torch.nn:
Containers: 神经网络骨架
Convolution Layers 卷积层
Pooling Layers 池化层
Normalization Layers 正则化层
Non-linear Activations (weighted sum, nonlinearity) 非线性激活
Convolution Layers
Conv2d
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
in_channels= : 输入图像的通道数
out_channels= : 输出图象的通道数
kernel_size=3: 3x3的卷积核,会在训练过程中不断调整
stride: 卷积核滑动的步长
padding: 在图像的纵向和横向填充 ,填充的地方一般默认为0,这样卷积核可以划过更多地方
padding_mode=zeros: padding时的填充值
dilation: 卷积核的对应位
groups
bias:偏置
卷积过程:

经典vgg16的卷积过程:

推导padding等参数的公式:

import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../dataset_transform",train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Zrf(nn.Module):
def __init__(self):
super(Zrf, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
# 初始化网络
zrf = Zrf()
print(zrf)
writer = SummaryWriter("conv2d")
step = 0
for data in dataloader:
imgs, targets = data
output = zrf(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input_imgs", imgs, step)
# torch.Size([64, 6, 30, 30]) ---> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output_imgs", output, step)
step = step + 1
writer.close()
Pooling Layers
MaxPool2d
最大池化--->下采样(别称)
(池化层没有要优化的参数,只是形式上的卷积核)
kernel_size=3: 3x3的窗口,用来取最大值
stride: 窗口滑动的步长,默认值是kernel_size的大小
padding: 在图像的纵向和横向填充 ,填充的地方一般默认为0
dilation: 空洞卷积
return_indices: 通常来说不会用到
ceil_mode: 设置为True时,会使用ceil模式(不满3x3也取一个最大值)而不是floor模式(不满3x3就不取值 )
一般理解------ceil:向上取整,floor模式:向下取整
为什么要进行最大池化? 在保持数据特征的同时,减小数据量
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="../dataset_transform", download=True, train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]], dtype=torch.float32)
# input = torch.reshape(input, (-1, 1, 5, 5))
# print(input.shape)
class Zrf(nn.Module):
def __init__(self):
super(Zrf, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3)
def forward(self, x):
output = self.maxpool1(x)
return output
zrf = Zrf()
# output = zrf(input)
# print(output)
writer = SummaryWriter("log_maxpol")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("max_before", imgs, step)
output = zrf(imgs)
writer.add_images("max_afteer", output, step)
step = step + 1
writer.close()
Non-linear Activations
Relu:大于0取原值,小于0取0

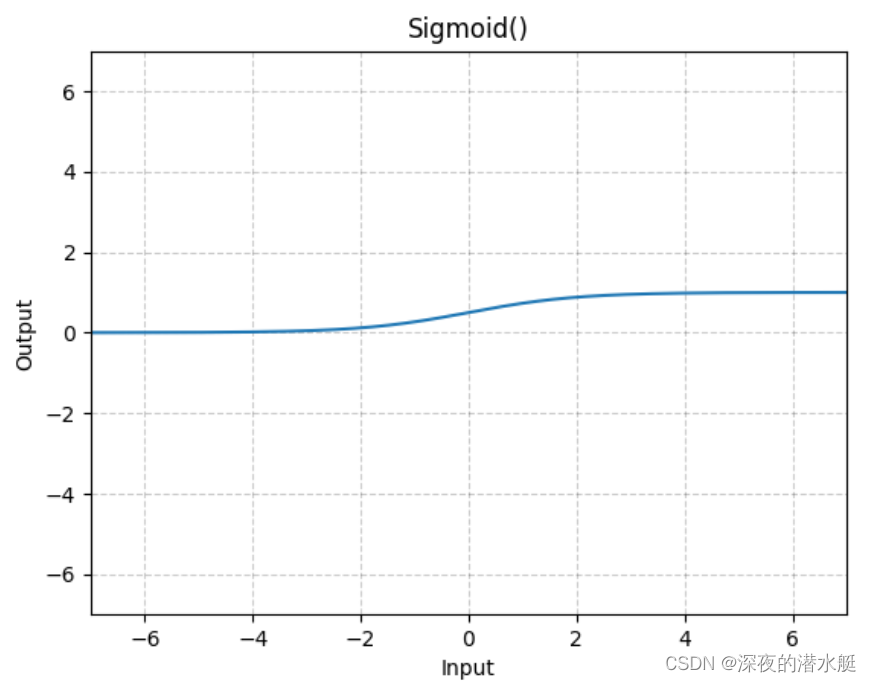
Sigmoid:常用激活函数
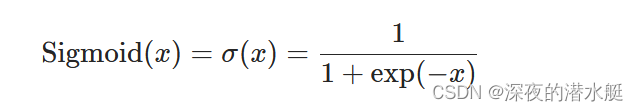
inplace参数
input = -1
Relu(input, inplace = True)
# 结果:input = 0
input = -1
output = Relu(input, inplace = False)
# 结果:input = -1, output = 0import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))
# print(input.shape)
dataset = torchvision.datasets.CIFAR10(root="../dataset_transform", download=True, train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Zrf(nn.Module):
def __init__(self):
super(Zrf, self).__init__()
# self.relu1 = nn.ReLU()
self.sigmoid1 = nn.Sigmoid()
def forward(self, input):
# output = self.relu1(input)
output = self.sigmoid1(input)
return output
# zrf = Zrf()
# output = zrf(input)
# print(output)
zrf = Zrf()
writer = SummaryWriter("log_sigmoid")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("before_sigmoid", imgs, step)
output = zrf(imgs)
writer.add_images("after_sigmoid", output, step)
step = step + 1
writer.close()
线性层以及其他层介绍
Linear Layers
线性层,目的是变换特征维度,参数:in_features, out_features, bias (bool)
in_features:
out_features:
bias (bool):偏置
计算过程中的权重k和偏置b要按照一定条件进行调整和优化
Normalization Layers
正则化层:对输入进行正则化(注意:正则化不是归一化),有助于梯度下降,解决过拟合

num_feature(int): 输入图像的通道数层
affine(bool): 当设置为True时,该模块具有可学习的仿射参数,一般默认为True
Recurrent Layers
循环网络,多用于文字处理中
Transformers Layers
。。。21年大火
Dropout Layers
在训练过程中,会随机的把输入图像(tensor数据类型)中的元素以p的概率变成0
主要是为了防止过拟合
Sparse Layers
主要用于自然语言处理
Distance Functions
计算两个值之间的误差
Loss Functions
计算损失