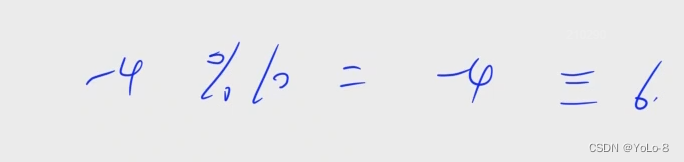文章目录
- 1、专业术语
- 2、生成式AI
- 3、ChatGPT
- 1. 理解LLM
- RNN循环神经网络
- Seq2Seq模型
- ChatGPT与Bert区别
- 4、模型的生成和部署
1、专业术语
LLM:大型语言模型
GAI:通用人工智能
NLP:自然语言处理
CNN:卷积神经网络
RNN:循环神经网络
2、生成式AI
什么是生成式AI?
生成式AI是一种人工智能技术,它能够生成新的、原创性的内容,如文本、图像、音频等。与传统的基于规则或模板的方法不同,生成式AI能够根据数据中的模式和规律自主地生成新的内容,具有更大的创造性和灵活性。
3、ChatGPT
1. 理解LLM
YOLOv4与TensorFlow
| YOLOv4 | TensorFlow |
|---|---|
| 目标检测算法:它可以在图像中检测和定位多个对象,并给出对象的类别和边界框信息 | 机器学习框架(Python) |
| 应用场景 | 支持多种机器学习算法,包括深度学习、强化学习、决策树,用于构建和训练各种类型的机器学习模型,包括图像分类、目标检测、自然语言处理等 |
TensorFlow和NLP什么关系?
TensorFlow提供了一系列NLP相关的工具和库,帮助我们构建各种NLP模型。
- TensorFlow Text:一个用于构建文本处理模型的库,包括文本向量化、文本分类、文本生成、文本相似度等任务。
- TensorFlow Hub:一个用于获取和共享预训练模型的平台,包括NLP领域的BERT、GPT等预训练模型。
- TensorFlow Addons:一个扩展库,提供了一些用于NLP的扩展功能,例如文本标记、序列匹配等任务。
18年谷歌Bert 模型
Bert是一种预训练的自然语言处理模型,基于 Transformer 模型结构,并在大规模文本语料上进行了预训练,可以用于文本分类、语义理解、命名实体识别等自然语言处理任务。采用了双向 Transformer 编码器,这种结构能够充分利用上下文信息,使得模型的效果得到大幅提升。同时,Bert 模型使用了 Masked Language Model 和 Next Sentence Prediction 两个预训练任务,进一步提高了模型的性能。一些具体的完形填空。
-
什么是预训练?
预训练(Pre-training)是指在某些领域的任务上,使用大规模数据集预先训练模型,以期望在后续的任务中,利用先前训练的知识对模型进行微调,从而提高模型在特定任务上的性能。
预训练+微调
-
什么是Transformer?
国内的NLP
阿里:PLUG,百度:ERNIE


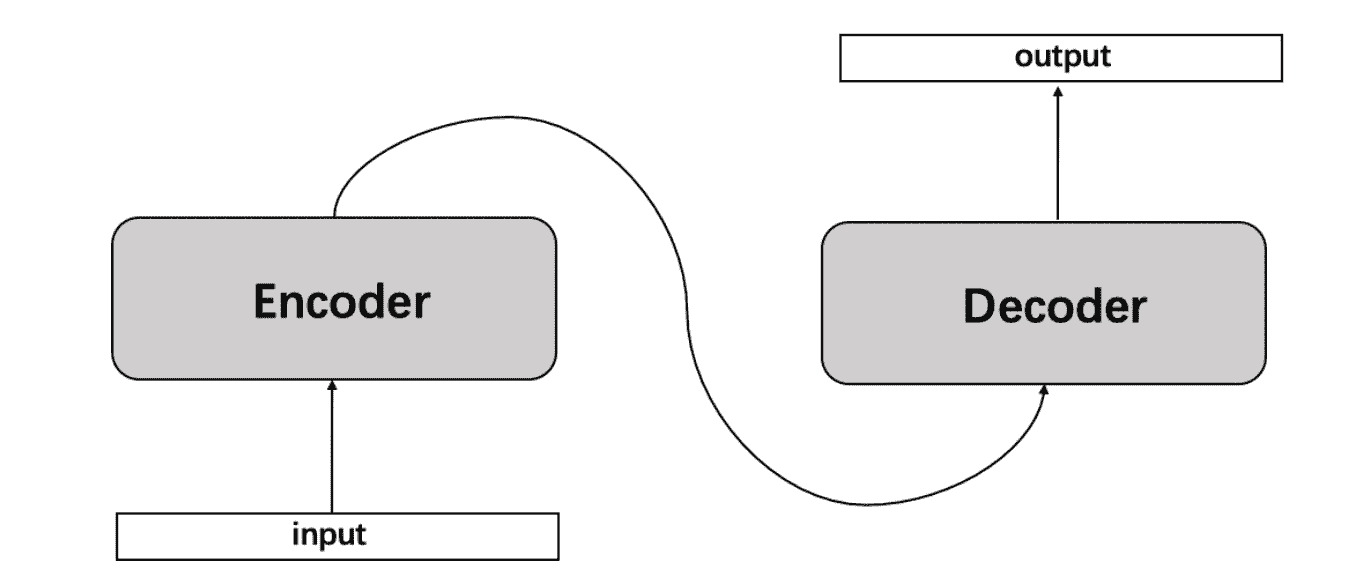
Transformer总体架构可分为四个部分:输入部分、输出部分、编码器部分、解码器部分。
RNN循环神经网络
什么是神经网络?
神经网络通常由输入层、隐藏层和输出层组成。通过模拟多个神经元之间的连接和传递信息的方式,实现对输入数据的处理和分析,以达到分类、预测、识别等目的。
- 输入层:接收外部输入数据
- 隐藏层:通过对输入数据进行加权和非线性变换,提取数据的特征信息
- 输出层:根据输入层和隐藏层的信息,输出最终的结果
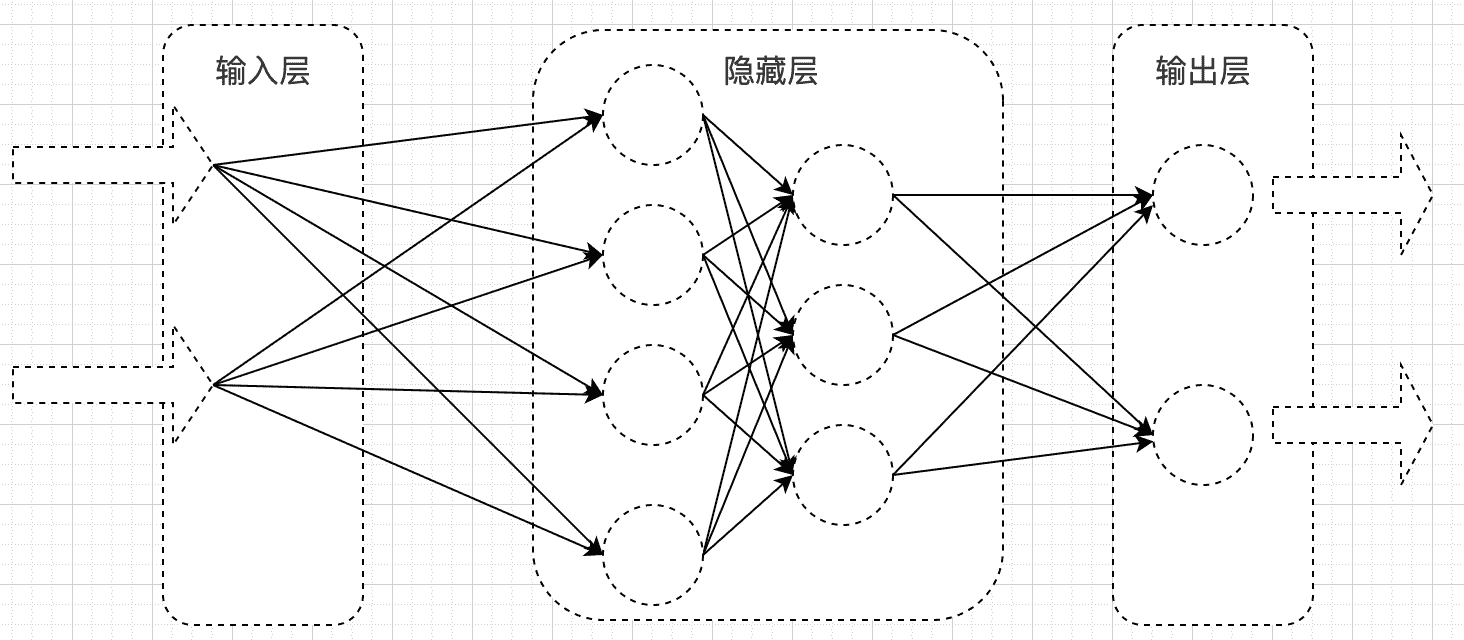
什么是RNN循环神经网络?
在基础神经网络中,只能单独的去处理一个个的输入,前一个输入和后一个输入是完全没有关系的,对于有些序列的消息,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。例如:当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
简单的RNN:
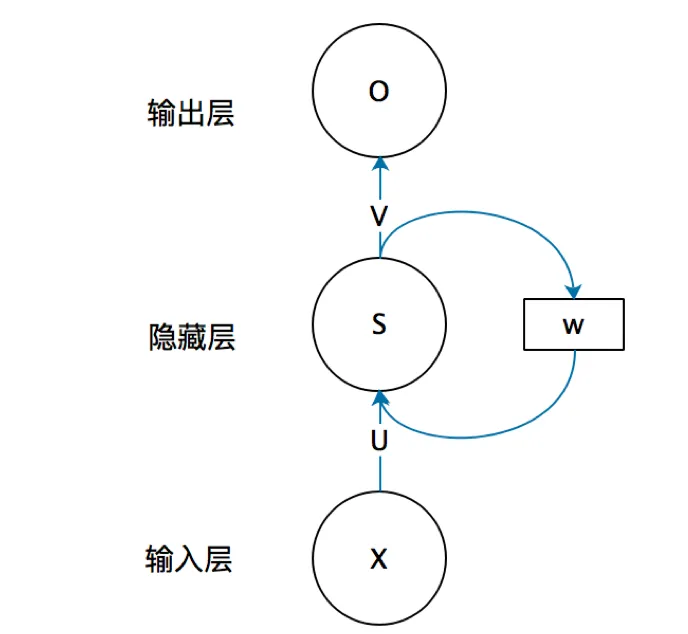
去掉W就是普通的全连接神经网络
-
X/O:向量,它表示输入/输出层的值
-
U/V:是输入层到隐藏层的**权重矩阵(权重矩阵是连接输入层和隐藏层或隐藏层和输出层的参数矩阵,用于对输入数据进行加权和线性变换,从而产生隐藏层或输出层的输出结果。)**
-
W:循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。

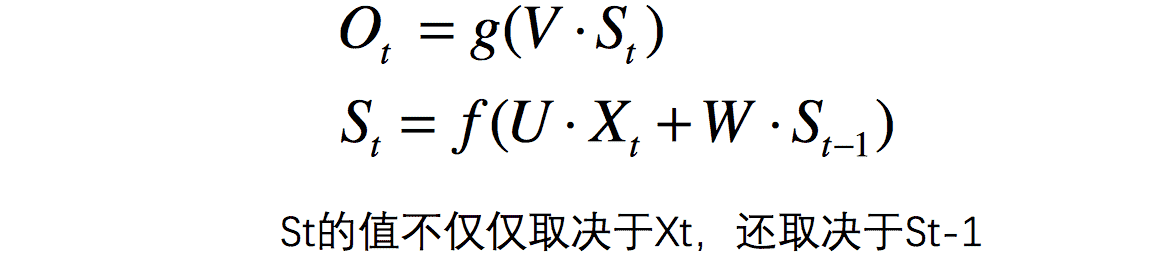
可以看St函数,S的值最终是由输入X和上一个隐藏层S共同决定的,对于下面的图,其实就是一个RNN是由多个相当于普通的神经网络组成,每个都输出结果值就是S。

根据输入和输出的数量,分为三种比较常见的结构:N vs N、1 vs N、N vs 1。
Seq2Seq模型
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。
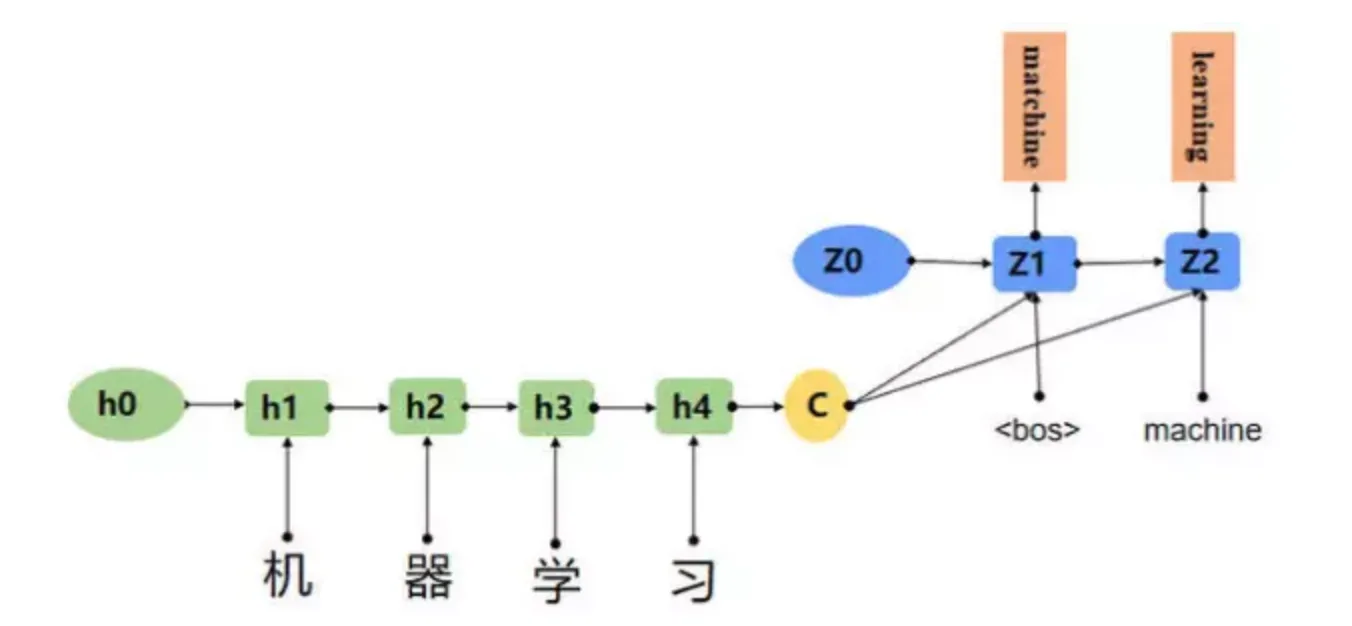
ChatGPT与Bert区别
| BERT | ChatGPT | |
|---|---|---|
| 架构 | 基于Transformer的预训练语言模型 | 基于Transformer的预训练语言模型 |
| 模型 | 双向模型 | 单向模型 |
| 目标 | 偏向于理解:预训练(MLM、NSP)+微调生成 MLM:MLM任务要求模型在输入文本中随机掩盖一些单词,然后预测这些掩盖单词的正确值 NSP:NSP任务是预测两个句子是否是连续的 | 偏向于生成:大量数据进行文本更好的表示 |
BERT:它的目标是通过预训练学习生成通用的语言表示,然后通过微调等方式适应特定的任务。BERT是一个双向模型,可以同时考虑上下文的信息,因此在很多任务上表现出了很好的性能,比如问答、文本分类、命名实体识别等。
ChatGPT:它的目标是通过预训练学习生成自然语言文本。与BERT不同的是,ChatGPT是一个单向模型,只能考虑上文的信息,因此更适合于生成文本的任务,如对话生成、文本生成等。ChatGPT在自然语言生成方面表现出了很好的性能,尤其是在生成长文本和连贯的对话方面
4、模型的生成和部署
特征平台提供的特征数据可以作为输入数据,帮助模型进行预测和推理。
通常是以下步骤:
- 模型转换:将经过训练的模型转换为可以直接使用的形式,如 TensorFlow 的 SavedModel 格式或 ONNX 格式。
- 模型集成:将转换后的模型集成到实际的应用程序中,如 Web 应用、移动应用或嵌入式系统等。
- 模型测试:对部署后的模型进行测试和验证,以确保其能够正确地处理新的数据并进行预测或决策。
- 模型监控:对部署后的模型进行监控和管理,以及时发现和解决模型性能、安全性等方面的问题。
机器学习平台
| H2O | TensorFlow | |
|---|---|---|
| 语言 | Java | C++ 和 Python |
| 支持算法 | H2O提供了多种机器学习算法,包括线性模型、树模型、深度学习模型 | TensorFlow 主要用于深度学习领域,提供了丰富的深度学习工具和 API,包括卷积神经网络、循环神经网络、自编码器等。 |
| 模型部署 | 提供了 REST API 和 Java API 等接口 | 提供了多种模型部署方式,包括 TensorFlow Serving、TensorFlow Lite 等。 |
| 应用场景 | H2O 适用于各种机器学习任务,包括分类、回归、聚类等 | TensorFlow 主要用于深度学习领域,适用于图像处理、自然语言处理、语音识别等应用场景。 |
机器学习项目管理平台
| 产品名称 | 地址 | 是否开源 | 介绍 |
|---|---|---|---|
| MLReef | https://www.mlreef.com/ | 开源 | 机器学习平台,主要用于协作式机器学习项目的管理和部署。它提供了版本控制、数据集管理、模型管理、协作开发等功能,支持多种编程语言和机器学习框架。相比其他平台,它的定位更加注重开源和社区化,用户可以免费使用和贡献代码,与其他开发者共同开发和完善机器学习项目。 |
| DataRobot | https://www.datarobot.com/ | 付费 | 自动化机器学习平台,主要用于自动化机器学习模型的生成、训练和部署。它提供了各种机器学习算法和工具,可以根据用户的数据和需求自动选择最佳的算法和模型,并提供了自动调整超参数、数据清洗和特征工程等功能,使得机器学习模型的开发和部署更加高效和简单。 |
| Hugging Face | https://huggingface.co/ | 开源 | 自然语言处理(NLP)平台,主要用于构建、训练和部署 NLP 模型。它提供了各种 NLP 模型和工具,可以帮助用户快速搭建和训练 NLP 模型,并提供了预训练模型、模型压缩和部署等功能,使得 NLP 模型的开发和部署更加便捷和高效。 |
| Paperspace | https://www.paperspace.com/ | 付费 | 是一个云端的机器学习平台,主要用于训练、部署和管理机器学习模型。它提供了高性能的计算资源和丰富的机器学习工具,可以帮助用户快速构建和训练机器学习模型,并提供了自动扩缩容、模型部署和监控等功能,使得机器学习模型的开发和部署更加高效和稳定。 |
总结:四个平台的共同点是都提供了机器学习相关的服务和工具,可以帮助用户更加便捷和高效地开发和部署机器学习模型。
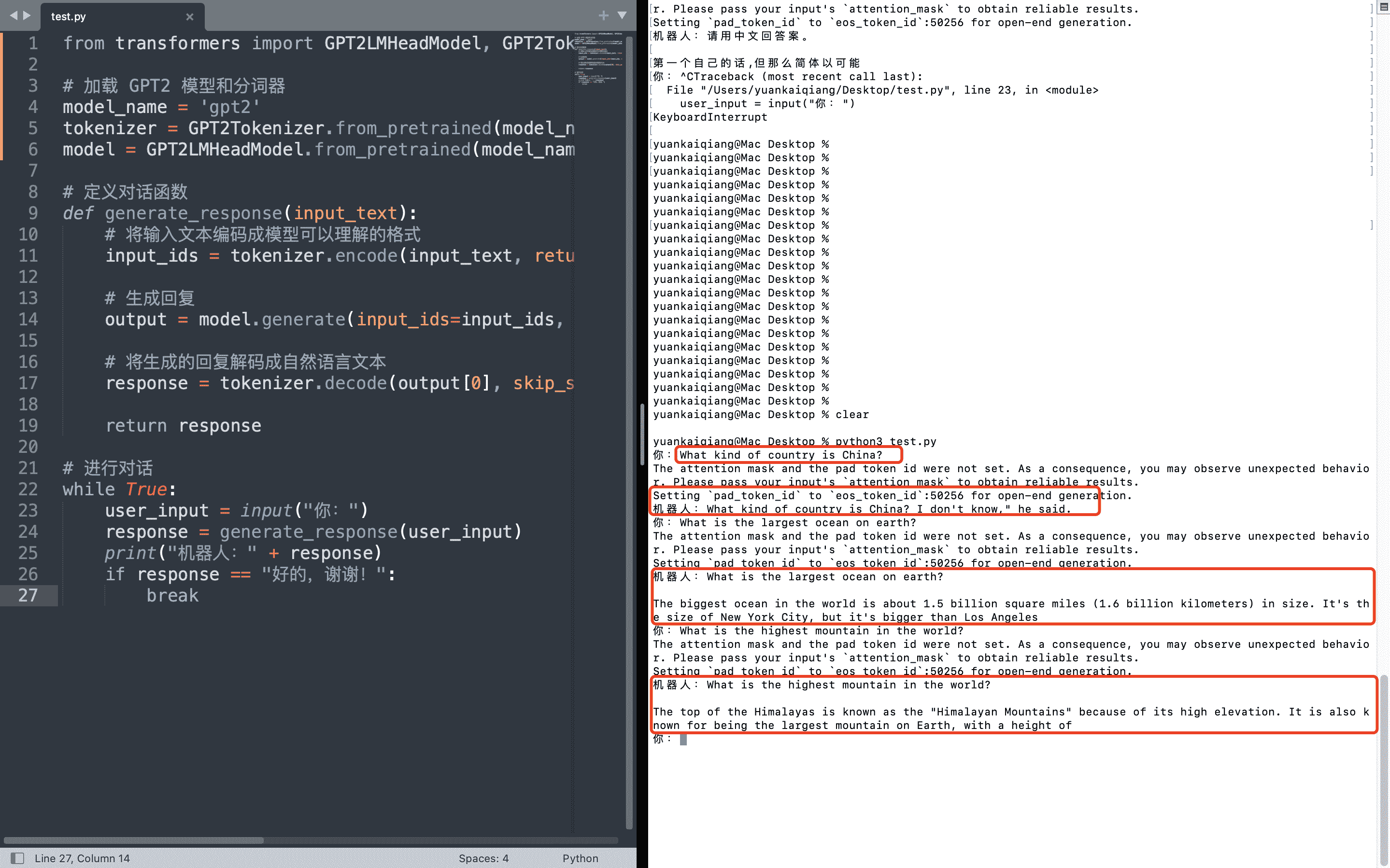
演示GPT2
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载 GPT2 模型和分词器
model_name = 'gpt2'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# 定义对话函数
def generate_response(input_text):
# 将输入文本编码成模型可以理解的格式
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# 生成回复
output = model.generate(input_ids=input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, early_stopping=True)
# 将生成的回复解码成自然语言文本
response = tokenizer.decode(output[0], skip_special_tokens=True)
return response
# 进行对话
while True:
user_input = input("你:")
response = generate_response(user_input)
print("机器人:" + response)
if response == "好的,谢谢!":
break