文章目录
- 一、MyBatis是什么
- 二、学习 MyBatis 的意义
- 三、配置 MyBatis 开发环境
- (一)配置 MyBatis 的相关依赖
- (二)配置数据库连接字符串和 MyBatis(保存的 XML 目录)
- 1. 创建并编辑配置文件
- 2. 配置 MyBatis 的 XML 文件
- 四、使用 MyBatis 操作数据库
- (一)创建实体类
- (二)创建接口
- (三)创建 XML 实现接口
- 1. 创建 XML 文件
- 2. 实现接口
- (四)执行 sql 语句
- 1. 添加服务层 service 代码
- 2. 添加控制层 controller 代码
- 3. 启动服务器,进行代码测试
- (五)MyBatis SQL 日志打印
- (六)单元测试
- 五、增删改操作
- (一)修改操作
- (二)删除操作
- (三)新增操作
- 六、参数占位符 #{} VS ${}
- (一)二者的定义
- (二)二者的区别以及适用场景
- 七、查询操作
- (一)单表查询
- (二)多表查询
- 1. 返回类型:resultType
- 2. 返回字典映射:resultMap
- 3. 多表查询
- (1)一对一的表映射
- (1)一对多和多对多的表查询
- 八、动态 SQL 使用
- (一)<if>标签
- (二)<trim>标签
- (三)<where> 标签
- (四)<set> 标签
- (五)<foreach> 标签
一、MyBatis是什么
百度百科:MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java对象)映射成数据库中的记录
简单来说,MyBatis 是更简单完成程序和数据库交互的工具,也就是更简单的操作和读取数据库的工具。MySQL和MyBatis绝对不一样,一个是数据持久化软件,一个是连接程序和软件的工具
二、学习 MyBatis 的意义
对于后端开发来说,唯二重要的东西就是后端程序和数据库,要实现这二者的连接,我们就需要依赖数据库连接工具,比如 JDBC,还有今天的 MyBatis,而 MyBatis 相对 JDBC 来说,要方便太多,JDBC 的操作流程很麻烦,大致可以分为以下几步:
- 创建数据库连接池 DataSource
- 通过 DataSource 获得数据库连接 Connection
- 编写带 ? 占位符的 sql 语句
- 通过 Connection 和 sql 语句生成操作命令对象 Statement
- 使用传过来的参数替换掉要占位符
- 使用 Statement 执行 sql 语句
- 如果是查询,还要获得 Statement 查询返回的结果集
- 处理结果集
- 释放资源
上述操作在我们执行一条sql语句时几乎都要走一遍,太繁琐,因此我们才要学习 MyBatis
三、配置 MyBatis 开发环境
MyBatis 也是⼀个 ORM 框架,ORM(Object Relational Mapping),即对象关系映射。在⾯向对象编程语⾔中,将关系型数据库中的数据与对象建⽴起映射关系,进⽽⾃动的完成数据与对象的互相转换,就很类似获取json数据的过程:
- 将输⼊数据(即传⼊对象)+ SQL 映射成原⽣ SQL
- 将结果集映射为返回对象,即输出对象
ORM 把数据库映射为对象:
- 数据库表(table)–> 类(class)
- 记录(record,⾏数据)–> 对象(object)
- 字段(field) --> 对象的属性(attribute)
⼀般的 ORM 框架,会将数据库模型的每张表都映射为⼀个 Java 类。
也就是说使⽤ MyBatis 可以像操作对象⼀样来操作数据库中的表,可以实现对象和数据库表之间的转换
(一)配置 MyBatis 的相关依赖
我们先创建一个 Spring Boot 项目,流程和前面一样,唯一的区别就是在添加依赖时需要多添加两项,一个 MyBatis 依赖,一个 MySQL 驱动
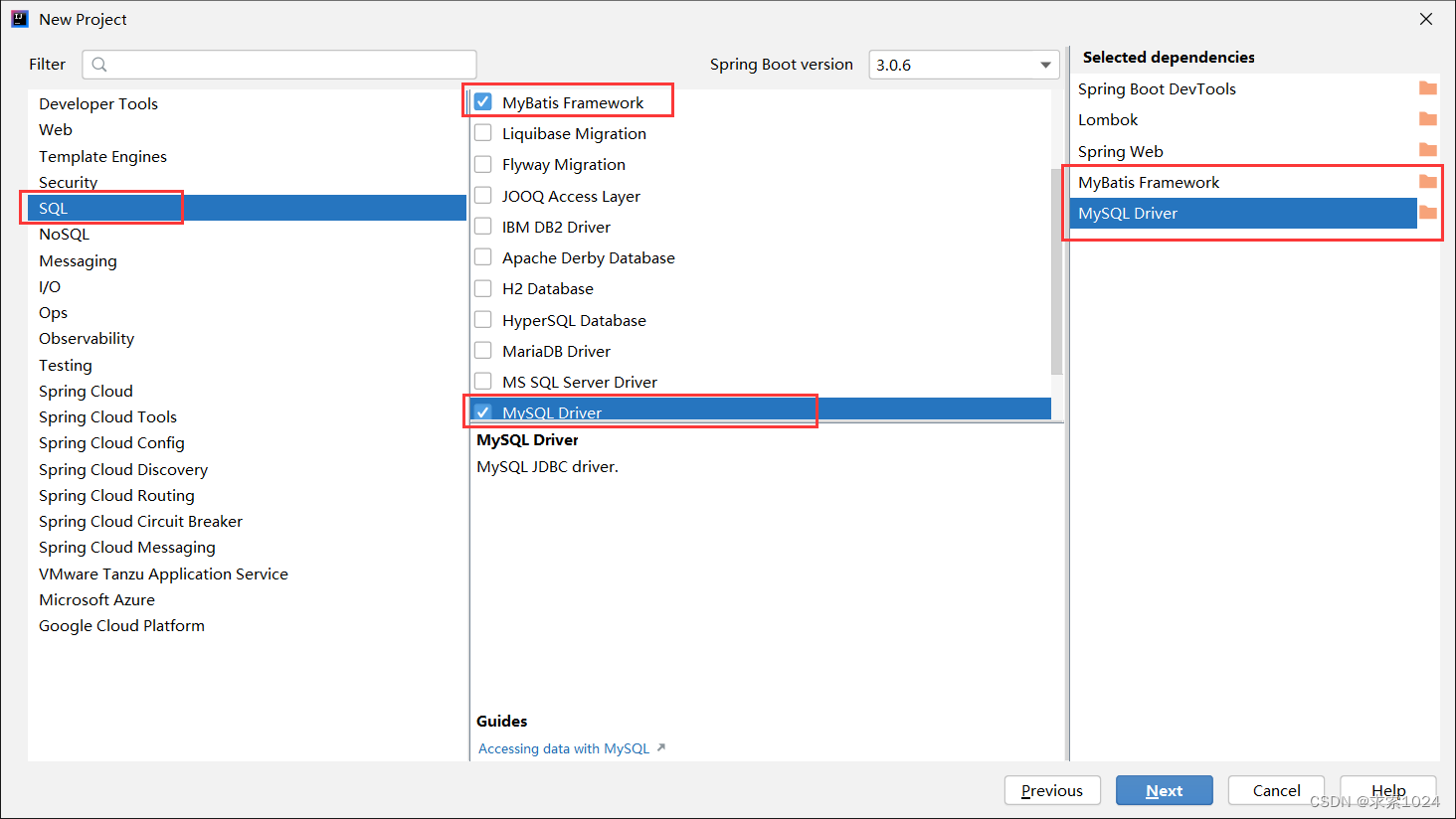
老的项目通过Edit Starters添加依赖即可
(二)配置数据库连接字符串和 MyBatis(保存的 XML 目录)
1. 创建并编辑配置文件
- 创建配置文件
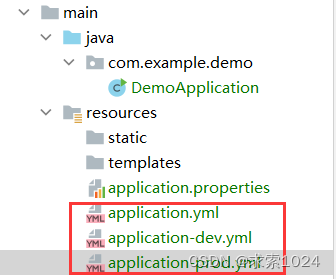
- 在公共配置文件中规定当前环境的配置文件
# 规定当前环境使用的配置文件
spring:
profiles:
# 使用开发环境的配置文件
active: dev
- 在开发环境和生产环境的配置文件中设置
由于现在还不涉及生产环境,因此我们这里只对开发环境进行配置,生产环境类似。注意:username 和 password 的值必须加引号,否则连接不上
# 配置数据库的连接信息
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/数据库名?characterEncoding=utf8&useSSL=false
username: "root"
password: "自己数据库的密码"
# 设置驱动名称
# 8.0以前不加.cj
driver-class-name: com.mysql.cj.jdbc.Driver
2. 配置 MyBatis 的 XML 文件
- 创建目录
MyBatis 的 XML 文件属于资源文件,因此应该放在 resources目录下,又因为以后 XML 文件以后将会有很多个,因此我们需要创建一个文件夹统一管理
- 在公共配置文件中配置 MyBatis 的 XML 文件保存路径
# 配置 MyBatis 的 XML 文件保存路径
mybatis:
# classpath表示从程序的根目录开始
# mybatis就是保存 xml 文件的包
# **Mapper.xml 规定了 MyBatis 的 xml 文件名
mapper-locations: classpath:mybatis/**Mapper.xml
四、使用 MyBatis 操作数据库
经过上述的操作,我们就可以正式的使用 MyBatis 操作数据库
在操作之前,我们需要了解一下 MyBatis 的操作模式,那就是:方法定义接口 + .xml方法实现 -> 生成可执行 sql,执行 sql 并将结果映射到程序对象中
(一)创建实体类
实体类是看着上面我们创建的数据表来定义的,数据表的表名就是实体类的类名,类中的属性名就对应着数据表中的字段,最后加上@Data注解,搞定
(二)创建接口
这里的接口和普通的接口没有一点区别,只是我们为了方便管理,建议把这些接口放到一个单独的文件夹下,然后创建接口,编写方法,如下图所示:
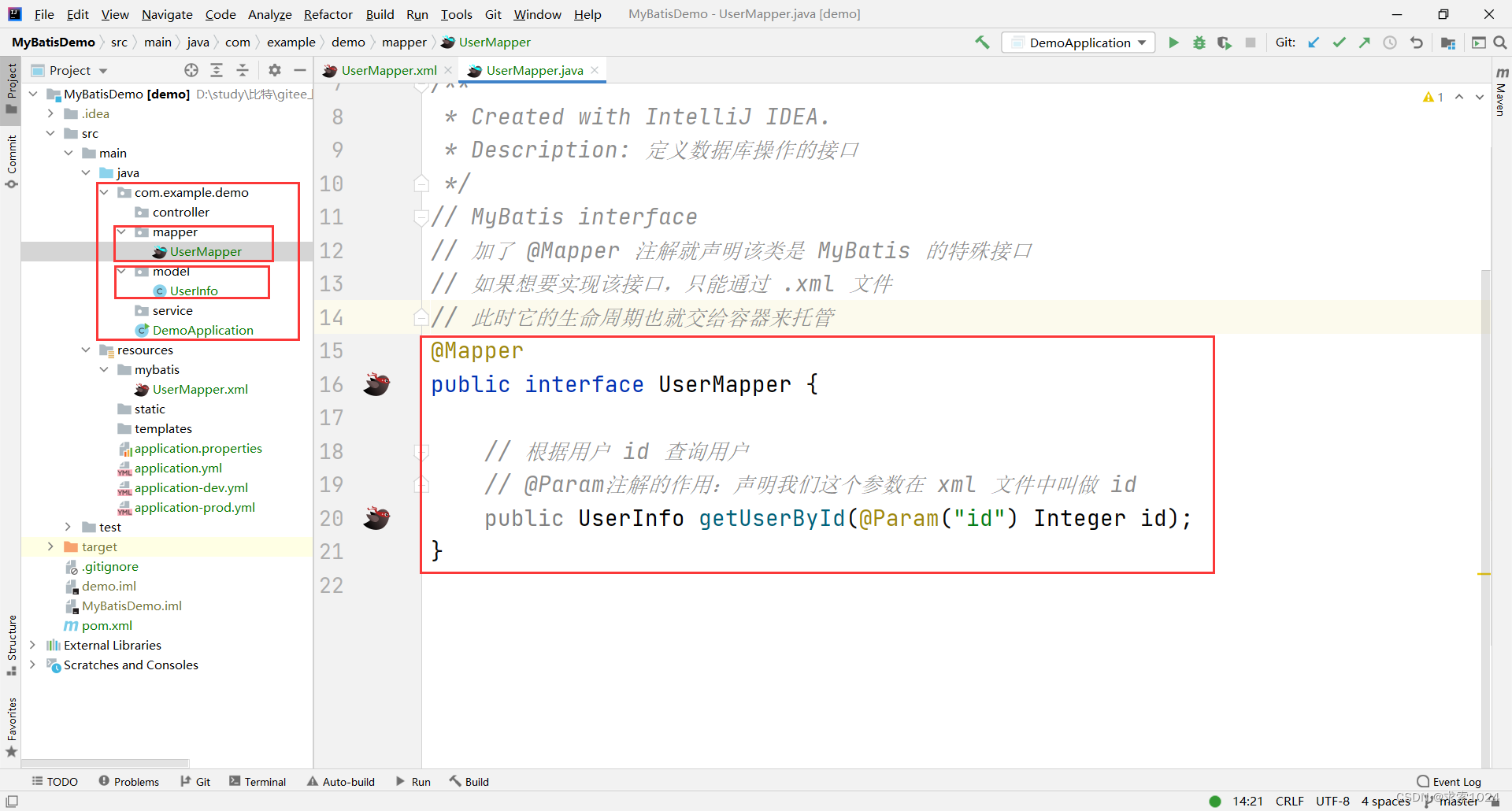
代码示例:
@Mapper
public interface UserMapper {
// 根据用户 id 查询用户
public UserInfo getUserById(@Param("id") Integer id);
}
@Mapper 注解的意义在于,告诉项目这个接口是 MyBatis 的特殊接口,必须通过 .xml 文件来实现,此时它的生命周期就会交给容器来托管
@Param注解的作用:声明我们这个参数在 xml 文件中叫做 id;作者的电脑上不加是可以的,但是不是所有电脑都可以,因此建议全部加上
(三)创建 XML 实现接口
1. 创建 XML 文件
在 mybatis 文件夹下创建 xml 文件,建议文件名跟接口名保持一致,这样我们一看就知道它们是一一对应的,当然,这么做的前提是我们在之前配置文件中声明的 xml 文件名合适,配置后的结果如图:
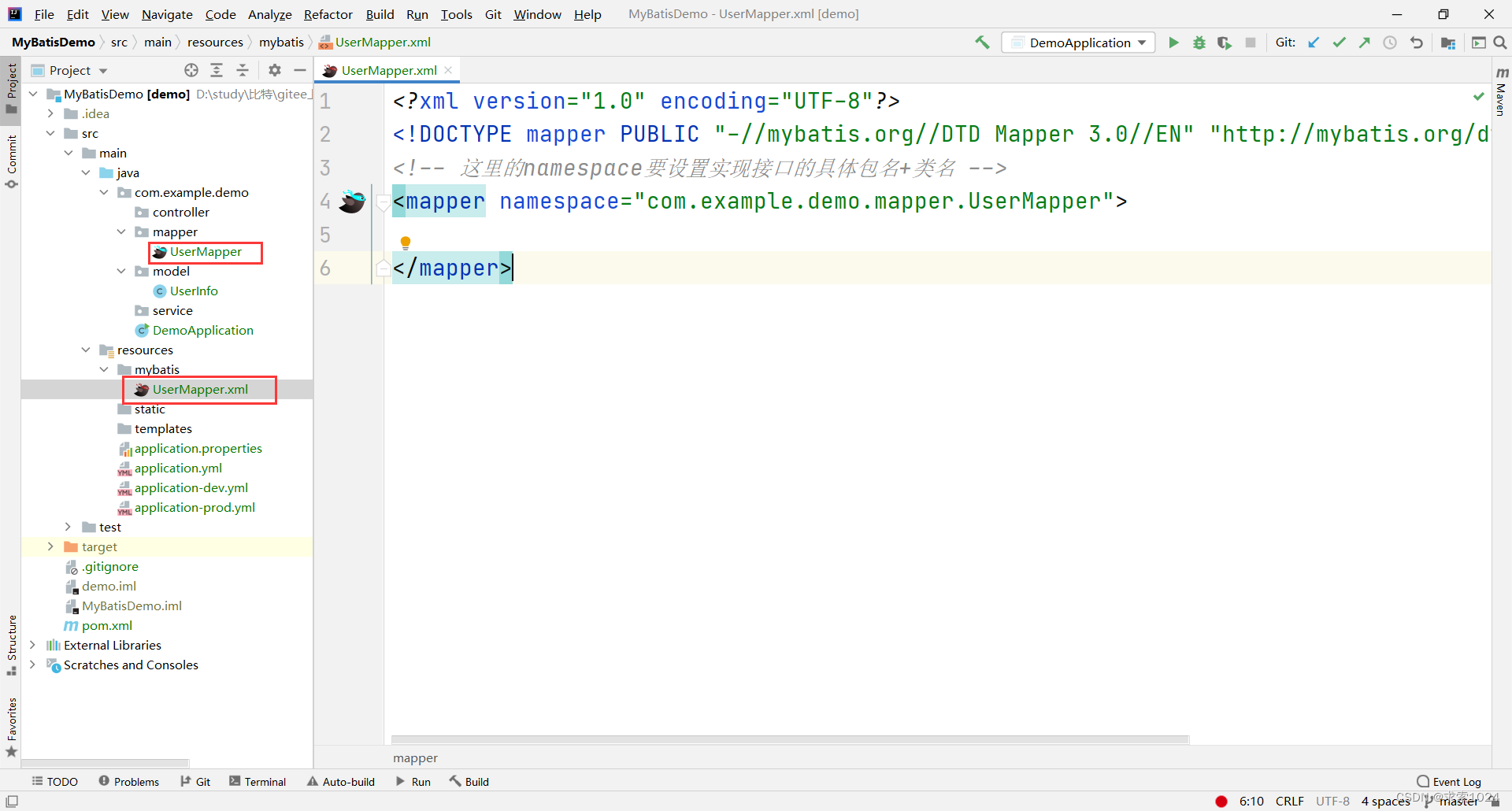
图片中有两点需要进行说明:
- xml文件中的标签是固定的,只需要对
namespace进行设置即可,因此我们不需要记住,只需要放到一个自己容易找到的地方即可,作者把代码放到了下面; - 左侧的燕子是一个插件,可以快速的找到接口中的方法在 xml 文件中实现的位置,反过来也是;而且还能帮助我们自动生成代码,但是需要我们进行手动配置

xml文件固定代码:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 这里的namespace要设置实现接口的具体包名+类名 -->
<mapper namespace="com.example.demo.mapper.UserMapper">
</mapper>
插件配置过程:
2. 实现接口
接口实现起来非常简单,如下方代码所示:
<select id="getUserById" resultType="com.example.demo.model.UserInfo">
select * from userinfo where id=${id}
</select>
图示:
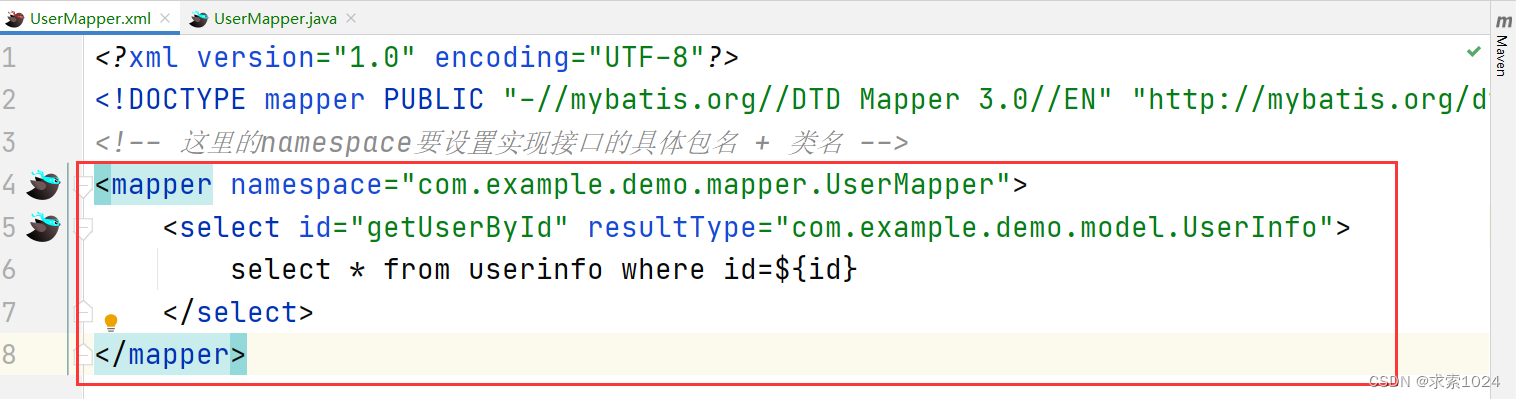
注意事项:
- 所有语句都是写在 mapper 标签中的
- 标签中的 id 就对应着接口的方法名
- 标签中的 resultType 表示返回结果的类型
- 中间写 sql 语句,可以不加";"
- 替换符可以使用"#{}“,也可使用”${}",中间的是方法参数在 xml 文件中的标识
(四)执行 sql 语句
1. 添加服务层 service 代码
关于为什么要有 service 这一层,作者在这里写一些自己的理解:mapper层(即dao层)是一个一个的sql执行语句,直接和数据库打交道,而 controller 层是发出一道操作数据的命令,可以类比成我们做相关 sql 题时的题目,controller 层说我就要实现这上面的需求,可是一个需求一个 sql 语句不一定能够实现,可能需要好几条,如果没有 service 层,那么 controller 层就需要自己操作,这样的话整体代码太过复杂,后期也不方便维护,因此拜托 service 层,由它来调用多条 sql 语句,获取最终执行结果,最后返回给 controller 层,相当于 controller 层只负责发布命令和等待结果就好,一方面降低了代码的复杂度,另一方面也使得功能和具体实现解耦,service 层的代码可以重复利用
代码示例:
@Service
public class UserService {
// 将 MyBatis 的 UserMapper 接口注入进来
@Autowired
private UserMapper userMapper;
public UserInfo getUserById(Integer id) {
return userMapper.getUserById(id);
}
}
2. 添加控制层 controller 代码
代码示例:
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@RequestMapping("/getuserbyid")
public UserInfo getUserById(Integer id) {
if(id == null) {
return null;
}
return userService.getUserById(id);
}
}
3. 启动服务器,进行代码测试
测试结果:

恭喜!!!我们实现了从0到1的一个跨越!
(五)MyBatis SQL 日志打印
该操作可以用于 MyBatis 的 sql 日志打印,是为了方便我们开发时查看最后执行的 sql,便于排查问题
'具体开启方式是在我们的配置文件中进行设置,由于这个功能我们往往开发时才会用到,因此选择设置在开发的配置文件;另一方面,由于 sql 日志打印等级在 info 之下,因此我们需要首先将日志打印等级降低到 debug
日志打印等级设置:
logging:
level:
com:
example:
demo: debug
MyBatis 设置日志打印的代码是固定的:
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImp
运行测试:
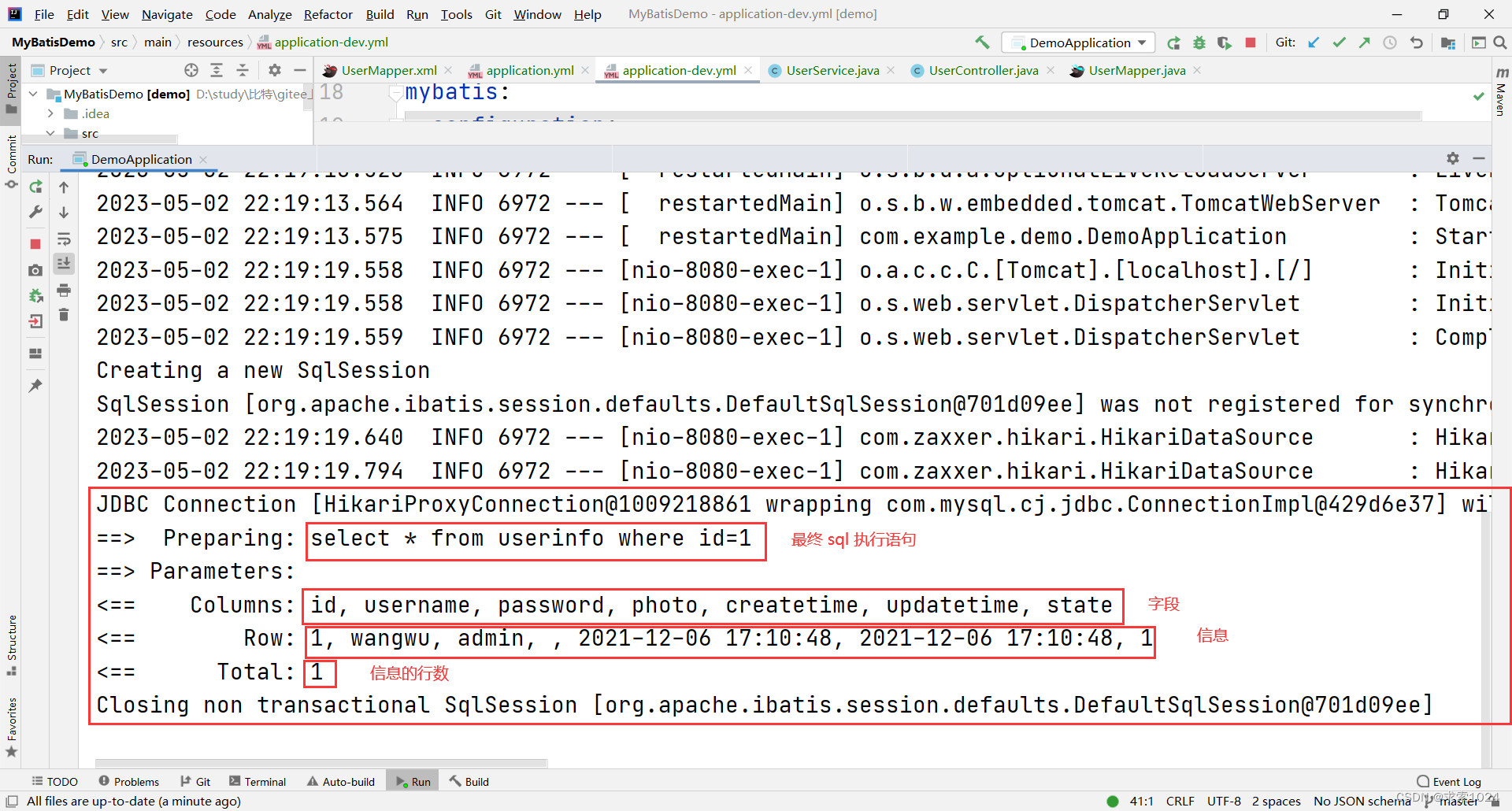
通过上述日志打印,我们就能很直观的看出最终拼成的 sql 语句和查询结果
(六)单元测试
我们看到上述的测试需要建 service 层代码,controller 层代码,如果每次建的话,就显得很麻烦,因此这里作者推荐使用单元测试对它的功能进行测试,具体请参考这篇博客:
五、增删改操作
(一)修改操作
修改操作在方法定义和实现具体代码上,有很多的细节需要注意:
- 修改操作的返回值只有一个影响的行数,因此我们的方法返回值可以写成 int;
- update 不需要写 resultType 参数,还是因为它只返回一个受影响的行数
- 字符串的替换符格式必须用 #{},不允许用 ${},主要是为了防止 sql 注入,具体解释放在下面
- 使用 #{} 作为字符串的替换符时,不需要在替换符外面加上引号,MyBatis 会自动进行添加
代码实现:
// 根据用户 id 修改用户的用户名
public int updateNameById(@Param("id") Integer id,
@Param("username") String username);
<!-- 根据用户 id 修改用户名 -->
<!-- update 不需要写 resultType -->
<update id="updateNameById">
<!-- 修改操作替换符格式建议用 #{} -->
update userinfo set username = #{username} where id = #{id};
</update>
(二)删除操作
逻辑删除操作就是修改操作,这里的删除操作指的是物理删除,也和修改操作基本一致,只是实现的标签有些不同,代码如下:
接口代码:
// 根据用户 id 删除用户信息
public int deleteUserById(@Param("id") Integer id);
xml代码:
<!-- 根据用户 id 删除用户信息 -->
<delete id="deleteUserById">
delete from userinfo where id = #{id};
</delete>
Test代码:
@Test
@Transactional
void deleteUserById() {
int result = userMapper.deleteUserById(2);
Assertions.assertEquals(1, result);
}
(三)新增操作
增加数据的操作要比修改删除的操作稍微复杂一些,主要体现在我们添加一个对象时,该如何拿到对象里面的值,以及是该返回受影响的行数还是返回新增成功的id
- 新增的接口方法
这里传对象时不必加 @Param 注解了
方式一:返回受影响的行数
// 新增一条数据,返回受影响的行数 / 新增成功之后的 id
public int addUser(UserInfo userInfo);
方式二:返回自增主键生成的 id
// 不需要返回,会直接填写到我们传的对象属性中
public void addUser2(UserInfo userInfo);
- xml代码实现
传过来的是一个对象,但是并不需要我们做什么设置,可以直接使用对象中的属性名来作为替换符的值,系统回自动识别
方式一:返回受影响的行数
<!-- 新增用户,并返回受影响的行数 -->
<insert id="addUser">
insert into userinfo (username, password, photo)
values (#{username}, #{password}, #{photo})
</insert>
方式二:返回新增成功之后的 id 值,该方式比较特殊,需要设置三个属性值:
- useGeneratedKeys=“true” ,这个属性值表示是否自动生成主键
- keyProperty=“id”,该属性表示将自动生成的主键赋值到我们传的对象中哪个属性上
- keyColumn=“id”,该属性是声明生成的键值在表中的字段名,在某些表中,如果主键不是第一列的话,那么这个属性是必须设置的,如果生成列不止一个,可以用逗号分隔多个字段名称
<!-- 新增用户,并返回自增的主键 id -->
<insert id="addUser2" useGeneratedKeys="true" keyProperty="id" keyColumn="id">
insert into userinfo (username, password, photo)
values (#{username}, #{password}, #{photo})
</insert>
- Test代码实现:
方式一:
@Test
@Transactional
void addUser() {
UserInfo userInfo = new UserInfo();
userInfo.setUsername("lihua");
userInfo.setPassword("111");
userInfo.setPhoto("");
int result = userMapper.addUser(userInfo);
Assertions.assertEquals(1, result);
}
方式二:
@Test
@Transactional
void addUser2() {
UserInfo userInfo = new UserInfo();
userInfo.setUsername("lihua");
userInfo.setPassword("111");
userInfo.setPhoto("");
System.out.println("添加之前的Id:" + userInfo.getId());
userMapper.addUser2(userInfo);
System.out.println("添加之后的Id:" + userInfo.getId());
Assertions.assertNotNull(userInfo.getId());
}
方式二运行结果:
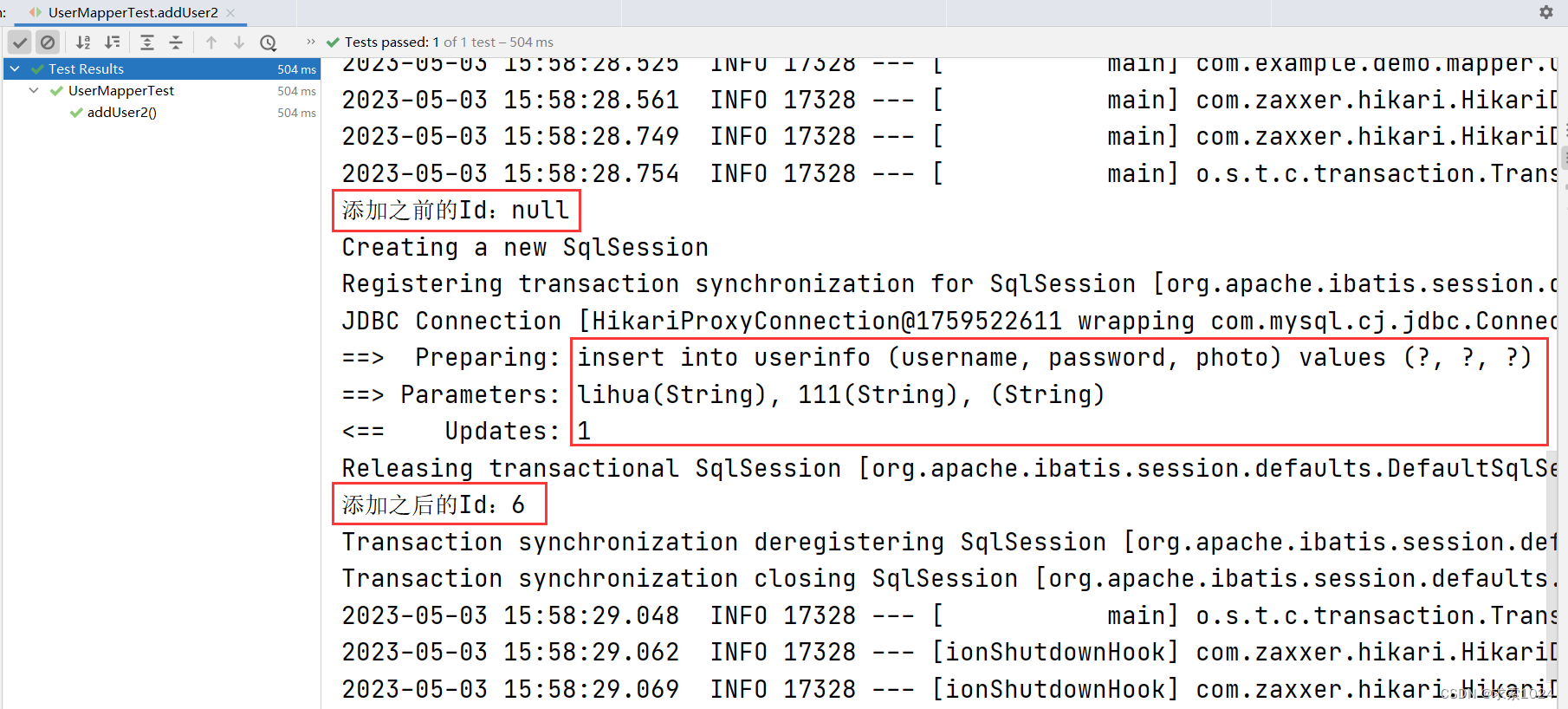
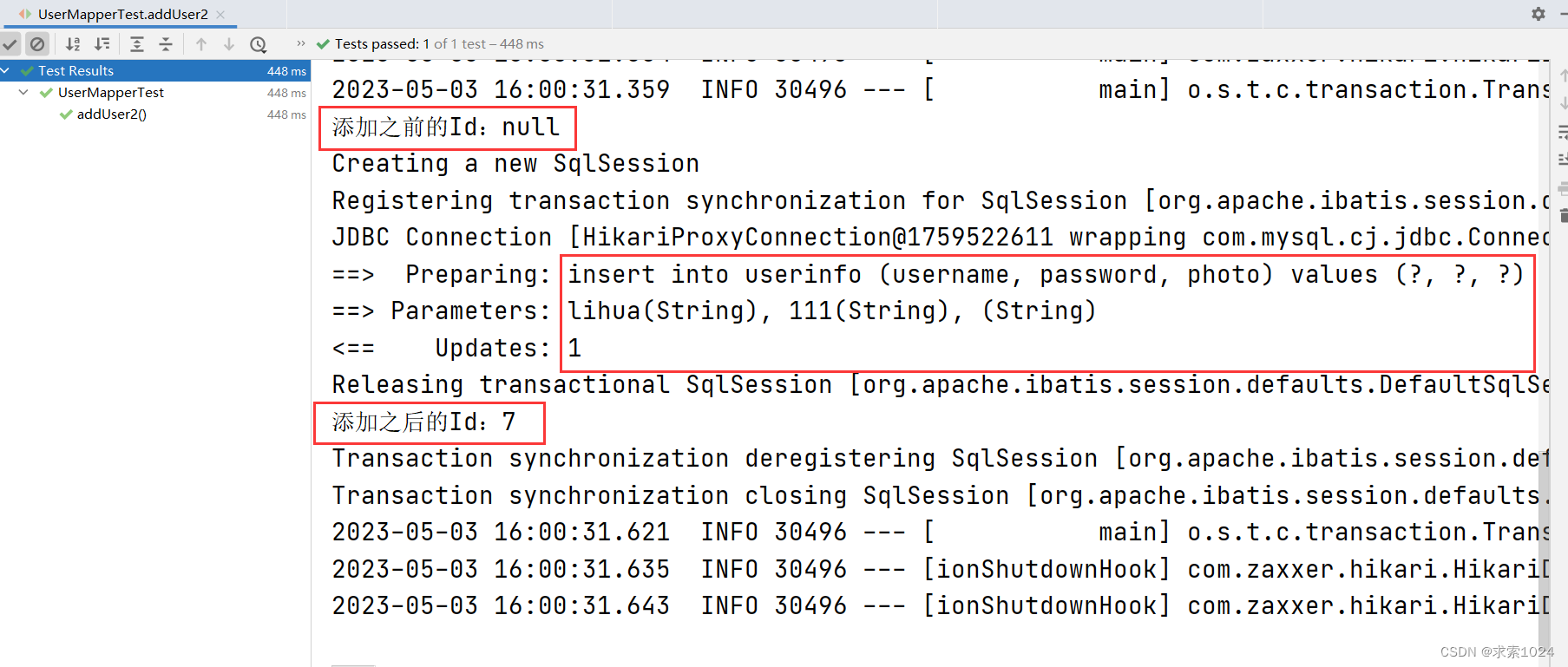
注意,由上述两张图对比我们可以看出,虽然事务回滚,数据并没有添加成功,但是主键 id 仍然会自增,这是 InnoDB 的特性,问题不大
六、参数占位符 #{} VS ${}
(一)二者的定义
1. #{}:预编译处理
预编译处理是指 MyBatis 在处理 #{} 时,会将 SQL 中的 #{} 替换为 ? 号,调用 PreparedStatement 的 set 方法来赋值
2. ${}:字符直接替换
字符直接替换是指 MyBatis 在处理 ${} 时,就把 ${} 替换成变量的值
(二)二者的区别以及适用场景
二者的特点与区别
1. #{}
#{}由于底层调用 PreparedStatement 的 set 方法来替换参数,此方法会获取传递进来的参数的每个字符,然后进行循环对比,如果发现有敏感字符(如:单引号、双引号等),则会在前面加上一个’/'代表转义此符号,让其变为一个普通的字符串,不参与SQL语句的生成,达到防止SQL注入的效果
其次,#{}在使用时,会根据传递进来的值来选择是否加上双引号,因此我们传递参数的时候一般都是直接传递,不用加双引号

**2. KaTeX parse error: Expected 'EOF', got '&' at position 6: {}** &̲emsp; {} 是直接进行字符串拼接的,不会比对,也不会判断参数是什么类型,更不会自动加双引号

二者的适用场景:
1. #{}
由于 #{} 可以防止 SQL 注入的问题,因此我们说,在传入的参数是字符串时,都建议使用 #{}
sql 注入示例:
${}示例
<select id="login" resultType="com.example.demo.model.UserInfo">
select * from userinfo where
username = '${username}' and password = '${password}';
</select>
测试代码
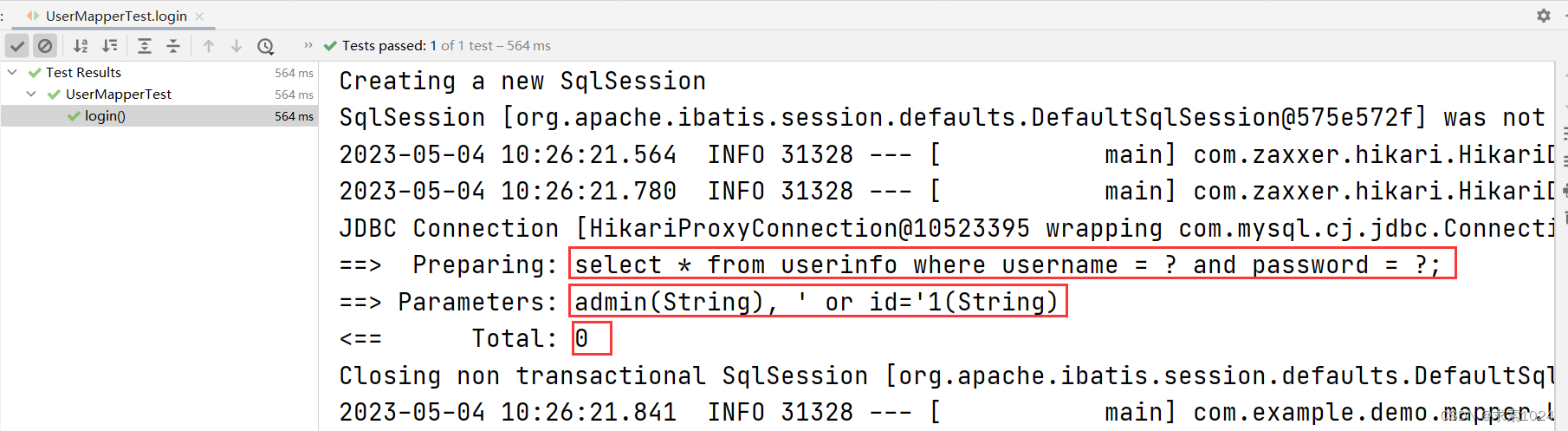
@Test
void login() {
String username = "admin";
String password = "' or id='1";
UserInfo userInfo = userMapper.login(username, password);
log.info("用户信息:" + userInfo);
// Assertions.assertEquals(1, userInfo.getId());
}
运行结果:
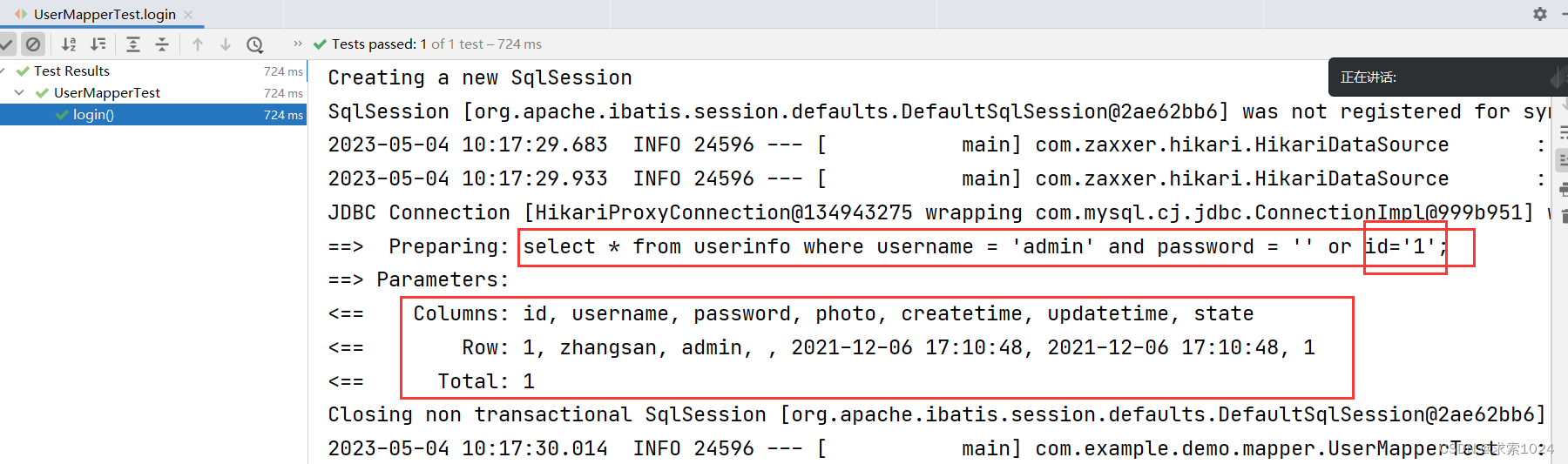
替换为 #{} 之后
<select id="login" resultType="com.example.demo.model.UserInfo">
select * from userinfo where
username = #{username} and password = #{password};
</select>
运行结果:
**2. KaTeX parse error: Expected 'EOF', got '&' at position 6: {}** &̲emsp; {} 虽然不能防止 SQL 注入,但是它存在也有它存在的意义。例如我们对某一列进行排序时,我们是要使用 asc/desc ,此时如果加上引号,就会导致 sql 错误,此时 #{} 就无法使用了;因此我们说当传递的是一个 SQL 关键字(命令)的时候,只能使用 ${},此时为了安全,我们必须把它的值限定死,防止 SQL 注入
接口代码示例:
// 对用户信息按照创建时间进行排序
public List<UserInfo> getUserSort(@Param("order") String order);
xml实现:
<select id="getUserSort" resultType="com.example.demo.model.UserInfo">
select * from userinfo order by createtime ${order}
</select>
测试代码实现:
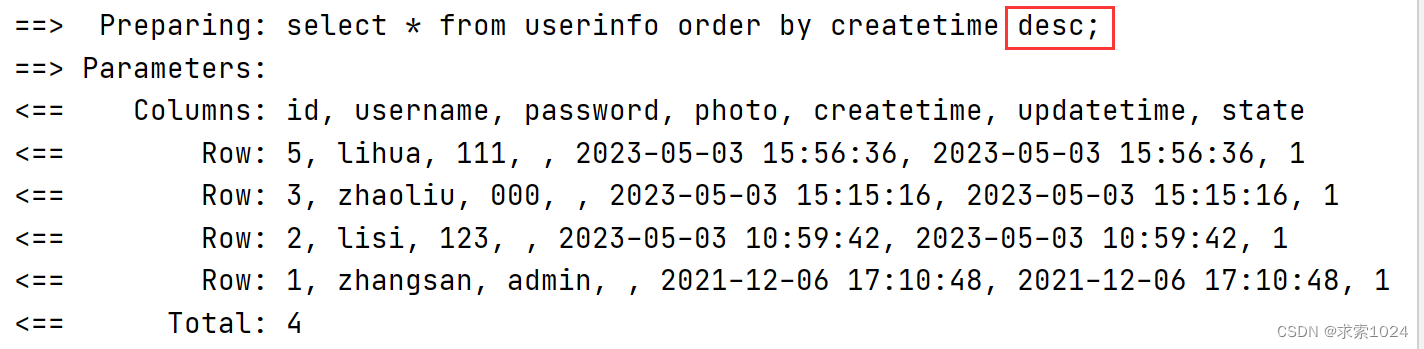
@Test
void getUserSort() {
List<UserInfo> list = userMapper.getUserSort("desc");
Assertions.assertNotNull(list);
}
测试结果:
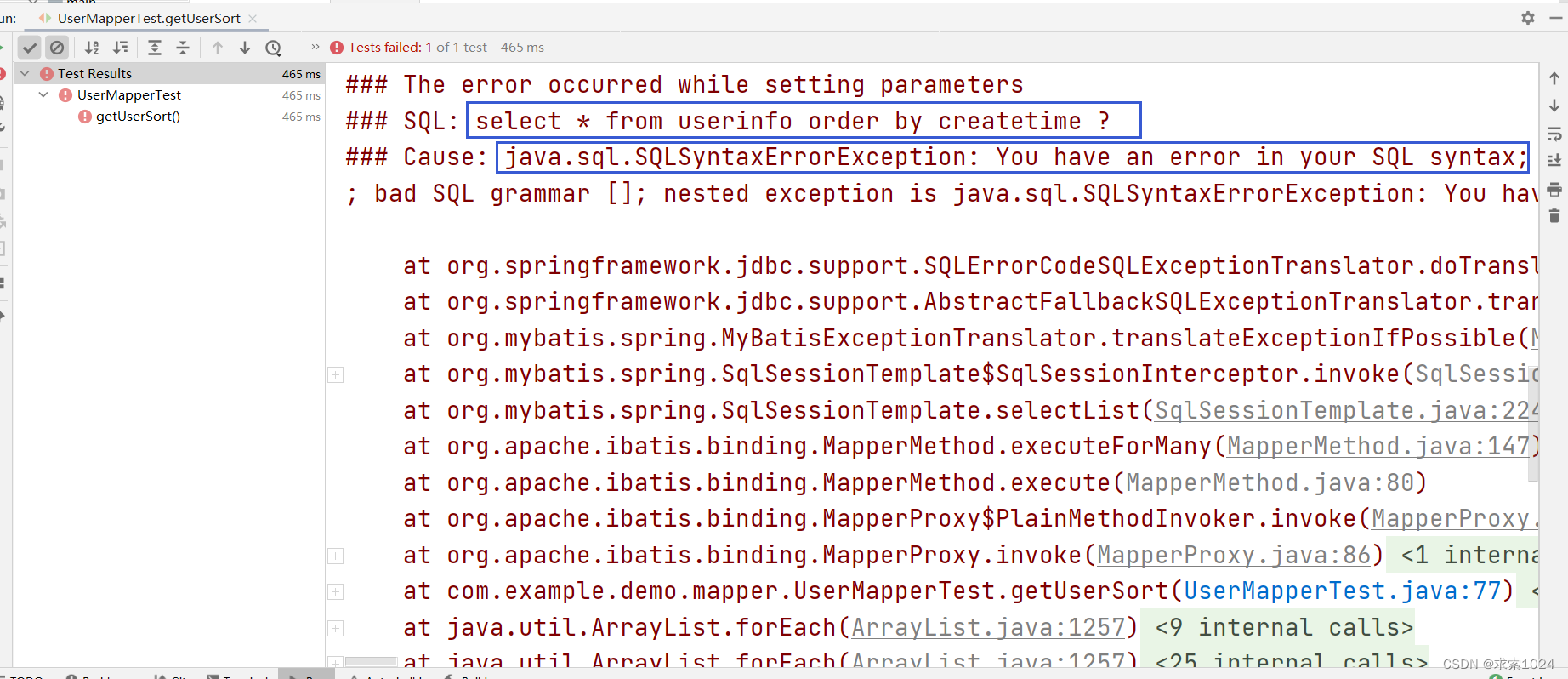
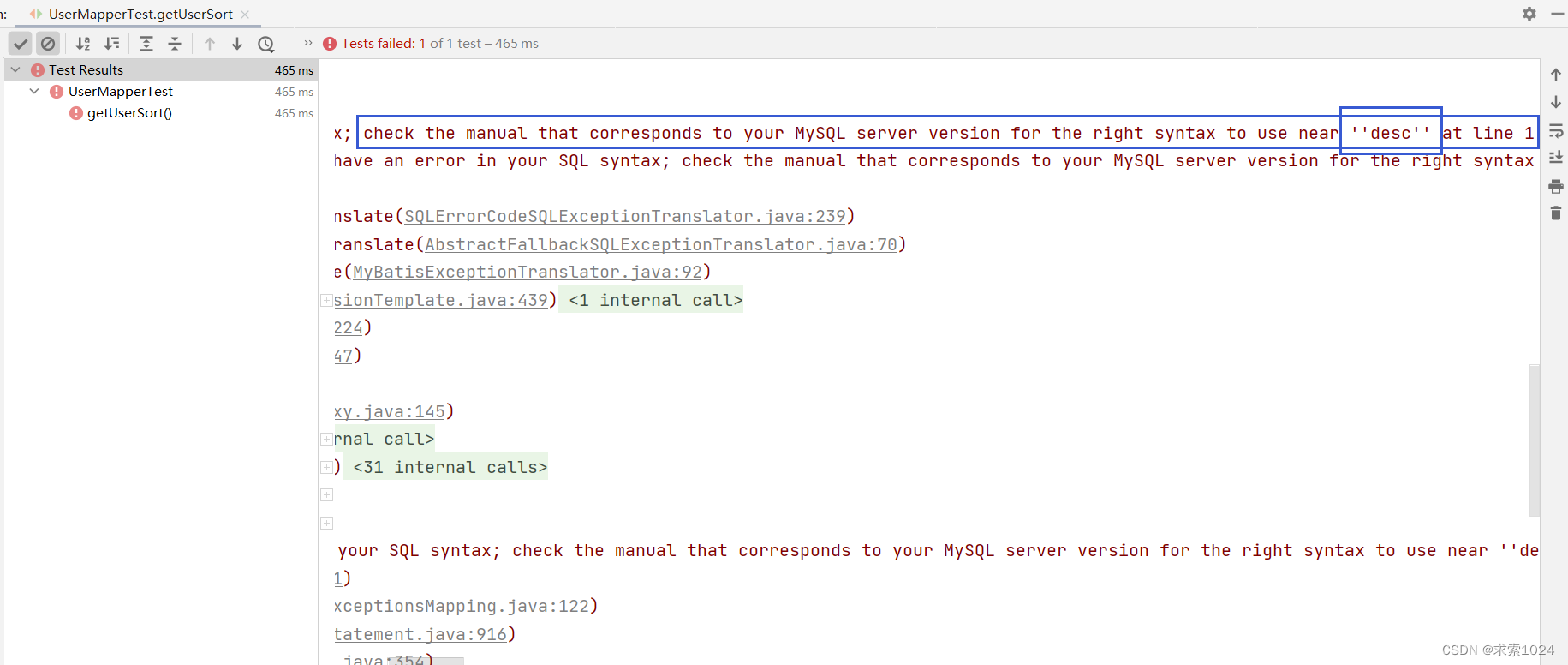
如果改成 #{},那么由于关键字被加了引号将会报错:
特殊场景:
当我们需要进行模糊查询时,例如在这种情况下:like '%#{username}%',因为 #{} 会自动添加引号,因此最后语句就会变成这样:like '%'zhangsan'%',但是这个由于是字符串,并且由于用户输入我们无法穷举,所以不能直接使用 ${},就要考虑使用 mysql 的内置函数 concat() 来处理,示例代码如下:
接口代码:
// 根据姓名模糊查询
public List<UserInfo> getListByName(@Param("username") String username);
原xml实现代码:
<!-- 根据用户名模糊查询 -->
<select id="getListByName" resultType="com.example.demo.model.UserInfo">
select * from userinfo where username like '%#{username}%';
</select>
测试代码:
@Test
void getListByName() {
List<UserInfo> list = userMapper.getListByName("li");
int i = 0;
if(list == null) {
return;
}
for (UserInfo user : list) {
log.info("用户信息" + i++ + ":" + user);
}
}
运行结果:
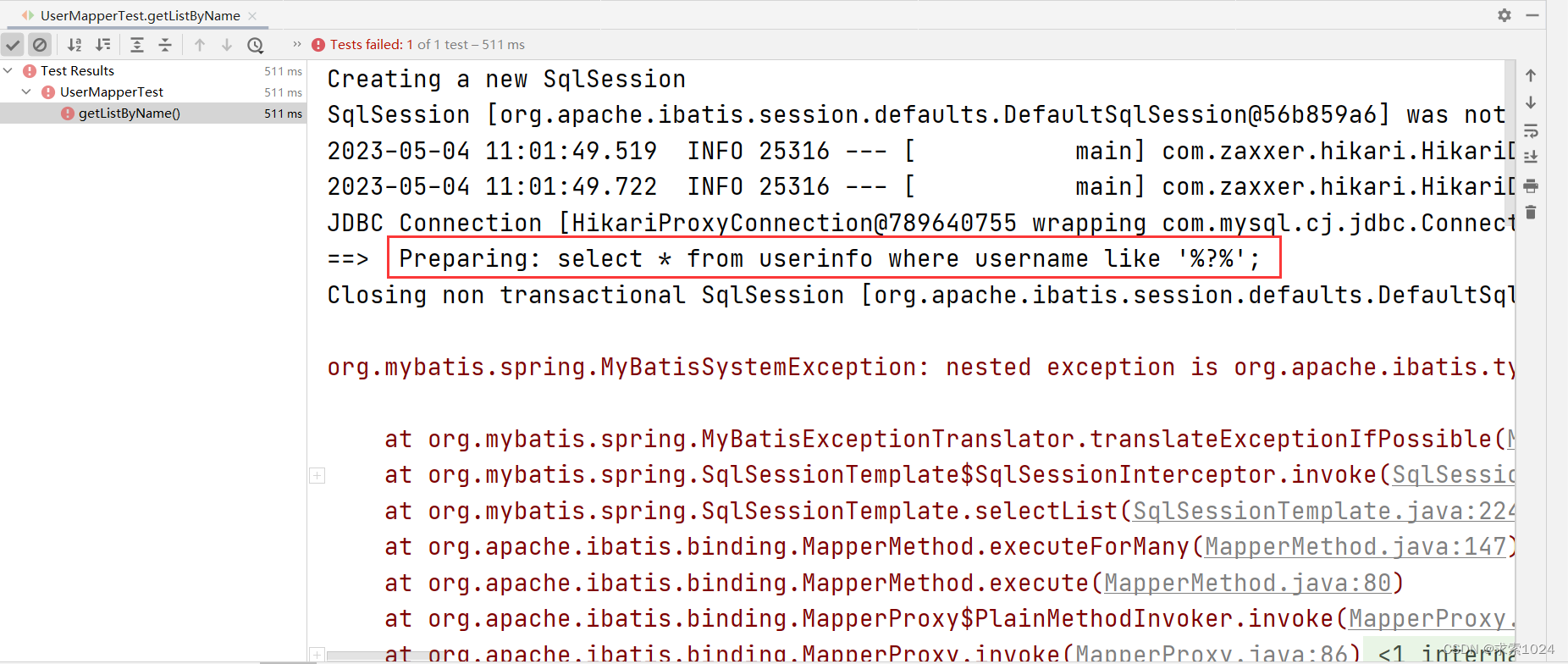
修改后的xml实现代码:
<!-- 根据用户名模糊查询 -->
<select id="getListByName" resultType="com.example.demo.model.UserInfo">
select * from userinfo where
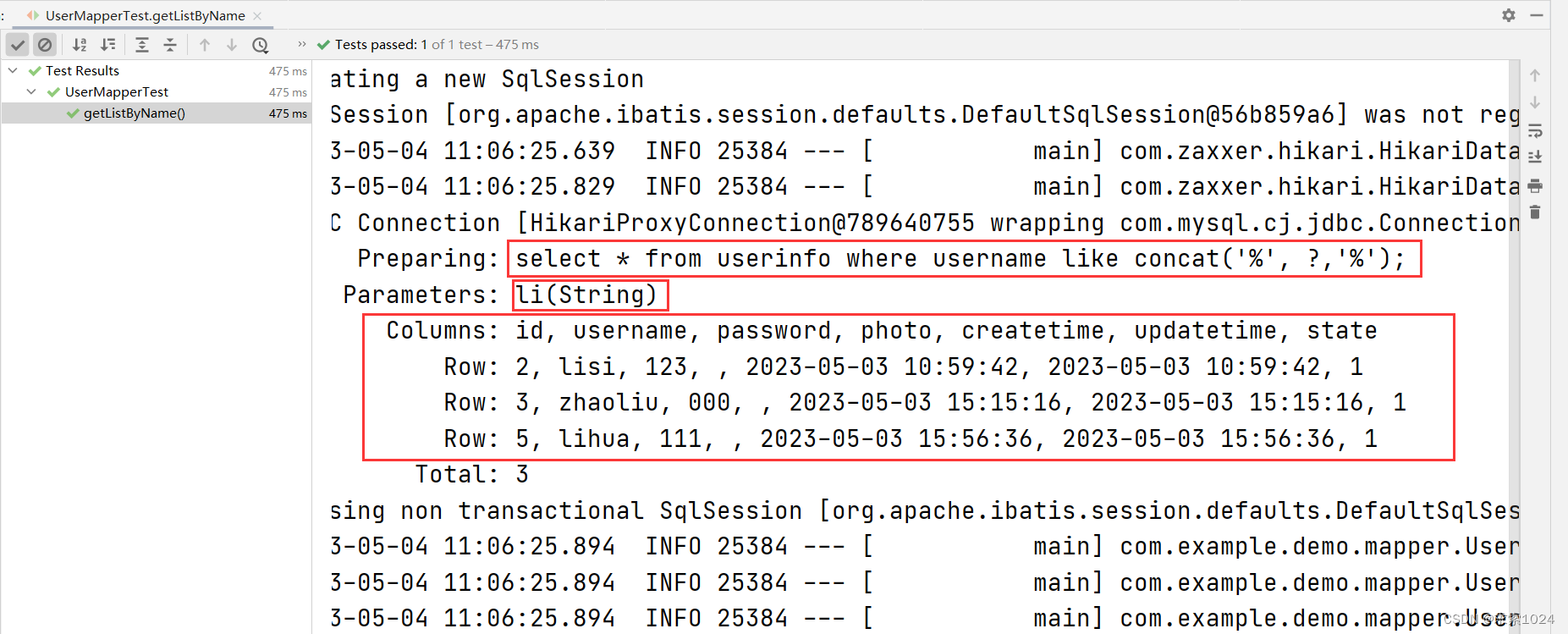
username like concat('%', #{username},'%');
</select>
运行结果:
七、查询操作
(一)单表查询
单表查询的操作比较简单,可以参考我们上述第一次进行 MyBatis 的 sql 执行语句,只是需要注意我们上面所写的不同情况 #{} 和 ${} 的使用
(二)多表查询
查询操作与增删改操作不同,增删改的操作返回值只是受影响的行数或者产生的自增 id。但是查询操作的返回值可能是一行数据,可能是多行数,如果多表查询,那么我们返回数据的存放也是个问题。因此查询操作比增删改操作多了一个设置返回类型的参数:resultType 或者 resultMap 的
1. 返回类型:resultType
resultType 是直接指定返回的具体实体类型的,使用非常方便,一般单表查询都会使用该属性设置,代码示例:
<!-- 根据用户 id 查询用户信息 -->
<select id="getUserById" resultType="com.example.demo.model.UserInfo">
select * from userinfo where id=#{id}
</select>
2. 返回字典映射:resultMap
resultMap 使用场景:
- 字段名称和程序中的属性名不同的情况,使用 resultMap 配置映射
- 一对一和一对多关系可以使用 resultMap 映射并查询数据
1. 字段名和属性名不同的情况
我们将属性名username改为name,然后根据 id 返回用户数据,结果如图:
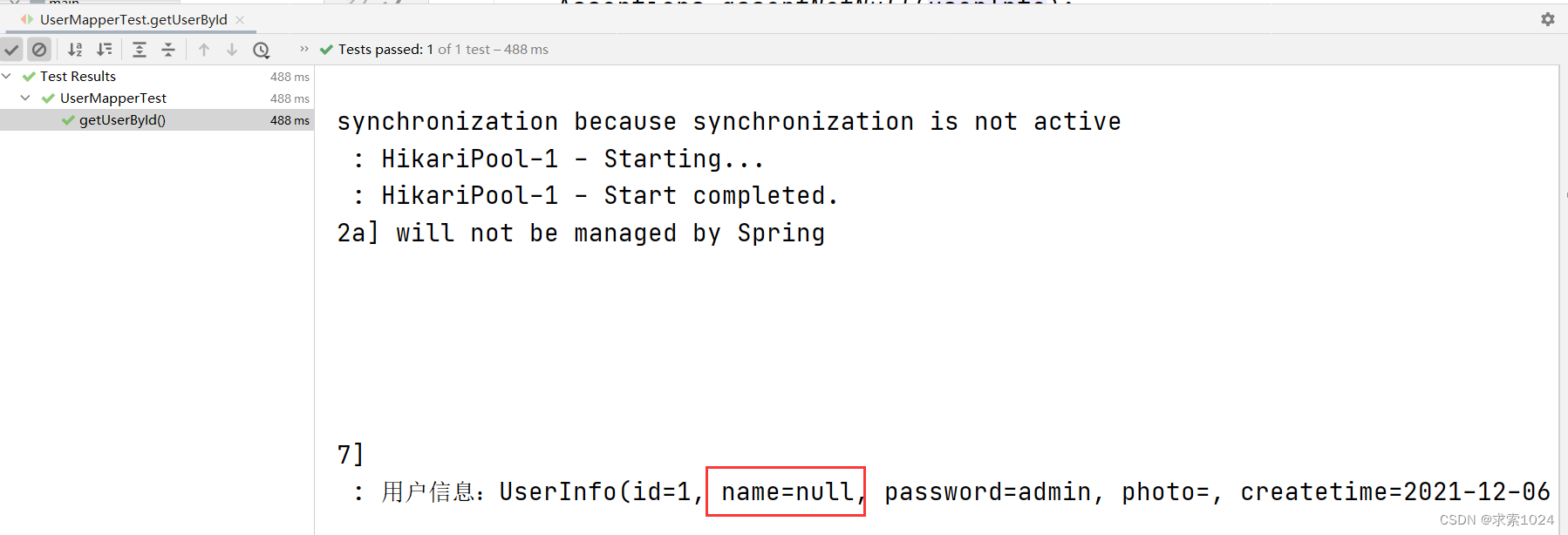
测试结果如图所示,由于属性名和字段名不一致,因此用户名的属性没有进行赋值,仍未 null
解决办法:
- 设置 resultMap,需要单独创建一个 resultMap 标签进行设置
<!-- id表示该 resultMap 的唯一标识 -->
<resultMap id="BaseMap" type="com.example.demo.model.UserInfo">
<!-- 主键映射 -->
<!-- column:字段名 -->
<!-- property:类中的属性名 -->
<id column="id" property="id"></id>
<!-- 普通属性映射 -->
<result column="username" property="name"></result>
</resultMap>
- 修改查询标签中的属性
<!-- 根据用户 id 查询用户信息 -->
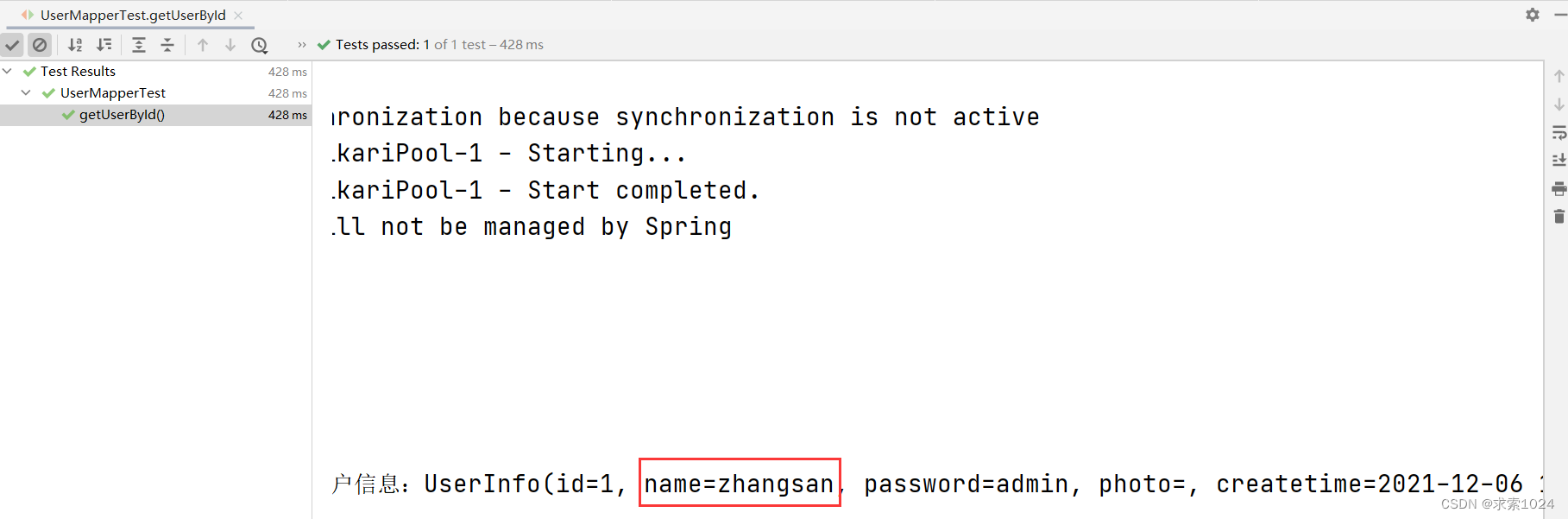
<select id="getUserById" resultMap="BaseMap">
select * from userinfo where id=#{id}
</select>
执行结果:
另一种解决方案:别名
- 接口代码:
// 获得所有用户信息
public List<UserInfo> getAll();
- xml实现代码:
<!-- 获取所有用户信息 -->
<select id="getAll" resultType="com.example.demo.model.UserInfo">
select id, username as name, password, photo, createtime, updatetime, state
from userinfo;
</select>
- 测试代码:
@Test
void getAll() {
List<UserInfo> list = userMapper.getAll();
int i = 0;
if(list == null) {
return;
}
for (UserInfo user : list) {
log.info("用户信息" + i++ + ":" + user);
}
}
执行结果:
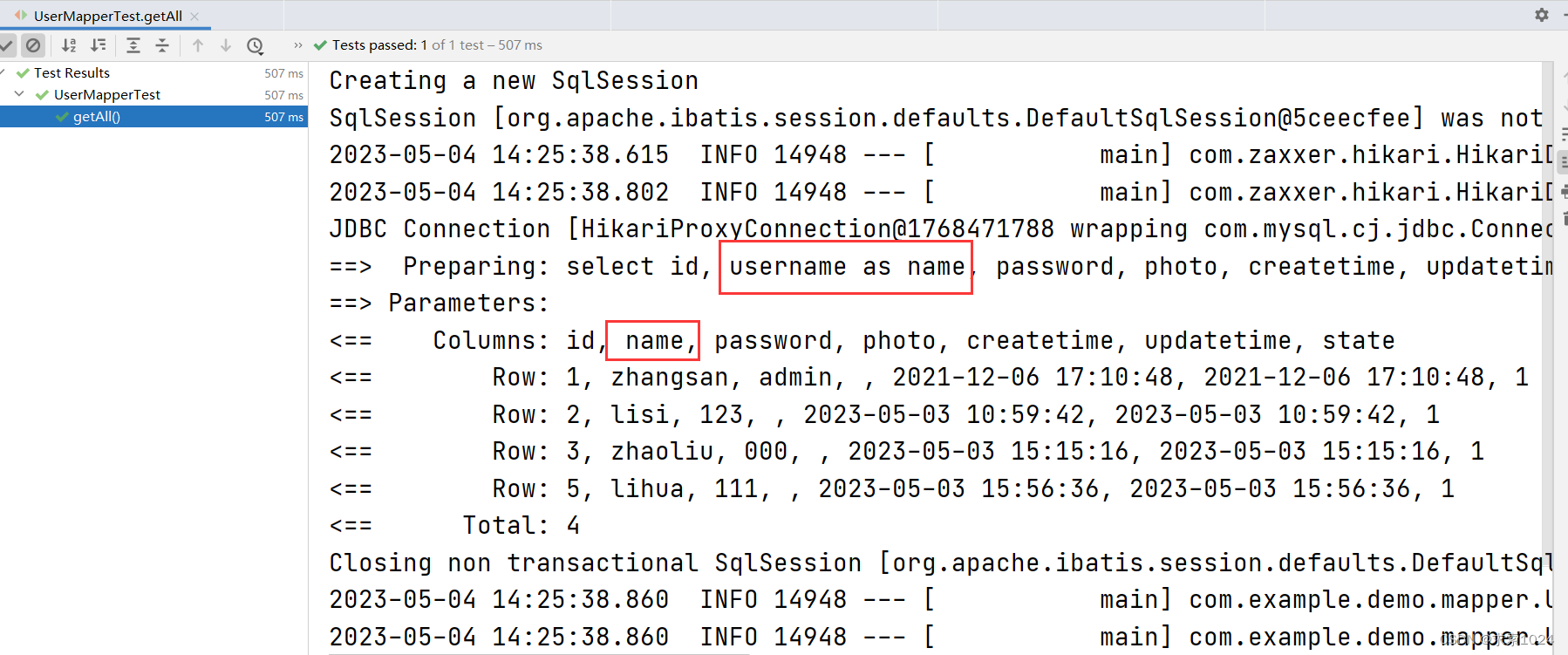
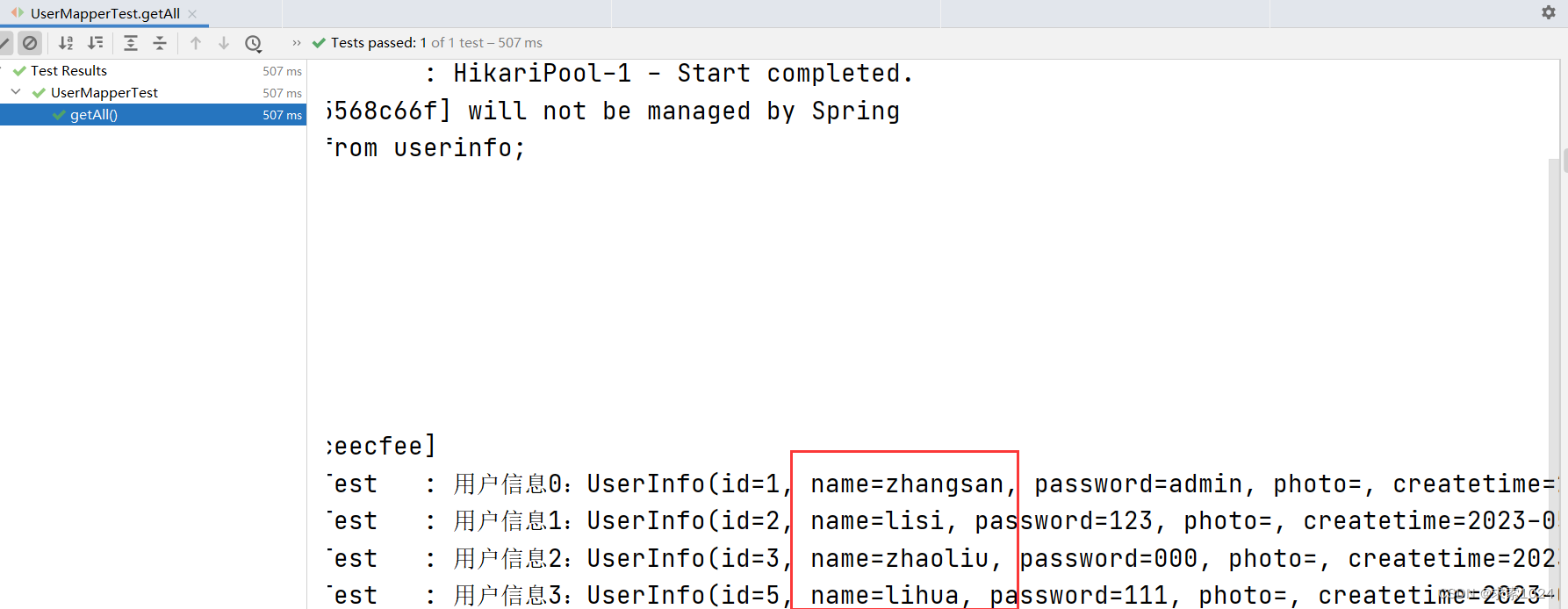
这种方式在企业里反而要比第一种更加常用,虽然我们看着是从 * 转成了一个个字段很麻烦,但是企业里为了查询的高效本来就不允许存在 * ,因此我们并不是在 * 的基础上进行优化,而是在原本就有字段的基础上给它加上别名
2. 一对一和一对多查询时使用 @resultMap 比较麻烦,因此我们不选择使用 @resultMap
3. 多表查询
(1)一对一的表映射
一对一的表映射得到的结果字段是两个表中的字段,此时我们用单纯的一个实体类接收势必会遗漏数据,但我们查询就是要看到它们之间的关系,因此我们需要用到视图对象
所谓视图对象,实际就是把两个实体类中的属性各选一些需要的合成一个新的类,这个类实例化之后就是视图对象
1.先创建对应的目录和类
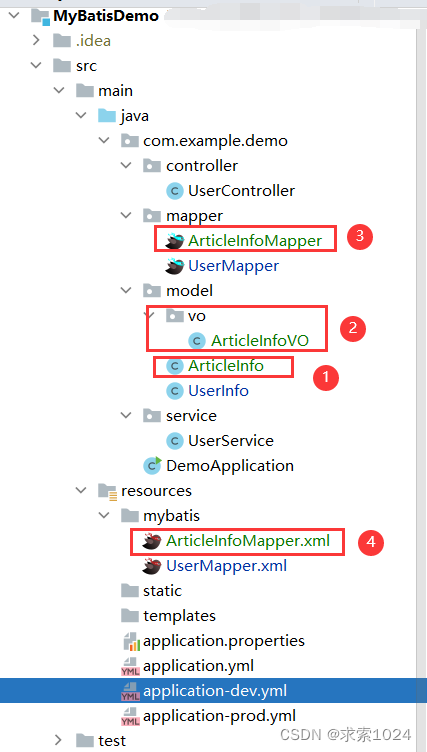
ArticleInfo实体类:
@Data
public class ArticleInfo {
private Integer id;
private String title;
private String content;
private String createtime;
private String updatetime;
private Integer uid;
private Integer rcount;
private Integer state;
}
视图对象类
@EqualsAndHashCode(callSuper = true)
@Data
public class ArticleInfoVO extends ArticleInfo {
// 增加一个 username 属性
private String username;
private Integer id;
private String title;
private String content;
private String createtime;
private String updatetime;
private Integer uid;
private Integer rcount;
private Integer state;
}
ArticleInfoMapper接口,注意这里的接口不是视图对象接口,而是实体类接口
@Mapper
public interface ArticleInfoMapper {
}
xml实现文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 这里的namespace要设置实现接口的具体包名 + 类名 -->
<mapper namespace="com.example.demo.mapper.ArticleInfoMapper">
</mapper>
2. 创建方法并实现
方法代码:
// 根据文章 id 查询对应用户的用户名和文章信息
// 返回值必须是 ArticleInfoVO
ArticleInfoVO getById(@Param("id") Integer id);
实现代码:
<select id="getById" resultType="com.example.demo.model.vo.ArticleInfoVO">
select u.username, a.*
from userinfo u left join articleinfo a on a.uid = u.id
where a.id = #{id}
</select>
运行结果:
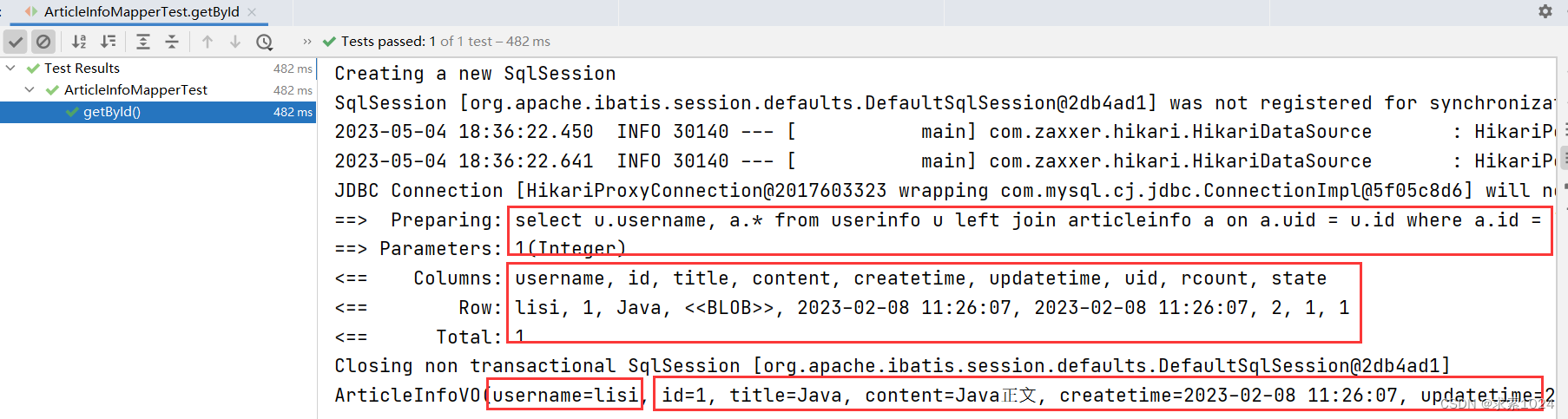
实现完成!实际的原理很简单,就是创建一个能容纳所有字段数据的新类,但是这个类不是一个实体类,只是一个视图对象类,它很灵活,可以根据我们想要的字段或属性自己调整
但是大家可能会注意到一件事,我们能不能直接继承基类,只定义扩展类的属性,这就是我们接下来要讨论的问题:
- 视图对象代码修改:
@EqualsAndHashCode(callSuper = true)
@Data
public class ArticleInfoVO extends ArticleInfo {
// 增加一个 username 属性
private String username;
}
- 执行结果:
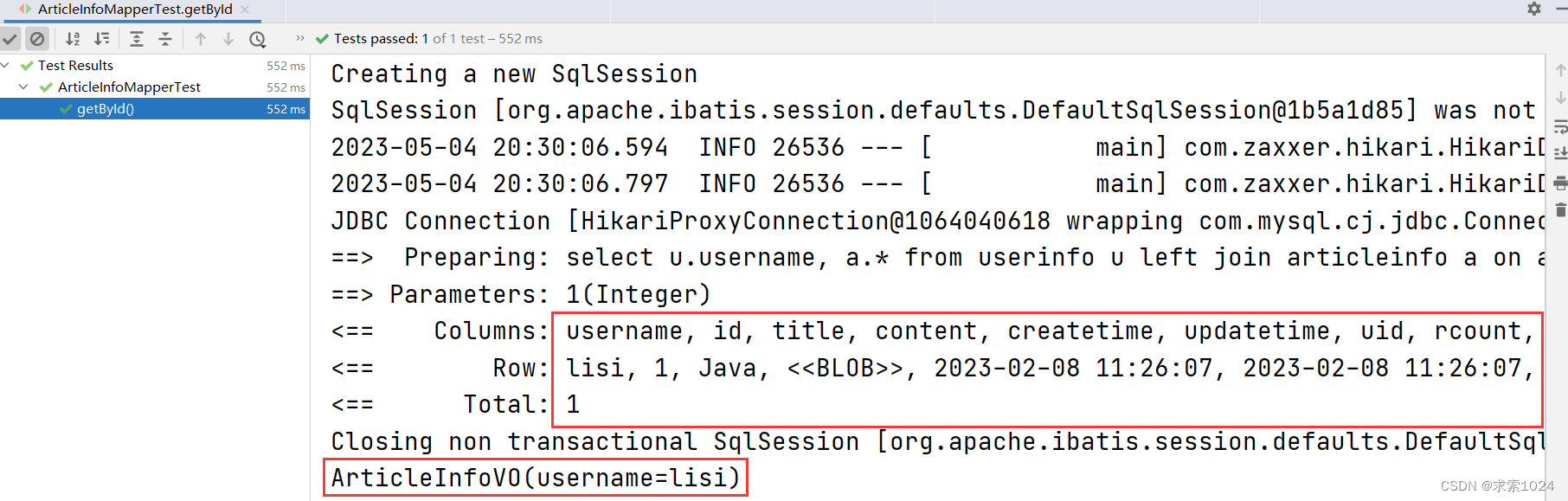
我们发现,虽然查询结果的信息显示的很完整,但是最后只给 username 进行了打印,接着我们进行排查,通过 debug 我们发现,其实属性都已经被我们赋值了,如下图:
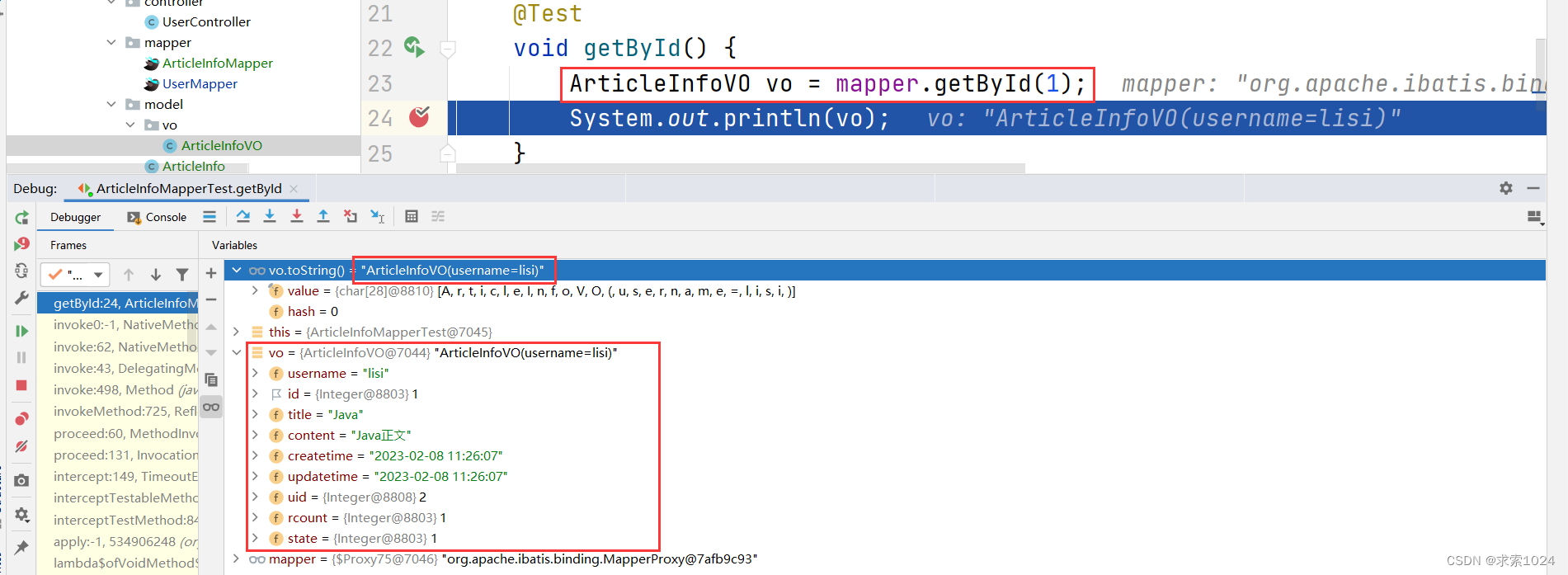
于是我们就能确认,并不是赋值出了问题,而是打印,也就是 toString() 方法,也就是 lombok 出了问题,我们点开 字节码的文件进行观察
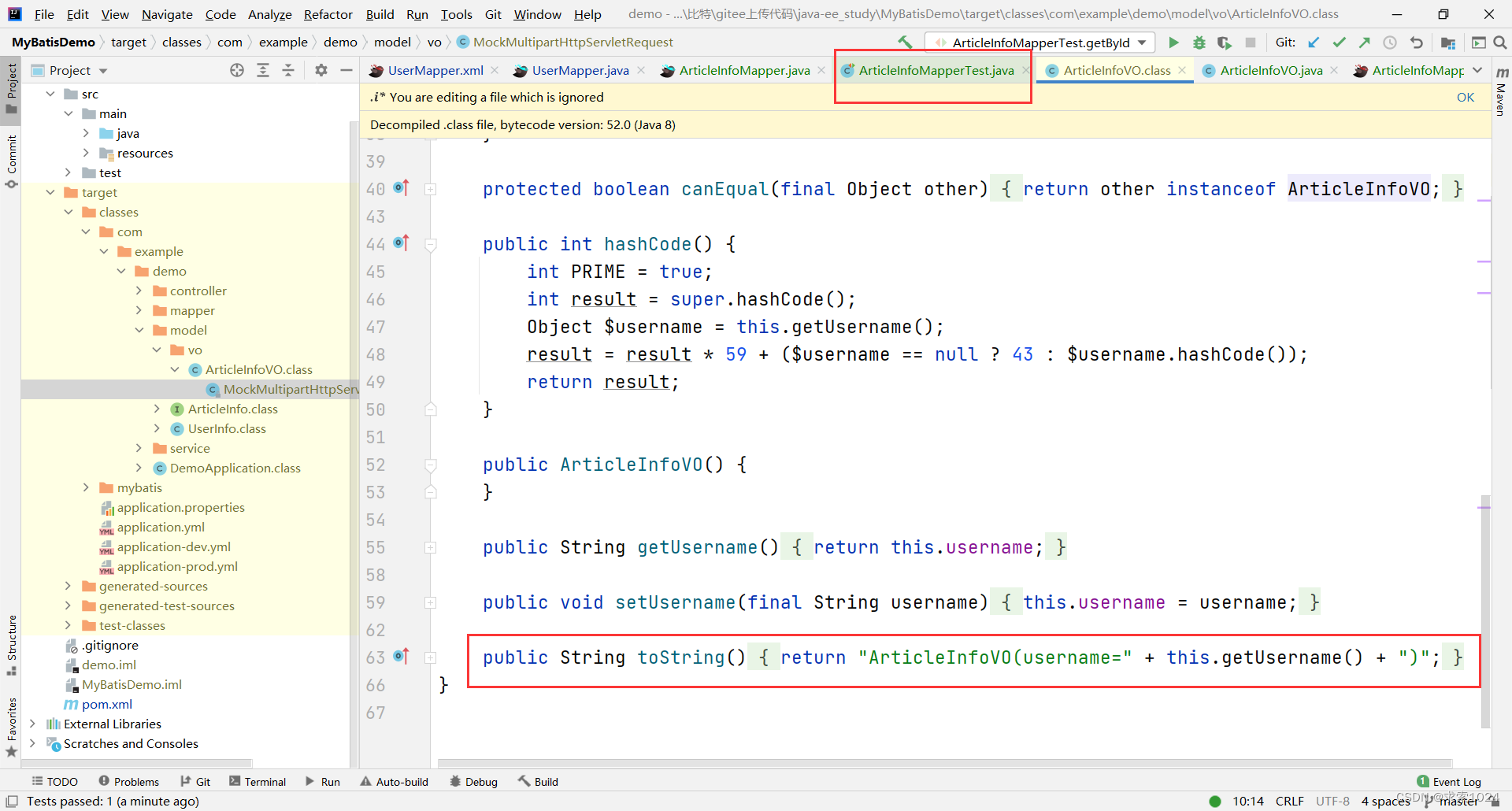
发现原来是 lombok 的 toString() 方法的问题,于是我们直接重写 toString 方法
代码示例:
// 重写 toString 方法
@Override
public String toString() {
return "ArticleInfoVO{" +
"username='" + username + '\'' +
"} " + super.toString();
}
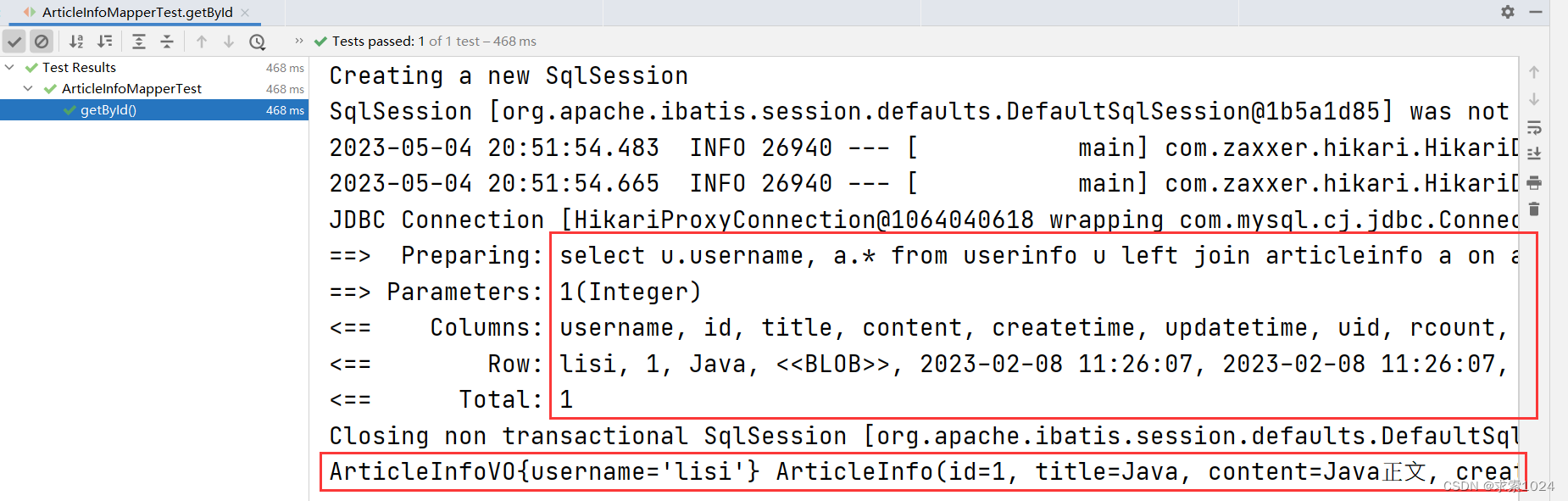
结果如图:
(1)一对多和多对多的表查询
根据实际代码查询结果,一对多和多对多的查询数据最后落下来都是通过视图对象来解决
对一对多的表关系进行查询时,例如查询用户 id 为 1 的所有博客,那么返回的结果就是顺序表,顺序表中的对象就是视图对象;对多对多的表关系进行查询时,例如一个作者可能投过多个出版社,一个出版社会收到多个作者的投稿,那么两个表之间就是多对多的关系,我们进行查询时,查询结果也一定是一对多的结果
因此我们说,多表联查的最终实现都是:联表查询语句(left join/inner join) + 视图对象
八、动态 SQL 使用
动态 SQL 是 MyBatis 的强大特性之一,能够完成不同条件下不同的 sql 拼接
(一)标签
我们在某个网站进行用户注册时,可能会遇到必填项和非必填项,那么像这种不确定有多少项的数据 MyBatis 的 sql 该如何编写,我们就用得到 标签
if 标签语法:
参数名
test 会产生一个 boolean 类型的 结果,如果是 true,那么添加标签中的内容到 sql 语句中,如果为 false,那么就不添加
标签代码示例,注意其中的photo是传入对象中的属性,不是数据库中的字段:
<!-- 新增用户,并返回受影响的行数 -->
<!-- 对新增用户代码进行修改,设置成动态 sql -->
<insert id="addUser">
insert into userinfo (
username,
password
<!-- 由于 photo 在我们编写 sql 代码时放在最后 -->
<!-- 因此我们需要注意它的前一个字段的逗号问题,将 if 里面的内容设置为 ,photo -->
<!-- 而 password 后面不能加逗号 -->
<if test="photo != null">
,photo
</if>
) values (
#{username},
#{password}
<if test="photo != null">
,#{photo}
</if>
)
</insert>
测试类代码:
@Test
@Transactional
void addUser() {
UserInfo userInfo = new UserInfo();
userInfo.setUsername("lihua");
userInfo.setPassword("111");
// userInfo.setPhoto("");
int result = userMapper.addUser(userInfo);
Assertions.assertEquals(1, result);
}
运行结果:
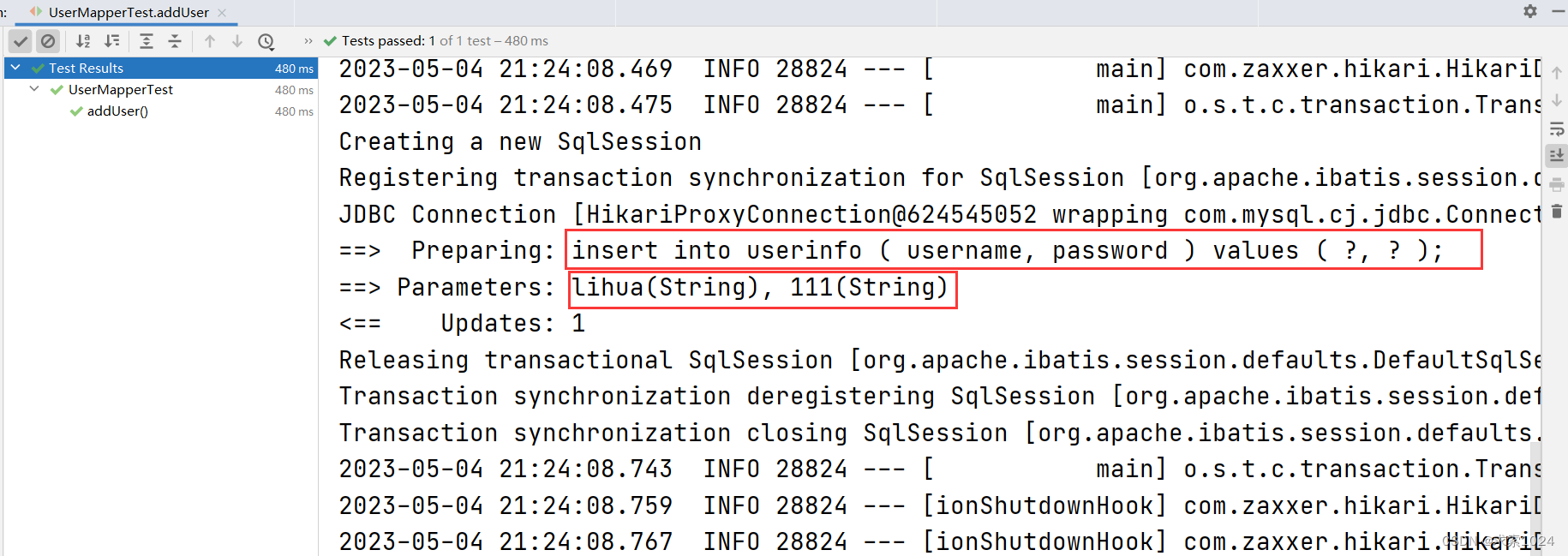
结果可以看出,最后生成的 sql 代码中 photo 字段没有出现
(二)标签
我们在使用 标签时,会发现一个问题,如果所有的字段都是非必填项,那么我们的逗号以及括号等该如何放置, 标签就可以解决这个问题,使用 标签搭配 标签,对多个字段采取动态生成的方式
标签中的属性:
- prefix:表示整个语句块,以 prefix 的值作为前缀
- suffix:表示整个语句块,以 suffix 的值作为后缀
- prefixOverrides:表示整个语句块要去除掉的前缀
- suffixOverrides:表示整个语句块要去除掉的后缀
对上述插入代码再次进行调整:
<insert id="addUser">
insert into userinfo
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="username != null">
username,
</if>
<if test="password != null">
password,
</if>
<if test="photo != null">
photo,
</if>
</trim>
values
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="username != null">
#{username},
</if>
<if test="password != null">
#{password},
</if>
<if test="photo != null">
#{photo},
</if>
</trim>
</insert>
suffixOverrides 的设置是如果最后有逗号,就去掉,没有就不去,我们可以从下方图片看出,photo 末尾的逗号已经被去除
正常情况下既然是添加操作,那么至少会有一个属性不为 null ,否则就没必要进行添加操作
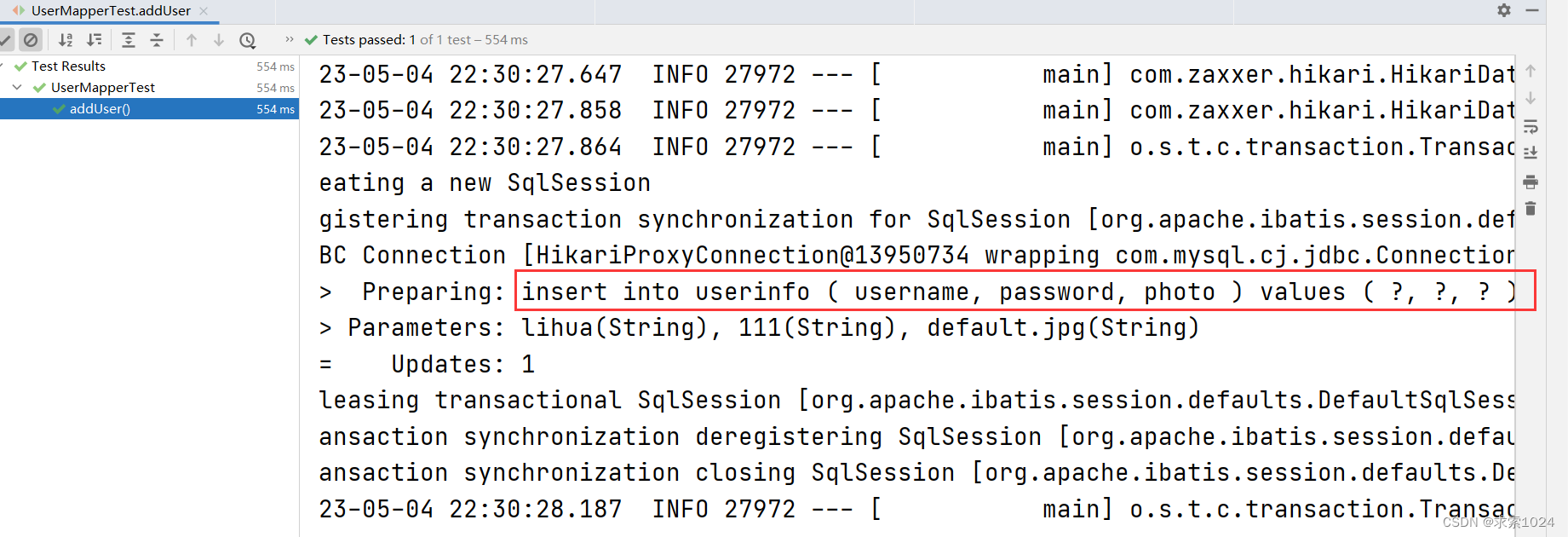
(三) 标签
传⼊的⽤户对象,根据属性做 where 条件查询,⽤户对象中属性不为 null 的,都为查询条件。例如 userInfo.username是"zhangsan",则查询条件为 where username = “zhangsan”
UserMapper 接口中条件查询代码:
// 根据某些用户信息筛选满足条件的用户
List<UserInfo> getListByUser(UserInfo userInfo);
xml文件实现代码:
<!-- 根据某些用户信息筛选满足条件的用户 -->
<select id="getListByUser" resultType="com.example.demo.model.UserInfo">
select * from userinfo
<where>
<if test="id != null">
and id=#{id}
</if>
<if test="username != null">
and username=#{username}
</if>
<if test="password != null">
and password=#{password}
</if>
<if test="state != null">
and state=#{state}
</if>
</where>
</select>
测试代码1:
@Test
void getListByUser() {
UserInfo userInfo = new UserInfo();
userInfo.setId(1);
userInfo.setUsername("zhangsan");
List<UserInfo> list = userMapper.getListByUser(userInfo);
System.out.println(list);
}
测试结果1:
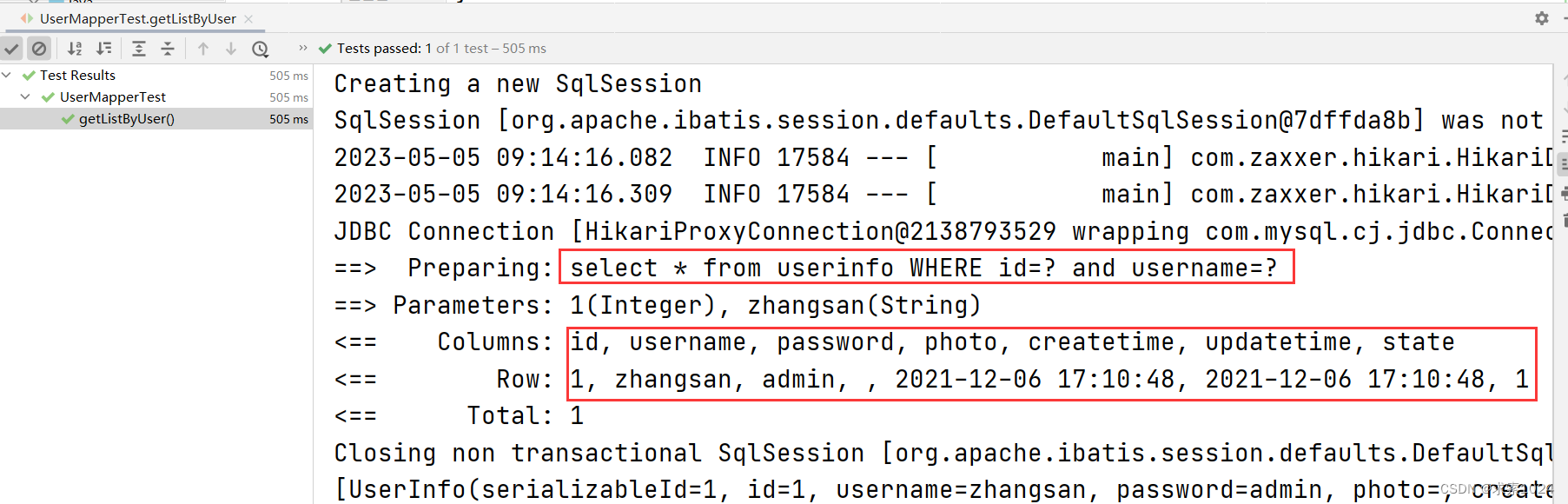
由该测试结果我们可以知道,当判断语句中开头有了 and 的时候,where 在生成 sql 代码时会自动删除,但是,and 在最后却不行
测试代码2:
@Test
void getListByUser() {
UserInfo userInfo = new UserInfo();
List<UserInfo> list = userMapper.getListByUser(userInfo);
System.out.println(list);
}
测试结果2:
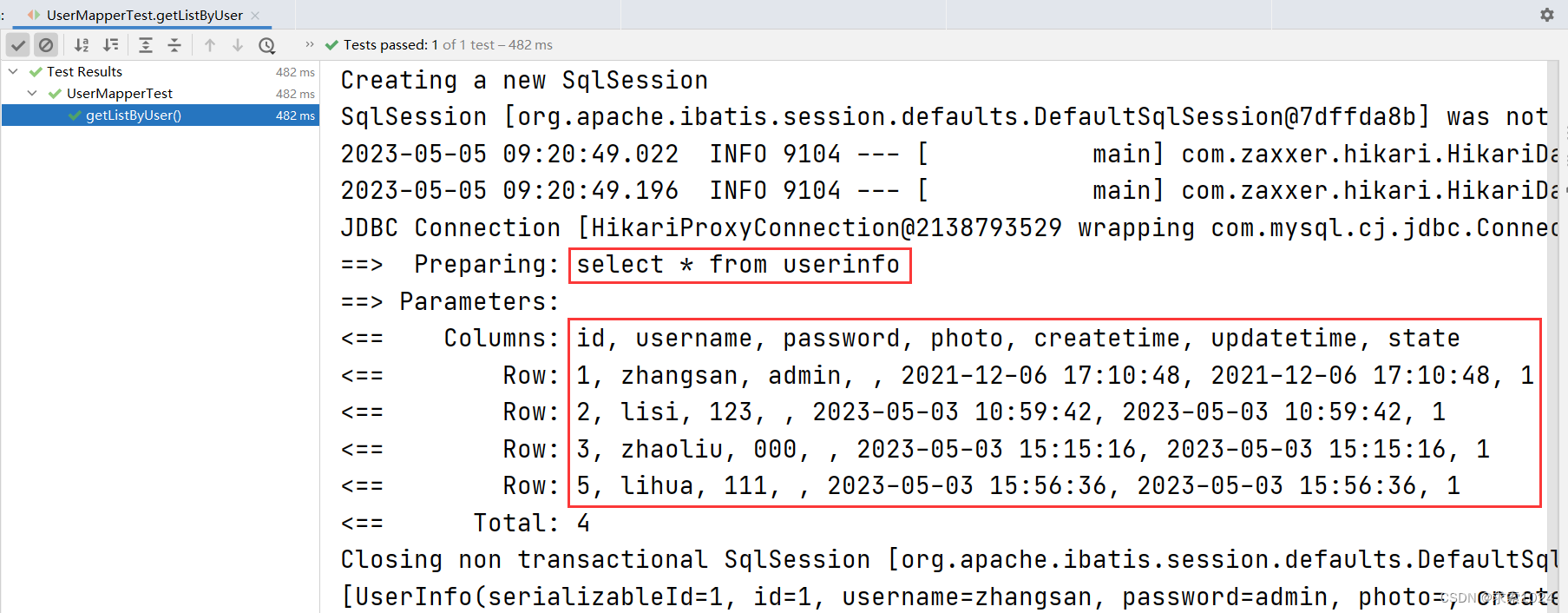
由该测试结果我们知道,当一个判断条件都不存在时,where 标签也就不会添加 where 关键字了
上述 标签也可以使用 替换,prefix也是根据内容是否存在选择添加的,可以说, 是功能弱化的
因此我们说:where 标签有以下几个特征:
- where 标签通常配合 if 标签使用
- where 标签会删除最前面的 and 标签,但不会删除最后面的 and 标签
- where 标签中如果没有内容,那么它就不会生成 where 关键字
(四) 标签
根据传⼊的⽤户对象属性来更新⽤户数据,可以使⽤标签来指定动态内容
与 极其类似,它也有几个特点:
- 标签通常要配合 标签使用
- 标签会自动去除最后一个英文逗号
根据用户 id 修改用户信息接口代码:
// 根据用户 id 修改用户的某些信息
int updateUserById(UserInfo userInfo);
xml文件实现代码:
<!-- 根据用户 id 修改用户信息 -->
<update id="updateUserById">
update userinfo
<set>
<if test="username != null">
username = #{username},
</if>
<if test="password != null">
password = #{password},
</if>
<if test="photo != null">
photo = #{photo}
</if>
</set>
where id = #{id}
</update>
测试代码:
@Test
void updateUserById() {
UserInfo userInfo = new UserInfo();
userInfo.setId(1);
userInfo.setUsername("hehai");
int result = userMapper.updateUserById(userInfo);
Assertions.assertEquals(1, result);
}
测试结果:
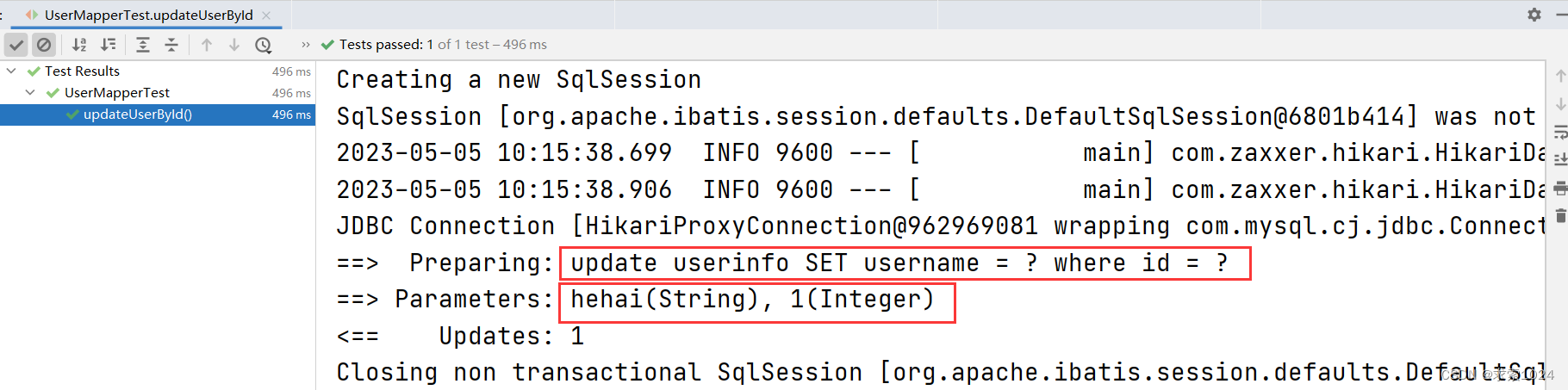
上述的 标签也可以替换为 ,也可以认为是功能弱化但更专精的 标签
(五) 标签
标签对集合进行遍历时可以使用该标签, 标签存在如下属性,但不止下面的属性:
- collection:绑定方法参数中的集合,如 List、Set、Map或数组对象
- item:遍历时的每一个对象
- open:语句块开头的字符串
- close:语句块结束的字符串
- separator:每次遍历之间间隔的字符串
根据用户 id 批量删除用户数据接口代码:
// 根据多个用户 id 批量删除用户信息
int deleteByList(List<Integer> list);
xml文件实现代码:
<!-- 根据用户 id 批量物理删除用户信息 -->
<delete id="deleteByList">
delete from userinfo where id in
<foreach collection="list" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</delete>
测试代码:
@Test
@Transactional
void deleteByList() {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
int result = userMapper.deleteByList(list);
Assertions.assertEquals(3, result);
}
测试结果:
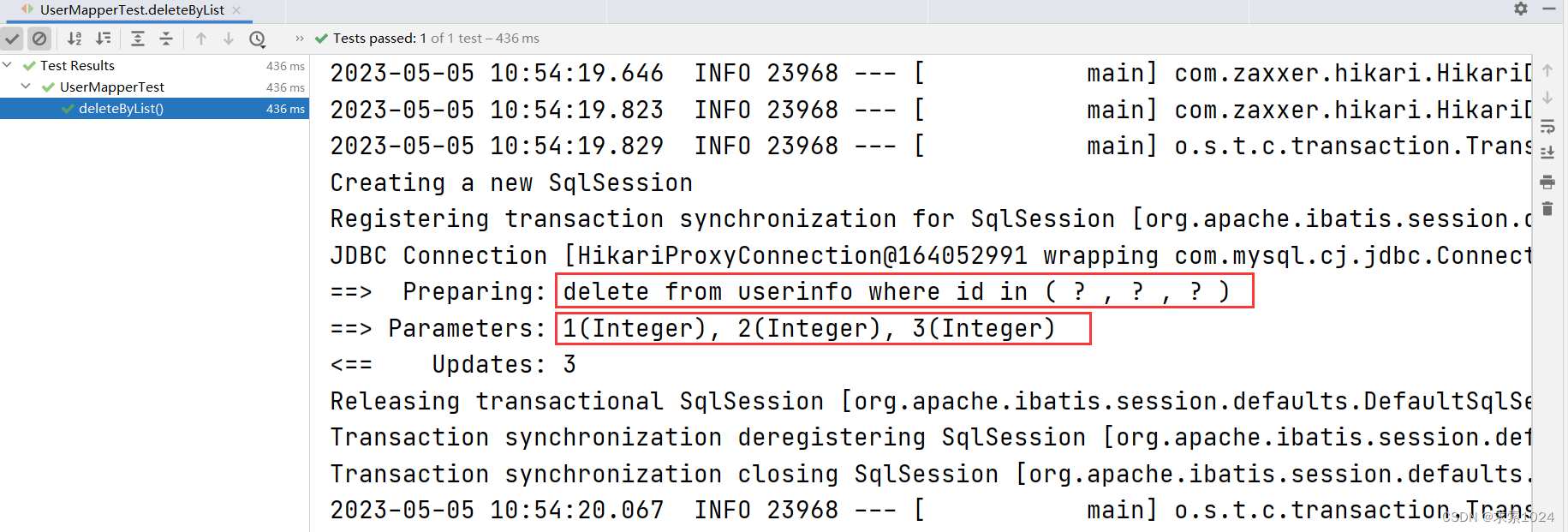
由结果可以看出,完全符合我们的预期,使用起来也比较简单,但是要熟悉熟悉
![[GFCTF 2021]ez_calc day3](https://img-blog.csdnimg.cn/4bce4b4c0b834d7ebc4cf75760c2f90f.png)