一、前言
在前面我们通过以下章节对数据分片有了基础的了解:
Spring Boot集成ShardingSphere实现数据分片(一) | Spring Cloud 40
Spring Boot集成ShardingSphere实现数据分片(二) | Spring Cloud 41
Spring Boot集成ShardingSphere实现数据分片(三) | Spring Cloud 42
书接上回,本章进行对以下部分进行讲解演示:
- 基于时间范围的分片算法(
INTERVAL)实现按月数据分片 - 创建自定义
ShardingSphere分片算法及实现按月数据分片
下面我们开始正文内容。
二、时间范围分片算法
2.1 简介
-
类型:
INTERVAL -
可配置属性:
| 属性名称 | 数据类型 | 说明 | 默认值 |
|---|---|---|---|
datetime-pattern | String | 分片键的时间戳格式,必须遵循 Java DateTimeFormatter 的格式。例如:yyyy-MM-dd HH:mm:ss,yyyy-MM-dd 或 HH:mm:ss 等。但不支持与 java.time.chrono.JapaneseDate 相关的 Gy-MM 等 | |
datetime-lower | String | 时间分片下界值,格式与 datetime-pattern 定义的时间戳格式一致 | |
datetime-upper (可选项) | String | 时间分片上界值,格式与 datetime-pattern 定义的时间戳格式一致 | 当前时间 |
sharding-suffix-pattern | String | 分片数据源或真实表的后缀格式,必须遵循 Java DateTimeFormatter 的格式,必须和 datetime-interval-unit 保持一致。例如:yyyyMM对应MONTHS | |
datetime-interval-amount (可选项) | int | 分片键时间间隔,超过该时间间隔将进入下一分片 | 1 |
datetime-interval-unit (可选项) | String | 分片键时间间隔单位,必须遵循 Java ChronoUnit 的枚举值。例如:MONTHS | DAYS |
-
所属类:
org.apache.shardingsphere.sharding.algorithm.sharding.datetime.IntervalShardingAlgorithm -
注意事项:
此算法主动忽视了
datetime-pattern的时区信息。 这意味着当datetime-lower, datetime-upper和传入的分片键含有时区信息时,不会因为时区不一致而发生时区转换。 当传入的分片键为java.time.Instant时存在特例处理,其会携带上系统的时区信息后转化为datetime-pattern的字符串格式,再进行下一步分片。
ShardingSphere内置提供了多种分片算法,请见官网:
https://shardingsphere.apache.org/document/5.2.1/cn/user-manual/common-config/builtin-algorithm/sharding/
2.2 使用示例
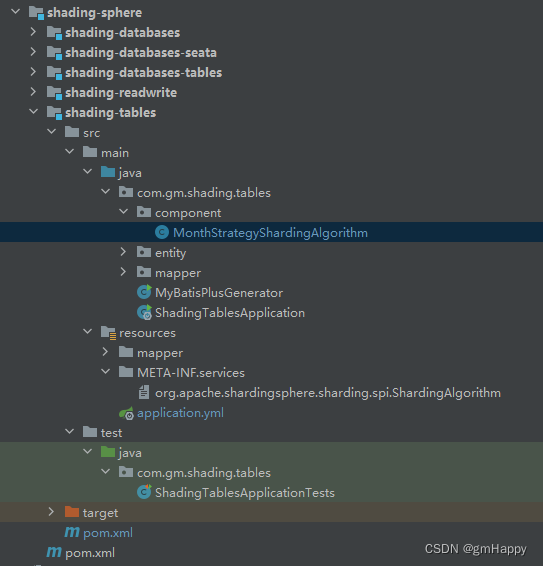
2.2.1 项目总体结构
2.2.2 Maven依赖
shading-sphere/shading-tables/pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>shading-sphere</artifactId>
<groupId>com.gm</groupId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>shading-tables</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>
<dependency>
<groupId>org.yaml</groupId>
<artifactId>snakeyaml</artifactId>
<version>1.33</version>
</dependency>
</dependencies>
</project>
-
shardingsphere-jdbc-core-spring-boot-starter使用版本5.2.1 -
JDBC的ORM框架选用mybatis-plus
2.2.3 逻辑表 t_share_month
DROP TABLE IF EXISTS `t_share_month_202304`;
CREATE TABLE `t_share_month_202304` (
`id` bigint NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`create_time` datetime NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_share_month_202305`;
CREATE TABLE `t_share_month_202305` (
`id` bigint NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`create_time` datetime NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_share_month_202306`;
CREATE TABLE `t_share_month_202306` (
`id` bigint NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`create_time` datetime NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
2.2.4 配置文件
shading-sphere/shading-tables/src/main/resources/application.yml:
spring:
application:
name: @artifactId@
shardingsphere:
# 数据源配置
datasource:
names: ds1
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.0.35:3306/db1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
# 定义规则
rules:
sharding:
# 数据分片规则配置
tables:
# 指定某个表的分片配置,逻辑表名
t_share_month:
actual-data-nodes: ds1.t_share_month_202$->{304..306}
#actual-data-nodes: ds1.t_share_month_${2022..2030}${(1..12).collect{t ->t.toString().padLeft(2,'0')}}
table-strategy:
standard:
sharding-column: create_time
sharding-algorithm-name: t_share_month_table_inline
key-generate-strategy:
column: id
key-generator-name: snowflake
# 分片算法配置
sharding-algorithms:
# 分片算法名称
t_share_month_table_inline:
type: INTERVAL
props:
datetime-pattern: yyyy-MM-dd HH:mm:ss
datetime-lower: 2023-04-01 00:00:00
datetime-interval-unit: MONTHS
sharding-suffix-pattern: yyyyMM
# 分布式序列算法配置(如果是自动生成的,在插入数据的sql中就不要传id,null也不行,直接插入字段中就不要有主键的字段)
keyGenerators:
# 分布式序列算法名称
snowflake:
# 分布式序列算法类型
type: SNOWFLAKE
props:
sql-show: true #显示sql
配置简要说明:
- 逻辑表
t_share_month按照create_time分片键进行每月数据分片
注意事项:
- 当部分月份的物理表未实际创建时,会造成分布式序列不生效,此时如物理表主键采用分布式序列会提示:
Cause: java.sql.SQLException: Field 'id' doesn't have a default value。
三、自定义分片算法
ShardingSphere支持两种方式来扩展自定义算法:SPI 和 ClassBased。CLASS_BASE实际上是已经实现了的SPI。
目录结构及依赖情况,请见2.2.1和2.2.2章节。
ShardingSphere内置提供了多种分片算法,请见官网:
https://shardingsphere.apache.org/document/5.2.1/cn/user-manual/common-config/builtin-algorithm/sharding/
3.1 创建自定义分片算法
新建一个类MonthStrategyShardingAlgorithm并实现StandardShardingAlgorithm接口。
com/gm/shading/tables/component/MonthStrategyShardingAlgorithm.java:
import com.google.common.collect.Range;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.sharding.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.RangeShardingValue;
import org.apache.shardingsphere.sharding.api.sharding.standard.StandardShardingAlgorithm;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.*;
@Slf4j
public class MonthStrategyShardingAlgorithm implements StandardShardingAlgorithm<LocalDateTime> {
/** 配置值需要储存 */
private Properties props;
private static final DateTimeFormatter yyyyMM = DateTimeFormatter.ofPattern("yyyyMM");
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<LocalDateTime> preciseShardingValue) {
LocalDateTime dateTime = preciseShardingValue.getValue();
String tableSuffix = dateTime.format(yyyyMM);
String logicTableName = preciseShardingValue.getLogicTableName();
String table = logicTableName.concat("_").concat(tableSuffix);
System.out.println("MonthStrategyShardingAlgorithm.doSharding table name: {}" + table);
return collection.stream().filter(s -> s.equals(table)).findFirst().orElseThrow(() -> new RuntimeException("逻辑分表不存在"));
}
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<LocalDateTime> rangeShardingValue) {
// 逻辑表名
String logicTableName = rangeShardingValue.getLogicTableName();
// between and 的起始值
Range<LocalDateTime> valueRange = rangeShardingValue.getValueRange();
Set<String> queryRangeTables = extracted(logicTableName, valueRange.lowerEndpoint(), valueRange.upperEndpoint());
ArrayList<String> tables = new ArrayList<>(collection);
tables.retainAll(queryRangeTables);
System.out.println("MonthStrategyShardingAlgorithm.doSharding tables collection name: {}" + tables);
return tables;
}
/**
* 根据范围计算表明
*
* @param logicTableName 逻辑表明
* @param lowerEndpoint 范围起点
* @param upperEndpoint 范围终端
* @return 物理表名集合
*/
private Set<String> extracted(String logicTableName, LocalDateTime lowerEndpoint, LocalDateTime upperEndpoint) {
Set<String> rangeTable = new HashSet<>();
while (lowerEndpoint.isBefore(upperEndpoint)) {
String str = getTableNameByDate(lowerEndpoint, logicTableName);
rangeTable.add(str);
lowerEndpoint = lowerEndpoint.plusMonths(1);
}
// 获取物理表明
String tableName = getTableNameByDate(upperEndpoint, logicTableName);
rangeTable.add(tableName);
return rangeTable;
}
/**
* 根据日期获取表明
*
* @param dateTime 日期
* @param logicTableName 逻辑表名
* @return 物理表名
*/
private String getTableNameByDate(LocalDateTime dateTime, String logicTableName) {
String tableSuffix = dateTime.format(yyyyMM);
return logicTableName.concat("_").concat(tableSuffix);
}
@Override
public Properties getProps() {
return props;
}
@Override
public void init(Properties properties) {
this.props = properties;
}
@Override
public String getType() {
return "CREATE_TIME";
}
}
3.2 基于ClassBased使用自定义分片算法
完整配置文件如下:
server:
port: 8844
spring:
application:
name: @artifactId@
shardingsphere:
# 数据源配置
datasource:
names: ds1
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.0.35:3306/db1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
# 定义规则
rules:
sharding:
# 数据分片规则配置
tables:
# 指定某个表的分片配置,逻辑表名
t_share_month:
actual-data-nodes: ds1.t_share_month_202$->{304..306}
#actual-data-nodes: ds1.t_share_month_${2022..2030}${(1..12).collect{t ->t.toString().padLeft(2,'0')}}
table-strategy:
standard:
sharding-column: create_time
sharding-algorithm-name: t_share_month_table_inline
key-generate-strategy:
column: id
key-generator-name: snowflake
# 分片算法配置
sharding-algorithms:
# 分片算法名称
t_share_month_table_inline:
type: CLASS_BASED
props:
strategy: standard
# 自定义标准分配算法
algorithmClassName: com.gm.shading.tables.component.MonthStrategyShardingAlgorithm
# 分布式序列算法配置(如果是自动生成的,在插入数据的sql中就不要传id,null也不行,直接插入字段中就不要有主键的字段)
keyGenerators:
# 分布式序列算法名称
snowflake:
# 分布式序列算法类型
type: SNOWFLAKE
props:
sql-show: true #显示sql
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
自定义算法核心配置:
# 分片算法名称
t_share_month_table_inline:
type: CLASS_BASED
props:
strategy: standard
# 自定义标准分配算法
algorithmClassName: com.gm.shading.tables.component.MonthStrategyShardingAlgorithm
3.3 基于SPI使用自定义分片算法
3.3.1 SPI配置
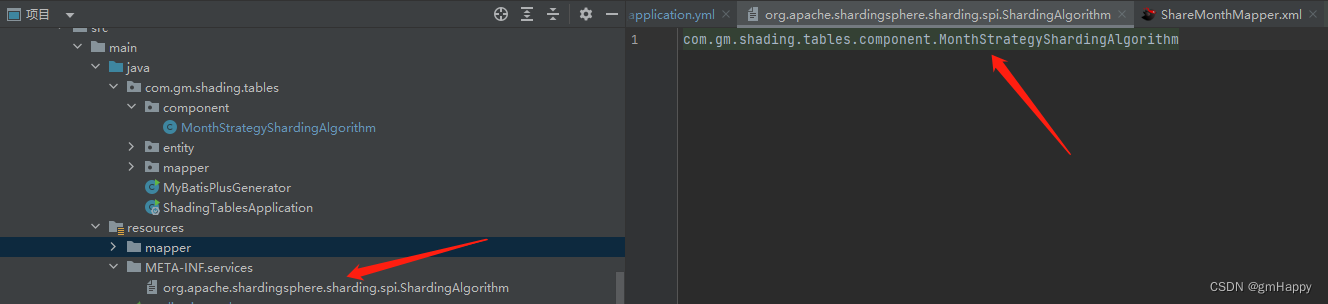
在 META-INF/services/org.apache.shardingsphere.sharding.spi.ShardingAlgorithm 文件中添加自定义分片算法全类名:
com.gm.shading.tables.component.MonthStrategyShardingAlgorithm
3.3.2 配置文件
完整配置文件如下:
server:
port: 8844
spring:
application:
name: @artifactId@
shardingsphere:
# 数据源配置
datasource:
names: ds1
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.0.35:3306/db1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: '1qaz@WSX'
# 定义规则
rules:
sharding:
# 数据分片规则配置
tables:
# 指定某个表的分片配置,逻辑表名
t_share_month:
actual-data-nodes: ds1.t_share_month_202$->{304..306}
#actual-data-nodes: ds1.t_share_month_${2022..2030}${(1..12).collect{t ->t.toString().padLeft(2,'0')}}
table-strategy:
standard:
sharding-column: create_time
sharding-algorithm-name: t_share_month_table_inline
key-generate-strategy:
column: id
key-generator-name: snowflake
# 分片算法配置
sharding-algorithms:
# 分片算法名称
t_share_month_table_inline:
type: CREATE_TIME
# 分布式序列算法配置(如果是自动生成的,在插入数据的sql中就不要传id,null也不行,直接插入字段中就不要有主键的字段)
keyGenerators:
# 分布式序列算法名称
snowflake:
# 分布式序列算法类型
type: SNOWFLAKE
props:
sql-show: true #显示sql
mybatis:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
自定义算法核心配置:
# 分片算法配置
sharding-algorithms:
# 分片算法名称
t_share_month_table_inline:
type: CREATE_TIME
注意事项:
- 配置文件中分片算法的
type属性,必须与自定义分片算法中的getType()方法的值相对应。
3.4 源码
上述示例完整源码请见:https://gitee.com/gm19900510/springboot-cloud-example.git