文章目录
- 高级搜索
- 通配符
- 批量选中引用序号@上标调整
- 搜索@替换作用范围设置🎈
- 通过样式选择作用区域
- 通过鼠标选择作用区域
- 高级替换
- 操作顺序
- 标点符号替换🎈
- 将英文逗号替换为中文逗号
- 使用普通查找和替换:
- 使用通配符替换
- 将英文句点替换为中文句号
- 使用普通查找替换
- 使用通配符替换
- 借助校对工具来替换
高级搜索
- Find text - Microsoft Support
通配符
- 在搜索中使用通配符 - Microsoft 支持
- Examples of wildcard characters - Microsoft Support
- Power User Tips and Tricks - Word, Excel, Dreamweaver (ntu.edu.sg)
- Using wildcards - Microsoft Word 365 (officetooltips.com)
批量选中引用序号@上标调整
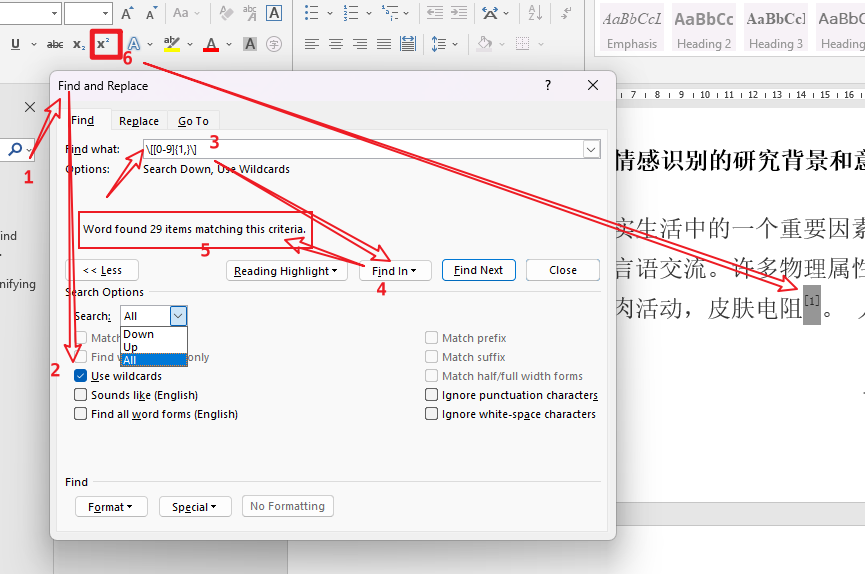
- 利用上述方法,可以一次性将正文中的citations
[xx]调整为上标! \[[0-9]{1,3}\]- 这里的
{1,3}表示对序号为1位数,2位数以及3位数的编号纳入匹配项 - 通常的文献参考在2位数到三位数不建议超过3,容易导致错误匹配
- 这里的
- 不幸的是,这种批量缩小的为上标的效果不稳定:
- 当您更新目录的时候,上标就会变回正文
- 导出其他格式(比如pdf),也无法保持上标
- 所以这种方只是临时偷个懒,想要稳定效果,还是建议文章定稿后批量地角标处理
搜索@替换作用范围设置🎈
通过样式选择作用区域
-
通常情况下,这种方式是常用的。
-
在搞机查找或替换的窗口中点击格式->样式,选中特定的样式,比如
正文样式 -
搜索选项里的搜索下拉框中有三个值:向上,向下,全部(这里的全部理解为循环搜索更加合适,而不是说指定搜索范围,而是方向)
-
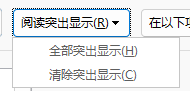
如果要统计点击阅读突出显示,如果选择全部,则会高亮所有匹配的内容,并且给出统计,
- 点击在一下项目中查找的某个按钮,也会统计当前表达式匹配了多少地方。
-
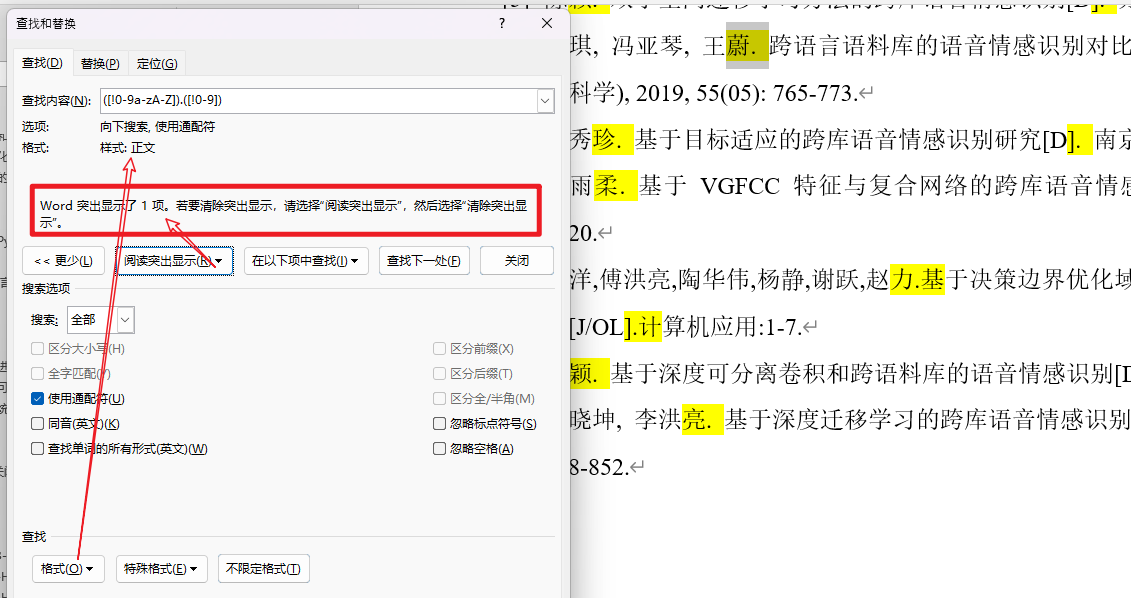
例如下面的例子中,正文部分有一个地方需要将英文句点替换为中文句号
-
注意,高亮部分的提示可能是滞后的,而不是实时的
-
如果您修改了查找表达式,且需要确保当前的高亮是准确匹配最新的表达式,则需要手动地通过点击下拉框按钮提供的
清除突出显示后再重新点击全部突出先显示(直接点击全部突出显示不会刷新高亮内容) -
-
-
通过鼠标选择作用区域
-
在以下项中查找中选择需要匹配的文档范围
-
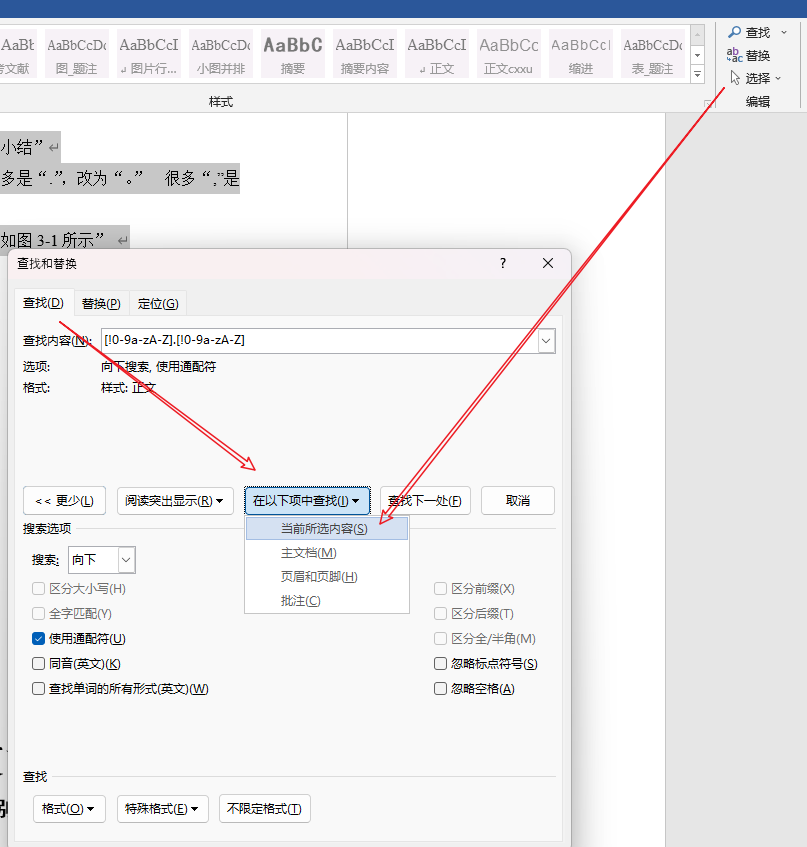
例如,我只想对正文部分进行匹配,而不希望影响到参考文献,可以这么做:
-
为了方便选中指定内容,假设文档的正文用的同一格式(这也是大多数情况,容易满足)
-
然后点击
开始->选择:选择所有格式类似的的文本 -
回到高级查找@替换窗口,将在以下项中查找的值改为选中内容
-
-
-
高级替换
- Replacing special characters - Microsoft Word 365 (officetooltips.com)
- Finding and replacing characters using wildcards (wordmvp.com)
操作顺序
- 先进行搜索,然后再替换!
- 搜索中选择搜索范围(搜索项选择),比如要搜索主文档或者页眉页脚等
标点符号替换🎈
将英文逗号替换为中文逗号
-
由于一片文章中可能既有英文段落又有中文段落,直接所有位置的英文逗号替换为中文逗号是不行的
-
中文段落用中文逗号
-
英文段落用英文逗号
-
-
假设某个文档中中文段落混用了英文逗号,下面是一些方案
使用普通查找和替换:
-
如果您的文档不是特别长,或者搜索
,发现总数不多,可以使用逐个检查替换来解决 -
还可以手动选择中文段落,然后直接使用基础替换将英文逗号替换为中文,最为简单
-
表达式
],这部分可以匹配发生文献引用的段落,这部分可能需要手动关注一下
使用通配符替换
-
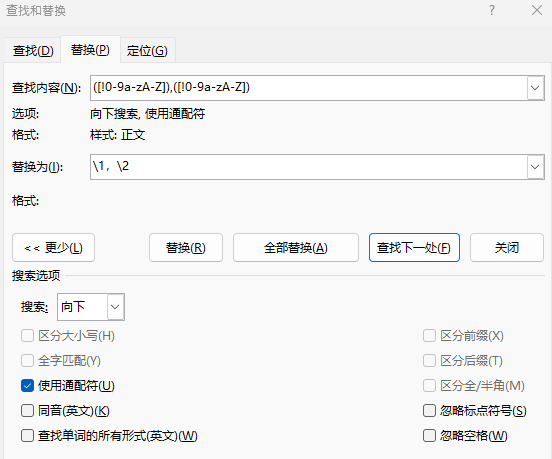
-
一次扫描1:
- 查找表达式:
([!0-9a-zA-Z]),- 表示中文(或阿拉伯数字)后跟上了一个英文逗号的情况(我们假设数字阿拉伯数字后跟中文逗号)
- 英文段落中的逗号不会被匹配到
- 和上图所示的不同,有时候我们会在中文段落插入英文单词,这时候我们依然认为这是个中文段落,因此只匹配一般可能会更加符合需求
- 目标表达式:
\1,
- 查找表达式:
-
二次扫描2:
-
,([!0-9a-zA-Z])也可以,目标表达式为,\1 -
实例文本:
-
相关的超参数:正则参数为0.001,gamma参数为0.001,核函数采用’poly’。
-
-
补充替换:
- 阿拉伯数字后跟的逗号建议自己逐个检查,通常这种情形不多
- 检查通配表达式为
[0-9],和,[0-9],分别用它们进行排查
将英文句点替换为中文句号
-
对于理工科的论文而言,许多试验数据带有小数点
-
参考文献中,即便中文,也用的英文标点符号
-
需要重点排查的主要有:
-
摘要
-
正文
-
tips:可以通过样式设置搜索替换的作用范围
-
使用普通查找替换
-
这种方式适合一段一段的处理(注意包含试验实验数据的段落,它们通常带有小数,容易造成不恰当的匹配)
-
直接在中文段落中搜索英文句点
.,然后突出显示它们,根据是否适合采用全部替换
使用通配符替换
-
通配符来查找并替换英文句点(小数点)为中文
- 假设文本中仅包含中文,英文,小数数值
- 只有英文单词(字母)之间和数字之间允许英文句点或说小数点
- 英文和数字之间则分情况,如果是英文段落,则可以用英文句点
- 如果是中文段落,则还是用中文句号,这种情况比较少。
- 非英文,非数字的字符后面通常不得跟着英文句点
([!0-9a-zA-Z]).- 目标表达式:
。\1
- 反之一样:
.([!0-9a-zA-Z])- 目标表达式:
\1。
- 手动判断:(可用于查找)
([0-9a-zA-Z]).([0-9a-zA-Z])
- 假设文本中仅包含中文,英文,小数数值
-
常用版本:可以避开英文段落和小数数值的段落,而中文混杂英文单词的段落依然接受查找
-
查找表达式:
([!0-9a-zA-Z]).([!0-9])-
示例文本:
-
用于各种语音情感识别任务.MFCC可以从语音信号中提取出频谱特征
-
-
-
([0-9a-zA-Z]).
-
-
借助校对工具来替换
- 现在有些专门的文档校对和润色工具,可以帮助用户更加轻松的检查出基本错误,甚至集成了AI功能









![[架构之路-190]-《软考-系统分析师》-4-据通信与计算机网络-5-图解CRC计算方法与步骤](https://img-blog.csdnimg.cn/6da120259ec7433581c7e7a634f21c8f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcXFfNTI1MTQ3NTA=,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)