前言
Mybatis缓存设计成了两层的体系,第一层叫做一级缓存,第二层叫做二级缓存(全局缓存)。我们从这里可以看到Mybatis的缓存方案是有两种处理方式的。
一级缓存(默认开启)
一级缓存默认开启的,程序首先去缓存中查找数据,缓存中没有的话再去数据库中进行查询。
二级缓存(全局缓存)
第一章:一级缓存
一:证明一级缓存默认开启
证明事项:
1:一级缓存默认开启
2:作为一级缓存来讲,只对于本SqlSession有效,别的SqlSession用不了。
二:换SqlSession更普遍
日后的开发过程中,这种换SqlSession是不是常见的呢?换的场景是普遍的,这是为什么呢?
不同的请求过来服务端之后,会有多个请求线程到达我们的服务端,Controler-Service-Dao,
Controller和Service和Dao都有可能是单例或者是多例的。这样的SqlSession是不一样的。
为什么说两个SqlSession是不一样的呢?这是为什么呢?我们开发过程中SqlSession也好,Conneciton也好是不能共享的,一定是一个请求一份。这是因为在开发过程中,这两个对象他是会控制事务的。正因为他们是控制事务的,才不能共享。
那么为什么控制事务的就不能共享呢?这是为什么呢?会产生相互的影响。假如说SqlSession是可以共享的,第一个线程开始事务啥也没干,第二个线程直接把事务提交了,这样不就有问题了么,所以这玩意是不可以共享的。
查询不是不需要事务么?这是不对的,查询在特殊场景下是需要事务的。这个特殊场景是在加悲观锁的时候,必须要事务。第二种说的就是我们二级缓存必须加事务,这样我们的二级缓存才会有效果。
那一般场景查询不是不需要事务的么?实际场景应用的时候,我们极少有只进行select的时候,更多的时候是一个Service把增删改查全干了。所以,这玩意必须要换,一个请求一个。
Mybatis一级缓存的作用和目的并没有那么大了,我们提供缓存的目的是为了是Java程序第二次与查询相同数据的时候可以从缓存中获取,减少与数据库之间的交互。提高系统效率,但是一级缓存如此设计的话,切换了SqlSession是用不上的。一级缓存在Mybatis设计当中对于我们开发帮助是不大的,主要解决的是Mybatis的内部的一些问题,内部比如说关联关系当中解决回环引用的时候使用的,对于应用来讲作用不大。
三:一级缓存源码分析
1:支持回顾
Mybatis通过如下:
sqlSession.getMapper()生成了UserDao的实现类。(代理实现类)
在代理底层调用的时候,实际上调用的是sqlSession.selectAll(),selectOne等方法,在这些方法里边是基于excutor方法来执行的。一级缓存和二级缓存的接入点都是在Excutor当中接入的。
Excutor接口实现类关系如下:
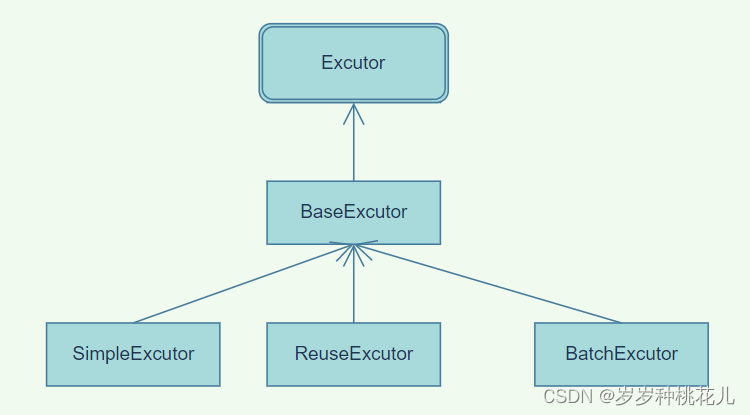
知识补充:
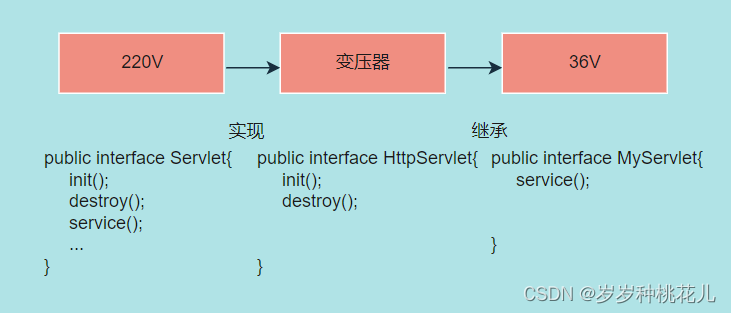
这个结构是一个典型的适配器设计模式。
适配器设计模式解决的是什么问题呢?
适配器就是变压器,适配器就是层层实现即可。一层实现一部分。
什么时候使用适配器模式?
我们这个类只想实现某些方法,将接口中的抽象方法进行分层实现。
2:源码分析
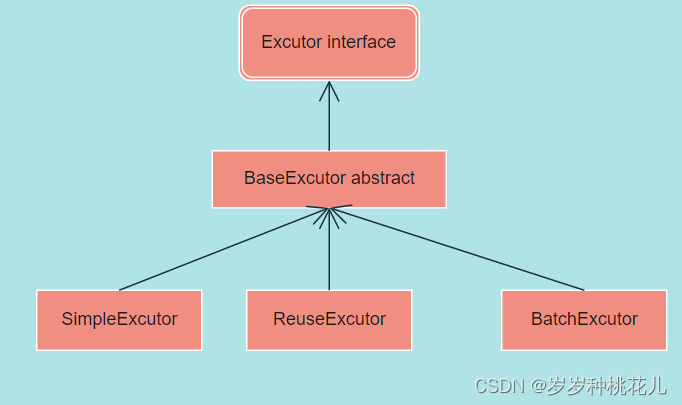
以及缓存当中的核心源码体现在哪里呢?是在BaseExcutor当中。子类都能享受到这个一级缓存的功能。
BaseExcutor当中维护了缓存,这个缓存到底是一个HashMap,两个PerpetualCache缓存一个是基本操作的缓存,一个是存储过程的缓存。存储过程是数据库的编程语言。数据库的变成语言专业名词就叫做存储过程,存储过程逐渐被大数据解决方案代替。
protected PerpetualCache localCache;
protected PerpetualCache localOutputParameterCache;
3:怎么接入缓存?
知识补充:

@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//拼接好的SQL
BoundSql boundSql = ms.getBoundSql(parameter);
//缓存Key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
//执行真正的查询
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
//有缓存查缓存
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
//没缓存查数据库
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//查询数据库
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//查询数据库之后放到缓存当中。
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
总结:
流程逻辑伴随着上述代码展开的,如果缓存中有数据直接返回,如果换出中没有数据为null,就查询数据库,查询数据库之后再将数据放到缓存当中便于下一次的查询。
第一次查询:
先做SQL-- 在做key–查询缓存–查询数据库–数据放到缓存中。
第二次查询:
先做SQL-- 在做key–查询缓存–直接返回数据。
![[天翼杯 2021]esay_eval](https://img-blog.csdnimg.cn/f920692342ee45c89f17eee46bbd391c.png)