别、领域识别、文本分类
- 槽位填充:比如买机票的机器人 使用命令体识形填充 从{位置}到{位置}的票2个位置的
- 回话管理、回话策略
- 自然语言生成
- 文本转语音
1.2.3 闲聊机器人的常见实现思路
- 信息检素《简单、能够回答的话术有限)
- seq2seg 和变种(答案覆盖率高,但是不能保证答案的通顺等)
1.3 企业中的聊天机器人是如何实现的
1.3.1 阿里小蜜-电商智能助理是如何实现的
参考地址: https://juejin.im/entry/59e96f946fb9a04510499c7f
1.3.1.1 主要交互过程
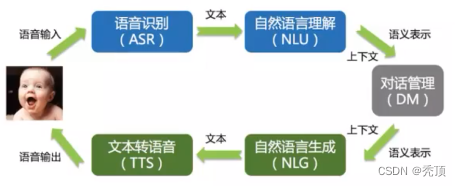
从图可以看出:
- 输入:语音转化为文本,进行理解之后根据上下文得到语义的表示
- 输出:根据语义的表是和生成方法得到文本,再把文本转化为语音输出
1.3.1.2 技术架构
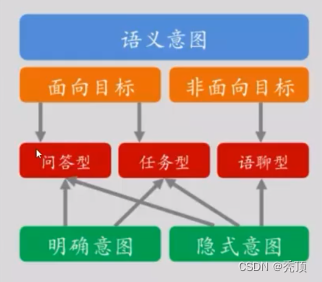
可以看出其流程为:
- 判断用户意图
- 如果意图为面向目标:可能是问答型或者是任务型
- 如果非面向目标:可能是语聊型
1.3.1.3 检索模型流程(小蜜还用了其他的模型,这里以此为例)
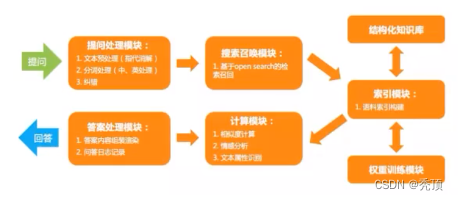
通过上图可知,小童的检索式回答的流程大致为:
- 对问题进行处理
- 根据问题进行召回,使用了提前准备的结构化的语料和训练的模型
- 对召回的结果进行组长和日志记录
- 对召回的结果进行相似度计算,情感分析和属性识别
- 返回组装的结果
1.3.2 58同城智能客服帮帮如何实现的
参考地址:http://www.6aiq.com/article/1536149308075?p=1&m=0
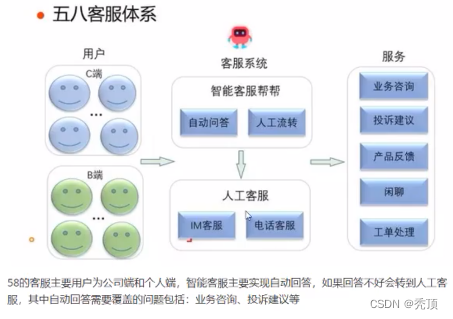
1.3.2.1 客服体系
1.3.2.2 智能客服整体架构
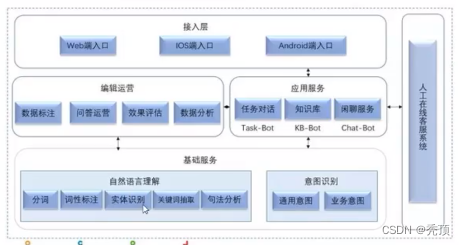
整体来看,58的客服架构分为三个部分
- 基础服务,实现基础的NLP的功能和意图识别
- 应用对话部分实现不同意图的模型,同时包括编相运营等内容
- 提供对外的接口
1.3.2.3 业务咨询服务流程
大数据流程
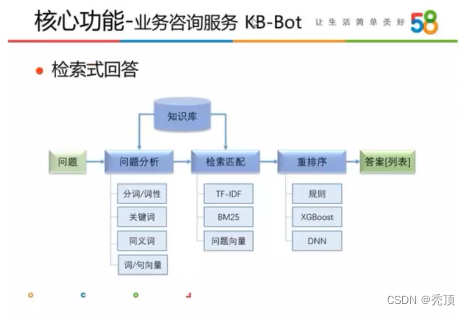
KB-bot的流程大致为:
- 对问题进行基础处理
- 对答案通过tfidf等方法进行召回
- 对答案通过规则深度神经网络等方法进行重排序
- 返回答案排序列表
使用融合的模型
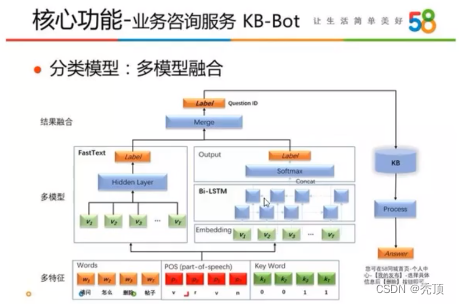
在问答模型的深度网络模型中使用了多套模型进行融合来获取结果 - 在模型层应用了 FastText、TextCNN 和 Bi-LSTM 等模型
- 在特征层尝试使用了单字、词、词性、词语属性等多种特征
通过以上两个模型来组合获取相似的问题,返回相似问题ID对应的答案
1.3.2.4 58的闲聊机器人
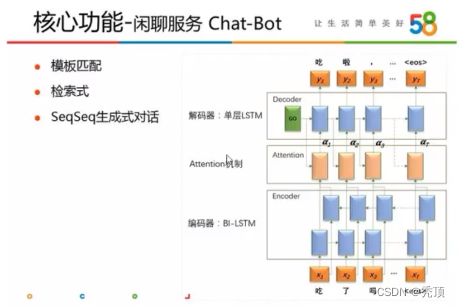
58同城的闲聊机器人使用三种方法包括
- 基于模板匹配的方法
- 基于搜索的方式获(上上图)
- 使用seq2seq的神经网络来实现
1.3.2.5 解决不了转人工服务
二、需求分析和流程介绍
目标
- 能够说出实现聊天机器人的需求
- 能够说出实现聊天机器人的流程
2.1需求分析
在黑马头条的小智同学板块实现聊天机器人,能够起到智能客服的效果,能够为使用app的用户解决基础的问题,而不用额外的人力。
但是由于语料的限制,所以这里使用了编程相关的问题,能够回答类似: python是什么,python有什么优势等问题
2.2 效果演示

2.3 实现流程
2.3.1 整体架构
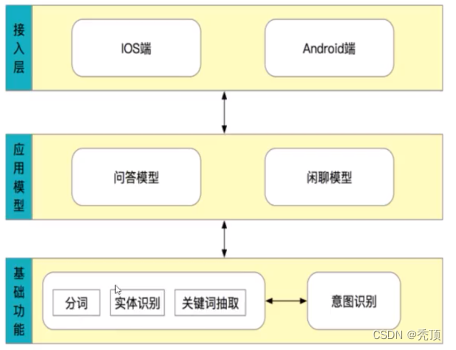
整个流程的描述如下
- 接受用户的问题之后,对问题进行基础的处理
- 对处理后的问题进行分类,判断其意图
- 如果用户希望闲聊,那么调用闲聊模型返回结果
- 如果用户希望咨询问题,那么调用问答模型返回结果
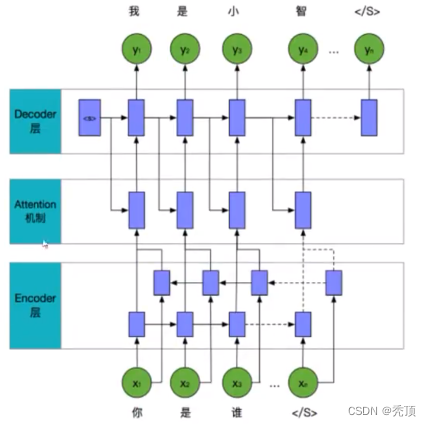
2.3.2 闲聊模型
闲聊模型使用了seq2seq模型实现
包含:
- 对数据的embedding
- 码层
- attention机制的处理
- 解码层
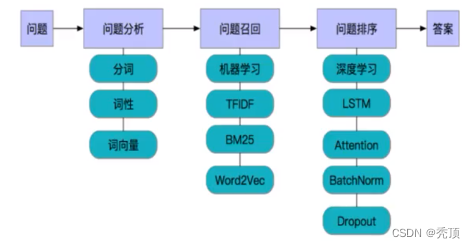
2.3.3 问答模型
问答模型使用了召回和排序的机制来实现,保证获取的速度的同时保证了准确率
- 问题分析:对问题进行基础的处理,包括分词,词性的获取,词向量的获取
- 问题的召回:通过机器学习的方法进行海选,海选出大致满足要求的相似问题的前K个
- 问题的排序: 通过深度学习的模型对问题计算准确率,进行排序
- 设置阈值,返回结果
三、环境准备
目标
- 能够使用anaconda创建虚拟环境
- 能够安装fasttext
- 能够安装pysparnn
3.1 Anaconda环境准备
- 下载地址: https://mirror.tuna.tsinghua.edu.cn/hep/anaconda/
- 下对应电脑版本软件,安装
1.windows: 双击exe文件
2.unix:给sh文件添加可执行权限,执行sh文件 - 添加到环境变量
1.windows安装过程中勾选
2.unix: export PATH=“/root/miniconda3/bin: $SPATH” - 创建虚拟环境
1.conda create -n 名字 python=3.6(版本)
2.查看所有虚拟环境: conda env list - 切换到虚拟环境
1.conda activate 名字 - 退出虚拟环境
1.conda deactivate 名字
3.2 fasttext安装
文档地址: https://fasttext.cc/docs/en/support.html
安装步骤:
1.下载 git clone https://github.com/facebookresearch/fastText.git
2. cd cd fastText
3. 编译 make
4. 安装 python setup.py install
3.3 pysparnn安装
文档地址: https://github.com/facebookresearch/pysparnn
安装步骤:
1.下载: git clone https 😕/github .com/facebookresearch/pysparnn.git
2.安装: python setupy.py install
四、语料准备
目标
- 准备分词词典
- 准备停用词
- 准备问答对
- 爬虫采集相似问题
4.1 分词词典

4.1.1 词典来源
- 各种输入法的词典
例: https://pinyin.sogou.com/dict/cate/index/97?rf=dictindex
例: https://shurufa.baidu.com/dict_list?cid=211 - 手动收集,根据目前的需求,我们可以手动收集如下词典
1.机构名称,例如: 传智 , 传智播客,黑马程序员
2.课程名词,例如: python,人工智能+python ,c++等
4.1.2词典处理
输入法的词典都是特殊格式,需要使用特殊的工具才能够把它转化为文本格式
工具名称:深蓝词库转换.exe
下载地址:https://github.com/studyzy/imewiconverter
4.1.3 对多个词典文件内容进行合并
下载使用不同平台的多个词典之后,把所有的xt文件合并到一起供之后使用
4.2 准备停用词
4.2.1 什么是停用词?
对句子进行分词之后,句子中不重要的词
4.2.2 停用词的准备
常用停用词下载地址: https://github.com/goto456/stopwords
4.2.3 手动筛选和合并
对于停用词的具体内容,不同场景下可能需要保留和去除的词语不一样比如: 词语哪个,很多场景可以删除,但是在判断语义的时候则不行
4.3 问答对的准备
4.3.1 现有问答对的样式
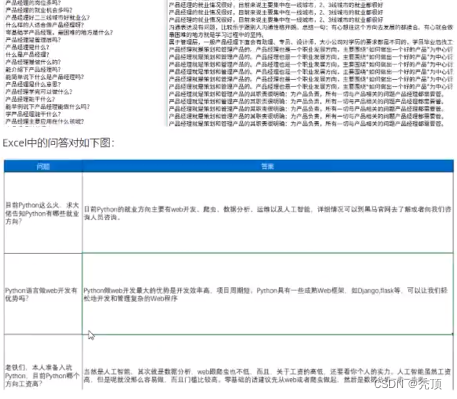
问答对有两部分,一部分是咨询老师整理的问答对,一部分是excel中的问答对,
最终我们需要把问答对分别整理到两个txt文档中,如下图(左边是问题,右边是答案):
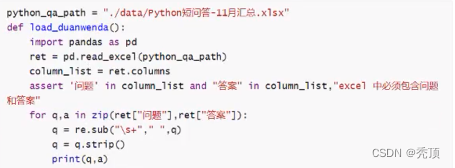
4.3.2 excel中问答对的处理
Excel中的问答对直接使用pandas就能够处理
五、文本分词
目标
- 完成停用词的准备
- 完成分词方法的封装
5.1 准备词典和停用词
5.1.1 准备词典

5.1.2 准备停用词

5.2 准备按照单个字切分句子的方法

5.3 完成分词方法的封装
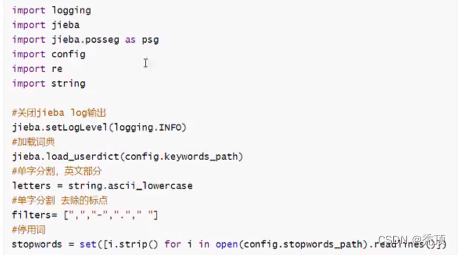
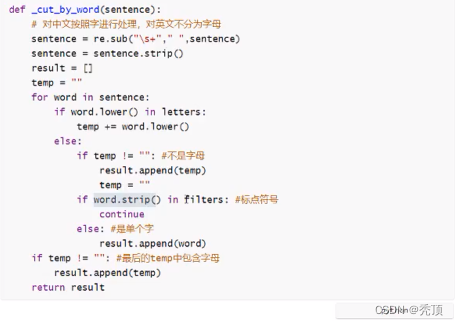
lib 下创建cut_sentencepy文件,完成分词方法的构建


![[附源码]Python计算机毕业设计Django动漫电影网站](https://img-blog.csdnimg.cn/eb33e9e83f9649808902d1da61073d9a.png)


![[附源码]Python计算机毕业设计Django高校实验室仪器设备管理系统](https://img-blog.csdnimg.cn/b2959c7668b0432c83171fcc1fa8fd1e.png)