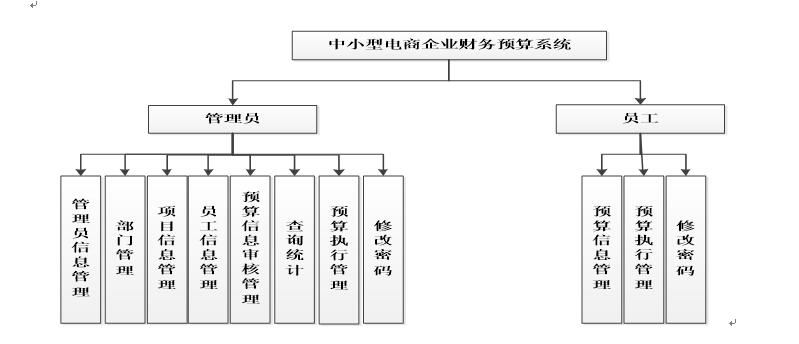
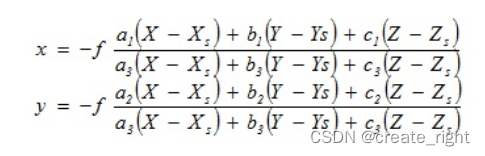简介
Mysq 执行一条SQL记录时,会首先将数据写入 redo log,然后更新到内存上,等到满足特定条件之后,才将数据写入到数据库磁盘文件。
redo log也保存在磁盘上,和数据库磁盘文件的区别,在于写入的方式。redo log的写入方式是顺序的,而数据库磁盘文件则是随机的。对于磁盘来说,顺序写入比随机写入更快。
这种分两次更新的方式,类似于redis 数据落库的方式,只不过操作的存储结构不同,造成了不同的结果。Redis中 写入数据时,会先写入aof_buf,然后根据 appendfsync 的值不同,选择是每次写入物理磁盘文件,还是按照间隔时间,分批写入。
相关术语
redo log,mysql 日志的一种存储在磁盘上,被用来恢复crash造成的事务丢失。
脏页,mysql 引擎上的缓存,用来缓存更新数据,加速读取,避免每次都从磁盘文件上读取。
磁盘文件,mysql 实际存储数据的物理结构。
三种存储机制的写入
Mysql 的 redo log机制保障了一旦数据写入了 redo log,那么后续就不会因为各种问题造成数据丢失。即使极端情况下,数据库宕机,也能通过读取redo log的方式,将数据恢复过来,并将对应数据写入到磁盘中。
这种redo log先于数据写入到磁盘的技术,被叫做 WAL(write ahead log,提前写日志)。
当然由于数据库除了要写入实际保存数据之外,还需要写入这样的一份 redo log,磁盘写的压力会增大。所有Mysql 也有其他的技术来降低写压力,比如说 随机写改成顺序写、单次写内存后批量更新到磁盘。

Redo log 的写入
当Mysql 需要执行一条 Update 语句时,InnoDB 引擎会先将记录写入到 redo log 中,并更新内存,这个时候更新就完成了。至于磁盘的写入,InnoDB 引擎会在适当的时候将操作记录更新到磁盘中,这个更新往往是系统比较空闲的时候,或者不得不更新的时候。
每个InnoDB 存储引擎至少有一个 redo log 文件组,多个 redo log文件。如果将文件组配置成 一组 4 个,每个redo log 文件大小是 1GB,那么 redo log的大小就可以记录 4GB的操作。InnoDB 引擎会将这组日志文件,从头开始写入,每次写到末尾时,又重新回到开头进行循环写。

如上图所述,环中有两个标识节点:
write pos 和 check point,write pos时当前记录的位置,check point 是当前数据更新的位置,这个数据更新指将记录更新到数据文件中。
write pos 和 check point 中间的间隔就是还可以写入的空间,而当 write pos 追上 check point 时,就表示 redo log 已经存满了,不能保存新的记录了,得停下来先将记录保存到数据文件中。
脏页到磁盘的写入
脏页是一种内存数据页,脏页的’脏’ 在于脏页上的数据和磁盘数据页上的内容不一样。
从脏页到磁盘的写入有四种:
当redo log写满了,会将 check point 向后推进一些。此时,会将check point 对应脏页 都flush 到磁盘上。
当系统内存不足时,需要淘汰一些内存数据页。如果被选中的是脏页,那也需要flush 到磁盘上。
当系统空闲时,Mysql 会主动将一些脏页 flush 到磁盘上。
Mysql 正常关闭时,会将内存上的脏页都flush 到磁盘上。
当脏页还没有被刷入磁盘,数据库就崩溃时,这时就需要做崩溃恢复。它的具体流程是从check point开始向后扫描日志,然后让redo log 更新内存内容。更新完成之后,内存变成脏页,最终再在合适的时候将脏页数据写盘。
总结
Mysql 数据更新时会从 redo log 到 脏页,最后由脏页更新到数据文件。所以之前用redo log 做数据恢复是一种比较宽泛的说法。
同时对Mysql 数据更新过程 和 Redis、RocketMQ 做数据持久化过程的比较也可以看出,对于这种逻辑数据转物理数据的方案也是殊途同归,利用计算机特性对数据写入做优化。
参考
02 | 日志系统:一条SQL更新语句是如何执行的?
阿里巴巴大淘宝技术:如何设计一套完整的订单系统,或者完整的业务流程?
阿里云数据库开源:MySQL WAL那些事儿