系列文章目录
Flink第一章:环境搭建
Flink第二章:基本操作.
Flink第三章:基本操作(二)
文章目录
- 系列文章目录
- 前言
- 一、物理分区
- 1.shuffle(随机分区)
- 2.Round-Robin(轮询)
- 3.rescale(重缩放分区)
- 4.broadcast(广播)
- 5.Custom(自定义分区)
- 二、Sink
- 1.写出到文件
- 2.写入到Kafka
- 3.写入到Mysql
- 总结
前言
上一次博客中我们完成了Flink的Source操作和Transform的一部分,这次我们练习剩下的部分和Sink操作.
一、物理分区
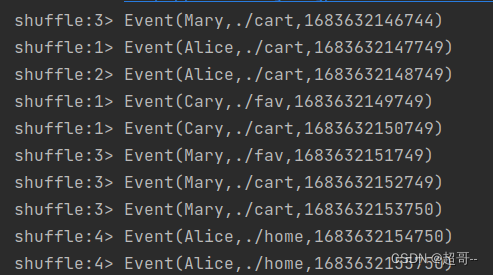
1.shuffle(随机分区)
将数据随机地分配到下游算子的并行任务中去。
PartitionShuffleTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.scala._
object PartitionShuffleTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val steam: DataStream[Event] = env.addSource(new ClickSource)
steam.shuffle.print("shuffle").setParallelism(4)
env.execute()
}
}
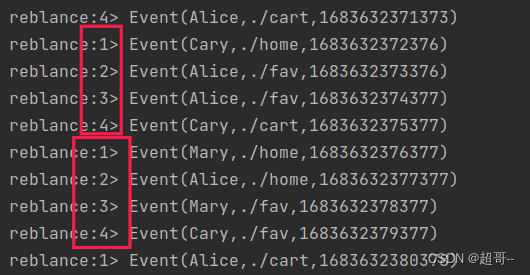
2.Round-Robin(轮询)
按照先后顺序将数据做依次分发
PartitionReblanceTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.scala._
object PartitionReblanceTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val steam: DataStream[Event] = env.addSource(new ClickSource)
steam.rebalance.print("reblance").setParallelism(4)
env.execute()
}
}
3.rescale(重缩放分区)
重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中.
PartitionRescaleTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala._
object PartitionRescaleTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val steam: DataStream[Int] = env.addSource(new RichParallelSourceFunction[Int] {
override def run(sourceContext: SourceFunction.SourceContext[Int]): Unit = {
for (i<-0 to 7) {
if (getRuntimeContext.getIndexOfThisSubtask == (i+1) % 2)
sourceContext.collect(i+1)
}
}
override def cancel(): Unit = ???
}).setParallelism(2)
steam.rescale.print("rescale").setParallelism(4)
env.execute()
}
}
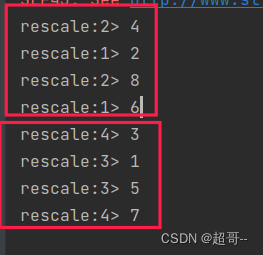
我们可以看到偶数都传到的1,2分区,奇数都传送到了3,4分区.
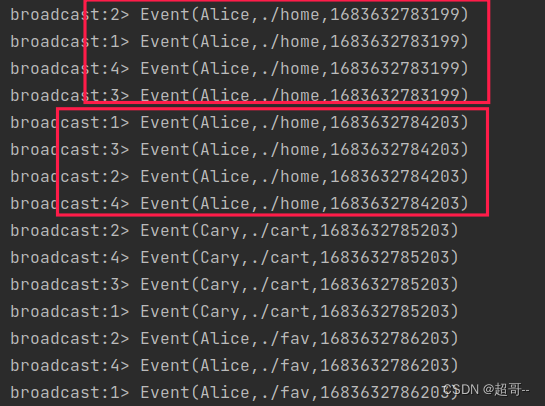
4.broadcast(广播)
数据会在不同的下游分区都传送一份
PartitionBroadcastTest.scala
package com.atguigu.chapter02.Transform
import com.atguigu.chapter02.Source.{ClickSource, Event}
import org.apache.flink.streaming.api.scala._
object PartitionBroadcastTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val steam: DataStream[Event] = env.addSource(new ClickSource)
steam.broadcast.print("broadcast").setParallelism(4)
env.execute()
}
}
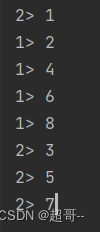
5.Custom(自定义分区)
PartitionCustonTest.scala
package com.atguigu.chapter02.Transform
import org.apache.flink.api.common.functions.Partitioner
import org.apache.flink.streaming.api.scala._
object PartitionCustonTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val steam: DataStream[Int] = env.fromElements(1,2,3,4,5,6,7,8)
steam.partitionCustom(new Partitioner[Int] {
override def partition(k: Int, i: Int): Int = {
k % 2
}
},data=>data).print().setParallelism(4)
env.execute()
}
}
二、Sink
创建需要的
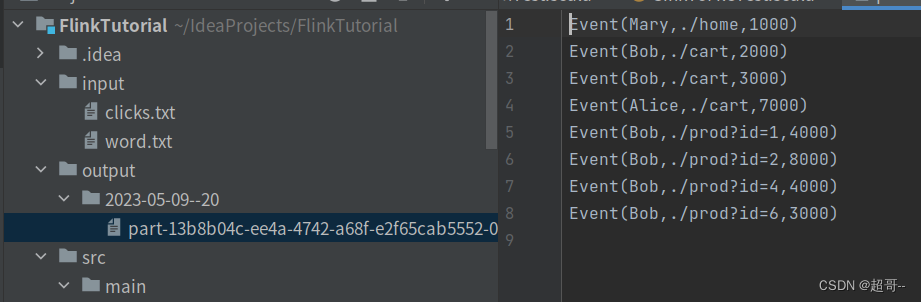
1.写出到文件
SinkToFileTest.scala
package com.atguigu.chapter02.Sink
import com.atguigu.chapter02.Source.Event
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.connector
import org.apache.flink.connector.file.sink.FileSink
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.scala._
object SinkToFileTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[String] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Bob", "./cart", 3000L),
Event("Alice", "./cart", 7000L),
Event("Bob", "./prod?id=1", 4000L),
Event("Bob", "./prod?id=2", 8000L),
Event("Bob", "./prod?id=4", 4000L),
Event("Bob", "./prod?id=6", 3000L),
).map(_.toString)
val filesink: FileSink[String] = FileSink.forRowFormat(new Path("./output"), new SimpleStringEncoder[String]("UTF-8")).build()
stream.sinkTo(filesink)
env.execute()
}
}
2.写入到Kafka
SinkToKafkaTest.scala
package com.atguigu.chapter02.Sink
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.connector.kafka.sink._
import org.apache.flink.streaming.api.scala._
object SinkToKafkaTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[String] = env.readTextFile("input/clicks.txt")
val sink: KafkaSink[String] = KafkaSink.builder()
.setBootstrapServers("hadoop102:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("clicks")
.setValueSerializationSchema(new SimpleStringSchema()).build()).build()
stream.sinkTo(sink)
env.execute()
}
}
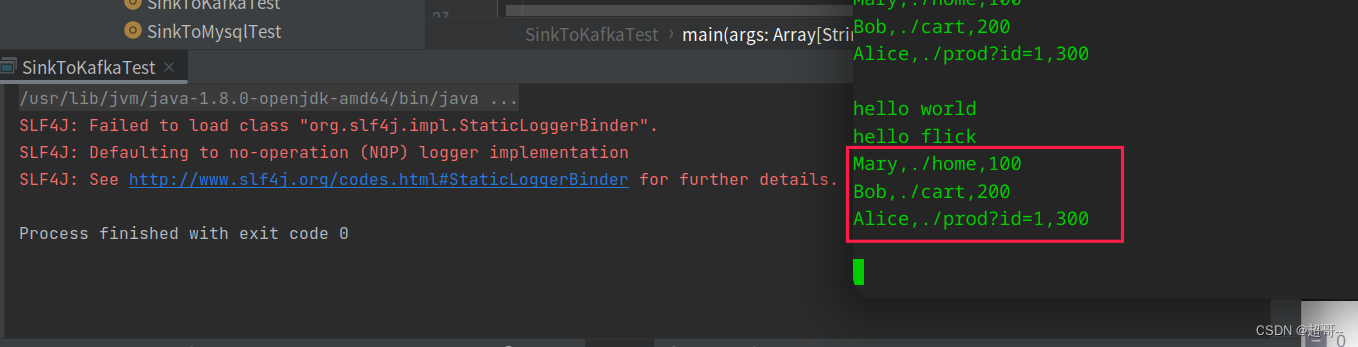
查看最新的消费数据.
3.写入到Mysql
SinkToMysqlTest.scala
package com.atguigu.chapter02.Sink
import com.atguigu.chapter02.Source.Event
import org.apache.flink.connector.jdbc.{JdbcConnectionOptions, JdbcSink, JdbcStatementBuilder}
import org.apache.flink.streaming.api.functions.sink.SinkFunction
import org.apache.flink.streaming.api.scala._
import java.sql.PreparedStatement
object SinkToMysqlTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream: DataStream[Event] = env.fromElements(
Event("Mary", "./home", 1000L),
Event("Bob", "./cart", 2000L),
Event("Bob", "./cart", 3000L),
Event("Alice", "./cart", 7000L),
Event("Bob", "./prod?id=1", 4000L),
Event("Bob", "./prod?id=2", 8000L),
Event("Bob", "./prod?id=4", 4000L),
Event("Bob", "./prod?id=6", 3000L),
)
val jdbcF: SinkFunction[Event] = JdbcSink.sink(
"INSERT INTO clicks (user,url) VALUES (?,?)",
new JdbcStatementBuilder[Event] {
override def accept(t: PreparedStatement, u: Event): Unit = {
t.setString(1, u.user)
t.setString(2, u.url)
}
},
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/test")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("123456")
.build()
)
stream.addSink(jdbcF)
env.execute()
}
}

Flink提供的Sink接口还有很多,这里就随便举几个例子,还需要那些查文档就行了.
总结
Flink的基本操作就练习完成了.