一条SQL在MySQL中是如何执行的
- 1. 示例表
- `举一个大家不容易理解的综合例子`
本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。
本节课内容:
- 索引下推优化详解
- Mysql优化器索引选择探究
- 索引优化Order by与Group by
- Using filesort文件排序详解
- 索引设计原则与实战
1. 示例表
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
-- 插入一些示例数据
drop procedure if exists insert_emp;
delimiter ;;
create procedure insert_emp()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into employees(name,age,position) values(CONCAT('zhuge',i),i,'dev');
set i=i+1;
end while;
end;;
delimiter ;
call insert_emp();
举一个大家不容易理解的综合例子
上上一个博客我们学了key_len的计算方法,https://blog.csdn.net/Ding_JunXia/article/details/130496580
如下:

- 第一个
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei';

- 第二个
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' AND age = 22;

- 第三个
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' AND age = 22 AND position ='manager';

4. 第四个
EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';

- 第五个
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' AND age = 22 AND position >'manager';

比较:如果三个字段的索引都走的话就是140个字节。为什么5就能走完3个字段的索引呢?为什么4的第一个字段是范围就一个索引都不走了呢?
Mysql一般认为联合索引如果第一个字段就用范围的话意味着这个结果集应该会很大,这个结果集很大意味着要回表,并且回表的次数比较多,他会认为使用全表扫描的可能会更快一点。其实他的底层也是有一些计算依据的。
============================================================================================
============================================================================================
我们在上上一个博客中写了很多原则,只能说大部分情况下是这样的.
1、联合索引第一个字段用范围不会走索引
EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';
结论:联合索引第一个字段就用范围查找不会走索引,mysql内部可能觉得第一个字段就用范围,结果集应该很大,回表效率不高,还不如就全表扫描
2、强制走索引
EXPLAIN SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' AND age = 22 AND position ='manager';

结论:虽然使用了强制走索引让联合索引第一个字段范围查找也走索引,扫描的行rows看上去也少了点,但是最终查找效率不一定比全表扫描高,因为回表效率不高
做了一个小实验:
-- 关闭查询缓存
set global query_cache_size=0;
set global query_cache_type=0;
-- 执行时间
SELECT * FROM employees WHERE name > 'LiLei';
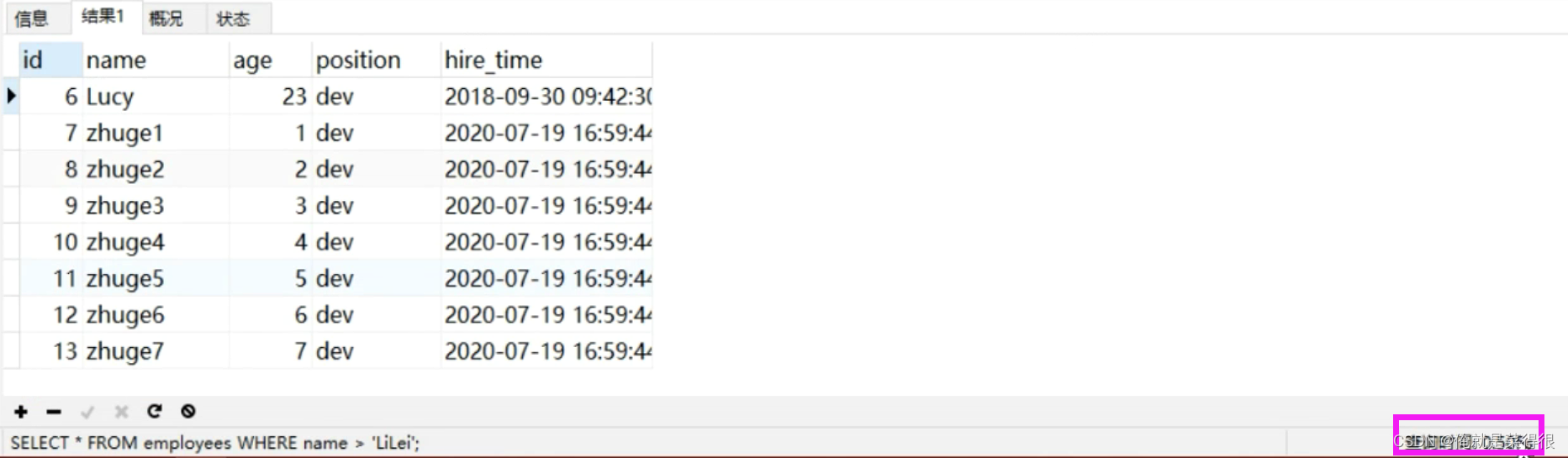
-- 执行时间
SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei';
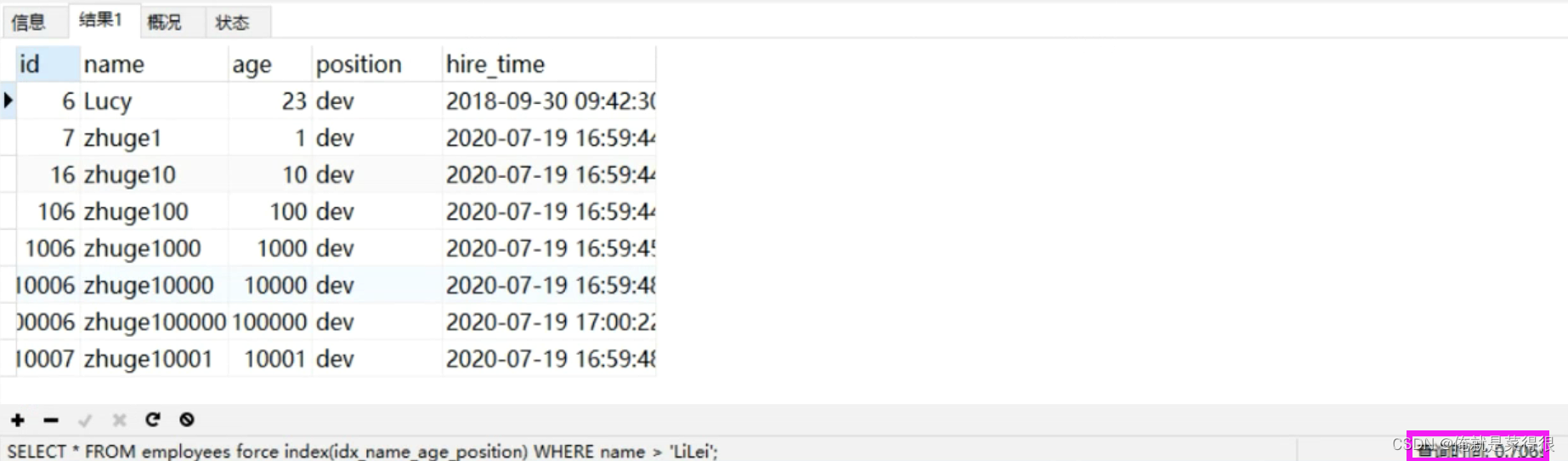
一定要把查询缓存给关闭了,如果不关第二次查询的时候会非常快。
3、覆盖索引优化
其实上述那种情况一般都是使用覆盖索引优化
EXPLAIN SELECT name,age,position FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';

============================================================================================
============================================================================================
4、in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描
EXPLAIN SELECT * FROM employees WHERE name in ('LiLei','HanMeimei','Lucy') AND age = 22 AND position ='manager';

EXPLAIN SELECT * FROM employees_copy WHERE name in ('LiLei','HanMeimei','Lucy') AND age = 22 AND position ='manager';
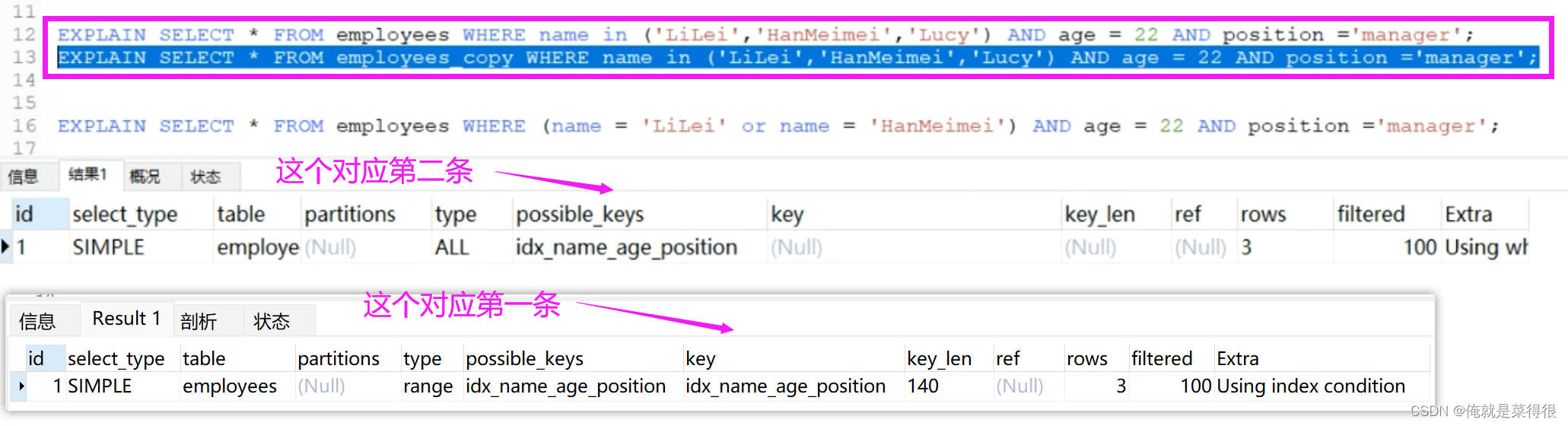
其实着两个表结构一模一样,唯一不同的是一个表数据少一个表数据多。employees多,employees_copy少。