BERT 的简介
1、BERT 是什么?它是用来做什么的?
BERT(Bidirectional Encoder Representations from Transformers)是由Google开发的自然语言处理模型,是一种预训练模型,可以用于多种自然语言处理任务,如文本分类、命名实体识别、问答系统等。BERT使用大量文本数据进行预训练,然后使用这些预训练的模型参数进行微调,从而实现在特定任务上的高精度性能。BERT的主要目标是在不同的自然语言处理任务上,通过微调少量的任务特定参数来提高模型的效率和性能。
BERT 是一种自然语言处理的预训练模型,用于预测单词或语句的含义³。它的全称是Bidirectional Encoder Representations from Transformers,意思是双向的Transformer编码器表示²。它的主要特点是利用了masked language model(遮蔽语言模型,MLM)和next sentence prediction(NSP)两种预训练任务,来生成深层的双向语言表征¹²。BERT可以在各种自然语言任务上进行微调,如文本分类、序列标注、问答等,取得了很好的效果¹²。
Source: Conversation with Bing, 2023/5/7
(1) BERT的通俗理解_bert是什么_小白的进阶的博客-CSDN博客. https://blog.csdn.net/laobai1015/article/details/87937528.
(2) 什么是BERT? - 知乎. https://zhuanlan.zhihu.com/p/98855346.
(3) BERT 详解 - 知乎. https://zhuanlan.zhihu.com/p/103226488.
2、BERT 模型在哪些自然语言处理任务中取得了突破性的效果?举例说明。
BERT 模型是一种基于 Transformer 的双向编码器表征模型,它可以在大量的自然语言处理任务中取得突破性的效果。¹² 例如:
- 在 GLUE 基准测试中,BERT 模型刷新了 11 项 NLP 任务的当前最优性能记录,包括自然语言推断、情感分析、语义相似度等。²
- 在 SQuAD v1.1 的问答任务中,BERT 模型的 F1 得分达到了 93.2 分,比人类表现还高出 2 分。²
- 在命名实体识别(NER)任务中,BERT 模型可以通过简单地微调预训练参数,在下游任务中进行训练,无需对任务特定架构做出大量修改。³
BERT 模型之所以能够在这些任务中取得优异的表现,主要是因为它利用了遮蔽语言模型(MLM)和下一句预测(NSP)两种预训练目标,来学习深度双向的语言表征,从而充分利用了上下文信息。²⁴
Source: Conversation with Bing, 2023/5/7
(1) #最全面# 使用 Bert 解决下游 NLP 实际任务 - 知乎. https://zhuanlan.zhihu.com/p/365357615.
(2) 最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录 - 知乎. https://zhuanlan.zhihu.com/p/46656854.
(3) 五分钟搭建一个基于BERT的NER模型 - 知乎. https://zhuanlan.zhihu.com/p/107743408.
(4) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
GLUE 基准测试是一个用于评估和分析自然语言理解系统的平台,它包含了九个不同的 NLP 任务,涵盖了句子级别和句子对级别的语言理解能力。¹²
GLUE 基准测试的计算方法是,首先将每个任务的模型输出与人工标注的答案进行比较,计算出每个任务的得分,然后对所有任务的得分进行加权平均,得到一个总体的 GLUE 得分。¹²
不同的任务有不同的评价指标,例如准确率、F1 值、皮尔逊相关系数等。¹² 不同的任务也有不同的权重,例如 MNLI 的权重是 5,而 WNLI 的权重是 0.5。¹² 权重的设置主要考虑了任务的难度、数据量和多样性等因素。¹
GLUE 基准测试提供了一个公开的排行榜,用于展示不同的模型在各个任务和总体得分上的表现。¹³ 目前,排行榜上的最高得分是 90.8,由 ALBERT+DAAF+NAS 模型取得。³
Source: Conversation with Bing, 2023/5/7
(1) GLUE Benchmark. https://gluebenchmark.com/.
(2) GLUE基准数据集介绍及下载 - 知乎. https://zhuanlan.zhihu.com/p/135283598.
(3) 【HugBert04】GLUE:BERT类模型的通用评估基准 - 知乎. https://zhuanlan.zhihu.com/p/151818251.
3、BERT 模型有哪些局限性和挑战?有哪些可能的改进方向?
BERT 模型是一种基于 Transformer 的双向编码器表征模型,它在大量的自然语言处理任务中取得了突破性的效果。¹² 但是,BERT 模型也存在一些局限性和挑战,例如:
- BERT 模型的参数量很大,导致存储和训练都比较消耗资源。³
- BERT 模型使用了掩码语言模型(MLM)作为预训练目标,但是这种方式会导致预训练和微调阶段的输入不一致,因为预训练时有部分词被掩码,而微调时没有。
- BERT 模型使用了下一句预测(NSP)作为预训练目标,但是这种方式并没有真正捕捉到句子之间的连贯性和逻辑关系,而是更倾向于依赖主题信息。
- BERT 模型对中文的处理是以字为单位的,而忽略了词语和短语等更高层次的语义信息。
针对这些局限性和挑战,有一些可能的改进方向,例如:
- 使用词向量因式分解(Factorized Embedding Parameterization)和跨层参数共享(Cross-layer Parameter Sharing)等技术来减少模型的参数量和内存消耗。³
- 使用动态掩码(Dynamic Masking)或者置换语言模型(Permutation Language Model)等技术来解决预训练和微调阶段的输入不一致问题。
- 使用句子顺序预测(Sentence Order Prediction)或者对比学习(Contrastive Learning)等技术来替代下一句预测(NSP),从而更好地学习句子之间的连贯性和逻辑关系。
- 使用词片段掩码(Whole Word Masking)或者实体级别掩码(Entity-level Masking)等技术来引入词语和短语等更高层次的语义信息。
Source: Conversation with Bing, 2023/5/7
(1) BERT的若干改进思路 - 知乎. https://zhuanlan.zhihu.com/p/168100983.
(2) 基于BERT的几种改进模型 - 知乎. https://zhuanlan.zhihu.com/p/444588460.
(3) 深度盘点:BERT 模型的优化改进方法! - 知乎专栏. https://zhuanlan.zhihu.com/p/520464164.
4、请简要说明 BERT 有哪些的改进模型,以及具体改进了什么?
BERT有很多改进模型,根据搜索结果,我为你列举了以下几个¹²³:
- ERNIE:百度提出的模型,引入了词语、短语和实体等知识信息,以及多任务预训练和对话语言模型。
- BERT-WWM:哈工大讯飞联合实验室提出的模型,使用了whole word masking的方法,即将完整的词语或实体进行掩盖,而不是单个字或字根。
- RoBERTa:Facebook提出的模型,使用了更大的训练数据集和batch size,用字节编码代替word piece,调整了Adam优化器的参数,并移除了NSP任务。RoBERTa还使用了动态masking的方法,即每次对同一个句子采用不同的mask方式,增强了数据的多样性和正则化效果。
- XLNet:CMU和Google提出的模型,使用了permutation language model的方法,即将输入序列进行随机排列,然后预测每个位置的原始token,从而避免了BERT中mask token带来的预训练和微调不匹配的问题。
Source: Conversation with Bing, 2023/5/7
(1) BERT的若干改进思路 - 知乎. https://zhuanlan.zhihu.com/p/168100983.
(2) BERT:最新BERT模型应用与改进论文集锦【附源码】 - 知乎专栏. https://zhuanlan.zhihu.com/p/157554937.
(3) 深度盘点:BERT 模型的优化改进方法! - 知乎. https://zhuanlan.zhihu.com/p/520464164.
5、BERT 的核心机制是什么?它有什么优势?
BERT的核心机制是使用Transformer的encoder结构,以及Masked Language Model和Next Sentence Prediction两种预训练任务,来学习语言的双向表示¹²。它有以下几个优势:
- 它可以利用大量的无标注文本数据,通过自监督学习的方式,提取语言的深层语义信息,从而提高下游任务的性能¹²。
- 它可以捕捉到单词的上下文信息,而不是像传统的词向量那样只考虑单词本身或者固定的窗口范围内的信息¹²。
- 它可以处理多种类型的自然语言处理任务,包括分类、回归、序列标注、问答等,只需要在预训练模型的基础上添加少量的任务特定层,并进行微调¹²。
- 它可以有效地利用Transformer的并行计算能力,加速模型的训练和推理过程¹²。
Source: Conversation with Bing, 2023/5/7
(1) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
(2) BERT 详解 - 知乎. https://zhuanlan.zhihu.com/p/103226488.
(3) 词向量哪个更好?Bert还是Glove? - 知乎. https://zhuanlan.zhihu.com/p/393372364.
BERT 的网络结构
6、BERT 的基本结构是怎样的?它由哪些部分组成?
BERT的基本结构是由多层Transformer的encoder组成的,它由以下几个部分组成¹²:
- 输入层:它将输入的文本序列转换为词向量,位置向量和段落向量的和,用于表示每个词的信息。它还添加了特殊的标记,如 [CLS] 和 [SEP],用于区分不同的句子和任务。
- 中间层:它由多个相同的子层组成,每个子层包含一个多头自注意力机制和一个前馈神经网络,以及两个层归一化操作。它可以对输入的序列进行编码,捕捉词之间的双向关系。
- 输出层:它根据不同的下游任务,对中间层的输出进行微调,添加一些额外的层,如分类层、序列标注层、问答层等。它可以利用预训练好的语言表示,提高各种自然语言处理任务的性能。
Source: Conversation with Bing, 2023/5/7
(1) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
(2) BERT原理和结构详解_bert结构______miss的博客-CSDN博客. https://blog.csdn.net/u011412768/article/details/108015783.
(3) Transformer,BERT模型介绍 - 知乎. https://zhuanlan.zhihu.com/p/365656960.
7、请解释一下 BERT 模型中的编码器的作用是什么?
BERT模型中的编码器的作用是对输入的文本序列进行深层的双向编码,提取每个词和整个句子的语义表示¹²。编码器由多个相同的子层组成,每个子层包含一个多头自注意力机制和一个前馈神经网络,以及两个层归一化操作²³。多头自注意力机制可以让每个词同时关注序列中的其他词,捕捉词之间的上下文关系;前馈神经网络可以对每个词进行非线性变换,增强模型的表达能力;层归一化可以稳定模型的训练过程,防止梯度消失或爆炸³。编码器的输出可以用于不同的下游任务,如分类、回归、序列标注、问答等,只需要在编码器的基础上添加少量的任务特定层,并进行微调¹²。
Source: Conversation with Bing, 2023/5/7
(1) 基于Transformer的双向编码器表示(BERT)——结构和训练 - 知乎. https://zhuanlan.zhihu.com/p/125655365.
(2) Bert:不就是transformer的编码器吗! - 知乎. https://zhuanlan.zhihu.com/p/301146068.
(3) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
8、请简要描述一下 BERT 模型中的位置编码是什么,并举例说明。
BERT的位置编码是可学习的Embedding,因此不仅可以标记位置,还可以学习到这个位置有什么用。
BERT选择这么做的原因可能是,相比于Transformer,BERT训练所用的数据量充足,完全可以让模型自己学习。
BERT要用可学习的位置编码而不是静态绝对位置编码的原因可能有以下几点¹²:
- 可学习的位置编码可以让模型自适应地调整位置信息,而不是依赖于固定的公式,这可能会提高模型的灵活性和泛化能力¹。
- 可学习的位置编码可以避免一些潜在的问题,比如静态绝对位置编码对于超过预设最大长度的序列无法处理,或者静态绝对位置编码对于不同长度的序列之间的相似度计算不够准确²。
- 可学习的位置编码可以与BERT的预训练目标(Masked Language Model和Next Sentence Prediction)更好地配合,因为这些目标都需要模型对输入序列中的词进行预测或判断,而不是只关注序列整体的表示²。
Source: Conversation with Bing, 2023/5/7
(1) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
(2) [1810.04805] BERT: Pre-training of Deep Bidirectional … https://arxiv.org/abs/1810.04805.
(3) BERT-分词和编码 - 知乎. https://zhuanlan.zhihu.com/p/369795659.
举例说明:
在BERT中,与一般的词嵌入编码类似,位置编码也是随机生成且可训练的,维度为[max_seq_length, embedding_size],其中 max_seq_length 代表序列长度, embedding_size 代表每一个token对应的向量长度。
9、BERT 模型中的 next sentence prediction 是什么?它有什么作用?
Next sentence prediction (NSP) 是 BERT 模型预训练时使用的一种目标,它的作用是让 BERT 学习句子之间的连贯性和逻辑关系。¹²
NSP 的具体过程是,给 BERT 输入两个句子 A 和 B,然后让 BERT 判断 B 是否是 A 的下一句。¹² 这两个句子有一半的概率是来自同一篇文章的连续段落,另一半的概率是来自不同文章的随机段落。²³
NSP 的输出是一个二分类的结果,如果 B 是 A 的下一句,输出 IsNextSentence,否则输出 NotNextSentence。¹²
NSP 的目的是让 BERT 能够理解句子之间的上下文关系,从而提高其在自然语言理解任务上的表现。¹²
Source: Conversation with Bing, 2023/5/7
(1) Next Sentence Prediction with BERT - Scaler Topics. https://www.scaler.com/topics/nlp/bert-next-sentence-prediction/.
(2) Next Sentence Prediction With BERT | Towards Data Science. https://towardsdatascience.com/bert-for-next-sentence-prediction-466b67f8226f.
(3) BERT - Hugging Face. https://huggingface.co/docs/transformers/model_doc/bert.
(4) KG-BERT: BERT for Knowledge Graph Completion - arXiv. https://arxiv.org/pdf/1909.03193.pdf.
(5) Can BERT do the next-word-predict task? - Data Science … https://datascience.stackexchange.com/questions/46377/can-bert-do-the-next-word-predict-task.
10、BERT 模型中的 segment embedding 是什么?它有什么作用?
Segment embedding 是 BERT 模型中的一种嵌入向量,它的作用是帮助 BERT 区分输入中的不同句子。¹²
Segment embedding 的具体过程是,给 BERT 输入两个句子 A 和 B,然后在每个句子的词向量上加上一个固定的向量,表示该词属于哪个句子。¹² 例如,句子 A 的词向量上加上一个全为 0 的向量,句子 B 的词向量上加上一个全为 1 的向量。³ 这样,BERT 就能通过 segment embedding 来识别句子的边界和顺序。¹²
Segment embedding 只有两种可能的向量,分别对应句子 A 和句子 B。¹² 如果输入只有一个句子,那么 segment embedding 就是全为 0 的向量。³
Source: Conversation with Bing, 2023/5/7
(1) Embeddings in BERT - OpenGenus IQ: Computing Expertise … https://iq.opengenus.org/embeddings-in-bert/.
(2) What are the segment embeddings and position embeddings … https://ai.stackexchange.com/questions/10133/what-are-the-segment-embeddings-and-position-embeddings-in-bert.
(3) 【译】为什么BERT有3个嵌入层,它们都是如何实现的 - 博客园. https://www.cnblogs.com/d0main/p/10447853.html.
(4) Understanding BERT — (Bidirectional Encoder … https://towardsdatascience.com/understanding-bert-bidirectional-encoder-representations-from-transformers-45ee6cd51eef.
11、BERT 中的自注意力机制是如何计算的?它有什么作用?
BERT中的自注意力机制是一种用于计算序列中每个词与其他词之间的相关性的方法¹²。它有以下几个作用:
- 它可以让模型捕捉到序列中的长距离依赖关系,比如两个句子之间的语义关联,或者一个句子中的主谓一致等¹。
- 它可以让模型对序列中每个词进行双向编码,即同时考虑左右两边的上下文信息,而不是像传统的单向模型那样只能看到一边的信息¹。
- 它可以让模型根据不同的任务和输入动态地调整注意力权重,从而实现更灵活和有效的表示学习²。
自注意力机制的计算过程如下¹²:
- 首先,对于输入序列中的每个词,分别计算其查询(query)、键(key)和值(value)向量,这些向量都是通过一个线性变换得到的。
- 然后,对于每个词,将其查询向量与其他所有词的键向量进行点积运算,得到一个注意力得分矩阵。
- 接着,对注意力得分矩阵进行缩放处理和softmax归一化,得到一个注意力权重矩阵。
- 最后,将注意力权重矩阵与其他所有词的值向量进行加权求和,得到每个词的输出向量。
为了提高模型的表达能力和并行效率,BERT还使用了多头自注意力机制,即将输入序列分成多个子空间,然后在每个子空间上分别进行自注意力计算,最后将各个子空间的输出向量拼接起来¹²。
Source: Conversation with Bing, 2023/5/7
(1) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
(2) [1810.04805] BERT: Pre-training of Deep Bidirectional … https://arxiv.org/abs/1810.04805.
(3) Huggingface简介及BERT代码浅析 - 知乎. https://zhuanlan.zhihu.com/p/120315111.
12、BERT 的多头自注意力机制是什么?它有什么作用?
BERT的多头自注意力机制是一种将自注意力机制分成多个子空间,然后在每个子空间上分别进行自注意力计算,最后将各个子空间的输出向量拼接起来的方法¹²。它有以下几个作用:
- 它可以让模型关注不同方面的信息,比如语义、语法、情感等¹²。
- 它可以让模型增加表示能力和并行效率,比如可以捕捉到更多的特征组合和交互¹²。
- 它可以让模型更容易适应不同的任务和输入,比如可以根据任务的需要调整不同头的权重²。
多头自注意力机制的计算过程如下¹²:
- 首先,对于输入序列中的每个词,分别计算其查询(query)、键(key)和值(value)向量,这些向量都是通过一个线性变换得到的。
- 然后,将每个词的查询、键和值向量分成多个头,每个头对应一个子空间,每个子空间有一个独立的维度大小。
- 接着,在每个子空间上,对每个词,将其查询向量与其他所有词的键向量进行点积运算,得到一个注意力得分矩阵。
- 接下来,对注意力得分矩阵进行缩放处理和softmax归一化,得到一个注意力权重矩阵。
- 最后,将注意力权重矩阵与其他所有词的值向量进行加权求和,得到每个词的输出向量。然后将各个子空间的输出向量拼接起来,得到最终的输出序列。
Source: Conversation with Bing, 2023/5/7
(1) Multi-headed Self-attention(多头自注意力)机制介绍 - 知乎. https://zhuanlan.zhihu.com/p/365386753.
(2) 拆 Transformer 系列二:Multi- Head Attention 机制详解 - 知乎. https://zhuanlan.zhihu.com/p/109983672.
(3) (多头)自注意力机制 - 知乎. https://zhuanlan.zhihu.com/p/484524337.
13、BERT 中的前馈神经网络层是如何设计的?它有什么功能?
BERT中的前馈神经网络层是一种在每个编码器层中使用的全连接层,它有两个线性变换和一个激活函数组成¹。它有以下几个功能:
- 它可以增加模型的非线性能力,从而提高模型的拟合能力¹²。
- 它可以增加模型的深度,从而提高模型的抽象能力¹²。
- 它可以增加模型的参数量,从而提高模型的表达能力¹²。
前馈神经网络层的计算过程如下¹:
- 首先,对于输入序列中的每个词,将其向量与一个权重矩阵相乘,得到一个中间向量。
- 然后,对中间向量应用一个激活函数 GELU,得到一个激活向量。
- 最后,将激活向量与另一个权重矩阵相乘,得到输出向量。
Source: Conversation with Bing, 2023/5/7
(1) [1810.04805] BERT: Pre-training of Deep Bidirectional … https://arxiv.org/abs/1810.04805.
(2) GitHub - google-research/bert: TensorFlow code and pre … https://github.com/google-research/bert.
(3) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
14、BERT 中的残差连接是如何添加的?它有什么意义?
BERT中的残差连接是在每个Transformer的block中添加的,它可以将block的输入和输出相加,然后进行层归一化。¹² 它有以下意义:¹³
- 它可以避免信息的丢失,因为残差连接可以保留原始输入的信息,同时增加网络中获取的新知识。
- 它可以缓解梯度消失,因为残差连接可以使得错误信号不经过任何中间权重矩阵变换直接传播到低层,一定程度上保持了梯度的大小。
- 它可以解决网络退化,因为残差连接可以使得冗余的层学习到恒等映射,而不是复杂的非线性映射,从而避免了模型效果变差的问题。
- 它可以使得 BERT 的层数变得更多,提高模型的特征表达能力。
Source: Conversation with Bing, 2023/5/7
(1) 【必知必会-2】残差连接 - 知乎. https://zhuanlan.zhihu.com/p/449792026.
(2) [1810.04805] BERT: Pre-training of Deep Bidirectional … https://arxiv.org/abs/1810.04805.
(3) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
15、BERT 中的层归一化是如何操作的?它有什么效果?
BERT中的层归一化是对一层的输入向量进行归一化操作,使得每个向量的均值为0,方差为1。¹² 它有以下效果:¹³
- 它可以加快网络的收敛速度,因为层归一化可以减少梯度的变化,使得每层的输入分布更加稳定。
- 它可以提高模型的泛化能力,因为层归一化可以减少过拟合的风险,使得模型对输入的噪声和扰动更加鲁棒。
- 它可以简化模型的训练,因为层归一化可以减少对学习率和初始化的依赖,使得模型更容易优化。
Source: Conversation with Bing, 2023/5/7
(1) BERT模型入门系列(四):Transformer模型详解 - 知乎. https://zhuanlan.zhihu.com/p/351294572.
(2) [1810.04805] BERT: Pre-training of Deep Bidirectional … https://arxiv.org/abs/1810.04805.
(3) BERT原理和结构详解_bert结构______miss的博客-CSDN博客. https://blog.csdn.net/u011412768/article/details/108015783.
16、前馈神经网络中为什么第一个线性变换要加激活函数,而第二个线性变换不加激活函数?为什么不是第一个线性变换不加激活函数,而第二个线性变换加激活函数?
- 第一个线性变换要加激活函数,是为了增加模型的非线性能力,从而提高模型的拟合能力。如果不加激活函数,那么两个线性变换就相当于一个线性变换,模型的复杂度就会降低。
- 第二个线性变换不加激活函数,是为了保持输出向量的维度和输入向量的维度一致,从而方便后续的层进行计算。如果加了激活函数,那么输出向量的值域就会受到限制,比如ReLU会将负数变为零,这可能会损失一些信息。
- 为什么不是第一个线性变换不加激活函数,而第二个线性变换加激活函数呢?这可能是因为第一个线性变换是对输入序列进行初步的编码,需要保留更多的信息,而第二个线性变换是对中间向量进行进一步的处理,需要增加更多的非线性能力。当然,这也不是唯一的可能,也许有其他的设计理由或实验结果支持这种选择。
17、请解释一下 BERT 模型中的 warm-up steps 是什么?它有什么作用?
BERT模型中的warm-up steps是指在训练的初始阶段,使用较大的学习率来加速模型的收敛¹²³。它有以下作用:
- 避免模型在训练开始时陷入局部最优或鞍点¹。
- 避免模型输出层附近的梯度过大,导致前向全连接层的不稳定变化²。
- 适应预训练模型的参数,避免过度微调³。
一般来说,warm-up steps的选择与训练步数、批量大小、网络深度等因素有关。一个常用的经验是设置warm-up steps为总训练步数的10%²。例如,如果总训练步数为10000,那么warm-up steps可以设置为1000。当然,这也需要根据具体的任务和数据进行调整。
Source: Conversation with Bing, 2023/5/7
(1) Optimizer and scheduler for BERT fine-tuning - Stack Overflow. https://stackoverflow.com/questions/60120043/optimizer-and-scheduler-for-bert-fine-tuning.
(2) Bert在fine-tune时训练的5种技巧 - 知乎. https://zhuanlan.zhihu.com/p/524036087.
(3) How to choose warm-up steps depending on the train steps … https://github.com/google-research/bert/issues/369.
18、使用了 warm-up steps 后,学习率的变化曲线是怎么样的?
使用了warm-up steps后,学习率的变化曲线是先线性增加,然后按比例递减的¹²³。这样做的目的是在训练开始时使用较小的学习率,避免模型陷入局部最优或鞍点,然后逐渐提高学习率,加速模型的收敛,最后再降低学习率,保证模型的稳定性。一个常见的学习率曲线如下图所示²:

其中,warm-up steps是指在训练步数(training steps)中占一定比例(warm-up proportion)的步数。例如,如果总训练步数为10000,warm-up proportion为0.1,那么warm-up steps就是1000。在这些步数内,学习率从0线性增加到初始值(initial learning rate)。之后,学习率按比例递减,直到达到最小值(minimum learning rate)或训练结束。
Source: Conversation with Bing, 2023/5/7
(1) In the context of Deep Learning, what is training warmup steps. https://datascience.stackexchange.com/questions/55991/in-the-context-of-deep-learning-what-is-training-warmup-steps.
(2) Warmup steps in deep learning - Data Science Stack Exchange. https://datascience.stackexchange.com/questions/103022/warmup-steps-in-deep-learning.
(3) python - Adam optimizer with warmup on PyTorch - Stack … https://stackoverflow.com/questions/65343377/adam-optimizer-with-warmup-on-pytorch.
19、什么是模型的暴露偏差?
模型的暴露偏差是指在生成序列时,模型依赖于自身生成的错误词,而不是真实的词,导致生成质量下降的现象。例如,如果一个模型要生成一个句子,它会根据上下文生成第一个词,然后根据第一个词生成第二个词,以此类推。如果第一个词是错误的,那么后面的词也很可能是错误的,因为模型没有看到真实的第一个词。这就是暴露偏差的问题。为了避免这个问题,一种方法是在训练过程中,让模型看到真实的词而不是自身生成的词,这就是masked language model的做法。
20、如何实现让模型看到真实的词而不是自身生成的词?
一种实现让模型看到真实的词而不是自身生成的词的方法是使用teacher forcing。teacher forcing是指在训练过程中,模型的输入是真实的词,而不是上一步生成的词。例如,如果一个模型要生成一个句子,它会根据上下文生成第一个词,然后根据真实的第一个词生成第二个词,以此类推。这样做的好处是可以避免暴露偏差,提高模型的学习效率和生成质量。但是,这样做也有一些缺点,例如可能导致模型过拟合训练数据,或者在测试时出现不一致的问题。
激活函数、损失函数、优化器
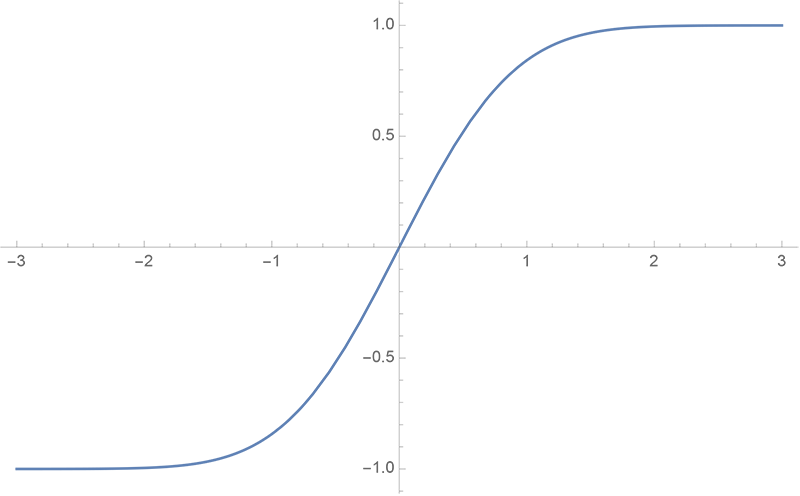
21、BERT 中各层的激活函数分别是什么?以及它们的曲线图。
BERT中各层的激活函数都是GELU,即高斯误差线性单元¹。GELU的表达式为:
GELU(x) = x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
其中,torch.erf是误差函数,其图像如下:
GELU的曲线图如下:
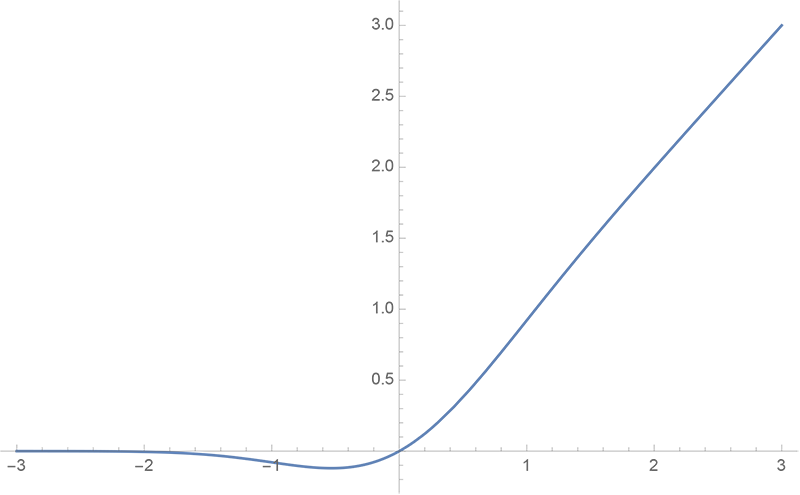
图片来源⁴
Source: Conversation with Bing, 2023/5/7
(1) BERT中的激活函数GELU:高斯误差线性单元 - 知乎. https://zhuanlan.zhihu.com/p/349492378.
(2) 详解激活函数(Sigmoid/Tanh/ReLU/Leaky ReLu等) - 知乎专栏. https://zhuanlan.zhihu.com/p/427541517.
(3) [1810.04805] BERT: Pre-training of Deep Bidirectional … https://arxiv.org/abs/1810.04805.
(4) GELU 的两个初等函数近似是怎么来的 - 科学空间. https://kexue.fm/archives/7309
22、GELU 和 ReLU 有什么区别?
GELU 和 ReLU 的区别和联系如下:
- ReLU 是整流线性单元,它的函数形式是 f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x),即当输入为正时,输出等于输入,当输入为负时,输出为零。¹
- GELU 是高斯误差线性单元,它的函数形式是 f ( x ) = x t i m e s P ( X < = x ) = x t i m e s p h i ( x ) f(x)=x \\times P(X<=x)=x \\times \\phi (x) f(x)=xtimesP(X<=x)=xtimesphi(x),其中 x x x 是输入值, X X X 是服从标准正态分布的随机变量, p h i ( x ) \\phi (x) phi(x) 是标准正态分布的累积分布函数。²
- ReLU 和 GELU 的共同点是,它们都是非线性激活函数,都可以增加神经网络的表达能力和拟合能力。它们都可以避免梯度消失问题,因为它们在正值区域都有一个恒定的梯度。
- ReLU 和 GELU 的不同点是,ReLU 在负值区域的梯度为零,而 GELU 在负值区域有一个非零的梯度,从而避免了死亡神经元的问题。³ 另外,GELU 在 0 附近比 ReLU 更加平滑,因此在训练过程中更容易收敛。⁴
- 目前的研究表明,在一些深度学习模型中,如 Transformer、BERT、GPT-2 等,使用 GELU 激活函数可以提供更好的性能和效果。²⁴
Source: Conversation with Bing, 2023/5/7
(1) 从ReLU到GELU,一文概览神经网络的激活函数 - 知乎. https://zhuanlan.zhihu.com/p/98863801.
(2) BERT中的激活函数GELU:高斯误差线性单元 - 知乎. https://zhuanlan.zhihu.com/p/349492378.
(3) GELU激活函数_relu和gelu的区别_ZhangTuTu丶的博客-CSDN博客. https://blog.csdn.net/qq_41296039/article/details/130148750.
(4) RELU和GELU的区别和联系 - CSDN文库. https://wenku.csdn.net/answer/ab7d9156a9dc497798b8cbd5e562a6f6.
23、请解释一下 BERT 模型的训练过程中的损失函数是什么?
BERT模型的训练过程中的损失函数是由两部分组成的:¹²³
- 第一部分是来自Masked LM的单词级别分类任务,用于预测句子中被掩盖的词,使用交叉熵损失函数。
- 第二部分是句子级别的分类任务,用于判断输入的两个句子是不是上下文关系,使用二元交叉熵损失函数。
两个损失函数的表达式分别是:
- 交叉熵损失函数:
L
C
E
=
−
∑
i
=
1
N
y
i
log
y
^
i
L_{CE} = -\sum_{i=1}^N y_i \log \hat{y}_i
LCE=−i=1∑Nyilogy^i
其中, N N N是词汇表的大小, y i y_i yi是第 i i i个词的真实标签(0或1), y ^ i \hat{y}_i y^i是第 i i i个词的预测概率。 - 二元交叉熵损失函数:
L
B
C
E
=
−
∑
i
=
1
M
(
y
i
log
y
^
i
+
(
1
−
y
i
)
log
(
1
−
y
^
i
)
)
L_{BCE} = -\sum_{i=1}^M (y_i \log \hat{y}_i + (1-y_i) \log (1-\hat{y}_i))
LBCE=−i=1∑M(yilogy^i+(1−yi)log(1−y^i))
其中, M M M是句子对的数量, y i y_i yi是第 i i i个句子对的真实标签(0或1), y ^ i \hat{y}_i y^i是第 i i i个句子对的预测概率。
Source: Conversation with Bing, 2023/5/7
(1) 原来你是这样的BERT,i了i了! —— 超详细BERT介绍(二 … https://bing.com/search?q=BERT+%e6%a8%a1%e5%9e%8b+%e6%8d%9f%e5%a4%b1%e5%87%bd%e6%95%b0.
(2) BERT模型的损失函数怎么定义的? - 知乎. https://www.zhihu.com/question/328123545.
(3) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
(4) 原来你是这样的BERT,i了i了! —— 超详细BERT介绍(二 … https://www.cnblogs.com/wangzb96/p/bert_pretrain.html.
24、请解释一下 BERT 模型的优化器是什么?
BERT模型的优化器是Adam¹²³,它是一种基于梯度下降的自适应学习率的优化算法。它可以根据每个参数的梯度的一阶矩(均值)和二阶矩(方差)动态调整每个参数的学习率,从而提高训练效率和稳定性。Adam优化器的表达式如下:
θ t + 1 = θ t − α v ^ t + ϵ m ^ t \theta_{t+1} = \theta_t - \frac{\alpha}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t θt+1=θt−v^t+ϵαm^t
其中, θ t \theta_t θt是第 t t t步的参数, α \alpha α是学习率, m ^ t \hat{m}_t m^t是第 t t t步的梯度的指数移动平均值, v ^ t \hat{v}_t v^t是第 t t t步的梯度平方的指数移动平均值, ϵ \epsilon ϵ是一个很小的常数,用于防止除零错误。
Source: Conversation with Bing, 2023/5/7
(1) 深度盘点:BERT 模型的优化改进方法! - 知乎专栏. https://zhuanlan.zhihu.com/p/520464164.
(2) 【译】BERT Fine-Tuning 指南(with PyTorch) - 知乎. https://zhuanlan.zhihu.com/p/143209797.
(3) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
BERT 的超参数
25、BERT 的超参数有哪些,详细说明每个超参数的作用
BERT的超参数有以下几种,每个超参数的作用如下:
| 超参数 | 作用 |
|---|---|
| vocab_size | 词汇表的大小,即模型可以识别的不同的token的数量 |
| hidden_size | Transformer中编码器和解码器的隐藏层的大小,也是词嵌入的维度 |
| num_hidden_layers | Transformer中编码器和解码器的层数 |
| num_attention_heads | Transformer中每个隐藏层的自注意力头的数量 |
| intermediate_size | Transformer中每个隐藏层的前馈网络的大小 |
| hidden_act | Transformer中隐藏层的激活函数,通常是gelu或relu |
| hidden_dropout_prob | Transformer中隐藏层的dropout概率 |
| attention_probs_dropout_prob | Transformer中自注意力机制的dropout概率 |
| max_position_embeddings | Transformer中位置嵌入的最大长度,即模型可以处理的序列的最大长度 |
| type_vocab_size | Transformer中句子类型嵌入的大小,即模型可以区分的不同类型句子(如单句或句对)的数量 |
| initializer_range | 模型参数初始化时使用的标准差 |
根据不同的模型规模,BERT有不同的超参数设置,如下表所示¹:
| 模型规模 | vocab_size | hidden_size | num_hidden_layers | num_attention_heads | intermediate_size | max_position_embeddings |
|---|---|---|---|---|---|---|
| BERT-Base | 30522 (英文) / 21128 (中文) | 768 | 12 | 12 | 3072 | 512 |
| BERT-Large | 30522 (英文) / 21128 (中文) | 1024 | 24 | 16 | 4096 | 512 |
¹: https://zhuanlan.zhihu.com/p/143209797
Source: Conversation with Bing, 2023/5/7
(1) 【译】BERT Fine-Tuning 指南(with PyTorch) - 知乎. https://zhuanlan.zhihu.com/p/143209797.
(2) BERT参数量计算 - 知乎. https://zhuanlan.zhihu.com/p/91903871.
(3) 图解BERT:通俗的解释BERT是如何工作的 - 知乎. https://zhuanlan.zhihu.com/p/364966458.
26、BERT 中 dropout 的作用是什么?BERT 中各层的 dropout 分别是多少? dropout 一般取什么值?
BERT 中 dropout 的作用和取值如下:
- Dropout 是一种正则化技术,用于防止过拟合,它的原理是在训练过程中随机丢弃一些神经元的输出,从而减少模型的复杂度和依赖性。¹
- BERT 中有两种 dropout,一种是 attention_probs_dropout_prob,用于 dropout attention 的权重矩阵,另一种是 hidden_dropout_prob,用于 dropout transformer 层的输出。²
- BERT 的原始论文中使用了 0.1 的 dropout 概率,这也是默认的配置值。²³ 但是不同的任务和数据集可能需要不同的 dropout 概率,一般来说,dropout 概率越高,正则化效果越强,但是也可能导致欠拟合。⁴
- Dropout 概率的选择需要根据实验结果进行调整,一般来说,可以从较小的值开始尝试,比如 0.1 或 0.2,然后逐渐增加或减少,观察模型的性能变化。⁵ 也可以使用网格搜索或贝叶斯优化等方法来寻找最优的 dropout 概率。⁴
Source: Conversation with Bing, 2023/5/7
(1) BERT - Hugging Face. https://huggingface.co/docs/transformers/model_doc/bert.
(2) BERT — transformers 3.0.2 documentation - Hugging Face. https://huggingface.co/transformers/v3.0.2/model_doc/bert.html.
(3) Transformers pretrained model with dropout setting. https://stackoverflow.com/questions/64947064/transformers-pretrained-model-with-dropout-setting.
(4) How BERT’s Dropout Fine-Tuning Affects Text Classification?. https://link.springer.com/chapter/10.1007/978-3-030-76508-8_11.
(5) Understanding BERT architecture - Medium. https://medium.com/analytics-vidhya/understanding-bert-architecture-3f35a264b187.
27、BERT 模型中的 masked language model 的 mask rate 是什么?如何确定合适的 mask rate?
BERT模型中的masked language model的mask rate是指在预训练过程中,随机选择一定比例的词(token)进行掩盖(mask),然后让模型根据上下文来预测被掩盖的词¹²。它有以下作用:
- 增加模型的泛化能力,因为masking可以让模型不依赖于某些特定的词,而是学习到更多的语义和语法信息¹。
- 促进模型的双向理解,因为masking可以让模型同时考虑左右两边的词,而不是像传统的语言模型那样只能从左到右或从右到左¹。
- 避免模型的暴露偏差,因为masking可以防止模型在生成序列时依赖于自身生成的错误词,而是始终使用真实的词²。
如何确定合适的mask rate是一个没有固定答案的问题,它可能取决于数据集的大小、复杂度、噪声等因素。BERT模型中使用了15%的mask rate,这是基于一个假设,即如果掩盖太多的词,模型就没有足够的上下文来学习好的表示;如果掩盖太少的词,模型就不能充分利用预训练数据³。但这个比例并不是普遍适用的,有些研究发现,对于更大的模型,使用更高的mask rate(例如40%)可以取得更好的效果³。因此,确定合适的mask rate可能需要根据具体的任务和数据进行实验和调整。
Source: Conversation with Bing, 2023/5/7
(1) [2202.08005] Should You Mask 15% in Masked Language … https://arxiv.org/abs/2202.08005.
(2) End-to-end Masked Language Modeling with BERT. https://keras.io/examples/nlp/masked_language_modeling/.
(3) Should You Mask 15% in Masked Language Modeling?. https://aclanthology.org/2023.eacl-main.217.pdf.
28、BERT 模型中的 masked language model 的 mask rate 是多少?
BERT模型中的masked language model的15%的比例是这样划分的:¹²⁴
- 在每个句子中,随机选择15%的词(token)进行掩盖(mask)。
- 在被选择的词中,80%的概率用[MASK]符号替换,10%的概率用随机的词替换,10%的概率保持不变。
- 在训练过程中,模型只计算被掩盖或替换的词的损失函数,忽略其他词。
这样做的目的是增加模型的泛化能力和双向理解,同时避免模型的暴露偏差²。
Source: Conversation with Bing, 2023/5/7
(1) [2202.08005] Should You Mask 15% in Masked Language … https://arxiv.org/abs/2202.08005.
(2) Masked-Language Modeling With BERT - Towards Data Science. https://towardsdatascience.com/masked-language-modelling-with-bert-7d49793e5d2c.
(3) Unmasking BERT: The Key to Transformer Model Performance. https://neptune.ai/blog/unmasking-bert-transformer-model-performance.
(4) Should You Mask 15% in Masked Language Modeling?. https://aclanthology.org/2023.eacl-main.217.pdf.
29、BERT 模型中的 special tokens 有哪些?它们有什么作用?
Special tokens 是 BERT 模型中的一些特殊的标记符号,它们有不同的作用,例如:
- [CLS] 是一个分类标记,它放在每个输入序列的开头,用于表示该序列的语义信息。¹² BERT 模型在预训练和微调时都会使用 [CLS] 标记的输出向量作为句子向量或者分类向量。¹²
- [SEP] 是一个分隔标记,它放在每个句子的结尾,用于表示句子的边界。¹² BERT 模型在处理两个句子的输入时,会使用 [SEP] 标记来区分句子 A 和句子 B。¹²
- [MASK] 是一个掩码标记,它放在一些随机选择的词上,用于表示这些词被遮蔽了。¹² BERT 模型在预训练时,会使用掩码语言模型(MLM)作为目标,来预测被 [MASK] 标记替换的词。¹²
- [UNK] 是一个未知标记,它放在一些词汇表中不存在的词上,用于表示这些词是未知的。³ BERT 模型在处理一些生僻词或者错误拼写的词时,会使用 [UNK] 标记来替换它们。³
Source: Conversation with Bing, 2023/5/7
(1) How special tokens in BERT-Transformers work?. https://datascience.stackexchange.com/questions/112598/how-special-tokens-in-bert-transformers-work.
(2) BERT Preprocessing with TF Text | TensorFlow. https://www.tensorflow.org/text/guide/bert_preprocessing_guide.
(3) bert language model - How to add new special token to the … https://stackoverflow.com/questions/69191305/how-to-add-new-special-token-to-the-tokenizer.
30、BERT 中的 [CLS] 的向量可以直接用来进行分类吗?效果怎么样?
BERT 模型中的 [CLS] 可以直接用来进行分类,因为它是一个特殊的标记,它放在每个输入序列的开头,用于表示该序列的语义信息。¹² BERT 模型在预训练和微调时都会使用 [CLS] 标记的输出向量作为句子向量或者分类向量。¹²
使用 [CLS] 进行分类的效果取决于具体的任务和数据集,有些任务可能会比其他任务更容易从 [CLS] 中提取有效的信息。³ 一般来说,使用 [CLS] 进行分类的效果还是不错的,因为它能够捕捉到句子中所有词的上下文信息,而不是简单地平均或者池化所有词的向量。⁴
但是,使用 [CLS] 进行分类也有一些局限性和挑战,例如:
- [CLS] 只是一个固定长度的向量,它可能无法充分地表示长句子或者多句子的复杂语义。
- [CLS] 的输出向量是基于预训练时的下一句预测(NSP)目标而训练的,这种方式并没有真正捕捉到句子之间的连贯性和逻辑关系,而是更倾向于依赖主题信息。
- [CLS] 的输出向量可能会受到输入序列中其他词的干扰或者噪声,导致分类效果下降。
Source: Conversation with Bing, 2023/5/7
(1) Why Bert transformer uses [CLS] token for classification … https://stackoverflow.com/questions/62705268/why-bert-transformer-uses-cls-token-for-classification-instead-of-average-over.
(2) BERT — transformers 3.0.2 documentation - Hugging Face. https://huggingface.co/transformers/v3.0.2/model_doc/bert.html.
(3) Bert-Transformer : Why Bert transformer uses [CLS] token for … https://datascience.stackexchange.com/questions/77044/bert-transformer-why-bert-transformer-uses-cls-token-for-classification-inst.
(4) Text Classification with BERT in PyTorch - Towards Data Science. https://towardsdatascience.com/text-classification-with-bert-in-pytorch-887965e5820f.
31、如果不使用 BERT 中的 [CLS] 的向量来进行分类,那么该使用什么来进行分类呢?
如果不使用 BERT 中的 [CLS] 的向量来进行分类,那么有一些其他的方法可以尝试,例如:
- 使用所有词的向量的平均或者池化作为句子向量或者分类向量。¹ 这种方法可以利用所有词的信息,但是可能会损失一些上下文信息和语义信息。²
- 使用最后一个词的向量或者第一个词的向量(除了 [CLS])作为句子向量或者分类向量。³ 这种方法可以简化模型的实现和计算,但是可能会忽略一些重要的词的信息。³
- 使用注意力机制(Attention Mechanism)或者自注意力机制(Self-Attention Mechanism)来加权所有词的向量,从而得到一个句子向量或者分类向量。 这种方法可以根据任务和数据集的特点,动态地调整每个词的重要性,从而提高模型的性能和灵活性。
Source: Conversation with Bing, 2023/5/7
(1) Why Bert transformer uses [CLS] token for classification … https://stackoverflow.com/questions/62705268/why-bert-transformer-uses-cls-token-for-classification-instead-of-average-over.
(2) nlp - What is purpose of the [CLS] token and why is its … https://datascience.stackexchange.com/questions/66207/what-is-purpose-of-the-cls-token-and-why-is-its-encoding-output-important.
(3) Removing SEP token in Bert for text classification. https://stackoverflow.com/questions/59719323/removing-sep-token-in-bert-for-text-classification.
32、BERT 的可学习参数量如何计算?公式是什么?以及超参数不同的 BERT 模型的可学习参数量分别是多少?
BERT 的可学习参数量是指模型中所有可训练的权重矩阵的元素个数之和。根据¹²,BERT 的可学习参数量计算公式是:
参数量 = ( 词表大小 + 最大长度 + 句子类型数 ) × 隐藏层维度 + Transformer层数 × ( Self-attention层参数量 + Feed-Forward Network层参数量 ) \text{参数量} = (\text{词表大小} + \text{最大长度} + \text{句子类型数}) \times \text{隐藏层维度} + \text{Transformer层数} \times (\text{Self-attention层参数量} + \text{Feed-Forward Network层参数量}) 参数量=(词表大小+最大长度+句子类型数)×隐藏层维度+Transformer层数×(Self-attention层参数量+Feed-Forward Network层参数量)
其中,Self-attention层参数量是:
隐藏层维度 2 头数 × 3 × 头数 + 隐藏层维度 2 \frac{\text{隐藏层维度}^2}{\text{头数}} \times 3 \times \text{头数} + \text{隐藏层维度}^2 头数隐藏层维度2×3×头数+隐藏层维度2
Feed-Forward Network层参数量是:
隐藏层维度 × 中间层维度 + 中间层维度 × 隐藏层维度 \text{隐藏层维度} \times \text{中间层维度} + \text{中间层维度} \times \text{隐藏层维度} 隐藏层维度×中间层维度+中间层维度×隐藏层维度
根据³,BERT 的超参数有以下几种:
| 模型 | 词表大小 | 隐藏层维度 | 头数 | 中间层维度 | Transformer层数 | 最大长度 | 参数量 |
|---|---|---|---|---|---|---|---|
| BERT-base | 30522 | 768 | 12 | 3072 | 12 | 512 | 110M |
| BERT-large | 30522 | 1024 | 16 | 4096 | 24 | 512 | 336M |
| BERT-xlarge | 30522 | 2048 | 32 | 8192 | 24 | 512 | 1.34B |
| BERT-xxlarge | 30522 | 4096 | 64 | 16384 | 24 | 512 | 5.36B |
Source: Conversation with Bing, 2023/5/8
(1) BERT参数量如何计算 - 知乎. https://zhuanlan.zhihu.com/p/357353536.
(2) Bert系列之模型参数计算 - 知乎. https://zhuanlan.zhihu.com/p/452369195.
(3) BERT详解:BERT一下,你就知道 - 知乎. https://zhuanlan.zhihu.com/p/225180249.
微调
33、BERT 模型如何进行微调?微调时需要注意哪些问题?
BERT模型是一种基于Transformer的预训练语言模型,它可以用于多种自然语言处理任务,如文本分类、命名实体识别、问答等。¹²
微调(Fine-tuning)是一种利用预训练模型的方法,它可以在一个特定的任务上对模型进行调整,以提高模型的性能和泛化能力。¹²³
微调时需要注意以下几个问题:
- 选择合适的预训练模型,根据任务的语言、领域和规模,选择最匹配的模型。²
- 选择合适的微调目标,根据任务的类型,选择不同的输出层和损失函数。²³
- 选择合适的微调参数,根据数据集的大小和复杂度,选择合适的学习率、批次大小、优化器和正则化方法。²³
- 选择合适的微调策略,根据任务的难度和数据集的质量,选择是否冻结部分层或使用不同的学习率。²³
Source: Conversation with Bing, 2023/5/8
(1) 【译】BERT Fine-Tuning 指南(with PyTorch) - 知乎. https://zhuanlan.zhihu.com/p/143209797.
(2) BERT原理解读及HuggingFace Transformers微调入门 - 知乎. https://zhuanlan.zhihu.com/p/448148614.
(3) 如何微调BERT模型进行文本分类 - 知乎. https://zhuanlan.zhihu.com/p/452358629.
以下是一些微调BERT模型的教程:
- 【译】BERT Fine-Tuning 指南(with PyTorch)¹:这是一个使用 Hugging Face 的 transformers 库和 PyTorch 框架来微调BERT模型进行文本分类的教程,它使用了 The Corpus of Linguistic Acceptability(CoLA) 数据集,并提供了详细的代码和注释。
- BERT原理解读及HuggingFace Transformers微调入门²:这是一个介绍BERT模型原理和使用 Hugging Face 的 transformers 库进行微调的教程,它涵盖了不同的任务类型,如单文本分类、语句对分类和序列标注,并给出了相应的代码示例。
- 如何微调BERT模型进行文本分类³:这是一个使用 Keras 和 TensorFlow 框架来微调BERT模型进行文本分类的教程,它使用了 IMDB 电影评论数据集,并展示了如何使用 BERT Base 和 BERT Large 两种变体。
Source: Conversation with Bing, 2023/5/8
(1) 【译】BERT Fine-Tuning 指南(with PyTorch) - 知乎. https://zhuanlan.zhihu.com/p/143209797.
(2) BERT原理解读及HuggingFace Transformers微调入门 - 知乎. https://zhuanlan.zhihu.com/p/448148614.
(3) 如何微调BERT模型进行文本分类 - 知乎. https://zhuanlan.zhihu.com/p/452358629.
BERT 有关的代码
34、BERT 的复现代码
https://zh-v2.d2l.ai/chapter_natural-language-processing-pretraining/bert.html
35、文本分类的 label 词向量化的研究
关于文本分类的 label 词向量化的研究,并总结如下:
- 文本分类的 label 词向量化是指将每个类别标签嵌入到与词向量相同的空间中,从而可以度量文本序列和标签之间的相似度⁴⁶。
- 一种常用的方法是使用注意力机制来计算文本序列和标签之间的兼容性,注意力机制可以根据训练集中的标签信息,给与文本序列中相关的词更高的权重⁴。
- 另一种方法是使用提示模板来引导文本序列中的词语与标签之间的联系,提示模板是一种包含 [MASK] 的句子,可以用来预测标签或者补全缺失的词语³。
- 使用 label 词向量化的方法可以提高文本分类的准确率和速度,同时保持词向量的可解释性⁴。
- 使用 label 词向量化的方法还可以利用其他来源的信息,例如预训练的词向量或者类别层次结构⁴⁵。
可以参考一些开源的项目,例如 https://github.com/hellonlp/classifier_multi_label 或者 https://github.com/taishan1994/prompt_text_classification ,它们都是使用 pytorch 实现的多标签文本分类模型,可能对你有帮助。
Source: Conversation with Bing, 2023/5/8
(1) Joint Embedding of Words and Labels for Text Classification. https://arxiv.org/abs/1805.04174.
(2) Joint Embedding of Words and Labels for Text Classification. https://aclanthology.org/P18-1216/.
(3) taishan1994/prompt_text_classification - Github. https://github.com/taishan1994/prompt_text_classification.
(4) Word-class embeddings for multiclass text classification. https://link.springer.com/article/10.1007/s10618-020-00735-3.
(5) 自然语言处理——使用词向量(腾讯词向量) - 知乎. https://zhuanlan.zhihu.com/p/111754138.
(6) hellonlp/classifier_multi_label - Github. https://github.com/hellonlp/classifier_multi_label.
36、使用pytorch来实现teacher forcing的例子
一种使用pytorch来实现teacher forcing的例子是在序列到序列的网络中,让解码器的输入是真实的词或者上一步生成的词,根据一个随机的概率来选择¹²。例如,如果我们要训练一个法语到英语的翻译模型,我们可以这样写:
# 定义一个teacher forcing的概率
teacher_forcing_ratio = 0.5
# 定义一个损失函数
criterion = nn.NLLLoss()
# 定义一个训练函数
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, max_length=MAX_LENGTH):
# 初始化编码器和解码器的隐藏状态
encoder_hidden = encoder.initHidden()
# 清空编码器和解码器的梯度
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# 获取输入和目标句子的长度
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
# 初始化损失值为0
loss = 0
# 将输入句子编码为一个向量
encoder_outputs, encoder_hidden = encoder(input_tensor, encoder_hidden)
# 将解码器的第一个输入设置为<SOS>符号
decoder_input = torch.tensor([[SOS_token]], device=device)
# 将解码器的第一个隐藏状态设置为编码器的最后一个隐藏状态
decoder_hidden = encoder_hidden
# 随机选择是否使用teacher forcing
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
# 如果使用teacher forcing
if use_teacher_forcing:
# 对于每个目标词
for di in range(target_length):
# 让解码器生成下一个词
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
# 计算损失函数
loss += criterion(decoder_output, target_tensor[di])
# 将解码器的下一个输入设置为真实的目标词
decoder_input = target_tensor[di]
# 如果不使用teacher forcing
else:
# 对于每个目标词
for di in range(target_length):
# 让解码器生成下一个词
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
# 计算损失函数
loss += criterion(decoder_output, target_tensor[di])
# 获取解码器输出的最大概率的词作为下一个输入
topv, topi = decoder_output.topk(1)
decoder_input = topi.squeeze().detach()
# 如果解码器生成了<EOS>符号,就停止生成
if decoder_input.item() == EOS_token:
break
# 反向传播损失函数并更新参数
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
# 返回平均损失值
return loss.item() / target_length
Source: Conversation with Bing, 2023/5/7
(1) Teacher forcing with pytorch RNN - Stack Overflow. https://stackoverflow.com/questions/47077831/teacher-forcing-with-pytorch-rnn.
(2) NLP From Scratch: Translation with a Sequence to Sequence … https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html.
(3) lkulowski/LSTM_encoder_decoder - Github. https://github.com/lkulowski/LSTM_encoder_decoder.
37、什么是NLLLoss?
NLLLoss是一种负对数似然损失函数,用于训练一个分类问题¹。它的输入是每个类别的对数概率,目标是每个样本的类别索引¹。它的表达式是:
L N L L = − ∑ i = 1 N y i log y ^ i L_{NLL} = -\sum_{i=1}^N y_i \log \hat{y}_i LNLL=−i=1∑Nyilogy^i
其中, N N N是词汇表的大小, y i y_i yi是第 i i i个词的真实标签(0或1), y ^ i \hat{y}_i y^i是第 i i i个词的预测概率。
NLLLoss与CrossEntropyLoss的区别是,CrossEntropyLoss相当于softmax + log + NLLLoss,即在计算NLLLoss之前,先对输入进行softmax归一化和对数变换²。因此,如果模型的输出已经是对数概率,就可以直接使用NLLLoss;如果模型的输出还需要归一化,就可以使用CrossEntropyLoss³。
一个使用pytorch实现NLLLoss的例子是:
# 定义一个损失函数
criterion = nn.NLLLoss()
# 定义一个模型
model = nn.Sequential(
nn.Linear(10, 5), # 输入维度为10,输出维度为5
nn.LogSoftmax(dim=1) # 对输出进行对数概率变换
)
# 定义一个输入向量
input = torch.randn(1, 10) # 随机生成一个1x10的向量
# 定义一个目标类别
target = torch.tensor([1]) # 目标类别为1
# 计算模型的输出
output = model(input)
# 计算损失函数
loss = criterion(output, target)
# 打印损失值
print(loss)
Source: Conversation with Bing, 2023/5/7
(1) NLLLoss — PyTorch 2.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html.
(2) torch.nn — PyTorch 2.0 documentation. https://pytorch.org/docs/stable/nn.html.
(3) 详解torch.nn.NLLLOSS - 知乎. https://zhuanlan.zhihu.com/p/383044774.