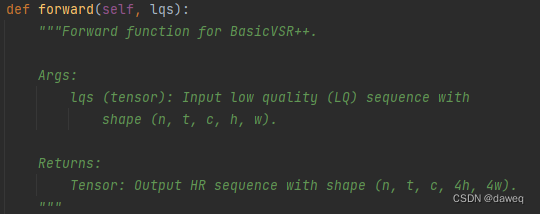
一、前向传播函数def forward(self, lqs):
输入:低质量序列L,shape为**(n, t, c, h, w)。
输出:HR序列,shape为(n, t, c, 4h, 4w)**。
(1)读取输入数据的维度大小
这里的n,t,c,h,w分别表示:一个bitch的图片数量,镜像扩展序列的标签,通道数(RGB为3),竖直像素,水平像素。数据的大小是(1,30,3,64,64)这里的t=30是可以设置的。
train_dataloader = dict(
num_workers=6, batch_size=1, dataset=dict(num_input_frames=30))
也就是一次读取的图片数量,这里设置为30,所以t=30。
n, t, c, h, w = lqs.size()
(2)是否使用CPU去缓存数据
这里的核心参数是cpu_cache_length这里的意思是如果你的序列长度大于了你设定的长度,那么会将中间特征传给CPU计算,如果你的GPU够大,这里可以设定的大一点,让GPU尽可能去使用。
# whether to cache the features in CPU (no effect if using CPU)
if t > self.cpu_cache_length and lqs.is_cuda:
self.cpu_cache = True
else:
self.cpu_cache = False
(3)是否是低质量序列
输入是不是低质量序列,是的话就克隆一份数据,不是的话就使用bicubic双三次差值制作一份低质量序列。
if self.is_low_res_input:
lqs_downsample = lqs.clone()
else:
lqs_downsample = F.interpolate(
lqs.view(-1, c, h, w), scale_factor=0.25,
mode='bicubic').view(n, t, c, h // 4, w // 4)
(4)检测是否是镜像扩展序列
检查输入是不是镜像扩展序列,调用self.check_if_mirror_extended()函数,返回值是self.is_mirror_extended值为True或者False。默认不是镜像扩展序列(false)。
(5)计算空间特征
从这里开始就要设计到对原数据的处理了,主要是计算空间特征,计算光流,传播这三块内容。
用 feats={}去保存特征,这是一个字典,其中用'spatial'关键词去保存特征。cpu_cache表示是否使用了cpu缓存,该值决定了特征计算的过程,默认是false。这里以没有使用为例子。首先self.feat_extract(lqs.view(-1, c, h, w)),因为已经是低质量图像了,所以是用在Basicvsr里面有的一个残差模块来提取特征ResidualBlocksWithInputConv(3, mid_channels, 5)。
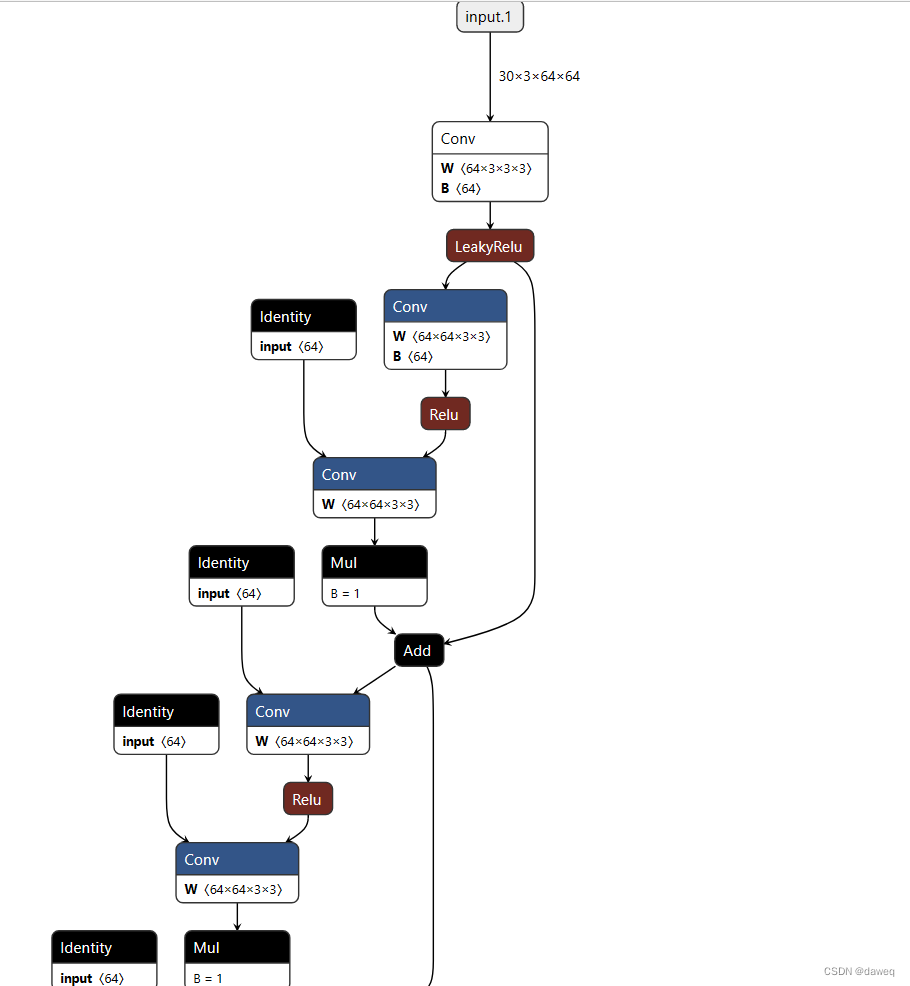
ResidualBlocksWithInputConv(3, mid_channels, 5)的三个参数分别为输入通道,输出通道,残差块数量。下图是残差模块的网络结果示意图,残差块一共是5个。之后再分析这个网络。输出特征的大小应该是(1,30,64,64,64)。
(6)光流计算模块
使用flows_forward, flows_backward = self.compute_flow(lqs_downsample)去计算光流,输入是低分辨率图像张量的拷贝,输出前向和后向光流。因为要前向和后向起点分别为第一帧图和最后一帧图,所以要分别去保存。使用self.spynet(lqs_1, lqs_2).view(n, t - 1, 2, h, w)和self.spynet(lqs_2, lqs_1).view(n, t - 1, 2, h, w)分别计算前向和后向(因为不是镜像扩展序列)。这里就不具体讲了,后续会单独讲。输出是(1,29,2,64,64)的大小。
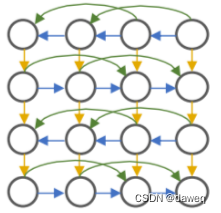
(7)特征传播模块
在模型传播图里面可以看到有两次前向传播和两次后向传播,所以我们也要区分一下,主要就是按照backward_1,backward_2,forward_1,forward_2这四个,要分别计算帧数间的特征,可以先在特征字典里保存这4个关键字。然后根据是前向还是后向,确定光流是哪一个。然后将特征,模型(就是前面那四个之一),和特征字典传到self.propagate里面最后返回该次计算的特征,最后一步是进行上采样。