文章目录
- 一.stack
- 二.queue
- 三.deque(双端队列)
- 四.优先级队列
- 优先级队列中的仿函数
- 手搓优先级队列
- 五.反向迭代器
- 手搓反向迭代器
vector和list我们称为容器,而stack和queue却被称为容器适配器。

这和它们第二个模板参数有关系,可以看到stack和queue的第二个模板参数的缺省值都是
deque,即双端队列容器。也就是说栈和队列都是以容器为主材料构建的,而且因为第二个参数是一个缺省值,我们不但可以使用deque构建,同样可以使用vector和list来构建。
用已经存在的容器来封装转换成不存在的容器,这种方式就被称之为适配器模式。
有了deque提供的接口,再要实现栈和队列就会变得很简单。
一.stack
栈的特点就是后进先出,,插入和删除都是在尾部进行,栈不提供迭代器(因为栈只能访问栈顶的元素)。
#include<deque>
namespace wbm
{
template <class T, class Container = deque<T>>
class stack
{
public:
bool empty()const
{
return _con.empty();
}
void push(const T&x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
size_t size()const
{
return _con.size();
}
const T& top()const
{
return _con.back();
}
private:
Container _con;
};
}
栈不但可以通过
deque来封装,还可以通过vector和list来封装,只要支持尾插尾删即可
二.queue
队列的特点是先进先出,队尾入,队头出,可以访问队头和队尾的数据,也不提供迭代器
#include<deque>
namespace wbm
{
template<class T,class Container=deque<T>>
class queue
{
public:
bool empty()const
{
return _con.empty();
}
void push(const T& x)
{
_con.push_back();
}
void pop()
{
_con.pop_front();
}
size_t size()const
{
return _con.size();
}
const T& fornt()const
{
return _con.front();
}
const T& back()const
{
return _con.back();
}
private:
Container _con;
};
}
只要是支持尾插头删的容器都可以做
queue的适配器,但是不建议使用数组,因为数组的头删效率太低
三.deque(双端队列)
因为vector和list都各有优缺点,因此大佬们就想是否可以创造一个容器兼具vector和list的优点又避免缺点,于是便有了双端队列deque,虽然deque的名字带着队列,但是它和队列毫无关系。

观察它提供的接口发现:它既支持随机访问,又支持头插头删和尾插尾删,看起来似乎确实是一个完美的容器。但如果真的那么完美,vector和list岂不是早就被淘汰了。
其实deque的底层是一个指针数组+多个buffer数组(buffer数组的大小是固定的)的组成形式;这个指针数组是一个中控数组,其中存放的元素是属于这个deque的buffer数组的地址。
第一次插入数据开辟的buffer数组的地址存放在中控数组的中间元素,如果buffer数组满了要继续尾插,则继续开辟新的buffer数组,此时第二个buffer数组的地址,存放在中控数组中间元素的下一个。如果你要头插,则开辟一个新的buffer数组,并将这个buffer数组的地址存放在中间元素的前一个。
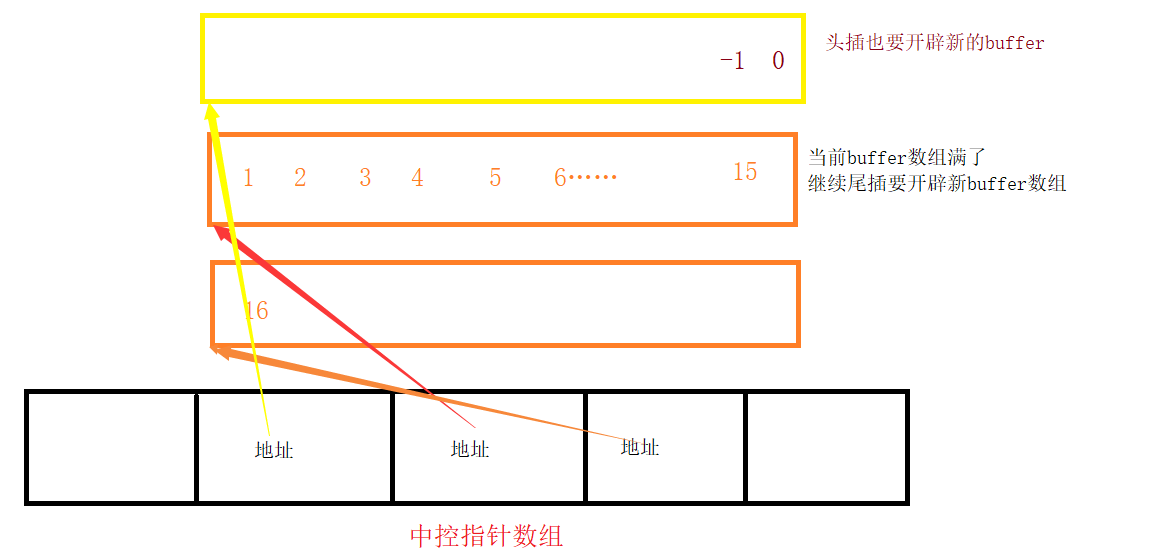
deque的优点:
1.扩容代价小于vector:它只有在中控满了以后才需要扩容,并且不需要拷贝原生数据,只要将中控数组与buffer之间的映射关系拷贝下来即可。
2.因为是一段一段的空间,所以CPU高速缓存命中率高于list。
3.头尾插入删除效率都较高,并且支持随机访问
但是deque也有自己的缺点:
1.随机访问效率不如vector,它的随机访问要通过计算得到,假设每个buffer数组的大小为size,你要访问第10个元素,首先要10/size来确定这个元素在哪一个buffer数组中,再用10%size来确定这个元素在这个buffer数组中的哪个位置,所以deque也不适合排序,因为排序需要大量的随机访问。
2.中间插入删除不如list,它在中间插入删删同样需要挪动一定量的数据
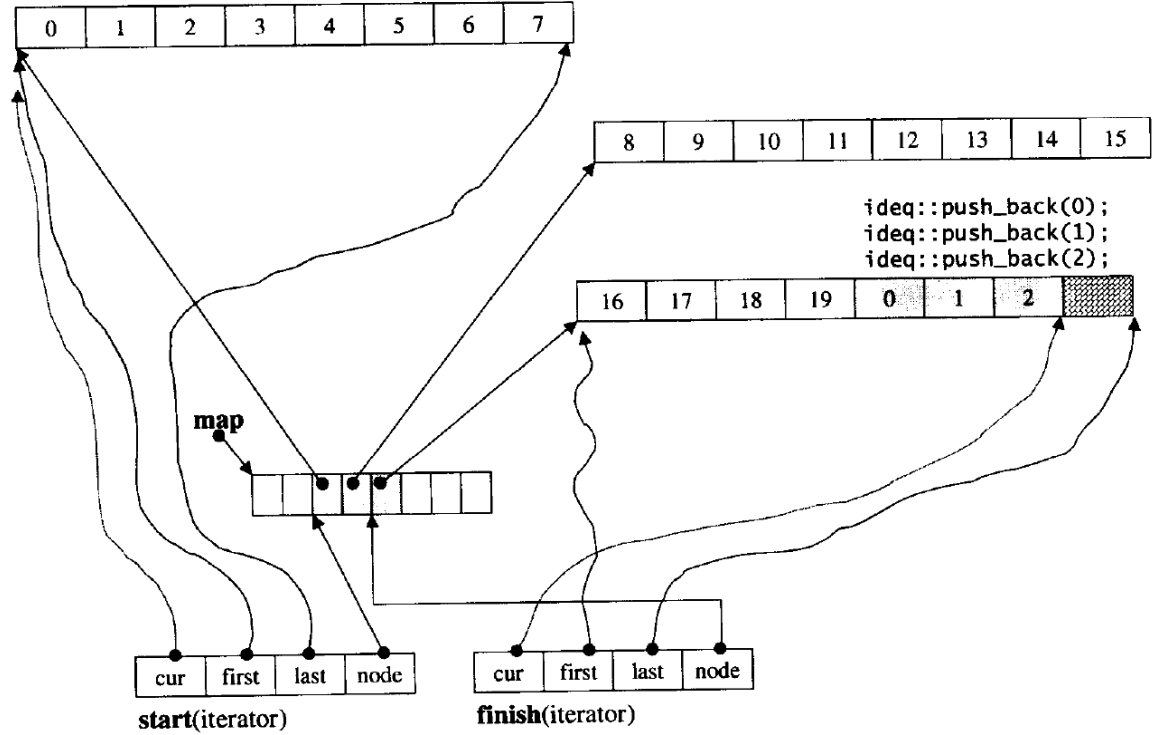
3.迭代器实现复杂:它的迭代器中有四个指针,当
cur==last时,说明本段空间被使用完毕++node继续去访问下一段空间,并更新first和last
四.优先级队列

优先级队列的特点就是优先级高的先出,它也是一个容器适配器,不提供迭代器,底层是一个堆并且默认是大堆。
priority_queue<int> //小堆
priority_queue<int,vector<int>,greater<int>> //大堆
优先级队列中的仿函数
仿函数是一个函数对象,它是一个类函数的对象,要达到类函数,所以这个类中必须要重载()。优先级队列中默认是大堆,如果我们要改成小堆,除了要显示传递第三个参数以外还要更改比较大小的算法。在C语言中,为了能让qsort排序任意类型,库中使用了函数指针的办法,让使用者显示的去写一个比较函数,并将该函数的地址作为参数传递过去。仿函数的一个应用场景就类似于函数指针。
namespace wbm
{
template<class T>
struct less //可以使用struct,也可以使用class,它们都是类,只是默认的访问限定不同
{
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template <class T>
struct greater
{
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
}
int main()
{
wbm::less<int> func;
//两者等价:func(1, 2)==func.operator()(1, 2);
return 0;
}
手搓优先级队列
#include<vector>
#include<iostream>
namespace wbm
{
template<class T>
struct less //可以使用struct,也可以使用class,它们都是类,只是默认的访问限定不同
{
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
template <class T>
struct greater
{
bool operator()(const T& x, const T& y)
{
return x > y;
}
};
template<class T, class Container =std:: vector<T>,class Compare = less<T>>
class priority_queue
{
private:
void Adjustdown(size_t parent)
{
Compare com;//构造一个仿函数对象
size_t child = parent * 2 + 1;//先默认是左孩子大,如果右孩子更大,把孩子节点更新成右孩子
while (child < _con.size())
{
if (child+1 < _con.size() && com(_con[child], _con[child + 1]))
{
++child;//默认是less,也就是左孩子比右孩子小
}
//将孩子节点和父节点做比较
if (com(_con[parent], _con[child]))
{
std::swap(_con[parent], _con[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void Adjustup(size_t child)
{
Compare com;
size_t parent = (child - 1) / 2;
while (child > 0)
{
if (com(_con[parent], _con[child]))
{
std::swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
public:
priority_queue()
{
//要有一个默认构造,不写就会报错
}
//迭代器区间构造,直接构造出一个堆,使用向下调整更佳
template<class InputIterator>
priority_queue(InputIterator first, InputIterator last)
:_con(first, last) //初始化列表,vector支持迭代器区间构造
{
//初始化建堆,使用向下调整,从第一个非叶子节点开始
for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--)
{
Adjustdown(i);
}
}
void push(const T& x)
{
_con.push_back(x);
Adjustup(_con.size() - 1);
}
void pop()
{
//将首元素和末尾元素换位置删除后调整
std::swap(_con.front(), _con.back());
_con.pop_back();
Adjustdown(0);
}
bool empty()const
{
return _con.empty();
}
size_t size()const
{
return _con.size();
}
const T& top()const
{
return _con.front();
}
private:
Container _con;
};
}
如果优先级队列中存放的是某个类的地址,又需要我们比较地址中值的优先级,那就需要使用仿函数来进行特殊处理。否则只会按照地址来比较。
五.反向迭代器
反向迭代器采用的是适配器模式,是通过正向迭代器的再封装实现的,你给它某个容器的正向迭代器,它就产生这个容器的反向迭代器,它与正向迭代器的位置是对称的并且正好相反。所以要控制反向迭代器,只需要使用运算符重载,篡改方向迭代器中++和--的规则就可以。
reverse_iterator rbegin(){return reverse_iterator(end());}
reverse_iterator rend(){return reverse_iterator(begin());}

rbegin和end一样,指向的是最后一个元素的下一个位置,要想访问到3,要先--再访问,这个问题可以通过重载*来解决
template<class Iterator,class Ref,class Ptr>
Ref operator*()
{
Iterator tmp=it;
return *(--tmp);
}
手搓反向迭代器
namespace wbm
{
//反向迭代器,使用正向迭代器封装
template<class Iterator,class Ref,class Ptr> //迭代器,T&/const T&,T*/const T*
class ReverseIterator
{
typedef ReverseIterator<Iterator, Ref, Ptr> Self;
public:
ReverseIterator(Iterator it)
:_it(it)
{}
Ref operator*()
{
Iterator tmp;
return *(--tmp);
}
Ptr operator->()
{
return &(operator*())
}
Self& operator++()
{
--_it;
return *this;
}
Self& operator--()
{
++_it;
return *this;
}
bool operator!=(const Ref& rit)const//两个迭代器之间的比较
{
return _it != rit;
}
private:
Iterator _it;//这里给的参数是一个正向迭代器
};
}