目录
- len的魔力
- 评论区大佬解答
- 答案详解
- 结构体是否相等
- 答案解析:
- 结构体比较规则
- 举例
- 常量的编译
- 我的答案
- 标准答案
- 内存四区概念:
- new关键字
- 答案
- iota的魔力
- 结果
- 解析
- 可跳过的值
- 定义在一行
- 中间插队
- 小结
- iota详解
- iota 原理
- iota 规则
- 依赖 const
- 按行计数
- 多个iota
- 空行处理
- 跳值占位
- 开头插队
- 中间插队
- 一行多个iota
- 小结
- nil赋值
- 答案解析:
- 接口
- 答案解析
- 空接口
- 非空接口 iface
- 答案
- 结构体json
- 答案
- 解析
- json.Marshal 函数的文档
- 类型断言
- 答案
- 解析
- channel
- 答案
- 解析
- sync.WaitGroup
- 答案
- 解析
- 空map取值
- 答案
- 注意
- 可变参数函数
- 答案
- 解析
- 可变参数
- 与传切片的区别
- 结构体嵌套接口
- 答案
- 解析
- Go 没有继承,但可以通过内嵌类型模拟部分继承的功能。
- 实例
- 回到题目
- 切片的第三个参数
- 答案
- 第三个参数
- %+d
- 答案
- 解析
- 匿名结构体嵌套
- 答案
- 解析
- defer的执行顺序
- 答案解析:
- interface{}接口类型
- 答案
- 解析
- 切片扩容
- 答案
- 解析
- 图示
- 当且仅当动态值和动态类型都为 nil 时,接口类型值才为 nil
- 答案解析
- String()方法
- 答案解析
- map 的 value 是不可寻址的
- 答案解析
- 解决方案
- 一个select死锁问题
- 结果
- 解析
- 相同问题
- 更多类似的问题
- 最典型的问题
- 循环中改变切片长度是否会死循环
- 答案解析
- python会
- defer再探
- 答案解析
- range数组和range指针
- 答案解析
- 结论
- 切片传参和切片扩容
- 答案解析
- range赋值地址
- 答案解析
- 同理如下
- range map
- 答案解析
- 多重赋值的坑
- 答案解析
- 如何判断map是否相等
- 答案
- DeepEqual部分源码
- Go 1.15 中 var i interface{} = a 会有额外堆内存分配吗?
- 答案解析
- 基准测试
- GO结构体字典值拷贝和值引用
- 答案解析:
- 结果
- 分析
len的魔力
package main
const s = "Go101.org"
// len(s) == 9
// 1 << 9 == 512
// 512 / 128 == 4
var a byte = 1 << len(s) / 128
var b byte = 1 << len(s[:]) / 128
func main() {
println(a, b)
}
-----------------------------------
>>> 4 0
评论区大佬解答
-
len(s)若s为字符串常量或者简单的数组表达式,则len返回的为int型的常量,若s为不为上述情况(有函数计算、通道等),则len返回的为int型的变量
-
关于位移操作,如果常量位移表达式的左侧操作数是一个无类型常量,那么其结果是一个整数常量,否则就是和左侧操作数同一类型的常量(必须是整数类型 );如果一个非常量位移表达式的左侧的操作数是一个无类型常量,那么它会先被隐式地转换为假如位移表达式被其左侧操作数单独替换后的类型。
-
“先被隐式地转换为假如位移表达式被其左侧操作数单独替换后的类型" :对于var b byte = 1 << len(s[:]),1 << len(s[:])会被隐式的转换为var b byte = 1(表达式被1单独替换)的类型,1为无类型常量,因为b为byte,所以1会被隐式转换为byte,所以1 << len(s[:])为byte类型。
-
s为常量表达式。对于var a byte = 1 << len(s) / 128,len(s)返回整型常量,所以1 << len(s)为常量表达式,且1为无类型常量,符合位移操作的第一种情况,所以为表达式结果为整型常量,故最后计算为4;
-
对于var b byte = 1 << len(s[:]) / 128,s[:]为函数计算,所以len(s[:])返回的为整型变量,所以1 << len(s[:]) / 128为非常量表达式,且1为无类型常量,符合位移操作的第二种情况,所以为表达式结果为byte,1<<9为512,转为byte类型,结果溢出,为0。
答案详解
-
len 是一个内置函数,在官方标准库文档关于 len 函数 有这么一句:
For some arguments, such as a string literal or a simple array expression, the result can be a constant. See the Go language specification’s “Length and capacity” section for details.(当参数是字符串字面量和简单 array 表达式,len 函数返回值是常量)
-
内置函数 len 和 cap 获取各种类型的实参并返回一个 int 类型结果。实现会保证结果总是一个 int 值。如果 s 是一个字符串常量,那么 len(s) 是一个常量 。如果 s 类型是一个数组或到数组的指针且表达式 s 不包含信道接收或(非常量的) 函数调用的话, 那么表达式 len(s) 和 cap(s) 是常量,这种情况下, s 是不求值的。否则的话, len 和 cap 的调用结果不是常量且 s 会被求值。
-
第一句的 len(s) 是常量(因为 s 是字符串常量);而第二句的 len(s[:]) 不是常量。这是这两条语句的唯一区别:两个 len 的返回结果数值并无差异,都是 9,但一个是常量一个不是。
var a byte = 1 << len(s) / 128 var b byte = 1 << len(s[:]) / 128 -
关于位移操作,在位移表达式的右侧的操作数必须为整数类型,或者可以被 uint 类型的值所表示的无类型的常量。如果一个非常量位移表达式的左侧的操作数是一个无类型常量,那么它会先被隐式地转换为假如位移表达式被其左侧操作数单独替换后的类型。
这里的关键在于常量位移表达式。根据上文的分析,1 << len(s) 是常量位移表达式,而 1 << len(s[:]) 不是。 -
如果常量位移表达式的左侧操作数是一个无类型常量,那么其结果是一个整数常量;否则就是和左侧操作数同一类型的常量(必须是整数类型 )
因此对于 var a byte = 1 << len(s) / 128,因为 1 << len(s) 是一个常量位移表达式,因此它的结果也是一个整数常量,所以是 512,最后除以 128,最终结果就是 4。
而对于 var b byte = 1 << len(s[:]) / 128,因为 1 << len(s[:]) 不是一个常量位移表达式,而做操作数是 1,一个无类型常量,根据规范定义它是 byte 类型(根据:如果一个非常量位移表达式的左侧的操作数是一个无类型常量,那么它会先被隐式地转换为假如位移表达式被其左侧操作数单独替换后的类型)。
所以 var b byte = 1 << len(s[:]) / 128 中,根据规范定义,1 会隐式转换为 byte 类型,因此 1 << len(s[:]) 的结果也是 byte 类型,而 byte 类型最大只能表示 255,很显然 512 溢出了,结果为 0,因此最后 b 的结果也是 0。
结构体是否相等
下面代码是否可以编译通过?为什么?
package main
import "fmt"
func main() {
sn1 := struct {
age int
name string
}{age: 11, name: "qq"}
sn2 := struct {
age int
name string
}{age: 11, name: "qq"}
if sn1 == sn2 {
fmt.Println("sn1 == sn2")
}
sm1 := struct {
age int
m map[string]string
}{age: 11, m: map[string]string{"a": "1"}}
sm2 := struct {
age int
m map[string]string
}{age: 11, m: map[string]string{"a": "1"}}
if sm1 == sm2 {
fmt.Println("sm1 == sm2")
}
}
答案解析:
编译不通过。
结构体比较规则
- 只有相同类型的结构体才可以比较,结构体是否相同不但与属性类型个数有关,还与属性顺序相关。
- 结构体是相同的,但是结构体属性中有不可以比较的类型,如map,slice,则结构体不能用==比较。
举例
sn1 := struct {
age int
name string
}{age: 11, name: "qq"}
sn3:= struct {
name string
age int
}{age:11, name:"qq"}
sn3与sn1就不是相同的结构体了,不能用等于号比较。但可以使用reflect.DeepEqual进行比较
if reflect.DeepEqual(sm1, sm2) {
fmt.Println("sm1 == sm2")
} else {
fmt.Println("sm1 != sm2")
}
常量的编译
下面代码有什么问题?
package main
const cl = 100
var bl = 123
func main() {
println(&bl,bl)
println(&cl,cl)
}
我的答案
这个还是比较简单的,因为常量在预处理的时候直接替换到代码中,相当于在某处直接写了一个常量值。

标准答案
- 常量不同于变量的在运行期分配内存,常量通常会被编译器在预处理阶段直接展开,作为指令数据使用。
内存四区概念:
-
数据类型本质:固定内存大小的别名
-
数据类型的作用:编译器预算对象(变量)分配的内存空间大小。
-
内存四区:
栈区(Stack):
空间较小,要求数据读写性能高,数据存放时间较短暂。由编译器自动分配和释放,存放函数的参数值、函数的调用流程方法地址、局部变量等(局部变量如果产生逃逸现象,可能会挂在在堆区)
堆区(heap):
空间充裕,数据存放时间较久。一般由开发者分配及释放(但是Golang中会根据变量的逃逸现象来选择是否分配到栈上或堆上),启动Golang的GC由GC清除机制自动回收。
全局区-静态全局变量区:
全局变量的开辟是在程序在main之前就已经放在内存中。而且对外完全可见。即作用域在全部代码中,任何同包代码均可随时使用,在变量会搞混淆,而且在局部函数中如果同名称变量使用:=赋值会出现编译错误。全局变量最终在进程退出时,由操作系统回收。
全局区-常量区:
常量区也归属于全局区,常量为存放数值字面值单位,即不可修改。或者说的有的常量是直接挂钩字面值的。
const cl = 10
cl是字面量10的对等符号。
所以在golang中,常量是无法取出地址的,因为字面量符号并没有地址而言。
new关键字
下面这段代码能否通过编译?
func main() {
list := new([]int)
list = append(list, 1)
fmt.Println(list)
}
答案
过于简单,new()的返回值是[]int类型的指针且为nil,对nil不可操作
iota的魔力
下面这段代码能否编译通过?如果可以,输出什么?
const (
x = iota
_
y
z = "zz"
k
p = iota
)
func main() {
fmt.Println(x,y,z,k,p)
}
结果

解析
iota是golang语言的常量计数器,只能在常量的表达式中使用。

iota在const关键字出现时将被重置为0(const内部的第一行之前),const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。
可跳过的值
可以使用下划线跳过不想要的值。
const (
OutMute AudioOutput = iota // 0
OutMono // 1
OutStereo // 2
_
_
OutSurround // 5
)
定义在一行
const (
Apple, Banana = iota + 1, iota + 2
Cherimoya, Durian
Elderberry, Fig
)
-----------------------------------
// Apple: 1
// Banana: 2
// Cherimoya: 2
// Durian: 3
// Elderberry: 3
// Fig: 4
iota 在下一行增长,而不是立即取得它的引用。
中间插队
const (
i = iota
j = 3.14
k = iota
l
)
那么打印出来的结果是 i=0,j=3.14,k=2,l=3
小结
- iota初始值为0,出现一次const自增1
- 省略const语句时,代表与上一句相同
const (
x = iota
_
y
z = "zz"
k
p = iota
)
写完整是:
const (
x = iota // 0
_ = iota // 1 _代表不需要这个值
y = iota // 2
z = "zz" // zz iota=3
k = "zz" // zz iota=4
p = iota // 5
)
值得注意的是:iota是在一个const递增的
package main
import "fmt"
const a = iota
const b = iota
func main() {
fmt.Println(a,b)
}
-----------------------------
0 0
iota详解
iota 的主要使用场景用于枚举。Go 语言的设计原则追求极尽简化,所以没有枚举类型,没有 enum关键字。
Go 语言通常使用常量定义代替枚举类型,于是 iota 常常用于其中,用于简化代码。
package main
const (
B = 1 << (10 * iota) // 1 << (10*0)
KB // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 7 << (10*5)
)
func main() {
println(B, KB, MB, GB, TB)
}
或
const (
B = 1
KB = 1024
MB = 1048576
GB = 1073741824
...
)
不使用 iota 的代码,对于代码洁癖者来说,简直就是一坨,不可接受。
而 Go 语言的发明者,恰恰具有代码洁癖,而且还是深度洁癖。Go 语言设计初衷之一:追求简洁优雅。
iota 原理
iota 源码在 Go 语言代码库中,只有一句定义语句,
const iota = 0 // Untyped int.
iota 是一个预声明的标识符,它的值是 0。 在 const 常量声明中,作为当前 const 代码块中的整数序数。
package main
const (
FirstItem = iota
SecondItem
ThirdItem
)
func main() {
println(FirstItem)
println(SecondItem)
println(ThirdItem)
}
编译上述代码:
# 使用 -N -l 编译参数用于禁止内联和优化,防止编译器优化和简化代码,弄乱次序。这样便于阅读汇编代码。
go tool compile -N -l main.go
# 导出汇编代码:
go tool objdump main.o
TEXT %22%22.main(SB) gofile../Users/wangzebin/test/test/main.go
...
main.go:10 MOVQ $0x0, 0(SP) // 对应源码 println(FirstItem)
main.go:10 CALL 0x33b [1:5]R_CALL:runtime.printint
...
main.go:11 MOVQ $0x1, 0(SP) // 对应源码 println(SecondItem)
main.go:11 CALL 0x357 [1:5]R_CALL:runtime.printint
...
main.go:11 MOVQ $0x2, 0(SP) // 对应源码 println(ThirdItem)
main.go:11 CALL 0x373 [1:5]R_CALL:runtime.printint
...
编译之后,对应的常量 FirstItem、SecondItem 和 ThirdItem,分别替换为$0x0、$0x1 和 $0x2。
这说明:Go代码中定义的常量,在编译时期就会被替换为对应的常量(所以根本不会有地址)。当然 iota,也不可避免地在编译时期,按照一定的规则,被替换为对应的常量。
所以,Go 语言源码库中是不会有 iota 源码了,它的魔法在编译时期就已经施展完毕。也就是说,解释 iota 的代码包含在 go 这个命令和其调用的组件中。
如果你要阅读它的源码,准确的说,阅读处理 iota 关键字的源码,需要到 Go 工具源码库中寻找,而不是 Go 核心源码库。
iota 规则
使用 iota,虽然可以书写简洁优雅的代码,但对于不熟悉规则的人来讲,又带来的很多不必要的麻烦和误解。
对于引入 iota,到底好是不好,每个人都有自己的评价。实际上,有些不常用的写法,甚至有些卖弄编写技巧的的写法,并不是设计者的初衷。
大多数情况下,我们还是使用最简单最明确的写法,iota 只是提供了一种选择而已。一个工具使用的好坏,取决于使用它的人,而不是工具本身。
以下是 iota 编译规则:
依赖 const
iota 依赖于 const 关键字,每次新的 const 关键字出现时,都会让 iota 初始化为0。
const a = iota // a=0
const (
b = iota // b=0
c // c=1
)
按行计数
iota 按行递增加 1。
const (
a = iota // a=0
b // b=1
c // c=2
)
多个iota
同一 const 块出现多个 iota,只会按照行数计数,不会重新计数。
const (
a = iota // a=0
b = iota // b=1
c = iota // c=2
)
空行处理
空行在编译时期首先会被删除,所以空行不计数。
const (
a = iota // a=0
b // b=1
c // c=2
)
跳值占位
占位 “_”,它不是空行,会进行计数,起到跳值作用。
const (
a = iota // a=0
_ // _=1
c // c=2
)
开头插队
开头插队会进行计数。
const (
i = 3.14 // i=3.14
j = iota // j=1
k = iota // k=2
l // l=3
)
中间插队
中间插队会进行计数。
const (
i = iota // i=0
j = 3.14 // j=3.14
k = iota // k=2
l // l=3
)
一行多个iota
一行多个iota,分别计数。
const (
i, j = iota, iota // i=0,j=0
k, l // k=1,l=1
)
小结
对于20221016中文网给出的每日一题来说,这样的iota用法完成就是一坨大便,就如同大家痛恨的某cpp书中a++--++之类的代码,如果用Go的思想去看,你的代码写成这样只说明了两点:1. 你的代码出问题了 2. 你人出问题了。
nil赋值
下面赋值正确的是:
A. var x = nil
B. var x interface{} = nil
C. var x string = nil
D. var x error = nil
答案解析:
参考答案及解析:BD。
这道题考的知识点是 nil。nil 只能赋值给指针、chan、func、interface、map 或 slice 类型的变量。强调下 D 选项的 error 类型,它是一种内置接口类型,看它的源码就知道,所以 D 是对的。
type error interface {
Error() string
}
接口
以下代码打印出来什么内容
package main
import (
"fmt"
)
type People interface {
Show()
}
type Student struct{}
func (stu *Student) Show() {
}
func live() People {
var stu *Student
return stu
}
func main() {
if live() == nil {
fmt.Println("AAAAAAA")
} else {
fmt.Println("BBBBBBB")
}
}
答案解析
interface 在使用的过程中,共有两种表现形式:一种为空接口(empty interface),
另一种为非空接口(non-empty interface)
空接口
空接口 eface 结构,由两个属性构成,一个是类型信息 _type,一个是数据信息。
type eface struct { // 空接口
_type *_type // 类型信息
data unsafe.Pointer // 指向数据的指针
}
非空接口 iface
face 结构中最重要的是 itab 结构(结构如下),每一个 itab 都占 32 字节的空间。
type iface struct {
tab *itab
data unsafe.Pointer
}
itab 里面包含了 interface 的一些关键信息,比如 method 的具体实现。
type itab struct {
inter *interfacetype // 接口自身的元信息
_type *_type // 具体类型的元信息
hash int32 // _type 里也有一个同样的 hash,此处多放一个是为了方便运行接口断言
_ [4]byte
fun [1]uintptr // 函数指针,指向具体类型所实现的方法
}
答案
所以,People 拥有一个 Show 方法,属于非空接口,People 的内部定义是一个iface结构体。
type People interface {
Show()
}
stu 是一个指向 nil 的空指针,但是最后return stu 会触发匿名变量 People = stu 值拷贝动作,所以最后live()放回给上层的是一个People insterface{}类型,也就是一个iface struct{}类型。 stu 为 nil,只是iface中的 data 为 nil 而已。 但是iface struct{}本身并不为 nil.
func live() People {
var stu *Student
return stu
}
结构体json
以下代码输出什么
package main
import (
"encoding/json"
"fmt"
"time"
)
func main() {
t := struct {
time.Time
N int
}{
time.Date(2020, 12, 20, 0, 0, 0, 0, time.UTC),
5,
}
m, _ := json.Marshal(t)
fmt.Printf("%s", m)
}
答案
"2020-12-20T00:00:00Z"
解析
package main
import (
"encoding/json"
"fmt"
)
type Person struct {
Name string `json:"name"`
Hobby string `json:"hobby"`
}
func main() {
person := Person{name: "polarisxu", hobby: "Golang"}
m, _ := json.Marshal(person)
fmt.Printf("%s", m)
}
要想输出 {“name”:“polarisxu”,“hobby”:"Golang”},一般我们会这么做:将 Person 的字段导出,同时设置上 tag。
但如果不想导出 Person 的字段可以通过实现 Marshaler 来做到。
func (p Person) MarshalJSON() ([]byte, error) {
return []byte(`{"name":"`+p.name+`","hobby":"`+p.hobby+`"}`), nil
}
time.Time 是一个没有导出任何字段的结构体类型,因此它肯定实现了 Marshaler 接口。
type Time struct {
// contains filtered or unexported fields
}
// MarshalJSON implements the json.Marshaler interface.
// The time is a quoted string in RFC 3339 format, with sub-second precision added if present.
func (t Time) MarshalJSON() ([]byte, error) {
if y := t.Year(); y < 0 || y >= 10000 {
// RFC 3339 is clear that years are 4 digits exactly.
// See golang.org/issue/4556#c15 for more discussion.
return nil, errors.New("Time.MarshalJSON: year outside of range [0,9999]")
}
b := make([]byte, 0, len(RFC3339Nano)+2)
b = append(b, '"')
b = t.AppendFormat(b, RFC3339Nano)
b = append(b, '"')
return b, nil
}
正是因为内嵌,t 的方法集包括了 time.Time 的方法集,所以,t 自动实现了 Marshaler 接口。
其实这道题的情况,在日常工作中还真有可能遇到。所以,当你内嵌某个类型时,特别这个类型不是你自己定义的,需要留意这种情况。
一般解决这个问题的方法有两种:1)不内嵌;2)重新实现 MarshalJSON 方法。
然而这道题无法重新实现 MarshalJSON 方法,因为结构体类型是匿名的。只能通过不内嵌来得到正确的结果。
json.Marshal 函数的文档
Marshal traverses the value v recursively. If an encountered value implements the Marshaler interface and is not a nil pointer, Marshal calls its MarshalJSON method to produce JSON. If no MarshalJSON method is present but the value implements encoding.TextMarshaler instead, Marshal calls its MarshalText method and encodes the result as a JSON string. The nil pointer exception is not strictly necessary but mimics a similar, necessary exception in the behavior of UnmarshalJSON.
如果值实现了 json.Marshaler 接口并且不是 nil 指针,则 Marshal 函数会调用其 MarshalJSON 方法以生成 JSON。如果不存在 MarshalJSON 方法,但该值实现 encoding.TextMarshaler 接口,则 Marshal 函数调用其 MarshalText 方法并将结果编码为 JSON 字符串。
可见,json.Marshal 函数优先调用 MarshalJSON,然后是 MarshalText,如果都没有,才会走正常的类型编码逻辑。
类型断言
下面这段代码能否编译通过?如果可以,输出什么?
func GetValue() int {
return 1
}
func main() {
i := GetValue()
switch i.(type) {
case int:
println("int")
case string:
println("string")
case interface{}:
println("interface")
default:
println("unknown")
}
}
答案
编译失败。
解析
类型断言,类型断言的语法形如:i.(type),其中 i 是接口,type 是固定关键字,需要注意的是,只有接口类型才可以使用类型断言。
channel
执行下面的代码会发生什么
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int, 1000)
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
}()
go func() {
for {
a, ok := <-ch
if !ok {
fmt.Println("close")
return
}
fmt.Println("a: ", a)
}
}()
close(ch)
fmt.Println("ok")
time.Sleep(time.Second * 100)
}
答案
panic: send on closed channel
解析
- 给一个 nil channel 发送数据,造成永远阻塞
- 从一个 nil channel 接收数据,造成永远阻塞
- 给一个已经关闭的 channel 发送数据,引起 panic
- 从一个已经关闭的 channel 接收数据,如果缓冲区中为空,则返回一个零值
- 无缓冲的channel是同步的,而有缓冲的channel是非同步的
本题中,因为 main 在开辟完两个 goroutine 之后,立刻关闭了 ch, 结果就是 panic
sync.WaitGroup
以下代码有什么问题
package main
import (
"sync"
)
const N = 10
var wg = &sync.WaitGroup{}
func main() {
for i := 0; i < N; i++ {
go func(i int) {
wg.Add(1)
println(i)
defer wg.Done()
}(i)
}
wg.Wait()
}
答案
输出结果不唯一,代码存在风险, 所有 go 语句未必都能执行到。
解析
go语句执行太快了,导致 wg.Add(1) 还没有执行 main 函数就执行完毕了。wg.Add 的位置放错了。
空map取值
下面这段代码输出什么?
type person struct {
name string
}
func main() {
var m map[person]int
p := person{"mike"}
fmt.Println(m[p])
}
答案
- m 是一个 map,值是 nil。
- 从 nil map 中取值不会报错,而是返回相应的零值,这里值是 int 类型,因此返回 0。
注意
- nil map 可以取值,但不能直接赋值
可变参数函数
下面这段代码输出什么?
func hello(num ...int) {
num[0] = 18
}
func main() {
i := []int{5, 6, 7}
hello(i...)
fmt.Println(i[0])
}
答案
18
解析
可变参数函数会将参数变成切片
func hello(num ...int) {
fmt.Println(num)
fmt.Printf("%T \n",num)
}
func main() {
hello(1,2,3,4,5)
fmt.Println()
}

值拷贝的形式传入,底层数组是一样的
func hello(num ...int) {
fmt.Println(num)
fmt.Printf("%T \n",num)
println(&num)
num[0]=18
}
func main() {
a:=[]int{1,2,3,4,5}
println(&a)
hello(a...)
println(&a)
fmt.Println(a)
}

可变参数是切片,切片是引用,所以func内赋值会带出来。
可变参数
func sum(vals ...int) int
----------------------------------
fmt.Println(sum()) // "0"
fmt.Println(sum(3)) // "3"
fmt.Println(sum(1, 2, 3, 4)) // "10"
- 在上面的代码中,调用者隐式的创建一个数组,并将原始参数复制到数组中,再把数组的一个切片作为参数传给被调用函数。
- 如果原始参数已经是切片类型,只需在最后一个参数后加上省略符。
下面的代码功能与上个例子中最后一条语句相同。
values := []int{1, 2, 3, 4}
fmt.Println(sum(values...)) // "10"
与传切片的区别
虽然在可变参数函数内部,…int 型参数的行为看起来很像切片类型,但实际上,可变参数函数和以切片作为参数的函数是不同的。
func f(...int) {}
func g([]int) {}
fmt.Printf("%T\n", f) // "func(...int)"
fmt.Printf("%T\n", g) // "func([]int)"
结构体嵌套接口
以下代码能否通过编译?
package main
import (
"fmt"
)
type worker interface {
work()
}
type person struct {
name string
worker
}
func main() {
var w worker = person{}
fmt.Println(w)
}
答案
能通过编译
解析
Go 没有继承,但可以通过内嵌类型模拟部分继承的功能。
- 接口也是类型,自然也将它作为嵌入类型。
- 这个类型默认就实现了这个接口
- 实例化 person 时,没有给 worker 指定值,因此 person 中的 worker 是 nil,调用它的话会报错
type person struct {
name string
worker worker
}
实例
sort包中:
- 这是用于排序的
type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less reports whether the element with
// index i should sort before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}
- 这是用于倒序的
type reverse struct {
// This embedded Interface permits Reverse to use the methods of
// another Interface implementation.
Interface
}
- 使用
func Reverse(data Interface) Interface {
return &reverse{data}
}
实例化 reverse 时,直接通过传递的 Interface 实例赋值给 reverse 的内嵌接口,然后 reverse 类型可以有选择的重新实现内嵌的 Interface 的方法。
回到题目
通过实例化的 w 调用 work 方法会报错,需要给 person 中的 worker 实例化,也就是需要一个实现了 worker 接口的类型实例。
type student struct{
name string
}
func (s student) work() {
fmt.Println("I am ", s.name, ", I am learning")
}
然后这样实例化 person:
var w worker = person{worker: student{"polarisxu"}}
切片的第三个参数
package main
import (
"fmt"
)
func main() {
a := [5]int{1, 2, 3, 4, 5}
t := a[3:4:4]
fmt.Println(t[0])
}
答案
4
第三个参数
- 截取操作符还可以有第三个参数,形如 [i,j,k],第三个参数 k 用来限制新切片的容量,但不能超过原数组(切片)的底层数组大小。
- 截取获得的切片的长度和容量分别是:j-i、k-i。
%+d
func main() {
i := -5
j := +5
fmt.Printf("%+d %+d", i, j)
}
答案
参考答案及解析:A。
解析
%d表示输出十进制数字,+表示输出数值的符号。这里不表示取反。
匿名结构体嵌套
下面这段代码输出什么?
type People struct{}
func (p *People) ShowA() {
fmt.Println("showA")
p.ShowB()
}
func (p *People) ShowB() {
fmt.Println("showB")
}
type Teacher struct {
People
}
func (t *Teacher) ShowB() {
fmt.Println("teacher showB")
}
func main() {
t := Teacher{}
t.ShowB()
}
答案
teacher showB。
解析
- 在嵌套结构体中,People 称为内部类型,Teacher 称为外部类型;
- 通过嵌套,内部类型的属性、方法,可以为外部类型所有,就好像是外部类型自己的一样。
- 此外,外部类型还可以定义自己的属性和方法,甚至可以定义与内部相同的方法,这样内部类型的方法就会被“屏蔽”。
- 这个例子中的 ShowB() 就是同名方法。
defer的执行顺序
下面代码段输出什么?
type Person struct {
age int
}
func main() {
person := &Person{28}
// 1.
defer fmt.Println(person.age)
// 2.
defer func(p *Person) {
fmt.Println(p.age)
}(person)
// 3.
defer func() {
fmt.Println(person.age)
}()
person.age = 29
}
答案解析:
参考答案及解析:29 29 28。变量 person 是一个指针变量 。
1.person.age 此时是将 28 当做 defer 函数的参数,会把 28 缓存在栈中,等到最后执行该 defer 语句的时候取出,即输出 28;
2.defer 缓存的是结构体 Person{28} 的地址,最终 Person{28} 的 age 被重新赋值为 29,所以 defer 语句最后执行的时候,依靠缓存的地址取出的 age 便是 29,即输出 29;
3.很简单,闭包引用,输出 29;
又由于 defer 的执行顺序为先进后出,即 3 2 1,所以输出 29 29 28。
interface{}接口类型
A、B、C、D 哪些选项有语法错误?
type S struct {
}
func f(x interface{}) {
}
func g(x *interface{}) {
}
func main() {
s := S{}
p := &s
f(s) //A
g(s) //B
f(p) //C
g(p) //D
}
答案
BD。
解析
-
函数参数为 interface{} 时可以接收任何类型的参数,包括用户自定义类型等,即使是接收指针类型也用 interface{},而不是使用 *interface{}。
-
永远不要使用一个指针指向一个接口类型,因为它已经是一个指针。
切片扩容
func main() {
s1 := []int{1, 2, 3}
s2 := s1[1:]
s2[1] = 4
fmt.Println(s1)
s2 = append(s2, 5, 6, 7)
fmt.Println(s1)
}
答案
[1 2 4]
[1 2 4]
解析
- golang 中切片底层的数据结构是数组
- 当使用 s1[1:] 获得切片 s2,和 s1 共享同一个底层数组,这会导致 s2[1] = 4 语句影响 s1。
- append 操作会导致底层数组扩容,生成新的数组,因此追加数据后的 s2 不会影响 s1。
图示
s1 := []int{1, 2, 3}
s2 := s1[1:]

s2[1] = 4
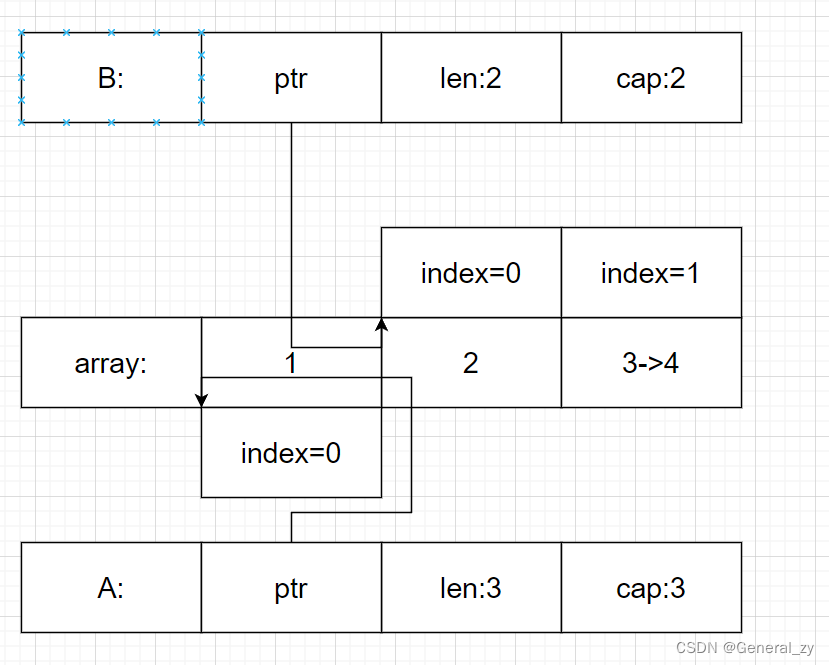
s2 = append(s2, 5, 6, 7)
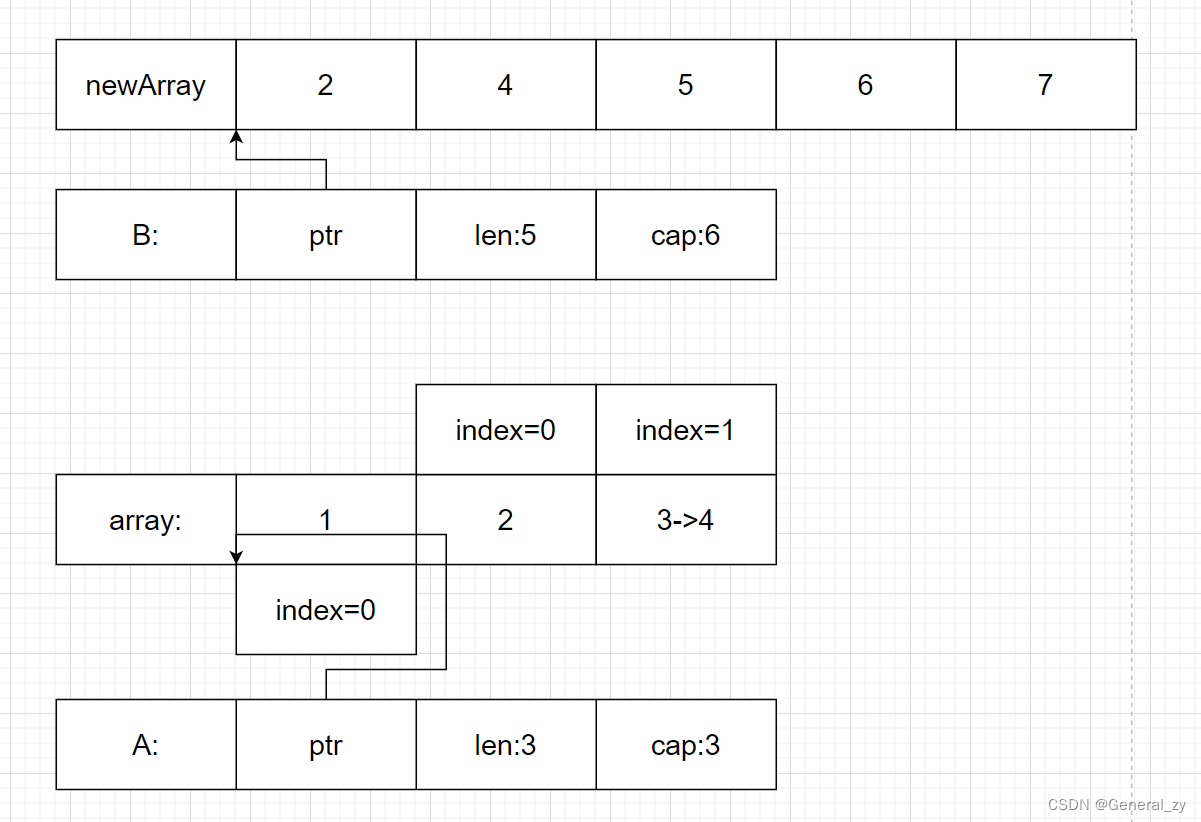
当且仅当动态值和动态类型都为 nil 时,接口类型值才为 nil
下面这段代码输出什么?为什么?
type People interface {
Show()
}
type Student struct{}
func (stu *Student) Show() {
}
func main() {
var s *Student
if s == nil {
fmt.Println("s is nil")
} else {
fmt.Println("s is not nil")
}
var p People = s
if p == nil {
fmt.Println("p is nil")
} else {
fmt.Println("p is not nil")
}
}
答案解析
参考答案及解析:s is nil 和 p is not nil。
- 分配给变量 p 的值明明是 nil,然而 p 却不是 nil。当且仅当动态值和动态类型都为 nil 时,接口类型值才为 nil。上面的代码,给变量 p 赋值之后,p 的动态值是 nil,但是动态类型却是 *Student,是一个 nil 指针,所以相等条件不成立。
String()方法
下面这段代码输出什么?
type Direction int
const (
North Direction = iota
East
South
West
)
func (d Direction) String() string {
return [...]string{"North", "East", "South", "West"}[d]
}
func main() {
fmt.Println(South)
}
答案解析
参考答案及解析:South。
-
根据 iota 的用法推断出 South 的值是 2;
-
如果类型定义了 String() 方法,当使用 fmt.Printf()、fmt.Print() 和 fmt.Println() 会自动使用 String() 方法,实现字符串的打印。
-
println(South)依旧会打印2. -
当改为指针接收者时不会调用String()
func (d *Direction) String() string { return [...]string{"North", "East", "South", "West"}[*d] }
-
原因:当对象是指针时,不用管接收者是指针接收者还是非指针接收者;当对象不是指针时,无法调用指针接收者的方法。
map 的 value 是不可寻址的
下面代码输出什么?
type Math struct {
x, y int
}
var m = map[string]Math{
"foo": Math{2, 3},
}
func main() {
m["foo"].x = 4
fmt.Println(m["foo"].x)
}
答案解析
- 编译报错 cannot assign to struct field m[“foo”].x in map。
- 错误原因:对于类似 X = Y的赋值操作,必须知道 X 的地址,才能够将 Y 的值赋给 X,但 go 中的 map 的 value 本身是不可寻址的。
- 究其原因,因为Go的map是通过散列表来实现的,说得更具体一点,就是通过数组和链表组合实现的。并且Go的map也可以做到动态扩容,当进行扩容之后,map的value那块空间地址就会产生变化,所以无法对map的value进行寻址。
解决方案
-
使用临时变量
type Math struct { x, y int } var m = map[string]Math{ "foo": Math{2, 3}, } func main() { tmp := m["foo"] tmp.x = 4 m["foo"] = tmp fmt.Println(m["foo"].x) } -
修改数据结构
type Math struct { x, y int } var m = map[string]*Math{ "foo": &Math{2, 3}, } func main() { m["foo"].x = 4 fmt.Println(m["foo"].x) fmt.Printf("%#v", m["foo"]) // %#v 格式化输出详细信息 }
一个select死锁问题
以下代码的输出结果:
func main() {
var wg sync.WaitGroup
foo := make(chan int)
bar := make(chan int)
wg.Add(1)
go func() {
defer wg.Done()
select {
case foo <- <-bar:
default:
println("default")
}
}()
wg.Wait()
}
结果

解析
-
对于 select 语句,在进入该语句时,会按源码的顺序对每一个 case 子句进行求值:这个求值只针对发送或接收操作的额外表达式。将代码改为:
func main() { var wg sync.WaitGroup foo := make(chan int) bar := make(chan int) wg.Add(1) go func() { defer wg.Done() select { case val:=<-bar: foo<-val // case foo <- <-bar: default: println("default") } }() wg.Wait() }此时,正常输出:default
-
所以上述语句的理解就是:getVal()、<-input 和 getch() 等类似的操作会执行,导致死锁
package main import ( "fmt" ) func main() { ch := make(chan int) go func() { select { case ch <- getVal(1): fmt.Println("in first case") case ch <- getVal(2): fmt.Println("in second case") default: fmt.Println("default") } }() fmt.Println("The val:", <-ch) } func getVal(i int) int { fmt.Println("getVal, i=", i) return i }无论 select 最终选择了哪个 case,getVal() 都会按照源码顺序执行:getVal(1) 和 getVal(2),必然输出:getVal, i= 1 | getVal, i= 2
相同问题
为什么每次都是输出一半数据,然后死锁?
package main
import (
"fmt"
"time"
)
func talk(msg string, sleep int) <-chan string {
ch := make(chan string)
go func() {
for i := 0; i < 5; i++ {
ch <- fmt.Sprintf("%s %d", msg, i)
time.Sleep(time.Duration(sleep) * time.Millisecond)
}
}()
return ch
}
func fanIn(input1, input2 <-chan string) <-chan string {
ch := make(chan string)
go func() {
for {
select {
case ch <- <-input1:
case ch <- <-input2:
}
}
}()
return ch
}
func main() {
ch := fanIn(talk("A", 10), talk("B", 1000))
for i := 0; i < 10; i++ {
fmt.Printf("%q\n", <-ch)
}
}
- 每次进入以下 select 语句时:<-input1 和 <-input2 都会执行,相应的值是:A x 和 B x(其中 x 是 0-5)。但每次 select 只会选择其中一个 case 执行,所以 <-input1 和 <-input2 的结果,必然有一个被丢弃了,也就是不会被写入 ch 中。因此,一共只会输出 5 次,另外 5 次结果丢掉了。
- 而 main 中循环 10 次,只获得 5 次结果,所以输出 5 次后,报死锁。
更多类似的问题
// ch 是一个 chan int;
// getVal() 返回 int
// input 是 chan int
// getch() 返回 chan int
select {
case ch <- getVal():
case ch <- <-input:
case getch() <- 1:
case <- getch():
}
最典型的问题
有内存泄露(传递给 time.After 的时间参数越大,泄露会越厉害)
PS: 内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
func main() {
ch := make(chan int, 10)
go func() {
var i = 1
for {
i++
ch <- i
}
}()
for {
select {
case x := <- ch:
println(x)
case <- time.After(30 * time.Second):
println(time.Now().Unix())
}
}
}
- 每次执行select都会执行一次time.After(30*time.Second)获取一个chan。
循环中改变切片长度是否会死循环
下面这段代码能否正常结束?
func main() {
v := []int{1, 2, 3}
for i := range v {
v = append(v, i)
}
}
答案解析
参考答案及解析:不会出现死循环,能正常结束。
循环次数在循环开始前就已经确定,循环内改变切片的长度,不影响循环次数。
python会
a = [1, 2, 3]
for i in a:
print(i)
a.append(i)
print(a)

defer再探
下面这段代码输出什么?
func f(n int) (r int) {
defer func() {
r += n
recover()
}()
var f func()
defer f()
f = func() {
r += 2
}
return n + 1
}
func main() {
fmt.Println(f(3))
}
答案解析
参考答案及解析:7。
func f(n int) (r int) {
// 入栈
defer func() {
r += n
recover()
}()
// f为nil
var f func()
// 入栈
defer f()
// f赋值为function
f = func() {
r += 2
}
// r = n+1
// return r
return n + 1
1. r = 3+1 = 4
2. 执行f()即,nil(),引发panic
3. 被异常捕获,执行r+=3 =7
4. return r
}
func main() {
fmt.Println(f(3))
}
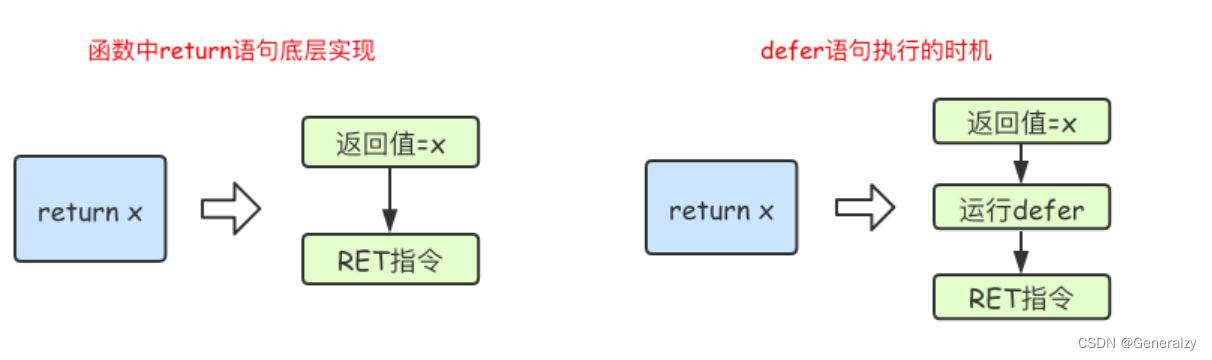
在Go语言的函数中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET指令执行前。具体如下图所示:
range数组和range指针
下面这段代码输出什么?
func main() {
var a = [5]int{1, 2, 3, 4, 5}
var r [5]int
for i, v := range a {
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
fmt.Println("r = ", r)
fmt.Println("a = ", a)
}
答案解析
r = [1 2 3 4 5]
a = [1 12 13 4 5]
range 表达式是副本参与循环,就是说例子中参与循环的是 a 的副本,而不是真正的 a。
如果想要 r 和 a 一样输出,修复办法:
func main() {
var a = [5]int{1, 2, 3, 4, 5}
var r [5]int
for i, v := range &a {
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
fmt.Println("r = ", r)
fmt.Println("a = ", a)
}
使用 *[5]int 作为 range 表达式,其副本依旧是一个指向原数组 a 的指针,因此后续所有循环中均是 &a 指向的原数组亲自参与的,因此 v 能从 &a 指向的原数组中取出 a 修改后的值。
结论
GO中无论做什么都是把原值copy一份,原值是指针就copy指针,原值是值类型就copy值类型。
切片传参和切片扩容
下面这段代码输出什么?
func change(s ...int) {
s = append(s,3)
}
func main() {
slice := make([]int,5,5)
slice[0] = 1
slice[1] = 2
change(slice...)
fmt.Println(slice)
change(slice[0:2]...)
fmt.Println(slice)
}
答案解析
[1 2 0 0 0]
[1 2 3 0 0]
知识点:可变函数、append()操作。
Go 提供的语法糖…,可以将 slice 传进可变函数,不会创建新的切片。第一次调用 change() 时,append() 操作使切片底层数组发生了扩容,原 slice 的底层数组不会改变; 第二次调用change() 函数时,使用了操作符[i,j]获得一个新的切片,假定为 slice1,
它的底层数组和原切片底层数组是重合的,不过 slice1 的长度、容量分别是 2、5,所以在 change() 函数中对 slice1 底层数组的修改会影响到原切片。
range赋值地址
下面这段代码输出结果正确吗?
type Foo struct {
bar string
}
func main() {
s1 := []Foo{
{"A"},
{"B"},
{"C"},
}
s2 := make([]*Foo, len(s1))
for i, value := range s1 {
s2[i] = &value
}
fmt.Println(s1[0], s1[1], s1[2])
fmt.Println(s2[0], s2[1], s2[2])
}
输出:
{A} {B} {C}
&{A} &{B} &{C}
答案解析
参考答案及解析:s2 的输出结果错误。
s2 的输出是 &{C} &{C} &{C},在前面题目我们提到过,for range 使用短变量声明(:=)的形式迭代变量时,变量 i、value 在每次循环体中都会被重用,而不是重新声明。所以 s2 每次填充的都是临时变量 value 的地址,而在最后一次循环中,value 被赋值为{c}。因此,s2 输出的时候显示出了三个 &{c}。
可行的解决办法如下:
for i := range s1 {
s2[i] = &s1[i]
}
同理如下
func main() {
a := []int{1,2,3,4,5}
b:=make([]*int,len(a))
for i,val:=range a{
b[i]=&val // 赋值地址:b[i]是val的地址
}
fmt.Println(a)
fmt.Println(b,*b[0])
}

不是地址赋值可以正常使用:
func main() {
a := []int{1,2,3,4,5}
b:=make([]int,len(a))
for i,val:=range a{
b[i]=val
}
fmt.Println(a)
fmt.Println(b)
}

range map
下面代码里的 counter 的输出值?
func main() {
var m = map[string]int{
"A": 21,
"B": 22,
"C": 23,
}
counter := 0
for k, v := range m {
if counter == 0 {
delete(m, "A")
}
counter++
fmt.Println(k, v)
}
fmt.Println("counter is ", counter)
}
答案解析
for range map 是无序的,如果第一次循环到 A,则输出 3;否则输出 2,并且对m的修改会生效,但不影响循环次数.
多重赋值的坑
下面代码输出正确的是?
func main() {
i := 1
s := []string{"A", "B", "C"}
i, s[i-1] = 2, "Z"
fmt.Printf("s: %v \n", s)
}
答案解析
- 多重赋值分为两个步骤,有先后顺序:
- 计算等号左边的索引表达式和取址表达式,接着计算等号右边的表达式;
- 赋值;
- 所以,会先计算 s[i-1],等号右边是两个表达式是常量,所以赋值运算等同于 i, s[0] = 2, “Z”。
如何判断map是否相等
如何确认两个 map 是否相等?
答案
map 深度相等的条件:
- 都为 nil
- 非空、长度相等,指向同一个 map 实体对象
- 相应的 key 指向的 value “深度”相等
直接将使用 map1 == map2 是错误的。这种写法只能比较 map 是否为 nil。
package main
import "fmt"
func main() {
var m map[string]int
var n map[string]int
fmt.Println(m == nil)
fmt.Println(n == nil)
// 不能通过编译
//fmt.Println(m == n)
}
或者直接利用反射:
package main
import(
"fmt"
"relflect"
)
func main() {
var m map[string]int
var n map[string]int
fmt.Println(reflect.DeepEqual(m,n))
}
DeepEqual部分源码
DeepEqual对于map是否相等也是从以上三点判断的。
case Map:
if v1.IsNil() != v2.IsNil() {
return false
}
if v1.Len() != v2.Len() {
return false
}
if v1.Pointer() == v2.Pointer() {
return true
}
for _, k := range v1.MapKeys() {
val1 := v1.MapIndex(k)
val2 := v2.MapIndex(k)
if !val1.IsValid() || !val2.IsValid() || !deepValueEqual(val1, val2, visited) {
return false
}
}
return true
Go 1.15 中 var i interface{} = a 会有额外堆内存分配吗?
var a int = 3
// 以下有额外内存分配吗?
var i interface{} = a
答案解析
在 Go 中,接口被实现为一对指针:指向有关类型信息的指针和指向值的指针。可以简单的表示为:
type iface struct {
// 类型
tab *itab
// 值
data unsafe.Pointer
}
其中 tab 是指向类型信息的指针;data 是指向值的指针。因此,一般来说接口意味着必须在堆中动态分配该值。
然而,Go 1.15 发行说明在 runtime 部分中提到了一个有趣的改进:
- Converting a small integer value into an interface value no longer causes allocation.
意思是说,将小整数转换为接口值不再需要进行内存分配。小整数是指 0 到 255 之间的数。
基准测试
函数中进行了 100 次 int 到 interface 的转换.
package smallint
func Convert(val int) []interface{} {
var slice = make([]interface{}, 100)
for i := 0; i < 100; i++ {
slice[i] = val
}
return slice
}
---------------------------
package smallint_test
import (
"testing"
"test/smallint"
)
func BenchmarkConvert(b *testing.B) {
for i := 0; i < b.N; i++ {
result := smallint.Convert(12)
_ = result
}
}
- go1.14 和 go1.15
$ go version
go version go1.14.7 darwin/amd64
$ go test -bench . -benchmem ./...
goos: darwin
goarch: amd64
pkg: test/smallint
BenchmarkConvert-8 569830 1966 ns/op 2592 B/op 101 allocs/op
PASS
ok test/smallint 1.647s
$ go version
go version go1.15 darwin/amd64
$ go test -bench . -benchmem ./...
goos: darwin
goarch: amd64
pkg: test/smallint
BenchmarkConvert-8 1859451 655 ns/op 1792 B/op 1 allocs/op
PASS
ok test/smallint 2.178s
- go 1.15,但把12改为256
$ go test -bench . -benchmem ./...
goos: darwin
goarch: amd64
pkg: test/smallint
BenchmarkConvert-8 551546 2049 ns/op 2592 B/op 101 allocs/op
PASS
ok test/smallint 1.502s
证明了上面提到的优化点。
Go 中定义了一个特殊的静态数组,该数组由 256 个整数组成(0 到 255)。当必须分配内存以将整数存储在堆上,并将其转换为接口的一部分时,它首先检查是否它可以只返回指向数组中适当元素的指针。这种经常使用的值的静态分配,是一种很常见的优化手段,例如,Python 对小整数执行类似的操作。
GO结构体字典值拷贝和值引用
以下代码能否编译?
package main
import "fmt"
type Student struct {
Name string
}
var list map[string]Student
func main() {
list = make(map[string]Student)
student := Student{"Aceld"}
list["student"] = student
list["student"].Name = "LDB"
fmt.Println(list["student"])
}
答案解析:
结果
编译失败,cannot assign to struct field list[“student”].Name in map
分析
map[string]Student 的 value 是一个 Student 结构值,所以当list[“student”] = student,是一个值拷贝过程。而list[“student”]则是一个值引用。那么值引用的特点是只读。所以对list[“student”].Name = "LDB"的修改是不允许的。
将 map 的类型的 value 由 Student 值,改成 Student 指针。
实际上每次修改的都是指针所指向的 Student 空间,指针本身是常指针,不能修改,只读属性,但是指向的 Student 是可以随便修改的,而且这里并不需要值拷贝。只是一个指针的赋值。
package main
import "fmt"
type Student struct {
Name string
}
var list map[string]*Student
func main() {
list = make(map[string]*Student)
student := Student{"Aceld"}
list["student"] = &student
list["student"].Name = "LDB"
fmt.Println(list["student"])
}