目录
一、前言
二、数据迁移场景
2.1 整库迁移
2.2 表数据迁移
2.3 mysql版本变更
2.4 mysql数据迁移至其他存储介质
2.5 自建数据到上云环境
2.6 mysql数据到其他国产数据库
三、数据库物理迁移实施方案
3.1 数据库物理迁移概述
3.1.1 物理迁移适用场景
3.1.2 物理迁优缺点
3.2 物理迁移之复制数据文件
3.2.1 数据文件复制概述
3.2.2 在第一个机器创建数据库
3.2.3 将第一个机器上的文件复制进行复制
3.3 物理迁移之工具迁移
3.3.1 删除IP2上的数据库
3.3.2 将IP1上面的数据库导出
3.3.3 将sql文件导入到IP2中
四、数据库逻辑迁移实施方案
4.1 物理迁移的缺点
4.2 逻辑迁移特点
4.2.1 逻辑迁移优缺点
4.2.2 逻辑迁移需要注意的问题
4.3 数据库逻辑备份与恢复
4.3.1 执行数据库备份命令
4.3.2 拷贝sql文件
4.3.3 恢复备份数据
五、使用程序迁移实施方案
5.1 业务案例需求与实现1
5.1.1 使用canal完成数据迁移
5.1.2 canal实现示例代码
5.2 业务案例需求与实现2
5.2.1 flink-cdc实现原理与思路
5.2.2 flink-cdc实现关键代码
六、中间件实现离线数据迁移
6.1 canal实现数据迁移或同步
6.1.1 使用canal实现数据迁移或同步
6.2 datax实现数据迁移
6.2.1 datax简介
6.2.2 datax特点
6.2.3 适用场景
6.2.4 datax实现数据迁移流程
6.2.5 datax数据迁移的模拟配置
七、客户端工具离线数据迁移
7.2.2 迁移配置
7.2.3 选择迁移的表
7.2.4 勾上遇到错误时继续
7.3 kettle
7.3.1 kettle概述
7.3.2 kettle数据迁移使用流程
八、写在文末
一、前言
在生产实践中,你的mysql数据库可能面临下面这些情况:
- 不可抗力的因素,数据库所在服务器被回收,或者服务器磁盘损坏,数据库必须得迁移?
- 单点数据库读写压力越来越大,需要扩展一个或多个节点分摊读写压力?
- 单表数据量太大了,需要进行水平或垂直拆分怎么搞?
- 数据库需要从mysql迁移到其他数据库,比如PG,OB...
以上的这些场景,对于不少同学来讲,或多或少的在所处的业务中可能会涉及到,没有碰到还好,一旦发生了这样的问题,该如何处理呢?本篇将用一定的篇幅结合生产实践经验来详细探讨下。
二、数据迁移场景
通常来说,不同的业务场景对数据迁移的模式和要求也不尽相同,有的需要对整个数据库进行服务器级别的迁移,有的只需要对表的数据进行迁移,还有的可能只是对数据库中的某些表做迁移,这里结合生产实践经验对涉及到的数据迁移几种场景做如下总结。
2.1 整库迁移
需要做整库迁移的引发原因主要有:
- 服务器被回收;
- 磁盘空间不足;
- 磁盘损坏;
- 项目微服务化改造,需要对数据库拆分...
整库迁移常见于数据库部署于物理机,但物理机由于某些特殊的原因可能被回收,或磁盘被损坏,从而该物理机上的数据库需要做整库的迁移;
某些场景下,为了还原生产问题的场景,但是在开发或测试环境无法复现时,也可能涉及到整库数据的迁移,需要将生产的数据往自建的机器上迁移一份。
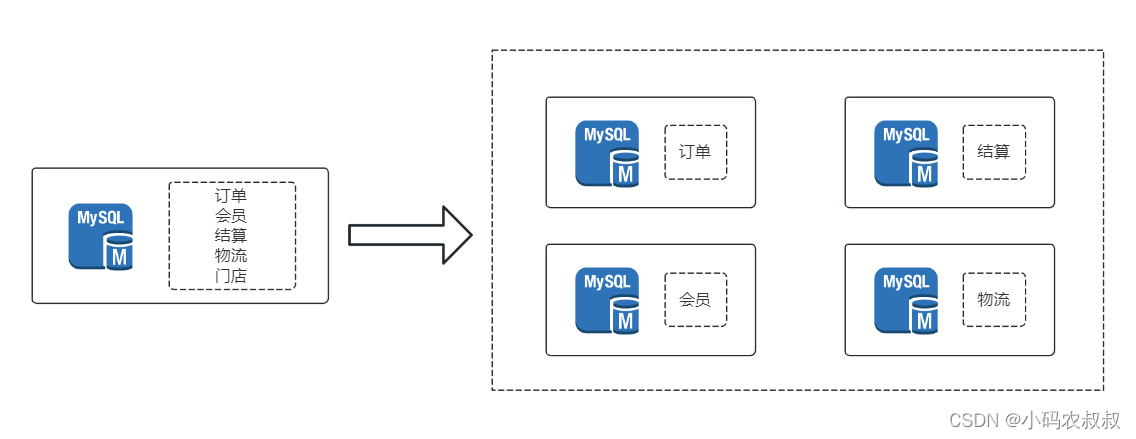
2.2 表数据迁移
不知道你是否遇到过下面的这些场景:
- 生产表结构发生变更,比如新增了字段,但不希望停机更新;
- 某个表的数据量过大,已经成为系统的性能瓶颈,需要对数据表的数据进行水平或垂直拆分;
- 项目发生变更,需要将某库下某表的数据完整迁移到另一个数据库下;
表数据的迁移通常发生在需要对单表数据量进行切分时,这时候,需要借助一定的手段,可能是工具,可能是sql脚本,存储过程,甚至是外部的程序来完成;
2.3 mysql版本变更
在小编过往的经历中,生产环境发生过mysql从5.7升级到8.X的版本,由于不同版本的数据库在字符集编码等方面有不小的差异,直接将低版本的数据作为高版本的来使用,中间经历了不少的曲折,经过一些踩坑之后,总算是踩完,因此,在涉及到mysql或其他关系型数据库升级版本的时候,大概率需要涉及数据的迁移。
2.4 mysql数据迁移至其他存储介质
当产品的架构发生调整,比如调整之前,业务数据存储在mysql等关系型数据库中,调整架构之后,需要对数据进行双写,比如往es、mongo、hbase等其他存储介质,此时,为了能够让新加入的存储介质尽快投入使用,需要将mysql数据与新的存储介质进行对齐,这就是涉及到数据迁移,这是一种实际生产中比较常见的场景。
2.5 自建数据到上云环境
在公有云尚未全面铺开的早些年前,很多公司都自购服务器搭建自己的数据库,或者具有一定规模的企业采用自建机房、自建数据中心,随着公有云的兴起和广泛使用,一旦服务上云,必然面临着自建数据往云上环境的数据迁移工作。
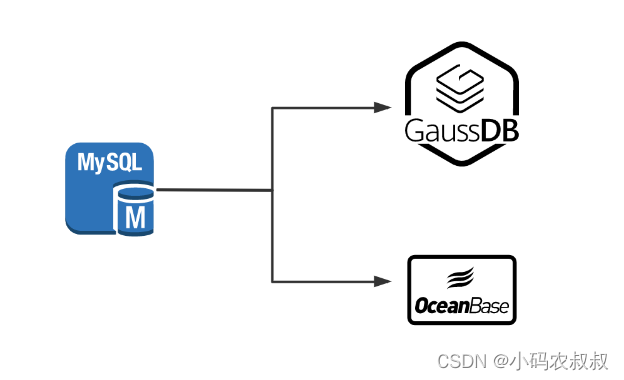
2.6 mysql数据到其他国产数据库
最近这几年,由于外部环境的影响,安全问题被很多互联网公司提升日程引发了关注,国内众多的国产数据库风起云涌,比如GAUSS,达梦等,对于已经投产的系统来说,为了兼容国产化数据库,必然面临将mysql数据往这些国产化数据库迁移的工作。
三、数据库物理迁移实施方案
在上文,比较详细的总结了一些常见的可能发生数据迁移的场景,针对不同的场景,在具体进行数据迁移时应对的策略也不尽相同,行业内也很难有一套通用的一招鲜的方案来解决所有的场景,不过,结合实际生产经验,这里总结一些相对可行的方案和思路提供参考。
3.1 数据库物理迁移概述
物理迁移适用于海量数据整体迁移。可以直接复制原始的数据文件,或者使用navicat客户端工具进行备份迁移。不同的服务器之间采用物理迁移需要将两台服务器中的MySQL server保持完全一样的版本、配置和权限。
这种物理迁移优点是速度快,缺点是要求新服务器与原服务器配置完全一致,即便如此也有可能引起一些未知错误。
3.1.1 物理迁移适用场景
适合大数据量下的整体迁移,比如服务器整机更换进行数据迁移。
3.1.2 物理迁优缺点
优点
迁移速度相对较快,无需考虑数据的细节
缺点
为了确保迁移前后的数据一致性,可能需要停机,不够灵活,未知的错误难以预料
接下来通过案例演示下物理迁移的完整步骤。
3.2 物理迁移之复制数据文件
前置准备
1、两台服务器,分别为IP1,IP2;
2、在两台服务器上分别提前准备好mysql的环境,可以使用docker快速搭建起来;
3.2.1 数据文件复制概述
使用过mysql数据库的同学对mysql的数据存储文件应该不陌生,以5.7为例,对于某个数据库来说,在mysql的数据目录下针对这个数据库会创建出来很多文件目录,比如记录表数据的ibd文件,描述表信息的frm文件等。
所以,理论上来讲,通过复制数据文件的方式实现数据迁移,只需要将数据库的数据目录文件进行完整的拷贝,保持目标机器的mysql数据目录和结构相同即可;
3.2.2 在第一个机器创建数据库
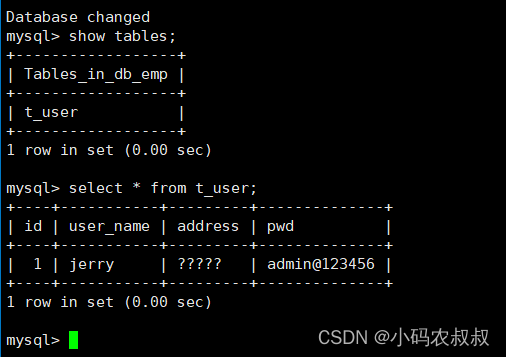
在IP1的机器上创建一个数据库db_emp,并在该数据库下创建一张表t_user,为t_user表插入一条数据;

此时,在mysql的数据目录下,可以看到一个关于该库的数据目录
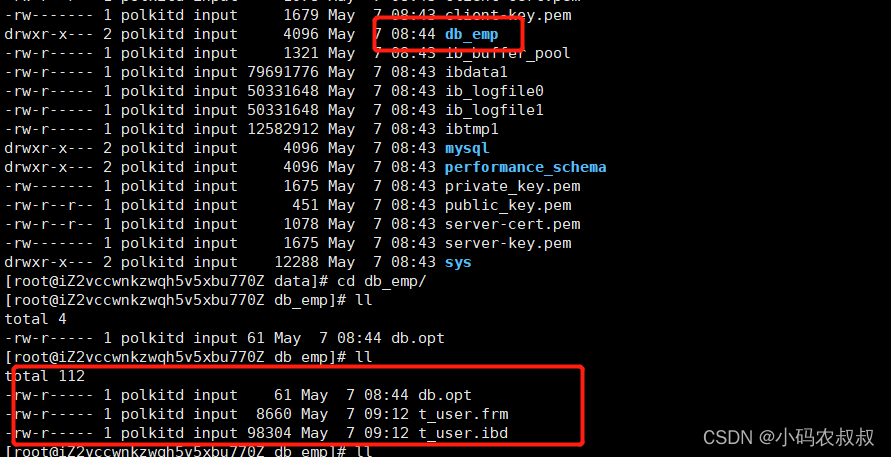
3.2.3 将第一个机器上的文件复制进行复制
需要注意的是,为了尽量减少数据拷贝迁移过程中引起的其他问题,尽量保持两个机器上的mysql版本一致,并且mysql数据目录的位置保持一致,如果是docker搭建的化,将挂载数据的目录设置一致即可;
需要拷贝的文件目录如下(有些同学说不用拷贝mysql目录也可以,我这里试了好像不行)
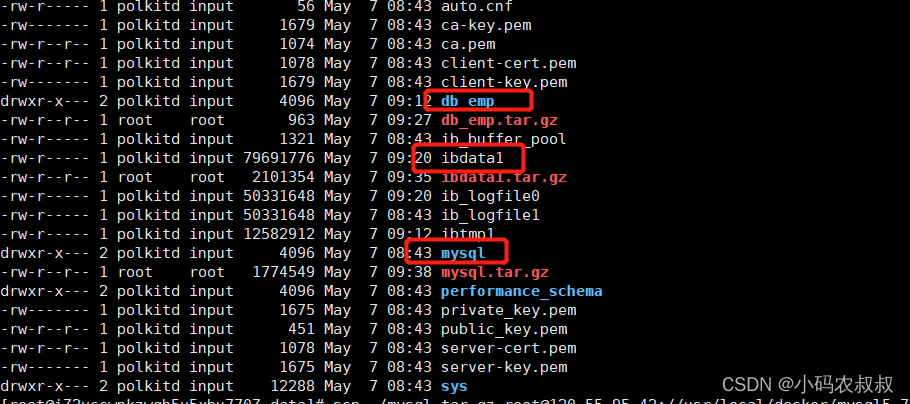
然后将上面的几个目录拷贝到IP2机器相同的位置即可,在拷贝之前,先确保IP目录下并无该文件
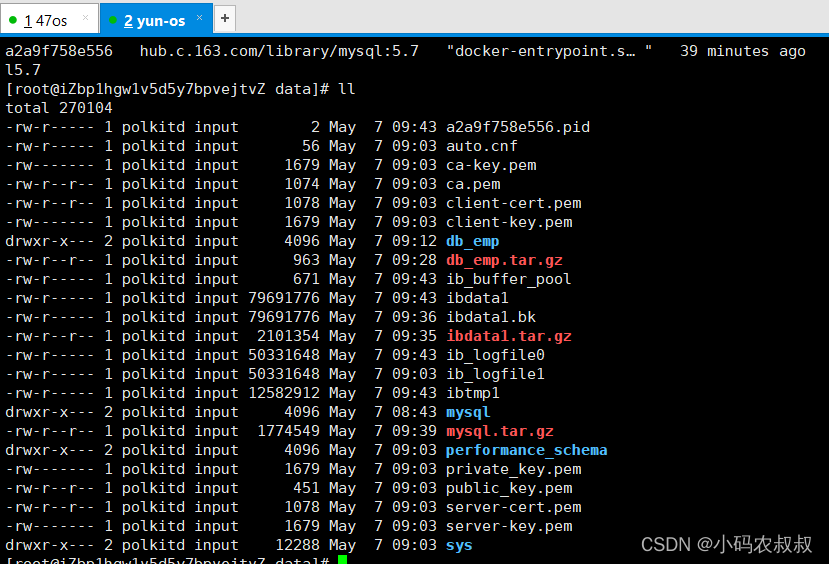
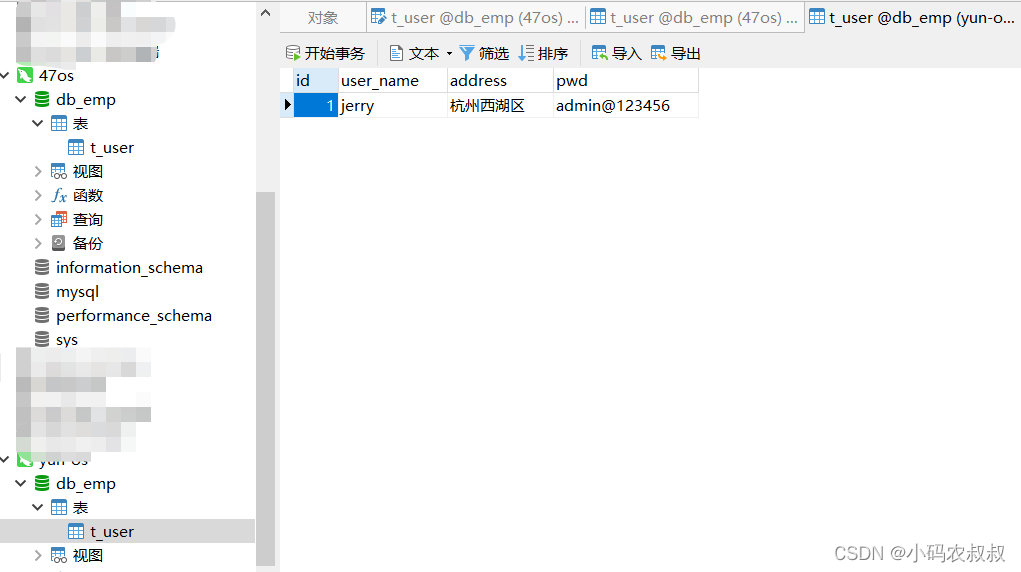
执行数据文件的拷贝,可以使用ftp工具,或者直接scp即可,拷贝完成后进行解压(注意对之前的数据目录进行备份一下)

拷贝完成后,解压该文件,解压完成后,重启一下mysql服务,然后使用客户端连接一下,不出意外的话,可以看到相同的数据库和表数据了;
3.3 物理迁移之工具迁移
从上面的操作来看,直接使用数据目录的复制这种方式在操作的时候过程还是很繁琐的,而且当需要迁移的数据库文件大小很大的时候,这个过程可能会很长,另外在数据传输的过程中也容易受到网络等外部环境因素的影响,当然,如果在生产实践中,如果允许使用客户端工具的话,可以考虑使用客户端工具配合进行整库数据的迁移。仍然以上面的数据库为例进行说明,下面来看具体的操作流程。
3.3.1 删除IP2上的数据库
为了保证演示效果,先把IP2上面的数据库删掉

3.3.2 将IP1上面的数据库导出
使用navicat工具连接IP1的mysql服务,并将db_emp的数据库导出为sql文件
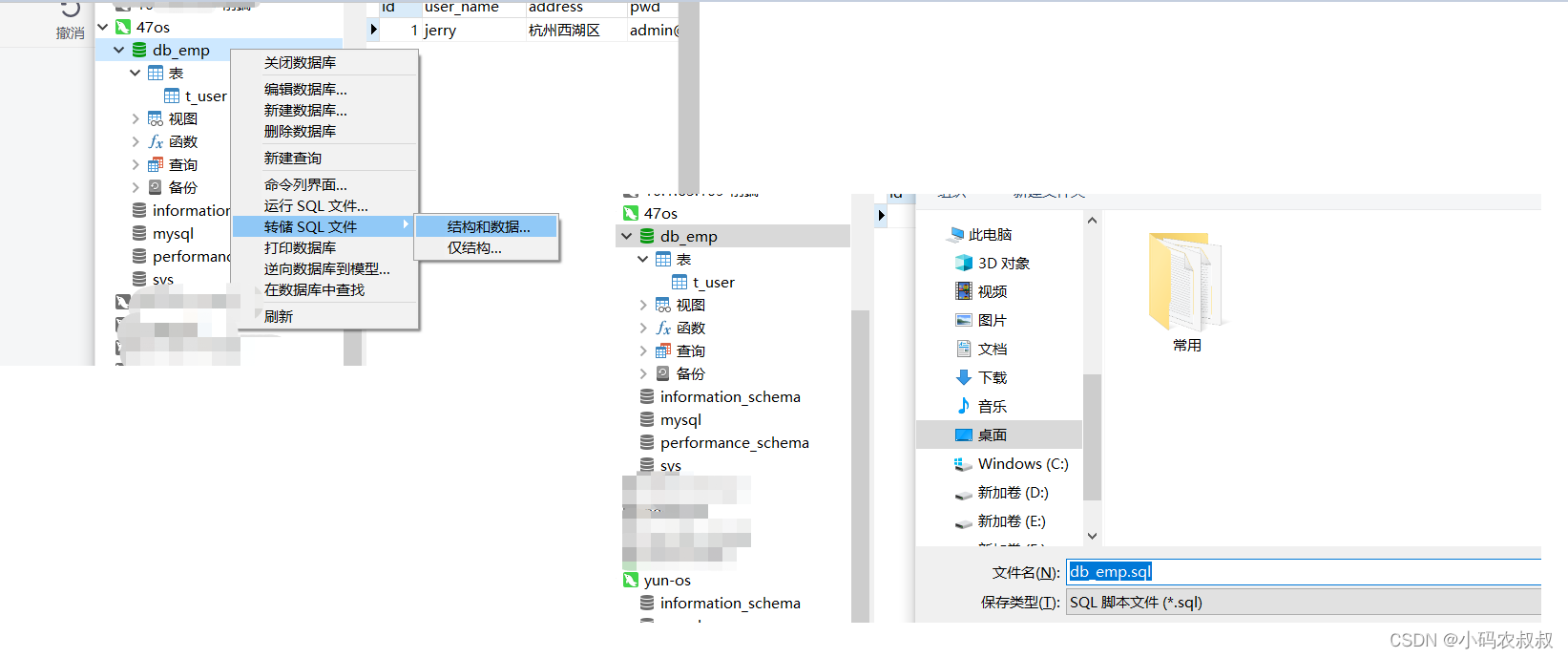
由于数据量较小,导出很快
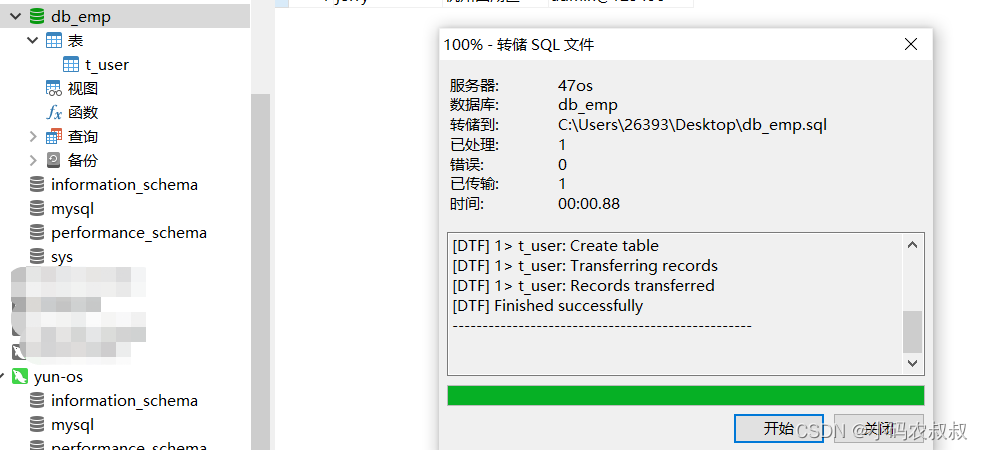
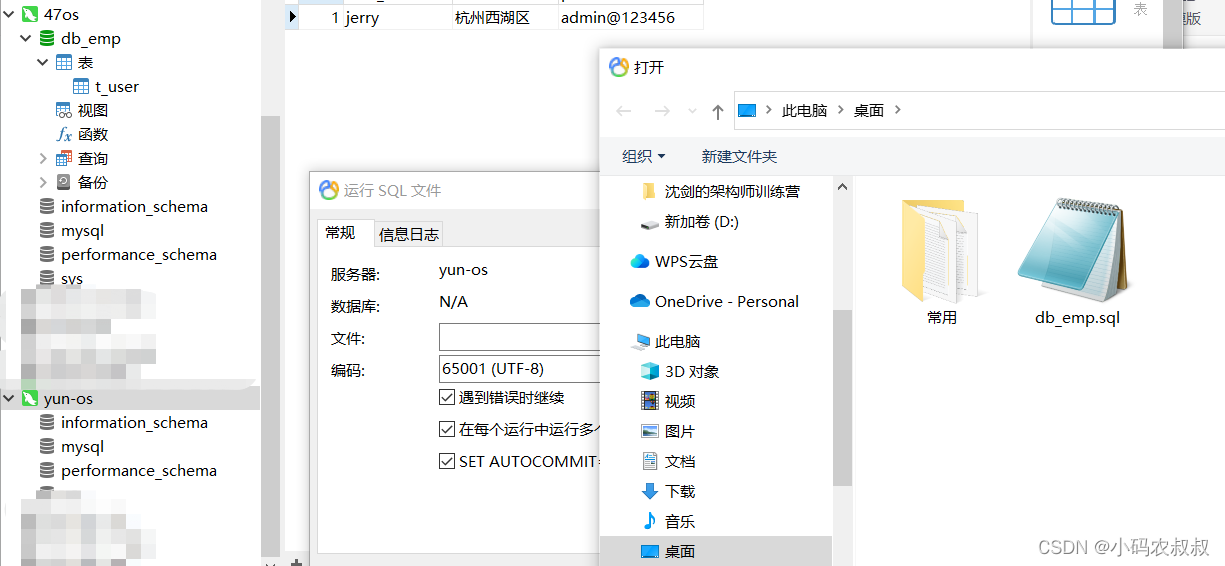
3.3.3 将sql文件导入到IP2中
运行sql文件,将上面导出的sql通过navicat导入即可,这个操作想必平时也有不少同学是这么操作的,就不再过多赘述了;
四、数据库逻辑迁移实施方案
物理迁移尽管看似简单粗暴,事实上在生产实践中,尤其是那些微服务众多,数据库规模庞大的环境,物理迁移并不是一种常用的方案,为什么这么说呢?
4.1 物理迁移的缺点
不够灵活
为了确保迁移前后数据的一致性,可能需要将线上运行的服务进行停机再迁移,这就不够灵活了
数据太大
实际生产环境中,数据库的文件大小小则上G,动则上T,这种跨机器的拷贝速度以及对于网络的要求是难以想象的。
备份麻烦
对之前的数据文件进行备份的话,需要占用较大的磁盘存储空间,文件众多并且文件量太大的话,备份起来需要耗费很多时间
环境难以保证一致
事实上,上述所说的确保数据复制前后不同机器的数据目录等环境保证一致这是很难做到的,现实中经常因为服务器环境因素带来了很多不可控的困难,这也是很多开发工程师和运维工程师头疼的地方
实际操作中,更多难以预知的因素就造成了使用物理迁移的方式并不是一种首选的数据迁移方案,因此在大多情况下,DBA或者运维实施人员更倾向于逻辑迁移。
仍然以上面的db_emp为例进行说明,下面来看具体的操作步骤。
4.2 逻辑迁移特点
相较于物理迁移来说,数据库的逻辑迁移优势更明显,可以适用于各种场景,具体来说:
4.2.1 逻辑迁移优缺点
优点
兼容性高,灵活方便,可以跨版本,文件传输相对较小
缺点
迁移时间可能很长,逻辑迁移的原理是根据 MySQL 数据库中的数据和表结构转换成 SQL 文件,如果备份的sql文件特别大,这个解析和转换的过程就会耗时很长
4.2.2 逻辑迁移需要注意的问题
1、排查不需要迁移的库或数据表;
2、对于大表单独做处理;
3、迁移完成后第一时间对数据进行验证
4.3 数据库逻辑备份与恢复
关于mysql的数据库数据表的逻辑备份这里不再展开详述,非本文的重点,有兴趣的同学可以参考这篇文章:mysql数据备份与恢复,简单来说,逻辑备份的核心是利用mysqldump 的命令对数据库数据表进行备份,基于这个文件进行数据的恢复,或者迁移等工作。
4.3.1 执行数据库备份命令
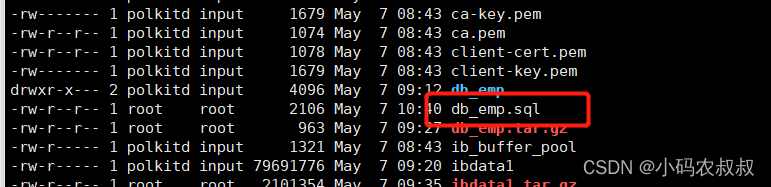
执行下面的数据库备份命令对db_emp数据库进行备份
mysqldump -uroot -p你的密码 --databases db_emp > /var/lib/mysql/db_emp.sql
执行完成后,可以看到在当前目录下导出了一个sql文件;
4.3.2 拷贝sql文件
将上述备份出来的数据库文件拷贝到第二台机器相同的目录下
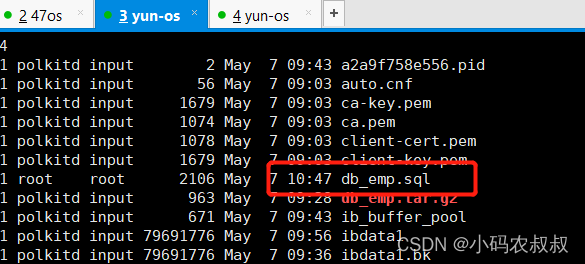
4.3.3 恢复备份数据
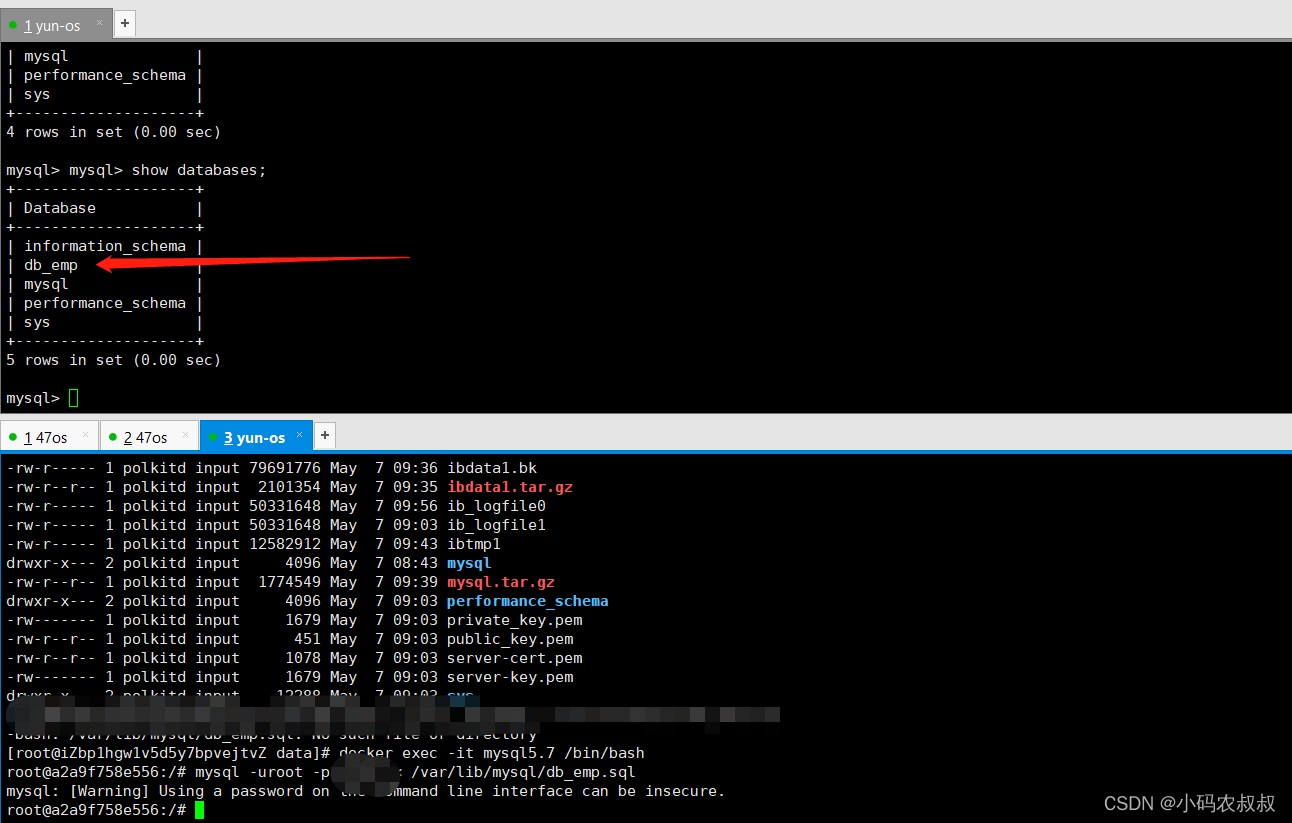
登录IP2的mysql服务,并删除之前的db_emp数据库

执行如下的命令进行数据恢复
mysql -uroot -你的密码 < /var/lib/mysql/db_emp.sql
执行完成后,再次查看IP2的mysql,可以看到数据已经完成了迁移;
五、使用程序迁移实施方案
在实际业务中,可能存在如下这些场景(来源于真实的业务需求):
- 项目现场并无专业的实施人员或对数据库很熟悉的人员;
- 数据库中的某些业务表可能会不定期的发生字段的增减;
- 异地高可用需要做数据的备份,增量或全量备份;
- 只需备份部分表的特定变更事件的数据,比如增删改数据;
- 需要对部分表数据进行异构合成新表给其他的业务使用...
总结来说,类似上面的这些场景的一个特点就是,需要迁移的数据场景具有一定的特殊性,或者说个性化的场景下,这种情况下,就很难通过某种固定的方法来处理,而通过程序的方式来解决是个不错的选择。
具体到实践时,该怎么实施呢?下面结合几种比较常见的场景,列举几种常用的处理方案。
5.1 业务案例需求与实现1
某应用A数据库下有一张表,现在需要将A表数据的部分字段数据保存到另一个库下,同时统计汇聚某个指标的结果给应用B进行大屏展示使用
需求分析
通过上面的需求描述,可以提炼如下关键点:
- 操作的是数据库中某一张具体的表;
- 需要迁移的是表中的部分数据;
- 需要对现有表数据进行统计计算;
结合上面的原始需要以及对需求的分析,这种需求直接通过sql的迁移很难达到目的,下面列举几种常用的实现方案:
- 通过mysql的存储过程;
- 通过逻辑迁移,迁移完成后,再手工修正、计算、填充计算结果;
- 通过程序去完成;
很明显,第一二两种方式的实现不够灵活,同时可能会涉及到停机操作,可以考虑使用一个中间程序来完成这件事。这里推荐阿里开源中间件canal来实现。
5.1.1 使用canal完成数据迁移
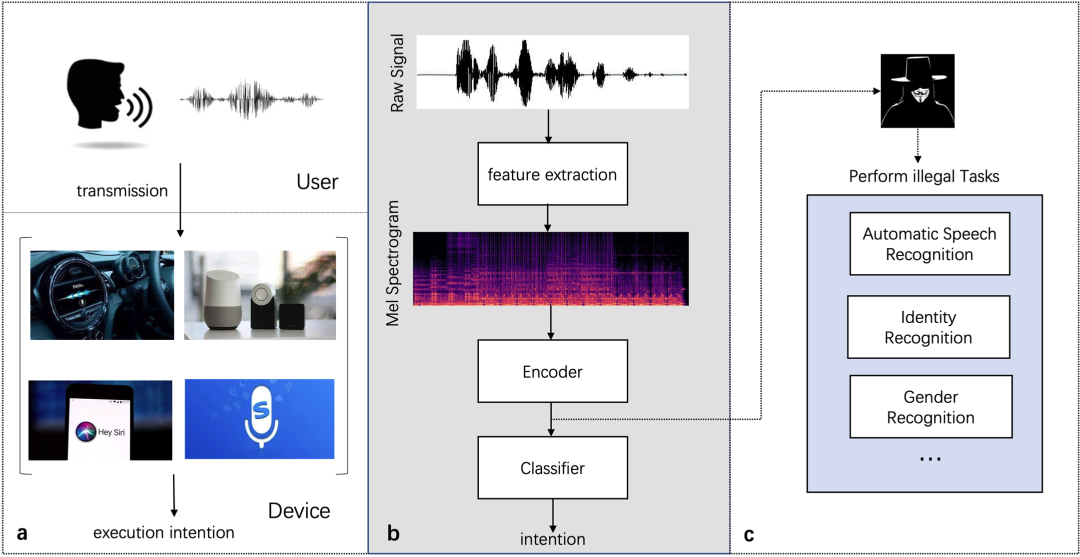
canal是阿里开源的一款mysql数据库同步的工具,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。canal git地址
canal实现原理如下图所示
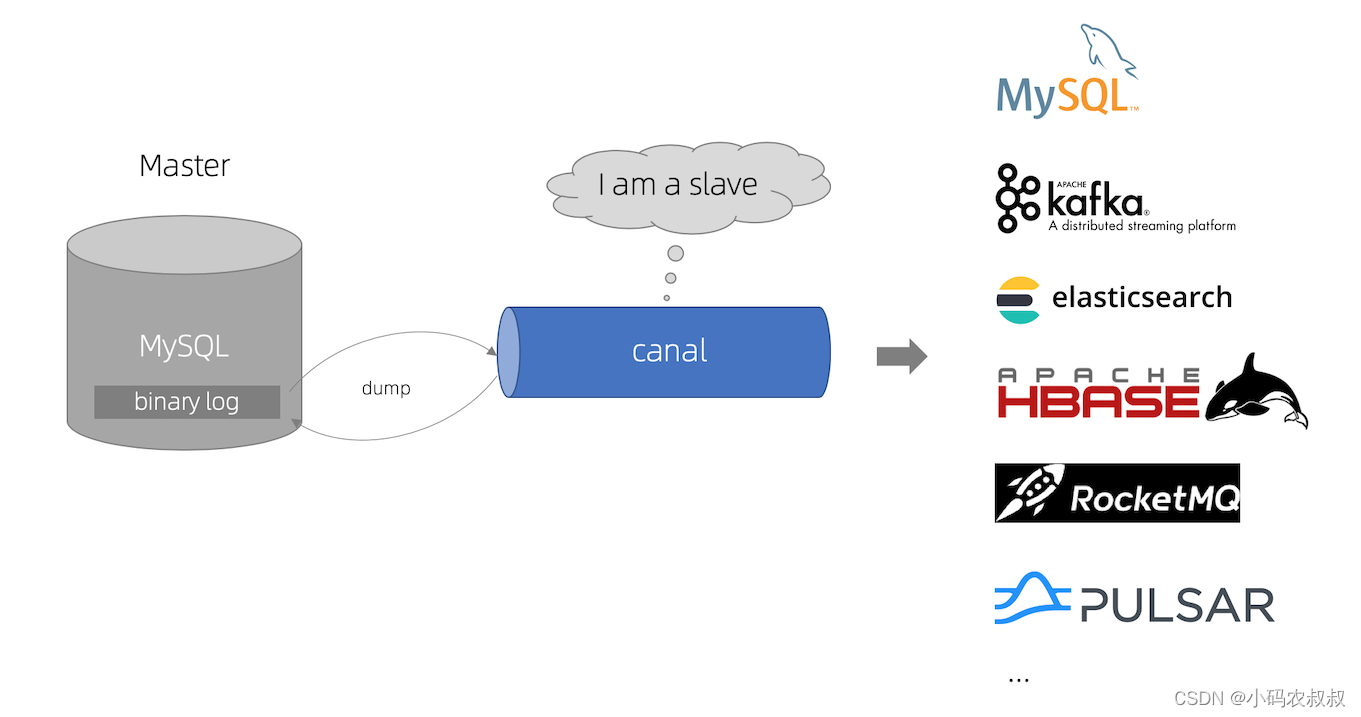
那么具体到应用程序来说,canal怎么实现上述的需求呢?其实可以简单理解为,使用canal之后,canal相当于是一个可以监听目标数据表各种事件变化的监听器,当监听到不同的数据变更事件之后,就可以对变化的日志进行解析处理,canal可以直接在服务器安装、部署、进行简单的配置、使用,也提供了程序的客户端SDK,基于SDK,就可以成为上述业务实现的切入点。
映射到上面的需求,完整的实现思路如下:
- 提前配置好服务端canal;
- 客户端引入canal的SDK;
- 应用程序监听指定的数据变化事件,并将数据写入新表;;
- 应用程序统计汇聚结果到新表(这一步也可以放到其他地方去做);

5.1.2 canal实现示例代码
中间程序示例代码(完整的实现可以参考官方demo案例)
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalClient {
public static void main(String[] args) throws Exception{
//1.获取 canal 连接对象
CanalConnector canalConnector =
CanalConnectors.newSingleConnector(new
InetSocketAddress("canal所在服务器IP", 11111), "example", "", "");
System.out.println("canal启动并开始监听数据 ...... ");
while (true){
canalConnector.connect();
//订阅表
canalConnector.subscribe("shop001.*");
//获取数据
Message message = canalConnector.get(100);
//解析message
List<CanalEntry.Entry> entries = message.getEntries();
if(entries.size() <=0){
System.out.println("未检测到数据");
Thread.sleep(1000);
}
for(CanalEntry.Entry entry : entries){
//1、获取表名
String tableName = entry.getHeader().getTableName();
//2、获取类型
CanalEntry.EntryType entryType = entry.getEntryType();
//3、获取序列化后的数据
ByteString storeValue = entry.getStoreValue();
//判断是否rowdata类型数据
if(CanalEntry.EntryType.ROWDATA.equals(entryType)){
//对第三步中的数据进行解析
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
//获取当前事件的操作类型
CanalEntry.EventType eventType = rowChange.getEventType();
//获取数据集
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
//便利数据
for(CanalEntry.RowData rowData : rowDatasList){
//数据变更之前的内容
JSONObject beforeData = new JSONObject();
List<CanalEntry.Column> beforeColumnsList = rowData.getAfterColumnsList();
for(CanalEntry.Column column : beforeColumnsList){
beforeData.put(column.getName(),column.getValue());
}
//数据变更之后的内容
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
JSONObject afterData = new JSONObject();
for(CanalEntry.Column column : afterColumnsList){
afterData.put(column.getName(),column.getValue());
}
System.out.println("Table :" + tableName +
",eventType :" + eventType +
",beforeData :" + beforeData +
",afterData : " + afterData);
}
}else {
System.out.println("当前操作类型为:" + entryType);
}
}
}
}
}
5.2 业务案例需求与实现2
需求描述
业务系统经常会遇到需要更新某个表的数据到多个存储的需求,即上述的需求的升级,比如mysql中某个表数据变化后,需要同步更新到另一个数据库下,还要同步更新到es,redis,mongo等存储
在这样的需求场景下,有一种更好的选择,那就是flink-cdc的实现。
5.2.1 flink-cdc实现原理与思路
下图为官网给出的一张关于flink cdc实现的业务流程图,不难理解这个与canal的实现原理很相似的
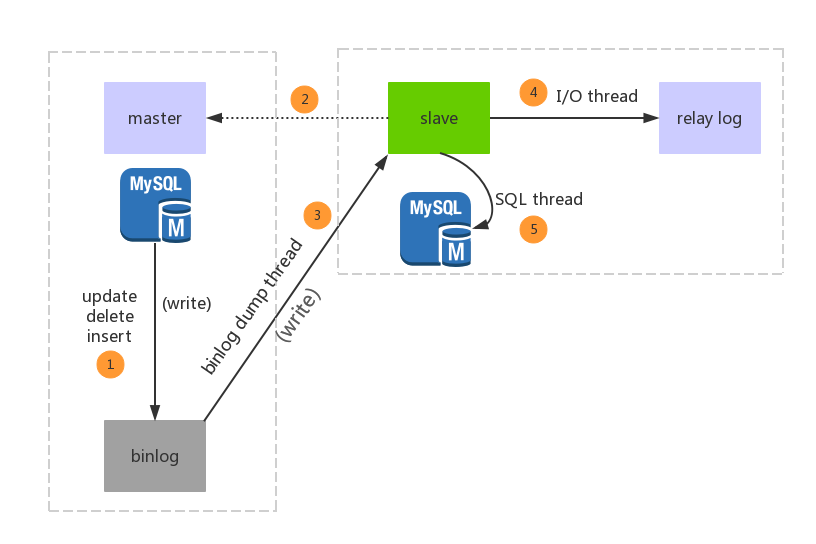
如果使用flink cdc来实现该需求,大致可以按照下面的思路来做
1、mysql配置binlog;
2、程序引入SDK依赖;
3、编写程序,监听目标表数据变化事件,写数据到目标表;
5.2.2 flink-cdc实现关键代码
下面给出使用flink-cdc实现的示例代码,有兴趣的同学可以深入研究学习一下
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class CdcTest2 {
public static void main(String[] args) throws Exception{
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建 Flink-MySQL-CDC 的 Source
tableEnv.executeSql("CREATE TABLE user_info1 (" +
" id STRING NOT NULL," +
" name STRING NOT NULL," +
" version INTEGER NOT NULL" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'IP'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = 'root'," +
" 'database-name' = 'bank1'," +
" 'table-name' = 'record'" +
")");
//tableEnv.executeSql("select * from user_info1").print();
Table table = tableEnv.sqlQuery("select * from user_info1");
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
//结果打印输出
retractStream.print();
env.execute("flinkCdcSql");
}
}
六、中间件实现离线数据迁移
随着数据迁移的需求增多,市面上也出现了一些比较好用开源中间件用于帮助完成数据库数据表的迁移工作,下面列举几种比较常用而且也比较稳定的用于做数据同步的中间件。
6.1 canal实现数据迁移或同步
在上文中,简单介绍了canal的作用以及结合程序完成数据同步的过程,事实上,canal的功能还是很强大的,可以做数据同步,也可以将mysql的数据导入到其他存储中,甚至配合应用程序,完成一些复杂的特殊的场景实现。
6.1.1 使用canal实现数据迁移或同步
一般来说,使用canal实现数据迁移或同步可参考下面的步骤
1、安装canal服务端;
2、添加配置文件,配置源数据库,数据表地址,配置目标数据库、数据表地址;
3、基于第二步,可以进行更细粒度的设置,比如只同步表的特定事件的变化数据,可以根据需求设置增量或全量同步;
4、配置文件完成后,启动服务;
5、如果直接通过配置的方式还不能解决,可以配合应用程序编码完成更复杂的操作;
6.2 datax实现数据迁移
6.2.1 datax简介
DataX 是阿里内部广泛使用的离线数据同步工具/平台,可以实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能,DataX采用了框架 + 插件 的模式,目前已开源,代码托管在github,datax git地址
6.2.2 datax特点
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
6.2.3 适用场景
通常是在服务暂停的情况下,短时间将一份数据从一个数据库迁移至其他数据库,或其他不同类型的数据库下
6.2.4 datax实现数据迁移流程
使用datax实现数据迁移的一般过程大致如下:
1、下载安装包并解压;
2、编写配置文件,配置待同步的原始数据库、表、连接等信息;
3、配置目标库的信息,数据库、表等;
4、datax无需源表与目标表名称一致,甚至字段也无需完全一致,只要数据类型对的上即可;
5、对配置文件执行命令,完成数据的离线迁移;
6.2.5 datax数据迁移的模拟配置
下面是一个使用datax进行数据迁移的配置信息,更详细的可以参阅官方提供的资料;
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"connection": [
{
"table": [
"user_info" #表名
],
"jdbcUrl": [
"jdbc:mysql://IP1:3306/shop001" #源地址
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true, #开启任务运行过程中的打印
"column": [
"id","name" #待同步的字段
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://IP2:3306/shop001", #目标地址
"table": ["user_info_copy"] #目标表
}
],
"password": "root",
"username": "root"
}
}
}
]
}
}
七、客户端工具离线数据迁移
在日常工作中,面对实时性要求不高,数据量不算特别大的场景,也可以借助一些客户端工具完成数据的迁移工作,下面介绍几种常用的客户端工具协助完成数据迁移工作。
7.1 navicat
navicat 这款客户端工具相信大家都不陌生,日常开发、运维过程中都会接触到,这款客户端工具不仅可以满足日常对mysql,PG,OB等众多数据库的连接使用,还可以协助完成一些常规的数据迁移工作。比如,通过navicat客户端可以轻松的完成将mysql数据库迁移到postgresql的过程,下面来看看具体的操作步骤。
7.2 navicat迁移mysql数据到postgresql
7.2.1 前置准备
迁移数据前需要新建MySQL、PostgreSQL连接,并确认连接账号有迁移库所有权限
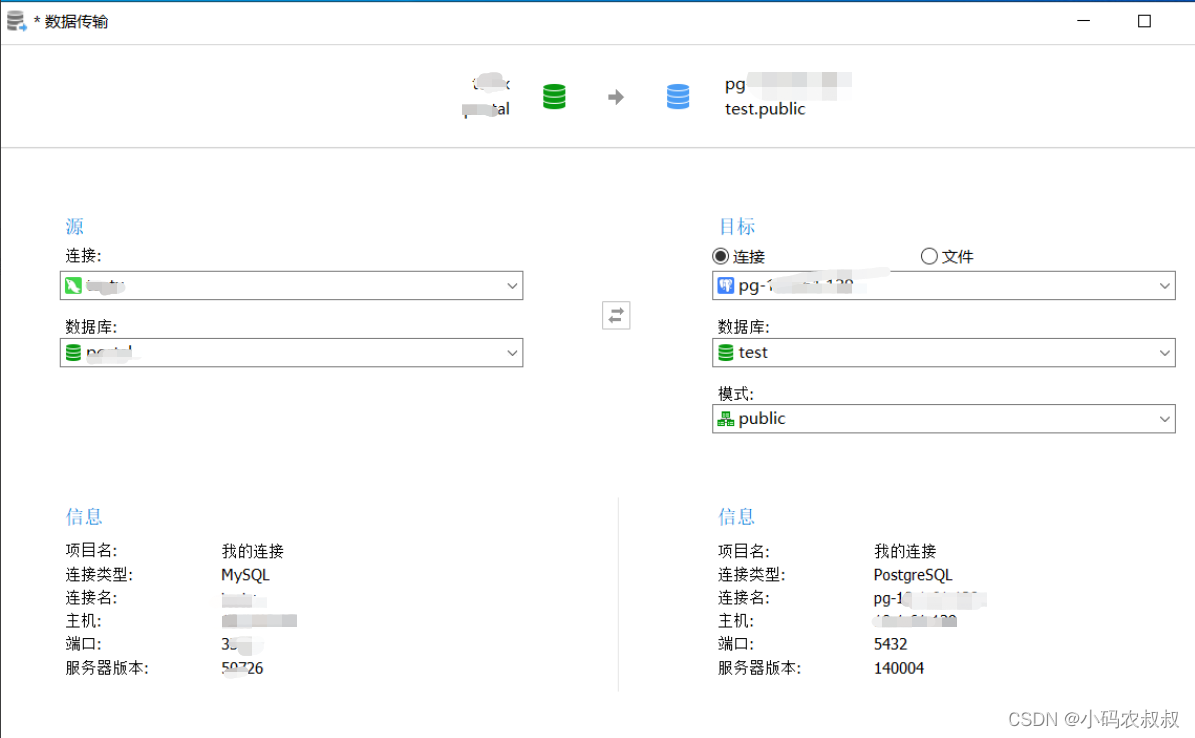
7.2.2 迁移配置
点击菜单工具>>传输,弹出如下窗口,选择源MySQL, 目标PostgreSQL数据库
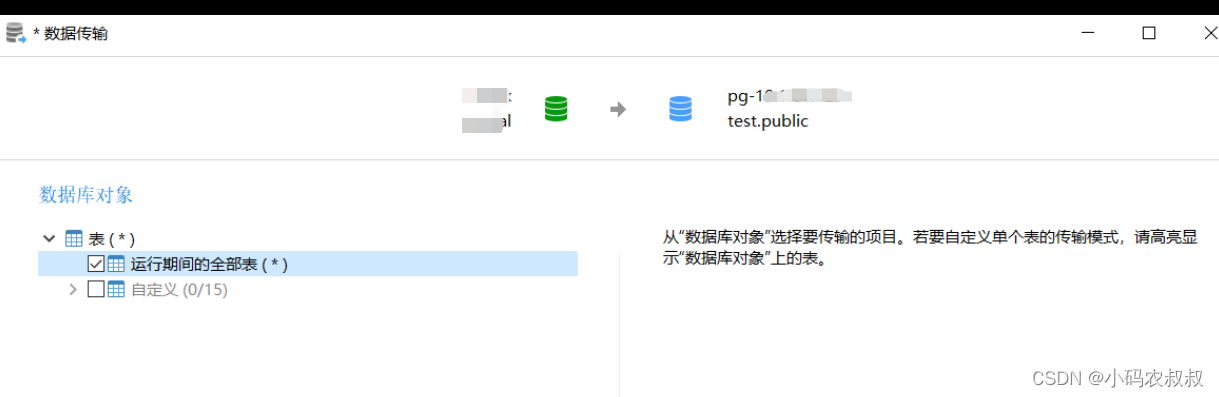
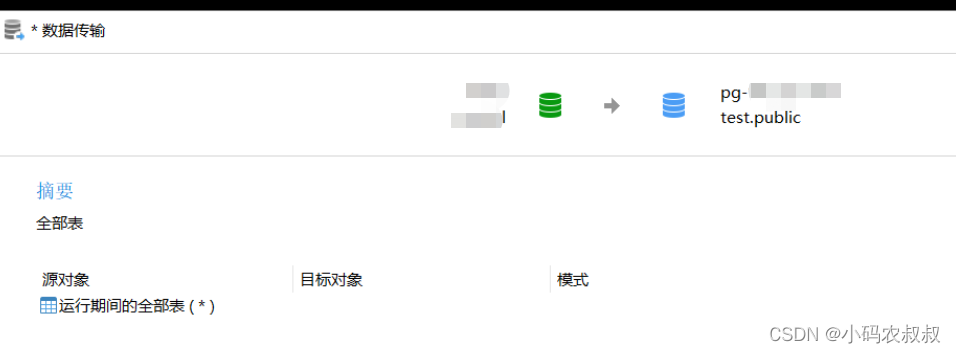
7.2.3 选择迁移的表
选择数据库下全部的表
7.2.4 勾上遇到错误时继续
原因是MySQL里的索引是表内唯一的, 但PostgreSQL里的索引名是全局唯一, 如果在同步时遇到相关的错误, 后面提供SQL补充
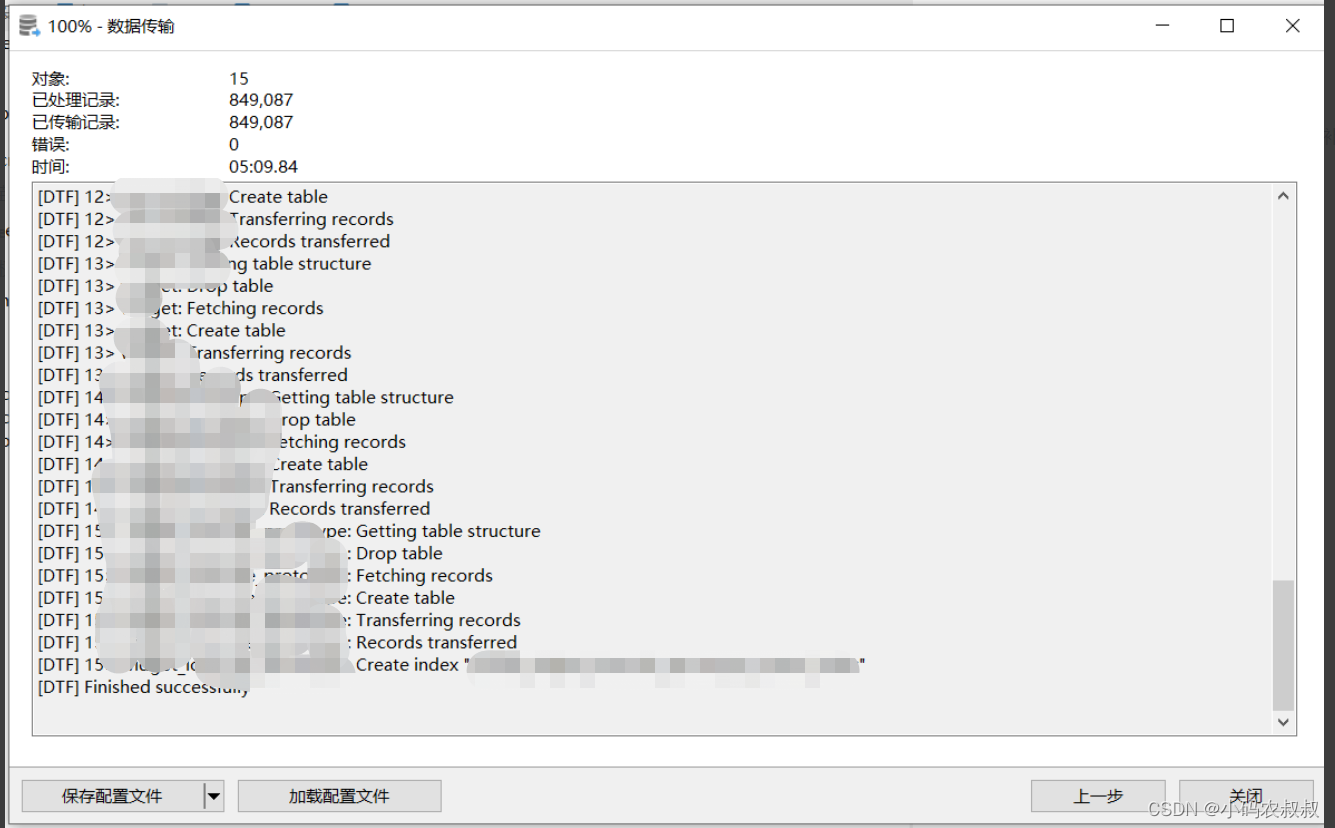
按照上面的操作步骤,就可以完成数据从mysql到pg的迁移了。
7.3 kettle
7.3.1 kettle概述
Kettle 中文名称叫水壶,该项目的主程序员希望把各种数据放到一个壶里,然后以一种指定的格式流出,Kettle是用来做数据迁移的,也就是将一个数据库中的数据全部导入另一个数据库。
Kettle是一款国外开源的ETL工具,纯Java编写,绿色无需安装,数据抽取高效稳定 (数据迁移工具)。
7.3.2 kettle数据迁移使用流程
kettle在大数据ETL中使用比较广泛,打开之后,可以通过界面类似于navicat的客户端,直接通过客户端进行各种操作配置即可完成,大致的思路和上面的navicat差不多。
kettle不仅可以作为mysql数据库之间的数据离线迁移,还可以实现不同类型数据库之间的迁移,比如mysql到mogo等。
八、写在文末
本文通过较大的篇幅详细总结了mysql数据迁移或同步的常用处理方案,事实上生产环境的情况远比这些复杂,比如mysql主从模式下需要扩展新的从节点等,这里提供一些相对通用的解决思路以供后面的工作中遇到类似的场景时可以进行查阅。本篇到此结束,感谢观看。