提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、需求背景
- 二、我要做什么
- 三、已有接口
- 四、脚本实现
- 五、实现效果图
前言
为提升自己的python能力,记录在工作中实现的自动化脚本,温故而知新,做到可复用。
一、需求背景
需求的参与用户是平台指定了会员等级以及消费分数,公司营销系统将符合参与条件的用户集合到一个指定标签当中
二、我要做什么
抽样监测数据库中符合参与条件的用户是否在指定的标签当中
三、已有接口
1.输入用户id和标签id,查询id是否在标签id当中,是则name会返回指定文案
四、脚本实现
拆分步骤
1、引入excel文件,使用openpyxl库
import openpyxl
# 加载本地excel文件,并将excel第一个sheet1赋值给ws
wb = openpyxl.load_workbook('D:/qatestdata/zhazhayuan.xlsx')
ws = wb['sheet1']
2、遍历excel中用户id列,并存储用户id用于后续调用
user_ids = []
for row in ws.iter_rows(min_row=2, values_only=True):
user_id = row[1]
user_ids.append(str(user_id))
user_ids = []:预设空列表
iter_rows() 方法用于迭代工作表中的所有行,而 min_row=2 则指定了迭代起始行为第 2 行。第一行为表头需注意第二行开始
user_id = row[1]:需要用到的id在第二列,赋值给user_id
user_ids.append(str(user_id)):将user_id插入到user_id列表当中
3、循环调用,并判断结果
for user_id in user_ids:
params = {'sceneId': 00001, 'uid': user_id}
response = requests.get(url, headers=headers, params=params)
name = response.json()['name']
if name != '符合':
print(f"uid {} 的 name 值为 {name},与预期不符!")
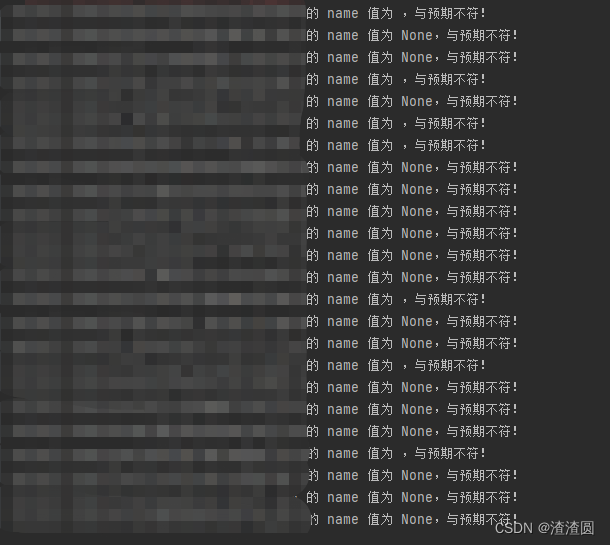
五、实现效果图