1 索引分类
在MySQL数据库,将索引的具体类型主要分为以下几类:主键索引、唯一索引、常规索引、全文索引。
| 分类 | 含义 | 特点 | 关键字 |
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建, 只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
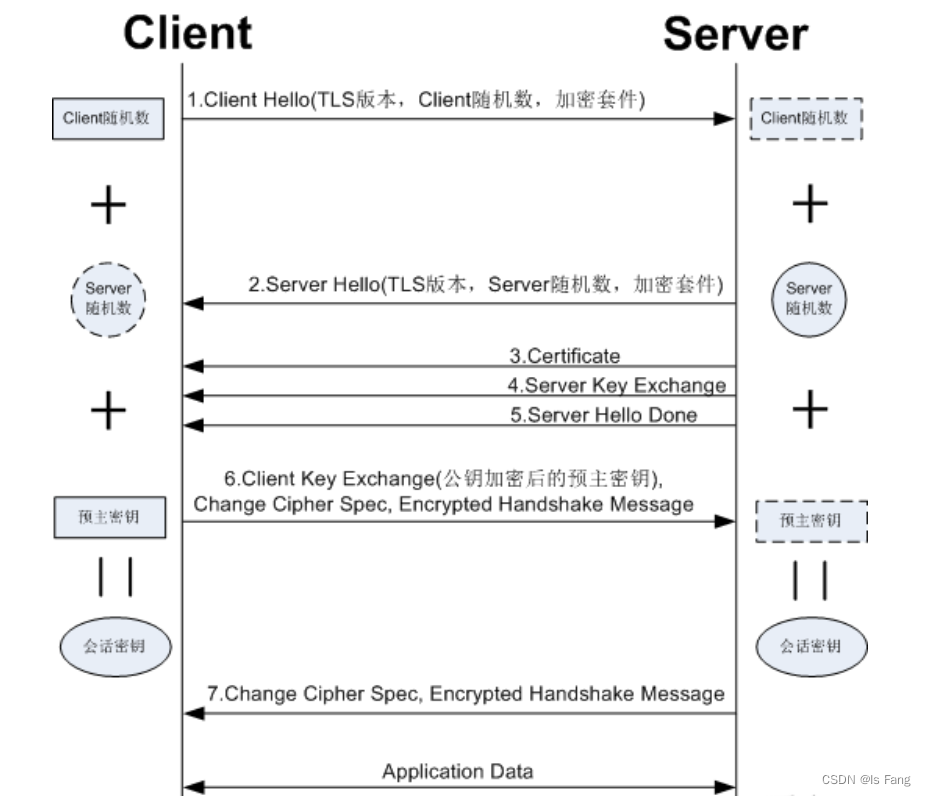
2 聚集索引&二级索引
而在在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
| 聚集索引(Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
聚集索引和二级索引的具体结构如下:
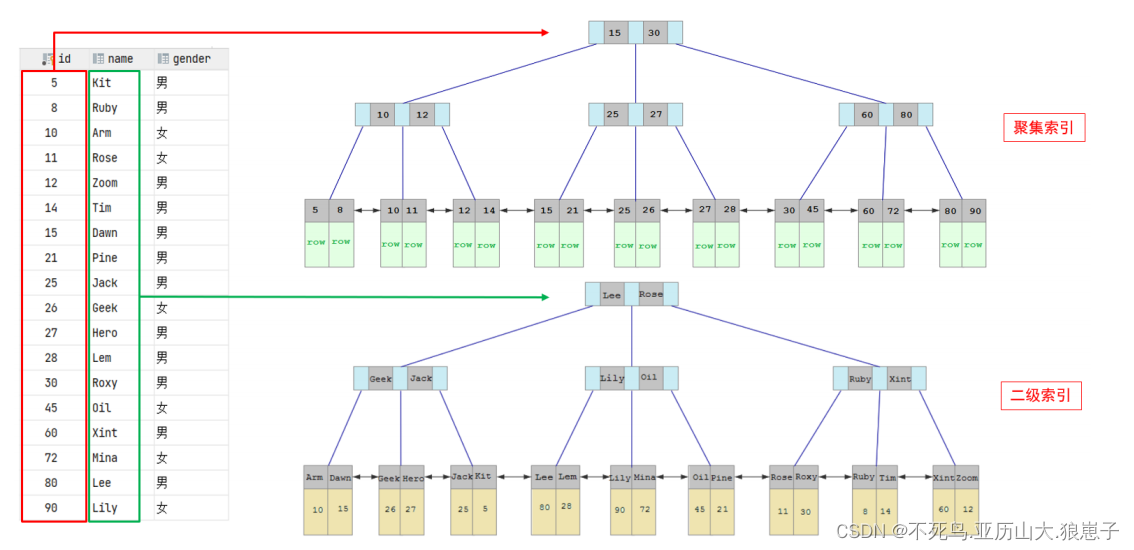
- 聚集索引的叶子节点下挂的是这一行的数据 。
- 二级索引的叶子节点下挂的是该字段值对应的主键值。
接下来,我们来分析一下,当我们执行如下的SQL语句时,具体的查找过程是什么样子的。
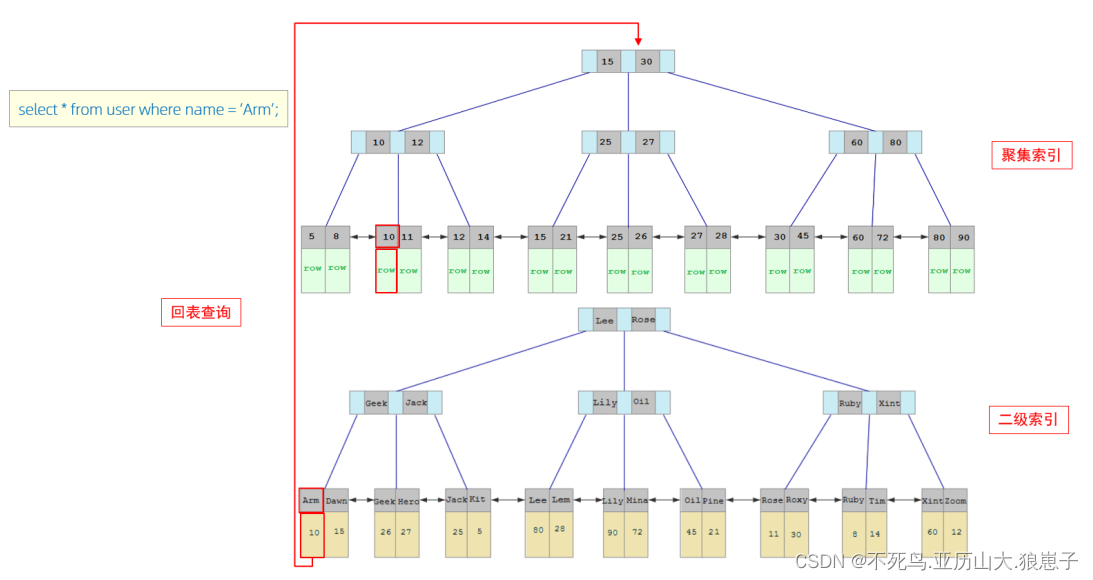
具体过程如下:
- 由于是根据name字段进行查询,所以先根据name='Arm'到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到 Arm 对应的主键值 10。
- 由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row。
- 最终拿到这一行的数据,直接返回即可。
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
思考题1:
以下两条SQL语句,那个执行效率高? 为什么?
A. select * from user where id = 10 ;
B. select * from user where name = 'Arm' ;
备注: id为主键,name字段创建的有索引;
解答:
A 语句的执行性能要高于B 语句。
因为A语句直接走聚集索引,直接返回数据。 而B语句需要先查询name字段的二级索引,然后再查询聚集索引,也就是需要进行回表查询。
思考题二:
InnoDB主键索引的B+tree高度为多高呢?
假设:
一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB的指针占用6个字节的空
间,主键即使为bigint,占用字节数为8。
高度为2:
n * 8 + (n + 1) * 6 = 16*1024 , 算出n约为 1170
1171* 16 = 18736
也就是说,如果树的高度为2,则可以存储 18000 多条记录。
高度为3:
1171 * 1171 * 16 = 21939856
也就是说,如果树的高度为3,则可以存储 2200w 左右的记录。








![[架构之路-190]-《软考-系统分析师》-4-据通信与计算机网络-5-图解CRC计算方法与步骤](https://img-blog.csdnimg.cn/6da120259ec7433581c7e7a634f21c8f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcXFfNTI1MTQ3NTA=,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)