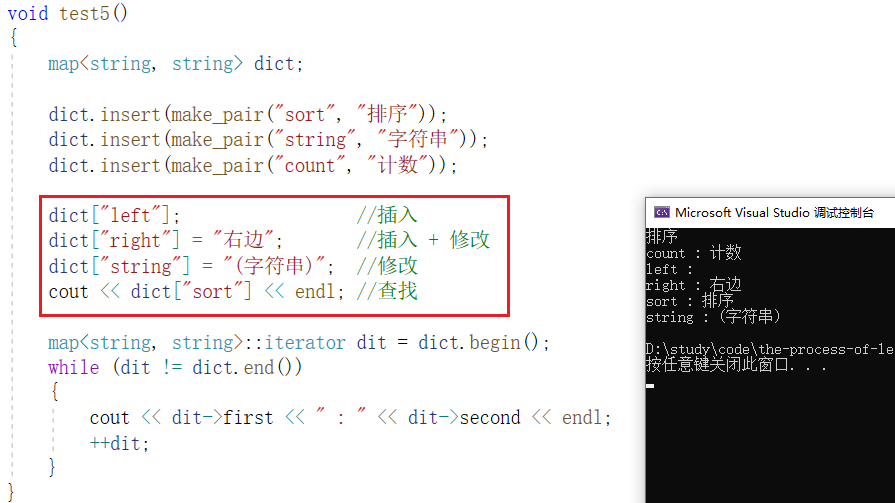
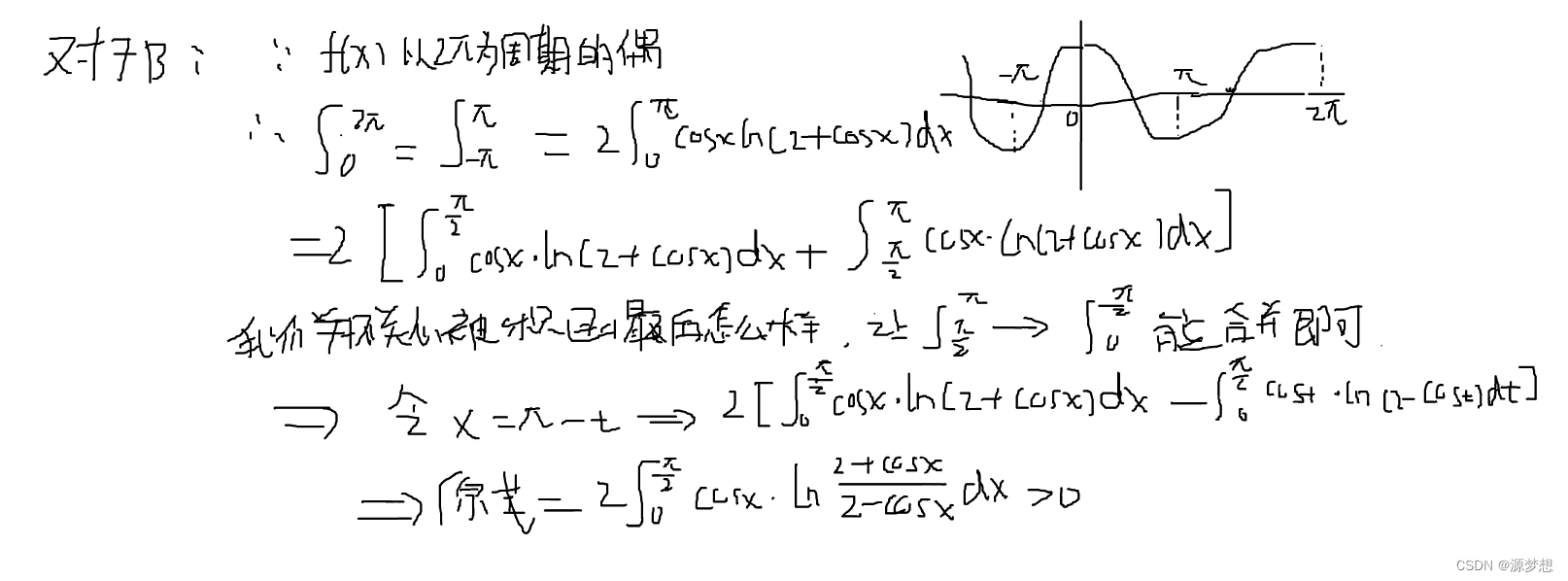主题建模和文本聚类:理论与实践
随着互联网和数字化时代的到来,海量的文本数据变得越来越容易获取。然而,如何从这些文本数据中获取有用的信息是一个非常具有挑战性的问题。主题建模和文本聚类是两个常见的文本挖掘技术,它们可以用于发现文本数据中的主题和模式。本文将介绍主题建模和文本聚类的原理,以及如何使用Python实现。
1. 主题建模
1.1 什么是主题建模
主题建模是一种通过分析文档中出现的单词来发现文档中的主题的技术。主题是指在文档集合中共同出现的词汇和短语的集合。主题建模可以用于文本分类、信息检索、推荐系统和社交媒体分析等领域。
1.2 主题建模的原理
主题建模的原理基于概率图模型。其中一种常见的概率图模型是潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)。LDA 假设每个文档都包含多个主题,每个主题都是由一些单词组成的概率分布。每个单词又有一个概率分布,表示它可能属于哪个主题。主题建模的目标是推断出这些概率分布。
1.3 Python实现
Python 中有一个非常流行的主题建模工具包叫做 gensim。下面是一个简单的代码示例,展示了如何使用 gensim 进行主题建模。
import gensim
from gensim import corpora
# 加载语料库
corpus = corpora.TextCorpus('data.txt')
dictionary = corpus.dictionary
# 训练 LDA 模型
lda_model = gensim.models.ldamodel.LdaModel(
corpus=corpus,
id2word=dictionary,
num_topics=10,
passes=10
)
# 输出主题和它们的前 10 个关键词
for topic in lda_model.show_topics(num_topics=10, num_words=10, formatted=False):
print('Topic {}: {}'.format(topic[0], [w[0] for w in topic[1]]))
上面的代码加载了一个文本文件,然后使用 gensim 中的 LdaModel 类训练了一个 LDA 模型。模型中有10个主题,每个主题包含10个关键词。运行上面的代码后,会输出每个主题及其对应的关键词。
2. 文本聚类
2.1 什么是文本聚类
文本聚类是一种将文档分为若干类别的技术。聚类的目的是使同一类别内的文档尽可能相似,而不同类别的文档尽可能不同。文本聚类可以用于文本分类、信息检索、推荐系统和社交媒体分析等领域。
2.2 文本聚类的原理
文本聚类的原理基于向量空间模型。在向量空间模型中,文档可以表示为向量,其中每个维度表示一个单词的出现次数或权重。可以使用词袋模型或 TF-IDF(Term Frequency-Inverse Document Frequency)等方法将文档转换为向量。然后,可以使用聚类算法(如K均值算法或层次聚类算法)将这些向量分为不同的类别。
2.3 Python实现
Python 中有一个非常流行的文本聚类工具包叫做 scikit-learn。下面是一个简单的代码示例,展示了如何使用 scikit-learn 进行文本聚类。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
# 加载语料库
corpus = [
'This is the first document.',
'This is the second document.',
'And this is the third one.',
'Is this the first document?',
]
# 将文档转换为向量
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(corpus)
# 使用 K 均值算法进行聚类
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
# 输出每个文档所属的类别
for i, label in enumerate(kmeans.labels_):
print('Document {} is in cluster {}'.format(i, label))
上面的代码加载了一个文本语料库,然后使用 scikit-learn 中的 TfidfVectorizer 类将文档转换为 TF-IDF 向量。接下来,使用 K 均值算法将这些向量分为两个类别。运行上面的代码后,会输出每个文档所属的类别。
3. 结论
主题建模和文本聚类是两个非常有用的文本挖掘技术。它们可以用于发现文本数据中的主题和模式,从而提高文本分析的效率。本文介绍了主题建模和文本聚类的原理,并展示了如何使用Python实现。希望本文对您有所帮助!