ElasticSearch
1、ElasticSearch学习随笔之基础介绍
2、ElasticSearch学习随笔之简单操作
3、ElasticSearch学习随笔之java api 操作
4、ElasticSearch学习随笔之SpringBoot Starter 操作
5、ElasticSearch学习随笔之嵌套操作
6、ElasticSearch学习随笔之分词算法
7、ElasticSearch学习随笔之高级检索
ElasticSearch,创始人 Shay Banon(谢巴农)
本文主要讲解ElasticSearch 高级搜索实战,来满足复杂的业务场景,还是用 Kibana 来操作。
文章目录
- ElasticSearch
- 前言
- 一、Boosting(控制相关度)
- 二、Bool 布尔查询
- 2.1 复合查询
- 2.2 包含不相等查询
- 2.3 实现 should_not 查询
- 2.4 控制查询相关性算分
- 三、多字段查询
- 3.1 最佳字段匹配(Best Fields)
- 3.1.1 Dis Max Query
- 3.1.2 Multi Match Query
- 3.2 多数字段匹配(Most Fields)
- 3.3 跨字段匹配(Cross Fields)
- 总结
前言
本文主要介绍 ES 的一下高级检索功能,80% 的业务场景,简单搜索就可以实现了,但是在一些复杂的业务场景中,我们必须使用一些高级的功能来满足,比如在一些与舆情监测项目或者智能推荐、猜你想搜这种复杂的功能,有时候需要搜索中需要提高相关度,有时候搜索需要减低相关度等。
Don’t bebe so much, show the codes…
让我们来准备一些数据来进行高级搜索测试,但是问题来了,这些数据真的是头疼,不好生成一些示例数据出来,这时候,chatGTP这是无敌了,简直太方便了。
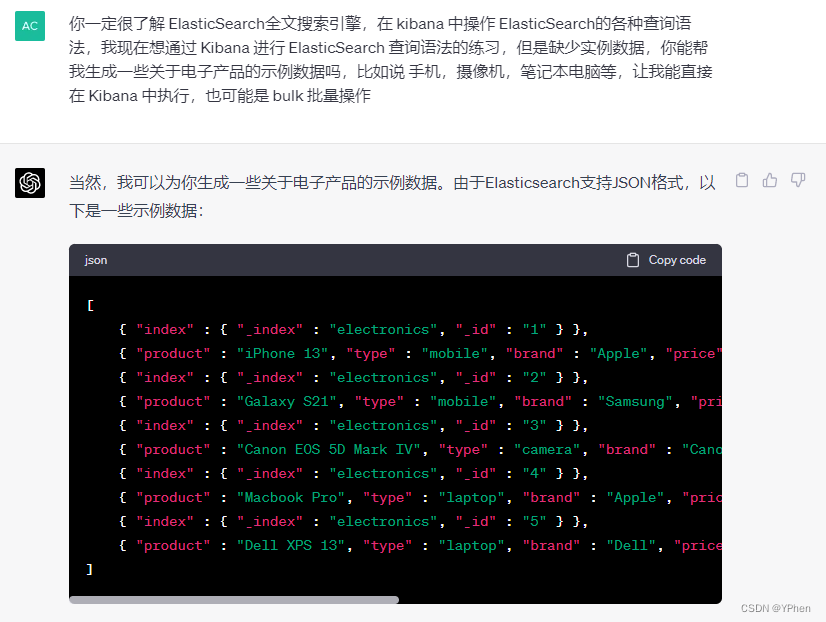
一、Boosting(控制相关度)
Boosting 是控制相关度的一种手段,此操作最好是需要 boost 参数来控制评分权重,如下:
- boost > 1时,打分的权重相对性提升
- 0 < boost < 1时,打分权重相对性降低
- boot < 0 时,负分
“positive” 查询用于匹配你感兴趣的文档,而 “negative” 查询匹配的文档会被降级,这就可以在不排除某些文档的情况下对文档进行检索,只是结果中存在相似度较低的文档,排在后面。
negative_boost 对 negative 部分 query 生效,在计算评分时,negative 部分 query 评分乘以 negative_boost 值。
GET electronics/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"desc": "手机"
}
},
"negative": {
"match": {
"desc": "相机"
}
},
"negative_boost": 0.2
}
},
"from": 1,
"size": 10
}
应用场景:希望检索的关键词的结果不是不出现,而是排在最后面。
二、Bool 布尔查询
2.1 复合查询
Bool 查询是一个或者多个子查询的组合体,包括 4 中子句,其中 2 种是影响评分的,两种不影响评分,具体如下:
- must:相当于JAVA中的 && 操作符,必须匹配,支持评分。
- should:相当于 JAVA 中的 || 操作符,选择性匹配,支持评分。
- must_not:相当于JAVA中的 !,必须不匹配,不支持评分。
- filter:简单的过滤,不支持评分。
注意面试中可能会被问到:
| 操作 | 描述 |
|---|---|
| Query | 会进行相关性算分,检索性能不高 |
| Filter | 不会进行相关性算分,检索性能会更好 |
注意: 把多个子查询合并为一个复合查询时,比如 bool 查询,每个子查询计算的评分会被合并到相关性总评分中。
布尔查询语法也是相当灵活:
1、子查询的顺序随意;
2、也可以嵌套多个子查询;
3、没有 must 条件的情况下,should 条件至少满足一项。
比如下面这一条示例,检索了 electronics 索引中,产品名称(title)带 “苹果” 的,描述(desc)中带有 “手机” 或者 “笔记本” 的,品牌(brand)是 “Apple” 的,颜色过滤掉 “black” 的结果。
brand.keyword 这里, 因为我并没有定义 schema,但是我用了 term 来精确匹配的,所以需要用 (.keyword) 来把 brand 字段设置成关键词匹配。
POST electronics/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "苹果"
}
}
],
"should": [
{
"match": {
"desc": "手机"
}
},
{
"match": {
"desc": "笔记本"
}
}
],
"filter": {
"term": {
"brand.keyword": "Apple"
}
},
"must_not": [
{
"term": {
"color": "black"
}
}
]
}
}
}
2.2 包含不相等查询
在具体业务中,有的业务数据并不是一个简单的字符串或者是数值,而是一个多值的情况,这种情况下我们在检索时希望精确匹配到多值中的一项,可以用 match 来查询,语句如下:
POST electronics/_search
{
"query": {
"match": {
"product_agency": "打电话"
}
},
"from": 0,
"size": 20
}
我们也可以换成 term 来精确匹配,需要加上 .keyword,语句如下:
POST electronics/_search
{
"query": {
"term": {
"product_agency.keyword": "打电话"
}
},
"from": 0,
"size": 20
}
以上两种方式,match 和 term 都可以查询出 product_agency 是 “打电话” 的手机信息,不过 “谷歌” 的手机确实没用过,那打电话的功能应该是有的,我要查询出只能打电话的,这时候可以增加 count 字段来解决这个问题,语句如下:
当然,如果 must 改为 filter, 则效率更佳!
POST electronics/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"product_agency.keyword": {
"value": "打电话"
}
}
},
{
"term": {
"product_agency_count": {
"value": 1
}
}
}
]
}
},
"from": 0,
"size": 20
}
说实话,写完之后自我觉得这个例子没啥特别之处。
2.3 实现 should_not 查询
有没有发现 bool 查询里面 should_not 是没有的,我们可以通过 bool 嵌套多个子查询来实现,在 should 中嵌套 bool,再嵌套 must_not 来实现,语句如下:
POST electronics/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"product_agency.keyword": {
"value": "打电话"
}
}
}
],
"should": [
{
"bool": {
"must_not": [
{
"term": {
"price": {
"value": 699.99
}
}
}
]
}
}
],
"minimum_should_match": 1
}
},
"from": 0,
"size": 20
}
注意: 这里需要加上 minimum_should_match 这个参数,最少匹配到一个 should 查询,这样才会生效。
说实话,这种只有在鸡肋业务中才会用到吧。
2.4 控制查询相关性算分
三、多字段查询
当值多字段查询操作在工作中很常见,大多数情况下就是用户数据一个关键词(通常是一个字符串),然后匹配到相关性最高的文档。
有三种这样的场景:
- 最佳字段(Best Fields):字段直接相互竞争又相互关联,比如 title 和 content 字段,评分来自最匹配字段。
- 多数字段(Most Fields):处理英文内容常见手段,在主字段(English Analyzer)抽取词干,加入同义词以匹配更多的文档;相同的文本,加入子字段(Standard Analyzer)以更加精准的匹配。
- 混合字段(Cross Field):对于某些信息,比如 名称、地址、图书的信息等等,需要多个字段才能确定,单个字段只能作为整体的一部分,希望在这些字段中尽可能找到多的词。
3.1 最佳字段匹配(Best Fields)
在多个字段匹配时,用 bool 的 should 就可以实现,比如下面这条查询:
POST electronics/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "苹果"
}
},
{
"match": {
"desc": "苹果"
}
}
]
}
}
}
但是这个查询并不会匹配到最好的结果,为什么?
should 的评分过程是这样的,匹配 should 语句中的多个子查询,加和多个子查询的评分,乘以匹配语句的总评分,除以语句的总数,显然这样的评分不够完美。
title 和 desc 两个字段属于竞争关系,所以不应该是评分简单加和,而是单个最佳字段的评分。
3.1.1 Dis Max Query
且看下面这条查询,可以通过 tie_breaker 来进行调整。
tie_breaker 介于 0 ~ 1 之间的浮点数,0 代表使用最佳匹配,1 代表所有语句同等重要。
1、取得最佳匹配的评分 _score。
2、将其他语句的评分与 tie_breaker(决胜局的意思) 进行相乘。
3、对所有评分求和并进行规范化。
看官网解释!!
POST electronics/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.7,
"boost": 1.2,
"queries": [
{
"match": {
"title": "苹果"
}
},
{
"match": {
"desc": "苹果"
}
}
]
}
}
}
3.1.2 Multi Match Query
另一种方式就是使用 multi_match 来检索,这种方式默认就是 best_fields 检索,所以可以不用指定 type 参数,tie_breaker 按照结果可调节。
POST electronics/_search
{
"query": {
"multi_match": {
"query": "苹果",
"fields": ["title", "desc"],
"type": "best_fields",
"tie_breaker": 0.2
}
}
}
3.2 多数字段匹配(Most Fields)
准备一些测试数据,首先来创建一个 index 并且定义 schema,加两条测试数据。
PUT /blogs
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "english",
"fields": {
"std": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
}
POST blogs/_bulk
{ "index": { "_id": 1 }}
{ "title": "My dog barks" }
{ "index": { "_id": 2 }}
{ "title": "I see a lot of barking dogs on the road " }
{ "index": { "_id": 3 }}
{ "title": "I have a dog named bark" }
{ "index": { "_id": 4 }}
{ "title": "I see barking dogs on the street, they are running and playing " }
用下面的检索语句来查询,发现查询出了所有的数据,结果与我们的预期不匹配。
GET blogs/_search
{
"query": {
"match": {
"title": "braking dogs"
}
}
}
下面的查询语句来查询,发现结果好了很多,用 title 字段来尽可能的匹配更多的文档,提升召回率,同时又用 title.std 将相关度更高的文档置顶。
GET blogs/_search
{
"query": {
"multi_match": {
"query": "braking dogs",
"fields": ["title", "title.std"],
"type": "most_fields"
}
}
}
我们可以更精确一点,每个字段对于最终评分可以通过自定义评分 boost 来控制。
比如 title 字段更重要,我们可以用 boost 来控制,同时也降低了其他信号字段的作用。
GET blogs/_search
{
"query": {
"multi_match": {
"query": "braking dogs",
"fields": ["title^10", "title.std"],
"type": "most_fields"
}
}
}
3.3 跨字段匹配(Cross Fields)
创建一个 address 的 index,字段是 provice 和 city,利用 ik 分词器分词。
PUT /address
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
PUT /address/_bulk
{ "index": { "_id": "1"} }
{"province": "甘肃","city": "酒泉"}
{ "index": { "_id": "2"} }
{"province": "湖南","city": "常德"}
{ "index": { "_id": "3"} }
{"province": "陕西","city": "西安"}
{ "index": { "_id": "4"} }
{"province": "湖南","city": "邵阳"}
{ "index": { "_id": "5"} }
{"province": "甘肃","city": "武威"}
{ "index": { "_id": "6"} }
{"province": "甘肃","city": "玉门"}
先用 most_fields 的方式来查询 “甘肃酒泉”,但是结果不符合预期,甘肃玉门 和 甘肃武威 也出来了,查询不支持 operator 。
GET address/_search
{
"query": {
"multi_match": {
"query": "甘肃酒泉",
"fields": ["province", "city"],
"type": "most_fields"
}
}
}
使用 cross_fields 来查询,支持 operator 操作。
查询结果符合我们的预期,只返回了 甘肃酒泉 的文档。
GET address/_search
{
"query": {
"multi_match": {
"query": "甘肃酒泉",
"fields": ["province","city"],
"type": "cross_fields",
"operator": "and"
}
}
}
还有另一种方式来解决,就是增加一个字段,用于检索完整的地址,比如:full_address 字段。
PUT /address
{
"mappings" : {
"properties" : {
"province" : {
"type" : "keyword",
"copy_to": "full_address"
},
"city" : {
"type" : "text",
"copy_to": "full_address"
}
}
},
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
这样我们就可以用 full_address 字段来检索 “甘肃酒泉” 这个关键词了,利用 match 匹配就可以了,语句如下:
GET /address/_search
{
"query": {
"match": {
"full_address": {
"query": "湖南常德",
"operator": "and"
}
}
}
}
总结
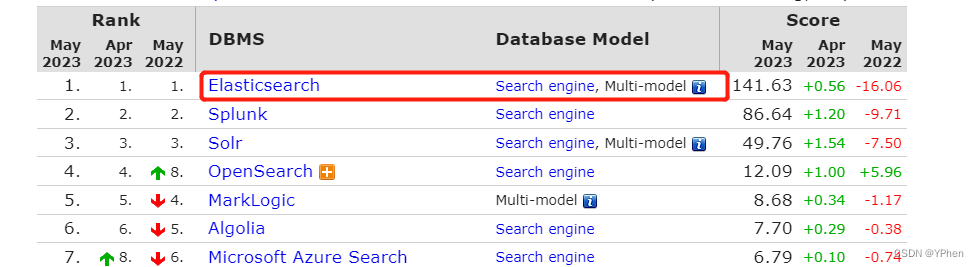
ES 是目前全文检索排行榜 首位,而且不断升级,现在一到 8.x 版本了,基本上 solr 搜索引擎用的公司已经不多了,虽然搜索速度很快,但做不到实时,这就很尴尬了,再加上定制写一写什么关联查询,简直鸡肋了。
ES 提供了很多高级检索,能很好的满足一些复杂的业务场景,可以嵌套,这样就不用总是加字段这种很 low 的方式来解决一些业务问题了。

![[ Azure 云计算从业者 | AZ-900 ] Chapter 06 | 认识与了解 Azure 中相关的计算服务](https://img-blog.csdnimg.cn/a96a93b244d3474ea486758a2b64011b.png)