hive简介
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,将结构化的数据文件映射为一张表,并提供类SQL(HQL)查询功能。
Hive本质:将HQL转化成MapReduce程序

(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
(4)结构化文件如何映射成一张表的?借助存储在元数据数据库中的元数据来解析结构化文件
Hive架构原理
Hive架构介绍

Hive的运行机制

hive通过给用户提供的一系列交互接口,接收到的用户的指令(SQl),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口中。
Hive和 数据库比较

综上所述,Hive压根就不是数据库,hive除了语言类似意外,存储和计算都是使用Hadoop来完成的。而Mysql则是使用自己的,拥有自己的体系。
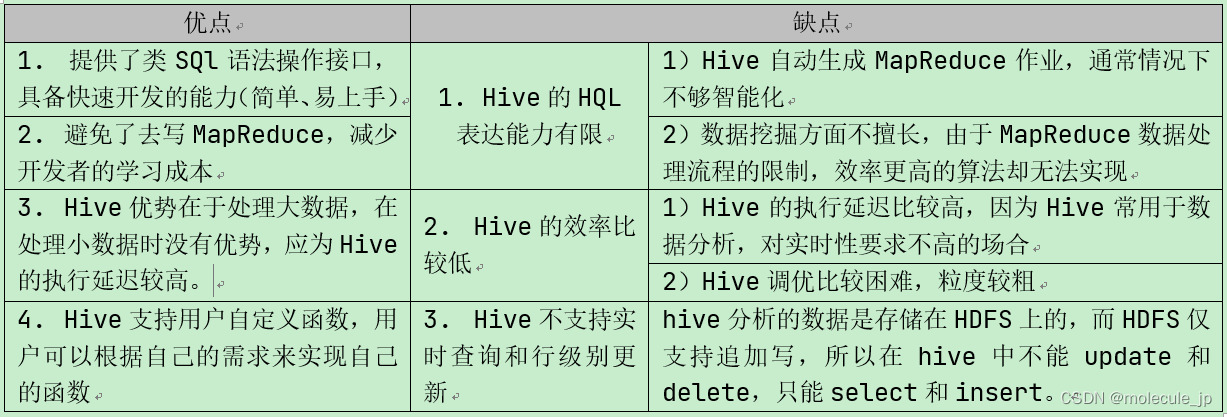
Hive的优缺点
Hive安装
修改hadoop相关参数
1)修改core-site.xml
[aa@hadoop102 hive]$ vim /opt/module/hadoop/etc/hadoop/core-site.xml
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
2)配置yarn-site.xml
[aa@hadoop102 hive]$ vim /opt/module/hadoop/etc/hadoop/yarn-site.xml
<!-- NodeManager使用内存数,默认8G,修改为4G内存 -->
<property>
<description>Amount of physical memory, in MB, that can be allocated
for containers. If set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically calculated(in case of Windows and Linux).
In other cases, the default is 8192MB.
</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 容器最小内存,默认512M -->
<property>
<description>The minimum allocation for every container request at the RM in MBs.
Memory requests lower than this will be set to the value of this property.
Additionally, a node manager that is configured to have less memory than this value
</description>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 容器最大内存,默认8G,修改为4G -->
<property>
<description>The maximum allocation for every container request at the RM in MBs.
Memory requests higher than this will throw an InvalidResourceRequestException.
</description>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- 虚拟内存检查,默认打开,修改为关闭 -->
<property>
<description>Whether virtual memory limits will be enforced for containers.</description>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
注意:修改完配置文件记得分发,然后重启集群。
Hive解压安装
1)把apache-hive-3.1.2-bin.tar.gz上传到linux的/opt/software目录下
2)将/opt/software/目录下的apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面
[aa@hadoop102 software]$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
3)修改解压后的目录名称为hive
[aa@hadoop102 module]$ mv apache-hive-3.1.2-bin/ /opt/module/hive
4)修改/etc/profile.d/my_env.sh文件,将hive的/bin目录添加到环境变量
[aa@hadoop102 hive]$ sudo vim /etc/profile.d/my_env.sh
……
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
[atguigu@hadoop102 hive]$ source /etc/profile