机器学习是人工智能领域的一个重要分支,可以帮助我们从大量数据中发现规律,进行预测和分类等任务。然而,想要真正掌握机器学习算法,并将其应用到实际问题中,还需要进行大量的实战练习。

本文将介绍几个常见的机器学习实战项目,旨在帮助读者从实践中学习并掌握机器学习算法。
1. 手写数字识别
手写数字识别是机器学习入门项目中的经典案例,通常使用的是支持向量机(SVM)算法。我们可以使用MNIST数据集进行训练和测试,这个数据集包含了大量的手写数字图片,标注了对应的数字。通过对这些图片进行预处理和特征提取,我们可以将SVM应用于分类任务,实现准确的手写数字识别。

2. 垃圾邮件过滤
垃圾邮件过滤也是机器学习的一个实际应用场景,可以使用朴素贝叶斯算法进行分类。我们可以使用公开的垃圾邮件数据集进行训练和测试,将邮件内容进行特征提取和处理,然后应用朴素贝叶斯算法进行分类。通过实际应用,可以有效地过滤掉垃圾邮件,提高工作效率。

3. 电影推荐系统
电影推荐系统是一个典型的协同过滤应用场景,可以使用基于用户的协同过滤算法进行实现。我们可以使用公开的电影评分数据集进行训练和测试,将用户的评分和喜好进行建模,然后通过协同过滤算法,推荐给用户可能感兴趣的电影。这个项目可以帮助读者理解协同过滤算法的原理和应用,以及如何通过算法实现个性化推荐。

4. 情感分析
情感分析是机器学习的一个热门应用场景,可以使用深度学习算法进行实现。我们可以使用公开的情感分析数据集进行训练和测试,将文本进行特征提取和处理,然后使用深度学习模型进行分类。通过实际应用,可以有效地分析文本中的情感倾向,帮助企业进行市场调研和口碑管理。
机器学习资料+60G入门进阶AI资Y包+技术问题答疑+完整版视频关注威❤公Z号【Ai技术星球】发送(123)必领
一些常见的机器学习算法如线性回归、逻辑回归、决策树、随机森林、支持向量机、K近邻等,都可以在实战中应用到。下面我们以分类问题为例,介绍一个机器学习实战的流程。

- 数据收集与预处理
首先需要收集并准备数据集。如果数据量比较少,可以手动标注;如果数据量比较大,可以考虑使用自动标注工具,如Amazon Mechanical Turk、CrowdFlower等。
接下来需要对数据进行预处理,包括缺失值填充、特征缩放、特征选择等。常用的特征缩放方法有Z-score标准化和min-max标准化。
- 数据可视化与探索性分析
在进行模型训练之前,需要对数据进行可视化与探索性分析。这可以帮助我们发现数据中的模式和异常值,并作出相应的处理。
常用的可视化工具包括matplotlib、seaborn、plotly等。在数据探索性分析方面,可以使用pandas、numpy等工具包。
- 模型选择与训练
选择合适的模型是机器学习实战中非常关键的一步。不同的模型适用于不同的数据集和任务。在这里我们以逻辑回归为例。
首先需要将数据集划分为训练集和测试集。在训练集上训练模型,并使用测试集进行验证。
- 模型评估与调优
在进行模型评估时,可以使用一些常见的评估指标,如精度、召回率、F1-score等。通过调整模型参数和选择合适的特征,可以进一步提高模型性能。
- 模型部署与应用
在模型训练和评估完成后,需要将模型部署到实际应用场景中。这可以使用一些常见的部署方式,如Web服务、移动应用等。
总的来说,机器学习实战需要掌握一些基本的数据处理和模型训练技巧。需要不断地尝试和实践,才能够提高自己的水平。

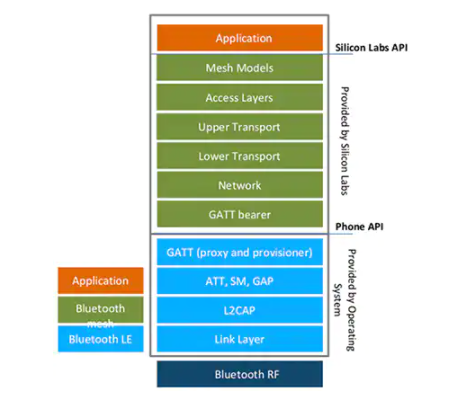




![[工具]Pytorch-lightning的使用](https://img-blog.csdnimg.cn/d3001cffcd0b4da795f7d57e3b219fd1.png)
![shiro反序列化[cve_2016_4437]](https://img-blog.csdnimg.cn/b30d9e2b3d8a4a98b8a513349e20a234.png)