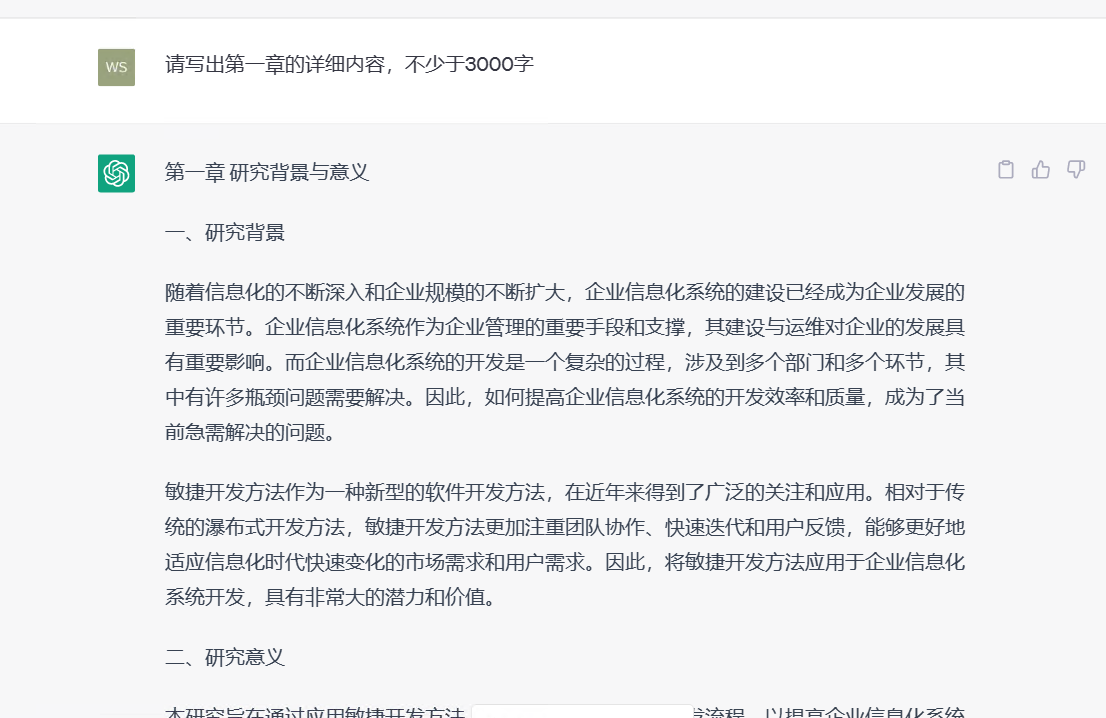
一、环形链表 I

方法1:哈希表

struct hashTable {
struct ListNode* key;
UT_hash_handle hh;
};
struct hashTable* hashtable;
struct hashTable* find(struct ListNode* ikey) {
struct hashTable* tmp;
HASH_FIND_PTR(hashtable, &ikey, tmp);
return tmp;
}
void insert(struct ListNode* ikey) {
struct hashTable* tmp = malloc(sizeof(struct hashTable));
tmp->key = ikey;
HASH_ADD_PTR(hashtable, key, tmp);
}
bool hasCycle(struct ListNode* head) {
hashtable = NULL;
while (head != NULL) {
if (find(head) != NULL) {
return true;
}
insert(head);
head = head->next;
}
return false;
}
代码解释
(1) HASH_FIND_PTR(hashtable, &ikey, tmp);
在这段代码中,hashtable 是哈希表的头指针,&ikey 是要查找的键,它是一个指向链表节点指针的指针的地址,tmp 是查找结果的输出参数,它是一个指向哈希表项的指针。因此,HASH_FIND_PTR(hashtable, &ikey, tmp) 的作用是在哈希表中查找指定键的哈希表项,并将结果存储在 tmp 中。如果找到了,则返回该哈希表项;否则返回 NULL。
(2)HASH_ADD_PTR(hashtable, key, tmp);
在这段代码中,hashtable 是哈希表的头指针,key 是哈希表项中表示键的字段,它是一个指向链表节点指针的指针,tmp 是要添加的键值对,它是一个指向哈希表项的指针。因此,HASH_ADD_PTR(hashtable, key, tmp) 的作用是将一个键值对添加到哈希表中,其中键是 tmp->key,即链表节点的指针,值是 tmp,即哈希表项的指针,同时更新哈希表的头指针 hashtable。
C++
class Solution {
public:
bool hasCycle(ListNode *head) {
//定义了一个 unordered_set<ListNode*> seen,
//表示存储已经遍历过的链表节点的集合。
unordered_set<ListNode*> seen;
while (head != nullptr) {
if (seen.count(head)) {
return true;
}
seen.insert(head);
head = head->next;
}
return false;
}
};
方法2:快慢指针

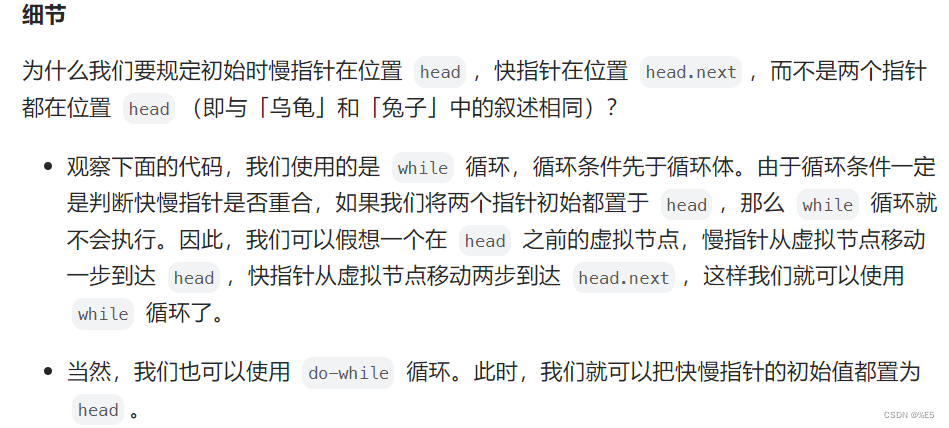
C
bool hasCycle(struct ListNode* head) {
if (head == NULL || head->next == NULL) {
return false;
}
struct ListNode* slow = head;
struct ListNode* fast = head->next;
while (slow != fast) {
//检测快指针 fast 是否到达了链表的末尾。如果 fast 指针到达了末尾,
//即 fast 指向空节点或者 fast 的下一个节点为空节点,则说明链表没有环,
//返回 false。
if (fast == NULL || fast->next == NULL) {
return false;
}
slow = slow->next;
fast = fast->next->next;
}
return true;
}
C++
class Solution {
public:
bool hasCycle(ListNode* head) {
if (head == nullptr || head->next == nullptr) {
return false;
}
ListNode* slow = head;
ListNode* fast = head->next;
while (slow != fast) {
if (fast == nullptr || fast->next == nullptr) {
return false;
}
slow = slow->next;
fast = fast->next->next;
}
return true;
}
};
二、环形链表 II
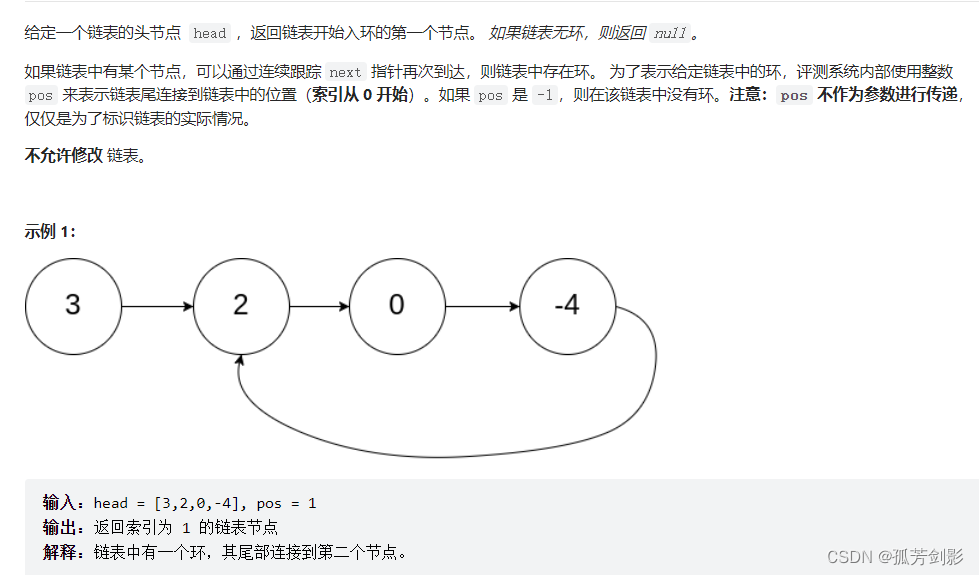

方法1:哈希表

C
struct hashTable {
struct ListNode* key;
UT_hash_handle hh;
};
struct hashTable* hashtable;
struct hashTable* find(struct ListNode* ikey) {
struct hashTable* tmp;
HASH_FIND_PTR(hashtable, &ikey, tmp);
return tmp;
}
void insert(struct ListNode* ikey) {
struct hashTable* tmp = malloc(sizeof(struct hashTable));
tmp->key = ikey;
HASH_ADD_PTR(hashtable, key, tmp);
}
struct ListNode* detectCycle(struct ListNode* head) {
hashtable = NULL;
while (head != NULL) {
if (find(head) != NULL) {
return head;
}
insert(head);
head = head->next;
}
return false;
}
C++
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
unordered_set<ListNode *> visited;
while (head != nullptr) {
if (visited.count(head)) {
return head;
}
visited.insert(head);
head = head->next;
}
return nullptr;
}
};
方法2:快慢指针

C
struct ListNode* detectCycle(struct ListNode* head) {
struct ListNode *slow = head, *fast = head;
while (fast != NULL) {
slow = slow->next;
if (fast->next == NULL) {
return NULL;
}
fast = fast->next->next;
if (fast == slow) {
struct ListNode* ptr = head;
while (ptr != slow) {
ptr = ptr->next;
slow = slow->next;
}
return ptr;
}
}
return NULL;
}
C++
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode *slow = head, *fast = head;
while (fast != nullptr) {
slow = slow->next;
if (fast->next == nullptr) {
return nullptr;
}
fast = fast->next->next;
if (fast == slow) {
ListNode *ptr = head;
while (ptr != slow) {
ptr = ptr->next;
slow = slow->next;
}
return ptr;
}
}
return nullptr;
}
};
三、相交链表

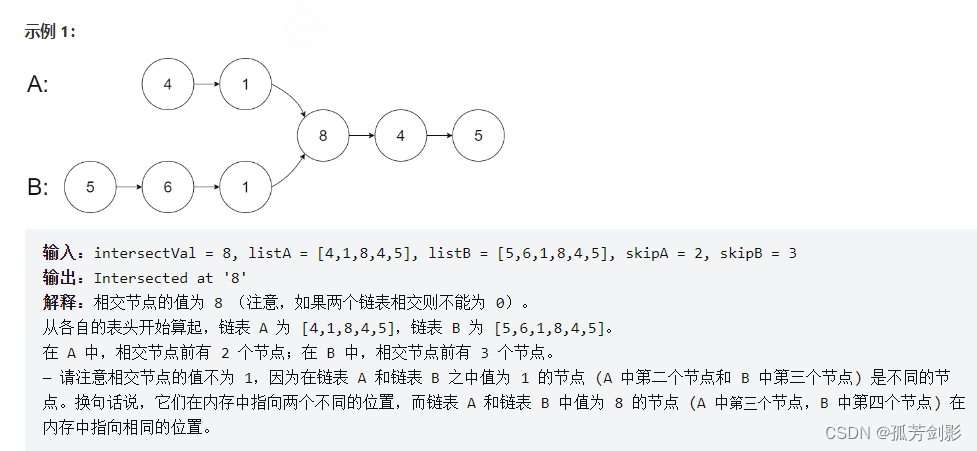

方法1:哈希集合

C
struct HashTable {
struct ListNode *key;
UT_hash_handle hh;
};
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct HashTable *hashTable = NULL;
struct ListNode *temp = headA;
while (temp != NULL) {
struct HashTable *tmp;
HASH_FIND(hh, hashTable, &temp, sizeof(struct HashTable *), tmp);
if (tmp == NULL) {
tmp = malloc(sizeof(struct HashTable));
tmp->key = temp;
HASH_ADD(hh, hashTable, key, sizeof(struct HashTable *), tmp);
}
temp = temp->next;
}
temp = headB;
while (temp != NULL) {
struct HashTable *tmp;
HASH_FIND(hh, hashTable, &temp, sizeof(struct HashTable *), tmp);
if (tmp != NULL) {
return temp;
}
temp = temp->next;
}
return NULL;
}
代码解释:
(1)HASH_FIND(hh, hashTable, &temp, sizeof(struct HashTable *), tmp);
HASH_FIND(hh, hashTable, &temp, sizeof(struct HashTable *), tmp); 的作用是在哈希表 hashTable 中查找是否存在指针 temp 所指向的 ListNode 节点,如果找到了就将指向 HashTable 结构体的指针赋值给 tmp,否则将 tmp 赋值为 NULL。
(2)HASH_ADD(hh, hashTable, key, sizeof(struct HashTable *), tmp);
HASH_ADD(hh, hashTable, key, sizeof(struct HashTable *), tmp); 的作用是将指针 tmp 所指向的 HashTable 结构体添加到哈希表 hashTable 中。具体来说,它将 tmp 关联到 key 成员(即指向 ListNode 的指针),并将 tmp 添加到哈希表中。
C++
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
unordered_set<ListNode *> visited;
ListNode *temp = headA;
while (temp != nullptr) {
visited.insert(temp);
temp = temp->next;
}
temp = headB;
while (temp != nullptr) {
if (visited.count(temp)) {
return temp;
}
temp = temp->next;
}
return nullptr;
}
};
方法2:双指针



C
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
if (headA == NULL || headB == NULL) {
return NULL;
}
struct ListNode *pA = headA, *pB = headB;
while (pA != pB) {
pA = pA == NULL ? headB : pA->next;
pB = pB == NULL ? headA : pB->next;
}
return pA;
}
C++
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if (headA == nullptr || headB == nullptr) {
return nullptr;
}
ListNode *pA = headA, *pB = headB;
while (pA != pB) {
pA = pA == nullptr ? headB : pA->next;
pB = pB == nullptr ? headA : pB->next;
}
return pA;
}
};
四、删除链表的倒数第N个节点

方法1:计算链表长度
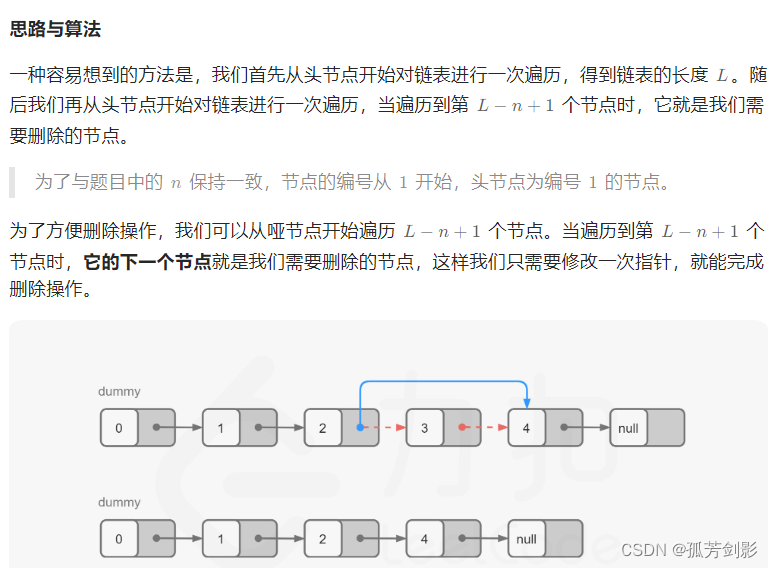
C
int getLength(struct ListNode* head) {
int length = 0;
while (head) {
++length;
head = head->next;
}
return length;
}
struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {
struct ListNode* dummy = malloc(sizeof(struct ListNode));
dummy->val = 0, dummy->next = head;
int length = getLength(head);
struct ListNode* cur = dummy;
for (int i = 1; i < length - n + 1; ++i) {
cur = cur->next;
}
cur->next = cur->next->next;
struct ListNode* ans = dummy->next;
free(dummy);
return ans;
}
C++
class Solution {
public:
int getLength(ListNode* head) {
int length = 0;
while (head) {
++length;
head = head->next;
}
return length;
}
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummy = new ListNode(0, head);
int length = getLength(head);
ListNode* cur = dummy;
for (int i = 1; i < length - n + 1; ++i) {
cur = cur->next;
}
cur->next = cur->next->next;
ListNode* ans = dummy->next;
delete dummy;
return ans;
}
};
代码解释:
(1)ListNode* dummy = new ListNode(0, head);
在C++中,使用new关键字可以动态地在堆上分配内存,返回指向该内存的指针。ListNode(0, head)是调用ListNode类的构造函数,创建一个新的ListNode对象,并将0和head作为参数传递给构造函数。因为该构造函数接收两个参数,所以使用了括号括起来的两个参数。
这段代码的作用是创建一个虚拟头节点,将其值初始化为0,next指针指向head,这样可以方便处理删除头节点的情况。因为该虚拟头节点是动态分配的,所以在函数结束时需要调用delete关键字释放动态分配的内存。

![[工具]Pytorch-lightning的使用](https://img-blog.csdnimg.cn/d3001cffcd0b4da795f7d57e3b219fd1.png)
![shiro反序列化[cve_2016_4437]](https://img-blog.csdnimg.cn/b30d9e2b3d8a4a98b8a513349e20a234.png)