0.关注博主有更多知识
C++知识合集
目录
1.C/C++内存分布
2.C++内存管理方式
2.1new和delete操作内置类型
2.2new和delete对自定义类型操作
2.3new和delete一定要配套使用
2.4new和malloc对错误的处理方式
3.operator new和operator delete函数
3.1new和delete的实现原理
4.定位new表达式
5.常见面试题
5.1malloc、free和new、delete的区别
5.2内存泄漏
1.C/C++内存分布
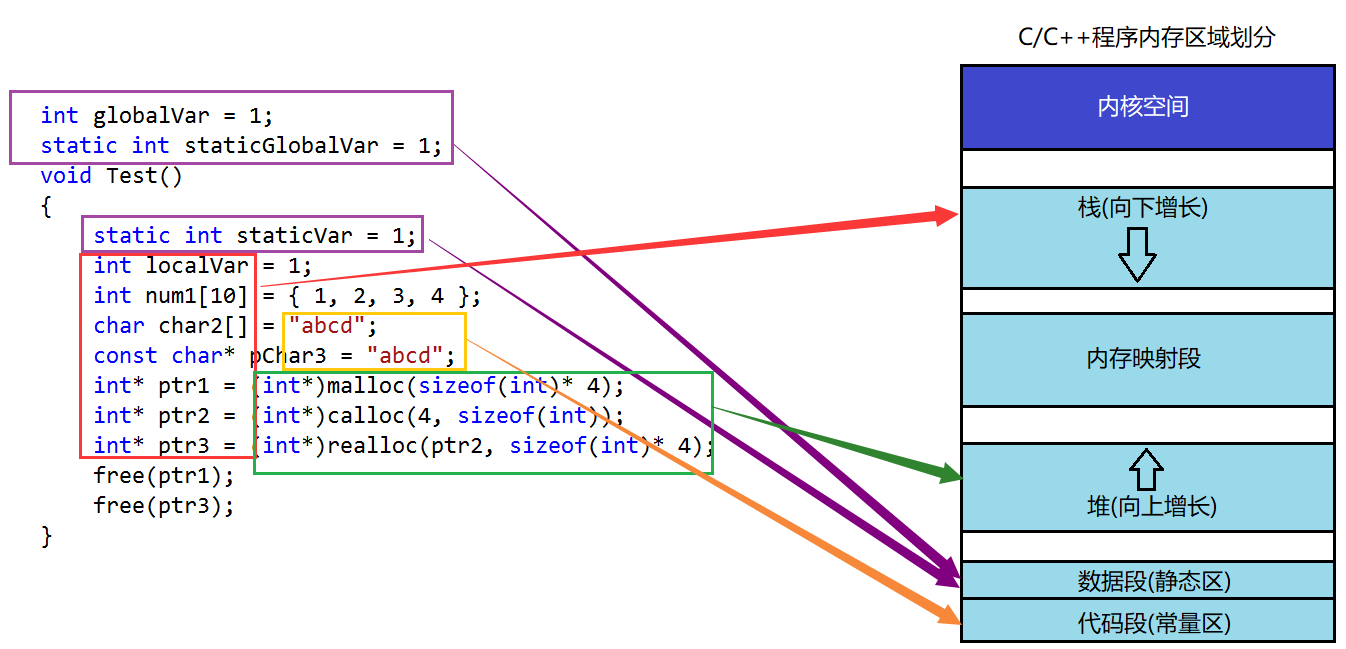
现代操作系统采用段页式虚拟内存管理来管理内存,其中,段就分为栈、堆、内存映射段、数据段、代码段以及内核空间。因为我们要讨论的是C/C++的内存管理,即站在语言、站在程序的角度来看待内存,所以对于操作系统的描述将会一笔带过。首先我们必须要知道,我们在编写代码的时候所说的内存都是虚拟内存,即使用的地址都是虚拟地址,但是因为操作系统独特的内存管理机制,使得我们可以正常运行程序。

实际上程序被编译好之后,其中的代码和指令都存储在可执行文件上了,而可执行文件是存放在磁盘上的。那么可执行文件当中的指令(机器指令)一定会存在访存指令,而现在可执行文件还没有被加载到内存当中,所以它使用的地址都是虚拟地址,这个虚拟地址是编译器自动分配的。那么当可执行文件(即程序)被加载到内存之后,操作系统使用进程来描述程序在内存当中的一次运行活动,那么进程是存储在内存当中的,但是它的访存指令使用的都是虚拟地址,所以会有一个名为虚拟进程地址空间的"空间",注意这个"空间"并不是一个实在的物理空间,它是一种假象,也就是说在32位操作系统下能够假想出大小为4G的空间,这个空间是每个进程都拥有的,这个空间就是虚拟进程地址空间。实际上虚拟进程地址空间的表示非常简单,用地址即可,操作系统为了描述进程还有一个名为进程控制块的结构体,该结构体当中有一个字段会记录每个内存段的起始地址和结束地址,例如数据段的起始地址为0x00123456,结束地址为0x00888888等等这样,即根据地址来确定能够看到的空间(一个地址确定一个字节)。CPU执行指令的时候访问的也是虚拟地址,但是CPU会做一个计算,即将虚拟地址转换成某种格式,然后操作系统通过这个特殊的格式去找到正确的物理地址,这就是一次访存的过程。
那么也就是说,程序、进程本身感知不到物理内存的存在,所以我们所说的C/C++程序的内存区域都是虚拟内存,但是这并不妨碍我们的讨论,因为操作系统有办法让我们的讨论结果正确。
内存分段的目的就是在于存储不同的类型的数据,例如动态开辟的空间是从堆上开辟的、函数栈、函数栈内部的数据都是在栈上开辟空间存储的......分段有利于操作系统的管理,在一定程度上起到了解耦合的作用。下面说明一下内存各段的作用:
1.栈,又叫做堆栈,非静态局部变量、函数参数、返回值等等存储的空间,由高地址向低地址增长,即向下增长
2.内存映射段,这是一个用于装载动态库的共享区,用户可以使用系统接口创建共享内存等等(操作系统的东西,大家看个热闹)
3.堆用于程序运行时的动态内存分配,堆由低地址向高地址增长,即向上增长
4.数据段,用于存储全局变量静态变量
5.代码段,存储可执行的代码和只读常量
那么我们以一段代码,初步分析各变量及其内容存放在哪里:
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = { 1, 2, 3, 4 };
char char2[] = "abcd";
const char* pChar3 = "abcd";
int* ptr1 = (int*)malloc(sizeof(int) * 4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);
free(ptr1);
free(ptr3);
}1.给定三个选项:A.栈 B.堆 C.数据段 D.代码段,判断下列内容存放在哪里:
globalVal存放在?C.数据段 staticGblobalVal存放在?C.数据段
staticVar存放在?C.数据段 localVar存放在?A.栈
num1存放在?A.栈
char2存放在?A.栈 *char2存放在?A.栈
pChar3存放在?A.栈 *pChar3存放在?D.代码段
ptr1存放在?A.栈 *ptr1存放在?B.堆
可能大家对*char2存放在栈上有所疑问,实际上我们要注意,char2是一个空间开辟在栈上的数组,数组当中保存了"abcd"这个字符串,这个字符串本身是代码段的一个常量,但是因为数组要保存字符串,所以数组当中保存的是代码段中的字符串的一份拷贝。
2.填空题
sizeof(num1)=?40
sizeof(char2)=?5 strlen(char2)=?4
sizeof(pChar3)=?4或8 strlen(pChar3)=?4
sizeof(ptr1)=?4或8
那么对于上面的这段程序,其变量及内容的映射效果是这样的:
2.C++内存管理方式
因为C++兼容C语言,所以C语言的动态内存管理方式也可以在C++上面用,但是malloc、free等等在C++上面还是有相当大的局限性的。所以C++提出了自己的内存管理方式,即使用new和delete来动态开辟、释放空间,new和delete都是操作符,以关键字的形式存在。
2.1new和delete操作内置类型
int main()
{
/*动态开辟一个int类型的空间*/
int *p1 = new int;
delete p1;
/*动态开辟一个int类型空间,并初始化为0*/
int *p2 = new int(0);
delete p2;
/*动态开辟十个int类型的空间,即开辟一个数组*/
int *p3 = new int[10];
delete[] p3;
/*动态开辟一个数组,并将前4个整数初始化为1、2、3、4,随后的都被初始化为0*/
int *p4 = new int[10]{1, 2, 3, 4};
delete[] p4;
return 0;
}可以看到new的用法与malloc()类似,在对上申请空间,然后获得该空间的起始地址。那么delete的用法是有讲究的,如果开辟的是单一类型的空间,那么直接delete即可;但是如果开辟的是一块数组,即连续的多个类型的空间,那么就需要使用delete[]释放空间。
事实上new和delete对于内置类型来说,与malloc()和free()没有太大差别,只不过new申请空间的方式相较于C语言的方式更加灵活而已。所以new和delete的真正战场在于对自定义类型操作。
2.2new和delete对自定义类型操作
class A
{
public:
A(int a = 0)
:_a(a)
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
private:
int _a;
};
int main()
{
/*两种用法都是调用默认构造*/
A *p1 = new A;
delete p1;
A *p2 = new A();
delete p2;
A *p3 = new A(100);
delete p3;
return 0;
}
可以看到new对自定义类型操作时会自动调用其构造函数;delete对自定义类型操作时会自动调用其析构函数。而在C语言中的malloc()和free()则不会这么干。这就意味着当我们的类中的成员需要动态开辟内存时,我们不需要手动释放了,而是直接把这个交给delete,可以很好的防止内存泄漏。并且因为C语言的malloc()不会调用构造函数,而且构造函数不能显式调用,所以使用malloc()根本不能正确的实例化出对象:
class A
{
public:
/*使用malloc()不会调用构造函数,所以_a成员无法初始化*/
A(int a = 0)
:_a(new int[10])
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
private:
int *_a;
};
int main()
{
/*malloc()没有调用构造,那么A类当中的成员无法正确初始化*/
A *p1 = (A *)malloc(sizeof(A));
free(p1);
return 0;
}
2.3new和delete一定要配套使用
动态开辟的内存一定要释放空间,否则会造成内存泄漏。事实上如果一个程序动态开辟了内存,但是在不久之后程序退出,那么释放不释放该内存都无所谓了,因为该空间会归还给操作系统;那么如果一个程序动态开辟了内存之后而久久不退出,那么随着时间的推移,这块空间依然被该程序占用,就会造成内存泄漏。
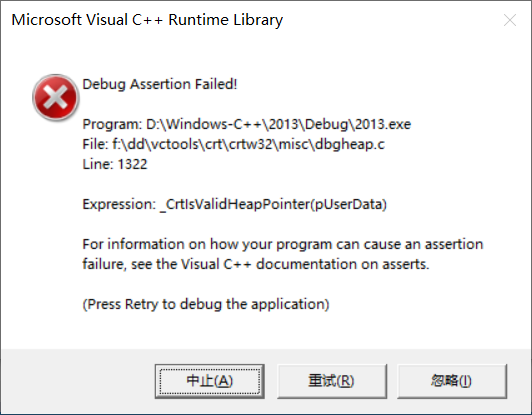
当然,使用new和delete时不仅仅要注意内存泄漏的问题,还需要注意配套使用的问题。如果new出来的仅仅是一个单一类型的对象,那么直接delete即可;如果new出来的是一个数组,那么必须使用delete[]释放,否则会造成严重的运行错误:
class A
{
public:
A()
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
};
int main()
{
A *p1 = new A;
delete[] p1;
return 0;
}
class A
{
public:
A()
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
};
int main()
{
A *p1 = new A[10];
delete p1;
return 0;
}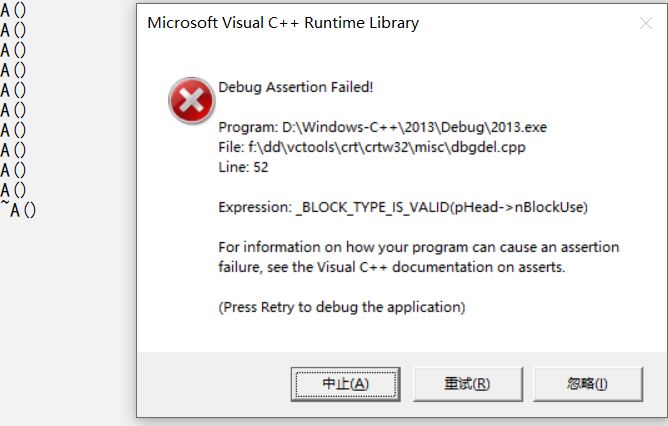
不同的编译器的崩溃原因是不一样的,这里简单介绍一下VS引发崩溃的原因。如果是对于自定义类型,那么在delete时会调用析构函数,那么delete就需要知道它应该调用多少次析构函数。如果只是单纯的使用delete去释放空间,那么它就会调用一次析构函数;如果使用delete[]去释放空间,那么delete[]在释放空间时,会将当前指针向前偏移4个字节,获取需要调用析构函数的次数,也就是说,如果new出来的是一个自定义类型的数组,那么new出来的空间会多4个字节,用来存放一个数字,这个数字用来表示有几个对象,即用来告诉delete[]要调用多少次析构函数:
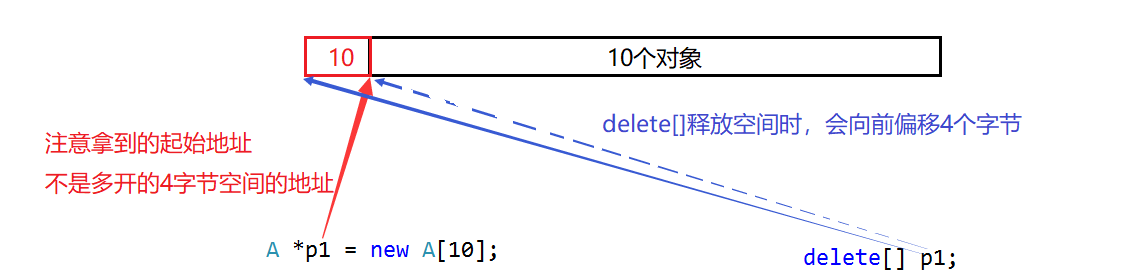
如同上面的第一个引发崩溃的程序,我们仅仅new了一个对象,但是却使用delete[]去释放,这就会造成delete[]释放的不是属于我们的空间:

而我们又知道动态开辟的空间不能只释放一部分,即不能局部释放,那么上面引发崩溃的第二个程序就是局部释放:

如果我们不显式的写析构函数,那么无论怎么使用new和delete都不会引发报错(VS2013是这样,其他的编译器不确定):
class A
{
public:
A()
{
cout << "A()" << endl;
}
};
int main()
{
A *p1 = new A[10];
delete p1;
return 0;
}
这是因为编译器的只能选择。因我们知道我们不显式定义析构函数,编译器会为我们自动生成一份,那么编译器自动的生成的析构函数的行为编译器是知道的,那么既然编译器知道该怎么做那么在new对象数组的时候就不会多开4个字节的空间,同理delete[]释放空间时也不会向前偏移4个字节。
总而言之,无论什么情况下会出错,什么情况下不会出错,那么我都建议new和delete一定要配套使用。
2.4new和malloc对错误的处理方式
new和malloc的差别不仅仅在于自动调用构造函数,它们的错误处理行为是不一样的。我们知道malloc()申请空间失败之后会返回一个空指针,所以我们需要在外部主动做判断:
int main()
{
while (true)
{
int *p = (int *)malloc(1024 * 1024);
if (p)
{
cout << p << endl;
}
else
{
cout << "申请失败" << endl;
break;
}
}
return 0;
}
但如果我们将上面代码的malloc()替换为new,就会发生不一样的变化:
int main()
{
while (true)
{
int *p = new int[1024 * 1024];
if (p)
{
cout << p << endl;
}
else
{
cout << "申请失败" << endl;
break;
}
}
return 0;
}
从输出结果上来看,new出来的空间总是"有效"的,因为它们都不是空指针。那么如果使用new动态开辟空间,如果处理错误呢?实际上要清楚的是C++是一门面向对象的语言,所以要有一套独特的体系区别去面向过程的语言,所以当new开辟空间出错时,不是通过返回值来判断,而是直接抛异常。这也是C++为什么要设计new和delete的一个原因。
int main()
{
/*使用try对可能会出现异常的地方尝试捕获异常*/
try
{
while (true)
{
int *p = new int[1024 * 1024];
if (p)
{
cout << p << endl;
}
else
{
cout << "申请失败" << endl;
break;
}
}
}
/*当出现异常后,异常直接被抛出,new的异常类型为exception*/
catch (exception& e)
{
cout << e.what() << endl;
}
return 0;
}
3.operator new和operator delete函数
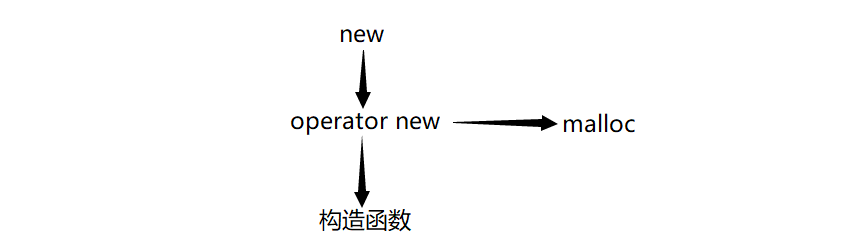
这里我们需要注意了,operator new和operator delete算是C++的一个坑(以后还有大坑、巨坑、天坑),因为operator new和operator delete它们不是运算符重载,它们就是一个在C++库当中的定义的全局函数,new在底层会调用operator new函数来申请空间,delete会在底层调用operator delete函数来释放空间。
我们已经知道了new会申请空间然后调用构造函数,所以new有两层机制,一是开辟空间,而是调用构造函数。而开辟空间是通过调用operator new得到的,而operator new在底层又会调用malloc:
我们截取一段operator new函数实现的代码:
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{
void *p;
/*调用malloc申请空间*/
while ((p = malloc(size)) == 0)
if (_callnewh(size) == 0)
{
/*如果申请失败,抛异常*/
static const std::bad_alloc nomem;
_RAISE(nomem);
}
return (p);
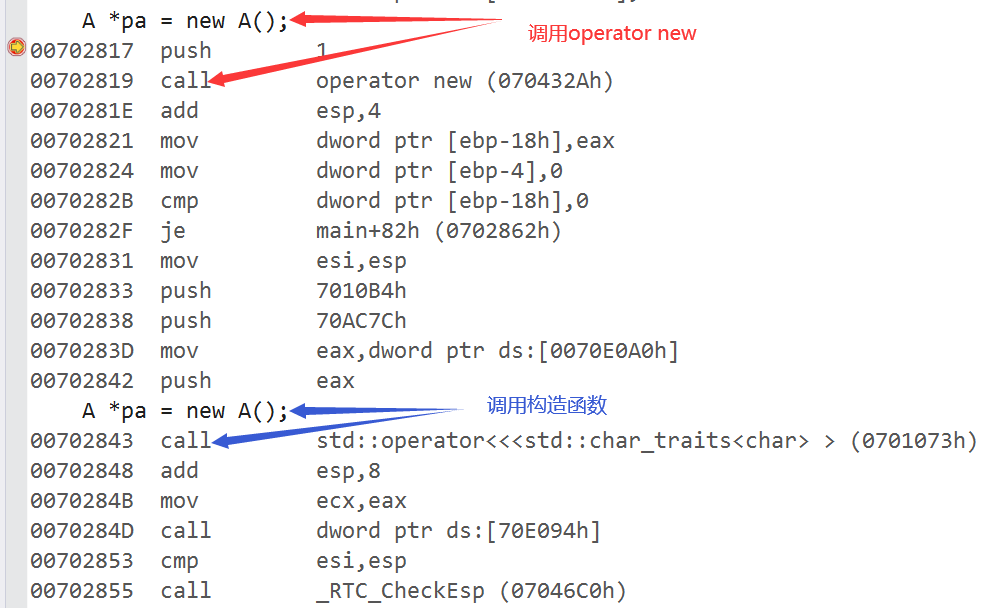
}我们以一个简单的程序为例,并观察它的反汇编:
class A
{
public:
A()
{
cout << "A()" << endl;
}
};
int main()
{
A *pa = new A();
return 0;
}
因为operator new是一个全局的函数,那么这就意味着我们可以直接调用它:
int main()
{
A *pa = (A *)operator new(sizeof(A));
return 0;
}那么同理,delete的底层也有两层,一是调用析构函数,二是调用operator delete释放空间,而operator delete又会调用free:
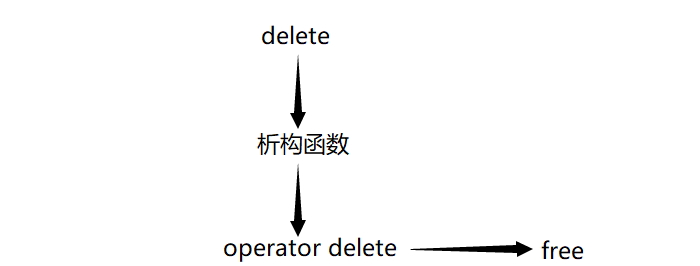
我们截取一段operator delete函数的实现代码:
#define free(p) _free_dbg(p, _NORMAL_BLOCK)
void operator delete(void *pUserData)
{
_CrtMemBlockHeader * pHead;
RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));
if (pUserData == NULL)
return;
_mlock(_HEAP_LOCK); /* block other threads */
__TRY
/* get a pointer to memory block header */
pHead = pHdr(pUserData);
/* verify block type */
_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));
/*调用free*/
_free_dbg(pUserData, pHead->nBlockUse);
__FINALLY
_munlock(_HEAP_LOCK); /* release other threads */
__END_TRY_FINALLY
return;
}我们以一个简单的程序为例,并观察其反汇编:
class A
{
public:
A()
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
};
int main()
{
A *pa = new A();
delete pa;
return 0;
}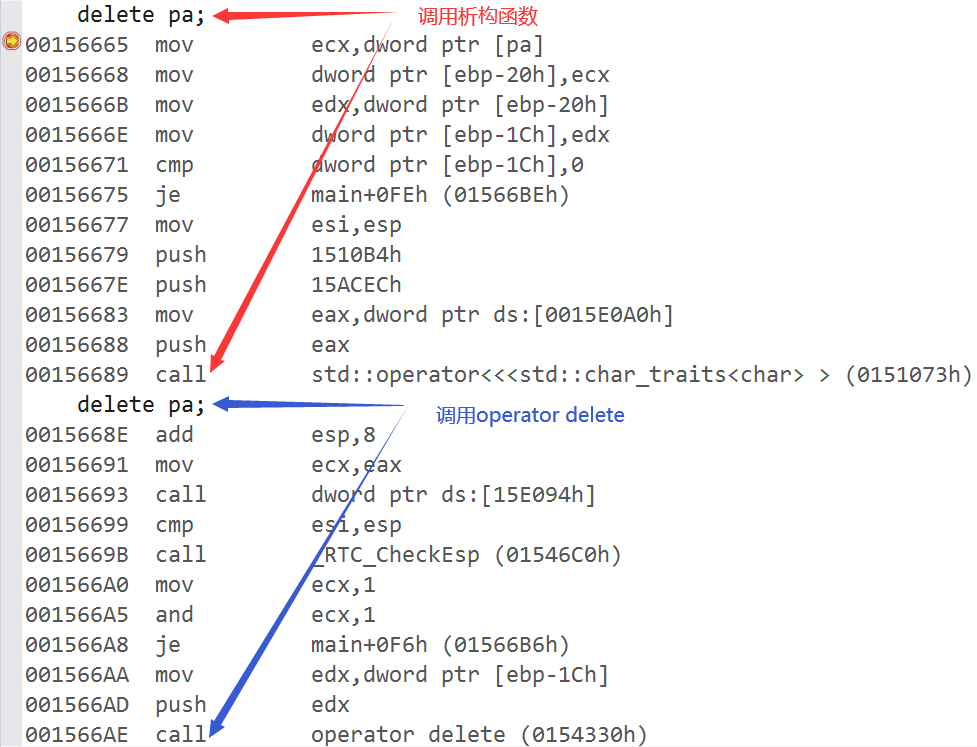
那么对于delete和free的错误处理方式基本上一样,那就是运行时报错,即程序崩溃。
3.1new和delete的实现原理
其实对于内置类型来说,new和malloc之间、delete和free之间没有太大差别,唯一的差别在于new开辟空间失败时会抛异常。
实际上最大的差别还是在于自定义类型:
1.new的原理:调用operator new申请空间;在申请的空间上执行构造函数
2.delete的原理:在空间上执行析构函数;调用operator delete函数释放空间
3.new []的原理:首先会调用operator new[],然后operator new[]又会调用operator new申请一块连续的空间;然后在这块连续的空间上执行多次构造函数
4.delete []的原理:在空间的上执行多次析构函数;调用oeprator delete[],然后operator delete[]又会调用operator delete释放一块连续的空间
4.定位new表达式
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。首先我们要知道构造函数不能显式调用,但是析构函数可以显式调用。那么malloc()开辟的空间不会调用构造函数,这就意味着我们在此之后不能显式调用构造函数,但是如果我们使用定位new表达式,可以做到显式调用构造函数:
class A
{
public:
A()
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
};
int main()
{
/*使用malloc()开辟的空间没有调用构造函数*/
A *pa = (A *)malloc(sizeof(A));
/*使用定位new表达式显式调用构造函数*/
new(pa)A();
/*delete则正常按照规则执行*/
delete pa;
return 0;
}
那么这种类似于"多此一举"的定位new表达式的应用场景是什么?实际上是配合内存池使用的。那么什么是内存池呢?内存池是一种内存池化技术,能够提高申请内存空间的效率。通俗一点来说,无论是使用malloc()还是new,它们的本质都是在堆上申请一块空间,但是从某种意义来说,内存上面的堆距离进程比较"远",并且内存上的堆是所有进程共享的,这就可能会造成申请空间时需要"排队"。那么池化技术就是空间开辟到离进较"近"的一个地方,作为一个内存池,进程需要动态申请空间时,不需要跑去堆上申请,只需要向内存池申请即可,这个内存池可以是进程单独占用。那么用一个例子来说就是在一座山上有很多户人家,山下有一条小溪,这条小溪是全村人的生命之源,那么村里这些每家每户都要去山下挑水,这就有两个问题,第一个是太远了,第二个是全村人共用,还得排队,所以有一户人家在自己家门口建了一个蓄水池,拉了一根水管到小溪里,蓄水池直接从小溪里面抽水上来,那么这家人就再也不用去山下的小溪挑水了,只需要在家门口的蓄水池打水就行了。
那么STL就是用内存池化技术,因为STL认为C/C++原生的内存管理机制不够高效,但是毕竟不是直接从堆上申请空间,所以在"动态开辟"时使用的方法就不是new或者malloc()了,而是自己的一套体系。那么自定义的体系可不会像编译器那么聪明会自动调用构造函数,所以向内存池内存申请空间时,得到的空间是未初始化的,所以需要定位new表达式。

5.常见面试题
5.1malloc、free和new、delete的区别
malloc、free和new、delete的共同点是:都是从堆上申请空间,并且需要显式释放空间。不同点在于:
1.malloc和free是函数,new和delete是以关键字形式存在的操作符
2.malloc申请的空间不会初始化,new会自动调用构造函数(申请自定义类型空间)
3.malloc申请空间时,需要明确计算空间大小并作为实参传递;new只需要指定空间类型以及个数即可
4.malloc的返回值类型为void*,使用时必须作强转;new不需要
5.malloc申请空间失败时,返回空指针,因此在使用空间之前要先做判断;new不需要作返回值判断,但是new申请空间失败时会抛异常
6.free不会调用析构函数;delete会先调用析构函数再释放空间
5.2内存泄漏
什么是内存泄漏:当我们动态开辟一块空间后,当这块空间不再需要使用时,可能由于疏忽、大意、错误导致未释放这块空间的情况。内存泄漏并不是说物理内存空间凭空消失,而是进程长期占用这块动态开辟的空间而不使用,而其他进程无权访问这块空间造成的内存浪费。
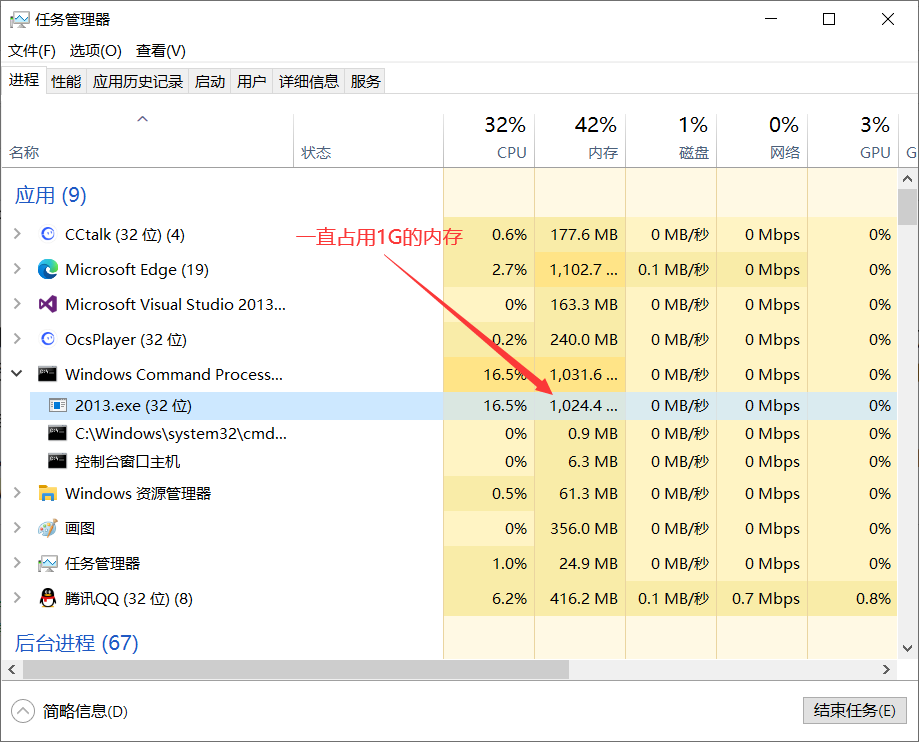
内存泄漏的危害:长期运行、永不终止的程序出现内存泄漏时影响是非常大的,例如操作系统、后台服务进程等等,出现内存泄漏之后会导致响应变慢、甚至卡死的情况。上面也说过,如果动态申请了一块内存,但是这个程序会马上退出,那么释放不释放这块空间已经无所谓了,因为程序退出时会将所占的资源全部归还给操作系统。我们举一个简单的例子来说明哪种程序一定要防止内存泄漏:
int main()
{
char *pa = new char[1024 * 1024 * 1024];
/*该程序永不退出并且不释放pa指向的空间
*那么就会导致内存泄漏*/
while (1)
{}
return 0;
}
内存泄漏的分类一般分为两种:
1.堆内存泄漏:这种情况就是new或malloc出来的堆内存空间忘记释放导致的内存泄漏
2.系统资源泄漏:例如程序当中建立了套接字、打开了文件等等,我们忘记将该资源释放掉,也会造成系统资源泄漏
避免内存泄漏的方法:
1.养成良好的设计规范
2.采用RAII的思想或C++11提供的智能指针来管理动态资源
3.有些公司内部规范使用内部实现的私有内存管理库
4.使用内存泄漏工具检测





![NSSCTF [suctf 2019]hardcpp WP 控制流混淆](https://img-blog.csdnimg.cn/831c28f32ed641a5b6b956c8d5ec09b2.png)