【自然语言处理(NLP)】基于Bi-DAF的机器阅读理解

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理(NLP)】基于Bi-DAF的机器阅读理解
- 前言
- (一)、任务描述
- (二)、环境配置
- 一、数据准备
- DuReader数据集
- 二、进阶使用
- (一)、任务定义与建模
- (二)、模型原理介绍
- (三)、数据格式说明
- 三、相关代码
- (一)、解压数据集
- (二)、提升模型表现
- (三)、生成词表
- 三、模型训练
- 四、模型评估
- 五、模型预测
- (一)、结果保存
- (二)、模型推断
- 总结
前言
(一)、任务描述
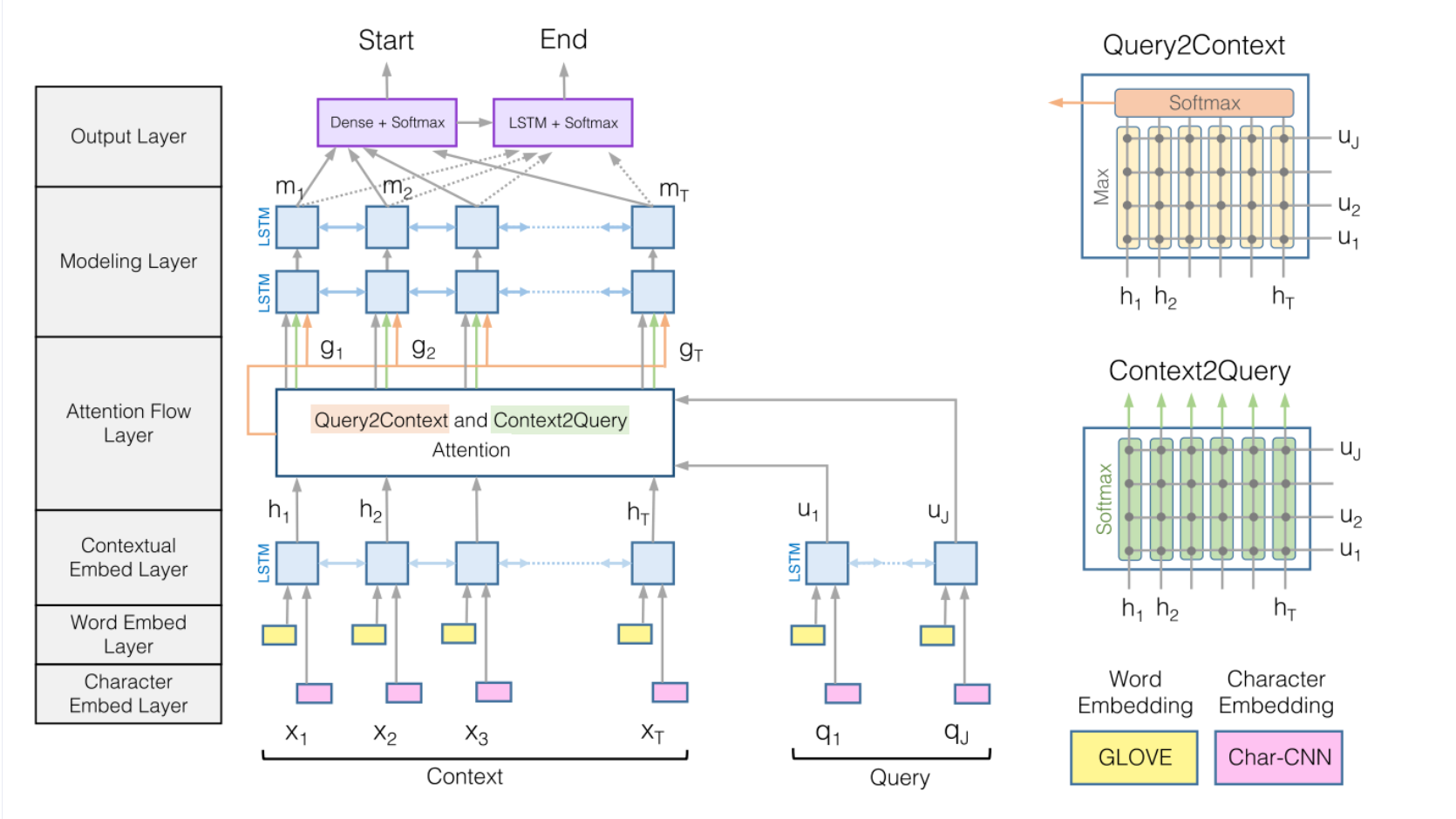
在机器阅读理解(MRC)任务中,我们会给定一个问题(Q)以及一个或多个段落§/文档(D),然后利用机器在给定的段落中寻找正确答案(A),即Q + P or D => A. 机器阅读理解(MRC)是自然语言处理(NLP)中的关键任务之一,需要机器对语言有深刻的理解才能找到正确的答案。本项目基于paddlepaddle,针对DuReader阅读理解数据集数据集实现并升级了一个经典的阅读理解模型——BiDAF模型,该模型的结构图如下所示:
在DuReader数据集上的效果如下表所示:
| Model | Dev ROUGE-L | Test ROUGE-L |
|---|---|---|
| BiDAF (原始论文基线) | 39.29 | 45.90 |
| 本基线系统 | 47.68 | 54.66 |
(二)、环境配置
本示例基于飞桨开源框架2.0版本。
import paddle
import paddle.nn.functional as F
import re
import numpy as np
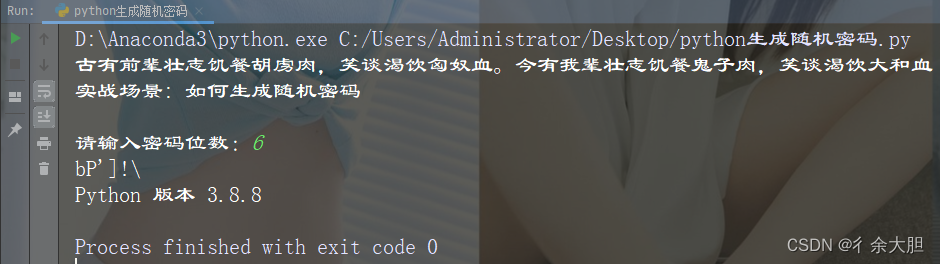
print(paddle.__version__)
# cpu/gpu环境选择,在 paddle.set_device() 输入对应运行设备。
# device = paddle.set_device('gpu')
输出结果如下图1所示:

一、数据准备
DuReader数据集
DuReader是一个大规模、面向真实应用、由人类生成的中文阅读理解数据集。DuReader聚焦于真实世界中的不限定领域的问答任务。相较于其他阅读理解数据集,DuReader的优势包括:
- 问题来自于真实的搜索日志
- 文章内容来自于真实网页
- 答案由人类生成
- 面向真实应用场景
- 标注更加丰富细致
更多关于DuReader数据集的详细信息可在DuReader官网找到
二、进阶使用
(一)、任务定义与建模
阅读理解任务的输入包括:
- 一个问题Q (已分词),例如:[“明天”, “的”, “天气”, “怎么样”, “?”];
- 一个或多个段落P (已分词),例如:[[“今天”, “的”, “天气”, “是”, “多云”, “转”, “晴”, “,”, “温度”, “适中”, “。”], [“明天”, “气温”, “较为”, “寒冷”, “,”, “请”, “注意”, “添加”, “衣物”, “。”]]。
模型输出包括:
- 段落P中每个词是答案起始位置的概率以及答案结束位置的概率 (boundary model),例如:起始概率=[[0.01, 0.02, …], [0.80, 0.10, …]],结束概率=[[0.01, 0.02, …], [0.01, 0.01, …]],其中概率数组的维度和输入分词后的段落维度相同。
模型结构包括:
- 嵌入层 (embedding layer):输入采用one-hot方式表示的词,得到词向量;
- 编码层 (encoding layer):对词向量进行编码,融入上下文信息;
- 匹配层 (matching layer):对问题Q和段落P之间进行匹配;
- 融合层 (fusion layer):融合匹配后的结果;
- 预测层 (output layer):预测得到起始、结束概率。
(二)、模型原理介绍
下图显示了原始的模型结构(如BiDAF模型结构图)。在本基线系统中,我们去掉了char级别的embedding,在预测层中使用了pointer network,并且参考了R-NET中的一些网络结构。
(三)、数据格式说明
DuReader数据集中每个样本都包含若干文档(documents),每个文档又包含若干段落(paragraphs)。有关数据的详细介绍可见官网、论文以及数据集中包含的说明文件,下面是一个来自训练集的样本示例
{
"documents": [
{
"is_selected": true,
"title": "板兰根冲剂_百度百科",
"most_related_para": 11,
"segmented_title": ["板兰根", "冲剂", "_", "百度百科"],
"segmented_paragraphs": [
["板兰根", "冲剂", ",", "药", "名", ":", ... ],
["【", "功效", "与", "主治", "】", ...],
...
],
"paragraphs": [
"板兰根冲剂,药名...",
"【功效与主治】...",
...
],
"bs_rank_pos": 0
},
{
"is_selected": true,
"title": "长期喝板蓝根颗粒有哪些好处和坏处",
"most_related_para": 0,
"segmented_title": ["长期", "喝", "板蓝根", "颗粒", "有", "哪些", "好处", "和", "坏处"],
"segmented_paragraphs": [
["板蓝根", "对", "感冒", "、", "流感","、", ...],
...
],
"paragraphs": [
"板蓝根对感冒、流感、流脑、...",
...
],
"bs_rank_pos": 1
},
...
],
"answer_spans": [[5, 28]],
"fake_answers": ["清热解毒、凉血;用于温热发热、发斑、风热感冒、咽喉肿烂、流行性乙型脑炎、肝炎、腮腺炎。"],
"question": "板蓝根颗粒的功效与作用",
"segmented_answers": [
["清热解毒", "、", "凉血", ";", "用于", "温", "热", "发热", ...],
["板蓝根", "的", "用途", "不仅", "是", "治疗", "感冒", ...],
...
],
"answers": [
"清热解毒、凉血;用于温热发热、发斑、风热感冒、咽喉肿烂、流行性乙型脑炎、肝炎、 腮腺炎 。",
"板蓝根的用途不仅是治疗感冒,板蓝根的功效与作用多,对多种细菌性、病毒性疾病都有较好的预防与治疗作用。",
...
],
"answer_docs": [0],
"segmented_question": ["板蓝根颗粒", "的", "功效", "与", "作用"],
"question_type": "DESCRIPTION",
"question_id": 91161,
"fact_or_opinion": "FACT",
"match_scores": [
0.9583333333333334
]
}
三、相关代码
(一)、解压数据集
# 从work中把代码解压出来,解压数据集
!unzip -qo data/data9722/demo.zip
!mv home/aistudio/data/demo data
!rm -r home
# !tar -zxf data/data9722/dureader_machine_reading-dataset-2.0.0.tar.gz -C data
(二)、提升模型表现
为了提升模型在DuReader2.0数据集上的表现,采用了一种新的段落抽取策略。该段落抽取策略可通过运行以下命令执行:
# 使用demo的话 这里不用执行
!cd src && sh run.sh --para_extraction
!mv extracted/* data/extracted
输出结果如下图1所示:

(三)、生成词表
在模型训练开始之前,需要先运行以下命令来生成词表以及创建一些必要的文件夹,用于存放模型参数等:
!cd src && sh run.sh --prepare
输出结果如下图2所示:

三、模型训练
运行下面的命令,即可开始训练。更多的参数配置可在src/args.py中修改,默认使用data/demo中的数据进行训练
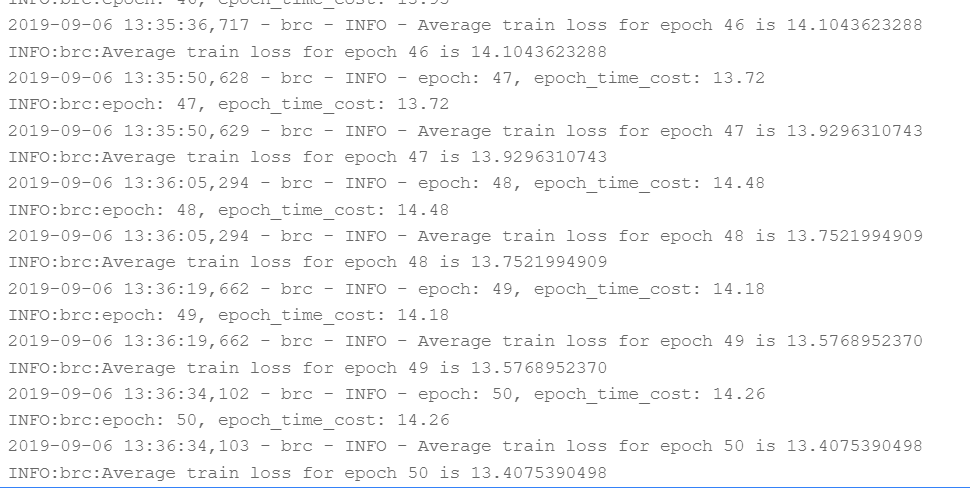
!cd src && sh run.sh --train --pass_num 50
部分输出结果如下图3所示:
四、模型评估
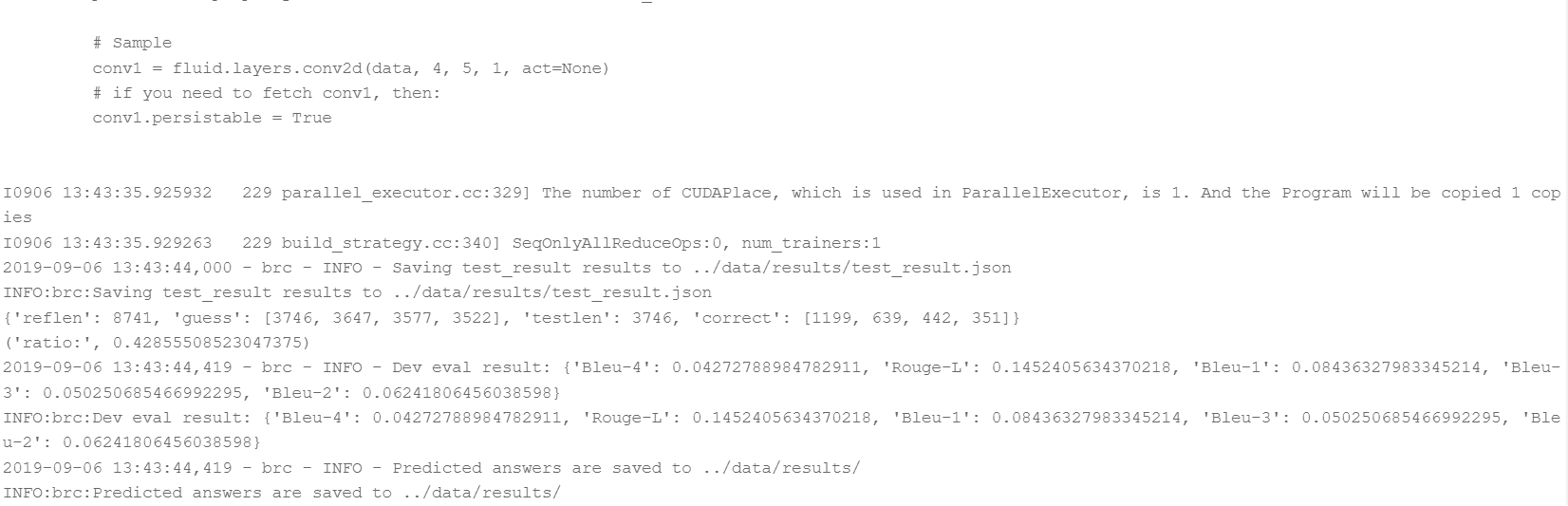
通过运行以下命令,可以利用训练好的模型在验证集进行评估,评估结束后程序会自动计算ROUGE-L指标并显示最终结果。默认使用data/demo中的数据进行评估。
!cd src && sh run.sh --evaluate --load_dir ../data/models/50
输出结果如下图4所示:
五、模型预测
通过运行以下命令,可以利用训练好的模型进行预测,预测结果会保存在data/result/目录下,可以使用文本编辑的模型打开json文件查看预测结果,默认使用data/demo中的数据进行预测
同时predict脚本在预测完成后还会将模型的参数进行固化,如果需要将功能拆分,可以修改run.py文件,将freeze 和predict拆分开
!cd src && sh run.sh --predict --load_dir ../data/models/50
(一)、结果保存
预测的结果以这样的形式保存在文件中,根据question_type 和question_id给出对应的question
{"yesno_answers": [], "entity_answers": [[]], "answers": ["在使用路由器上网时,我们会发现在路由器上,标注得有WAN口(有的路由器是Internet口)和LAN口(有的路由器标注的是1、2、3、4)。很多用户一看就晕了,根本就不知道WAN口与LAN口的区别,自然不知道应该怎么连接了。"], "question_type": "DESCRIPTION", "question_id": 221576}
(二)、模型推断
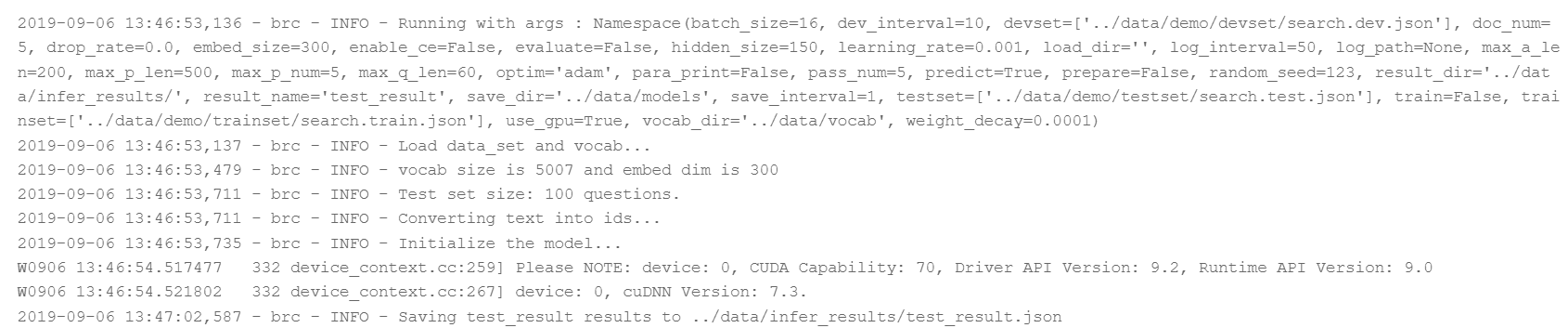
# 使用固化后的模型参数进行推断
!cd src && python infer.py --predict --result_dir ../data/infer_results/
输出结果如下图5所示:
总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~