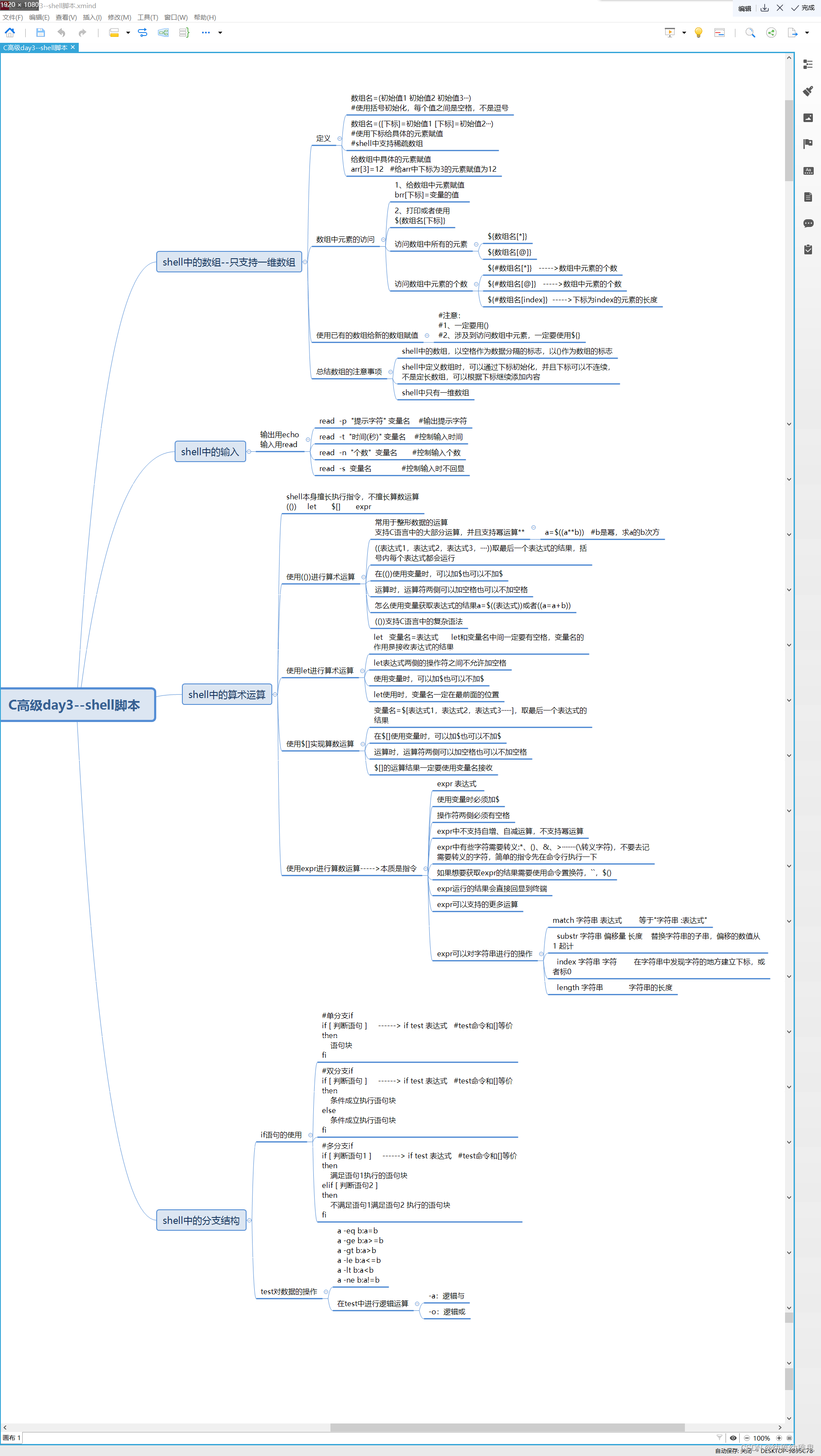
在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务 (99.9%、99.99%、99.999% 等等)。
但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供正常服 务(如主从分离、快速容灾技术),还需要考虑数据容量的扩展、数据安全不会丢失等。
在Redis中,实现高可用的技术主要包括持久化、复制、哨兵和集群,下面分别说明它们的作用,以及解决了什么 样的问题。
- 持久化:持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储 在硬盘,保证数据不会因进程退出而丢失。
- 复制:复制是高可用Redis的基础,哨兵和集群都是在复制基础上实现高可用的。复制主要实现了数据的多机备 份,以及对于读操作的负载均衡和简单的故障恢复。缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力 受到单机的限制。
- 哨兵:在复制的基础上,哨兵实现了自动化的故障恢复。缺陷:写操作无法负载均衡;存储能力受到单机的限 制。
- 集群:通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高 可用方案。
一、Redis持久化
持久化的功能:Redis是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期 将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢 复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置。
Redis持久化分为 RDB持久化和 AOF持久化:前者将当前数据保存到硬盘,后者则是将每次执行的写命令保存 到硬盘(类似于MySQL的binlog);由于AOF持久化的实时性更好,即当进程意外退出时丢失的数据更少,因此 AOF是目前主流的持久化方式,不过RDB持久化仍然有其用武之地。
1.1 RDB持久化
RDB全称为RedisDataBase,RDB持久化是将当前进程中的数据生成快照保存到硬盘(因此也称作快照持久化),保存的文件后缀是rdb,默认的文件名为dump.rdb。当Redis重新启动时,可以读取快照文件恢复数据。
什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
1.1.1 触发条件
RDB持久化的触发分为手动触发和自动触发两种。
1) 手动触发
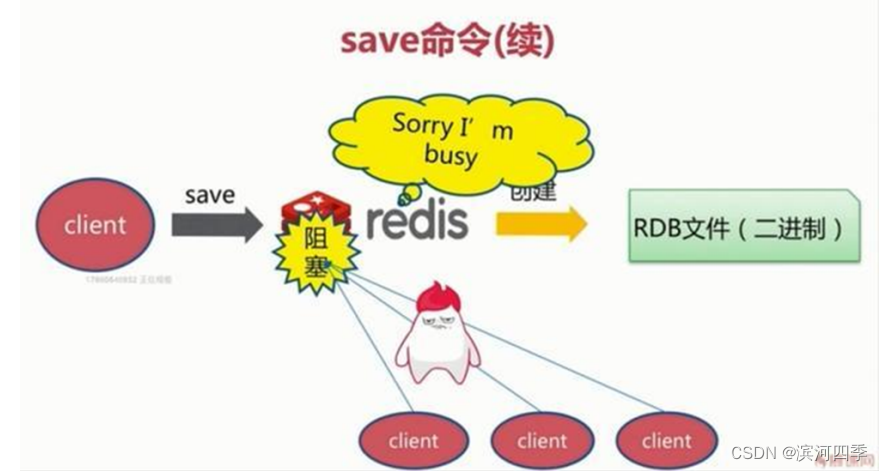
save命令和bgsave命令都可以生成RDB文件。
save命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流 程如下:
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
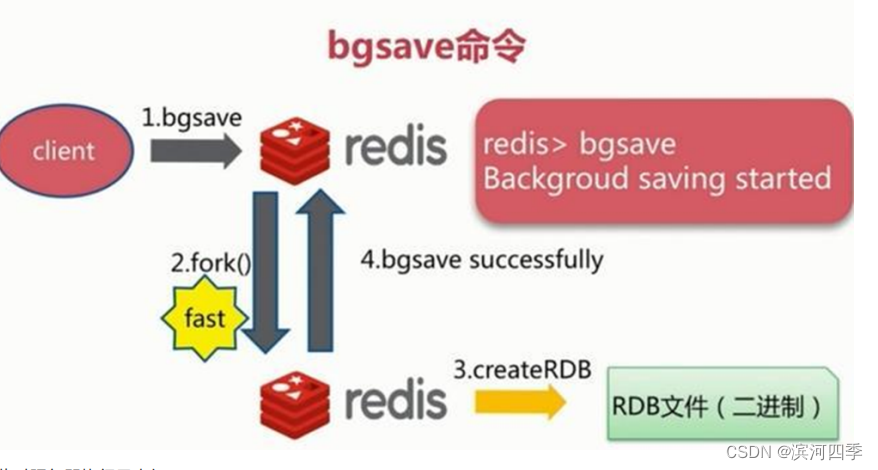
而bgsave命令会创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求。
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
具体操作是:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在 fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用bgsave 命令
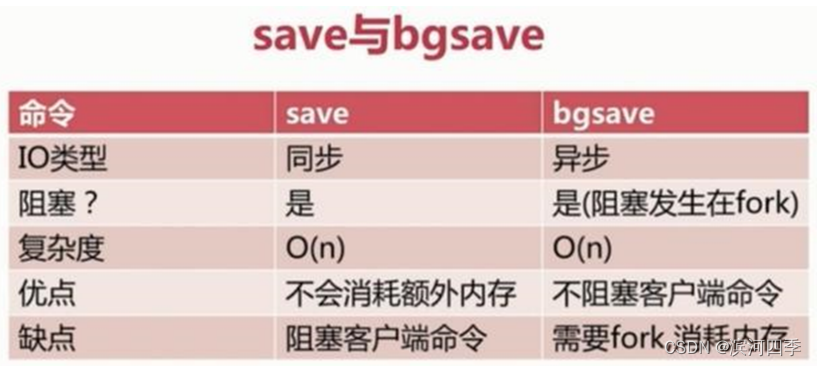
1.1.2 save与bgsave命令对比
bgsave命令执行过程中,只有fork子进程时会阻塞服务器,而对于save命令,整个过程都会阻塞服务器,因此 save已基本被废弃,线上环境要杜绝save的使用;后文中也将只介绍bgsave命令。此外,在自动触发RDB持久化 时,Redis也会选择bgsave而不是save来进行持久化;
2) 自动触发
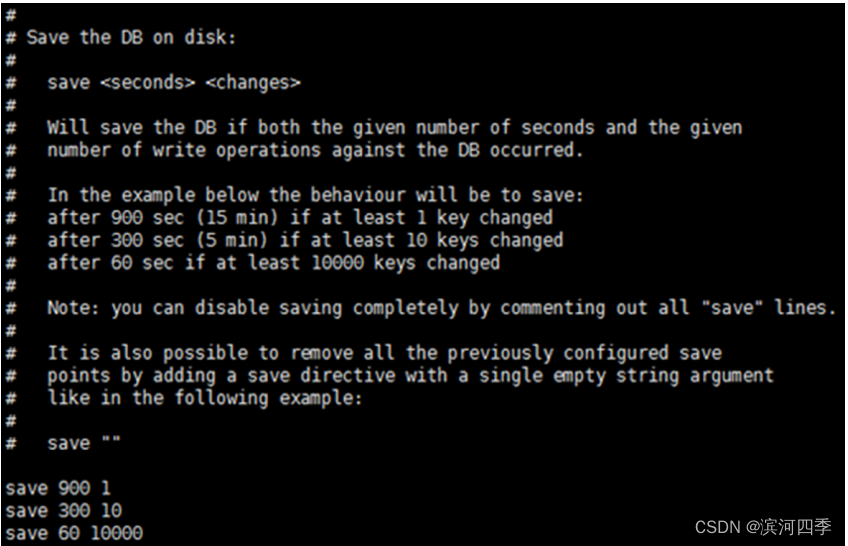
save m n
自动触发最常见的情况是在配置文件中通过save m n,指定当m秒内发生n次变化时,会触发bgsave。 例如,查看redis的默认配置文件(Linux下为redis根目录下的redis.conf),可以看到如下配置信息:
其中save 900 1的含义是:
当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsave;
save 300 10和save 60 10000同理。
当三个save条件满足任意一个时,都会引起bgsave的调用。
1.1.3 相关参数配置解释
参数配置在 redis.conf 文件里。
# save:这里是用来配置触发 Redis的持久化条件,也就是什么时候将内存中的数据保存到硬盘。 默认如下配置
save 900 1 #表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10 #表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000 #表示60 秒内如果至少有 10000 个 key 的值变化,则保存
# 默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没 有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始 接收数据了
stop-writes-on-bgsave-error yes
# 默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行 压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
rdbcompression yes
# 默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的 性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
rdbchecksum yes
设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。使用上面的 dbfilename 作为保存的文件 名。
dir /usr/local/var/db/redis/ 设置快照的文件名,默认是 dump.rdb dbfilename dump.rdb
1.1.4 RDB的优缺点、
优点:
适合大规模的数据恢复,如果业务对数据完整性和一致性要求不高,RDB是很好的选择。
缺点:
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会 开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所 以在快照持久化期间修改的数据不会被保存,可能丢失数据。
1.1.5 RDB备份触发条件:
- 执行save或bgsave命令可触发生成dump.rdb文件
- 执行shutdown命令可以触发生成dump.rdb文件
- 配置文件中如果通过配置参数save m n,指定当m秒内发生n次变化时,会触发bgsave生成dump.rdb文件

1.2 AOF持久化
AOF 全称是Append Only File,是 redis 记录执行指令的日志文件。
1.2.1 AOF工作原理
将写操作追加到文件中,AOF 日志是写后日志,“写后”的意思是 Redis 是先执行命令,把数据写入内存后,然后才 记日志;里面记录的是指令执行的步骤,非常详细,描绘出了数据的变化过程。
工作机制很简单,redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。
1.2.2 AOF持久化原理
每当有一个写命令过来时,就直接保存在我们的AOF文件中。
1.2.3 AOF备份触发条件(配置文件修改三种参数)
- 每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
- 每秒同步everysec:异步操作,每秒记录 如果一秒内宕机,有数据丢失
- 不同no:从不同步
二、RDB备份恢复案例
连接redis,进行数据的增加删除操作
再执行save命令
然后将进程关掉
将rdb文件挪走
在重新启动,连接客户端
可以看到没有数据,因为你将它默认的存储数据的文件挪走了
这时候重新输入两条数据,这时候目录里是没有dump.rdb文件的,因为这时数据是存在内存中的,只用手动执行save命令,才会将数据写到dump.rdb文件里
想要之前的数据回来,就将服务关掉,然后将原来的dump.rdb挪回来
重新开启redis服务,连接redis客户端,查询数据;发现数据回来了





三、AOF备份恢复案例
修改配置文件
重启服务,会有一个appendonly.aof文件
连接客户端,查看是否有数据,发现没有,因为我们这时候使用的是AOF,原来使用RBD存数的数据还在,只是我们不用了;
重新设置数据,发现appendonly.aof文件内存变了,不再是0
然后将服务关掉,将appendonly.aof文件挪走,再启动服务,连接客户端,进行查看数据,发现为空;
再将服务关掉,将原来挪走的aof文件挪回来,
再进行查看,发现有数据了;









![[天翼杯 2021]esay_eval](https://img-blog.csdnimg.cn/f920692342ee45c89f17eee46bbd391c.png)