上篇文章已经全局初步介绍了SAM和其功能,本篇作为进阶使用。
文章目录
- 0.前言
- 1.SAM原论文
- 1️⃣名词:提示分割,分割一切模型,数据标注,零样本,分割一切模型的数据集
- 2️⃣Introduction
- 3️⃣Task: promptable segmentation
- 4️⃣ Model: Segment Anything Model
- 5️⃣ Data: data engine & dataset
- 2.代码实战
- 1️⃣ 配环境
- 2️⃣装包
- 3️⃣下载权重版本
- 4️⃣代码
- 5️⃣会有报错
- 3.SAM相关论文
- 🍏Segmenting anything also Detect anything
- 🍐Segment Everything Everywhere All at Once
- 🍊SegGPT: Segmenting Everything In Context
- 🍋Anything-3D: Towards Single-view Anything Reconstruction in the Wild
- 🍌SAM Fails to Segment Anything? -SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, and More
- 🍒Segment Anything Is Not Always Perfect: An Investigation of SAM on Different Real-world Applications
- ——————————————医疗影像分割领域:————————————
- 🍉SAMM (SEGMENT ANY MEDICAL MODEL): A 3D SLICER INTEGRATION TO SAM
- 🍇SAM.MD: Zero-shot medical image segmentation capabilities of the Segment Anything Model
- 🍓Accuracy of Segment-Anything Model (SAM) in Medical Image Segmentation Tasks
- 🍈When SAM Meets Medical Images: An Investigation of Segment Anything Model (SAM) on Multi-phase Liver Tumor Segmentation
- 🥭Segment Anything Model (SAM) for Digital Pathology: Assess Zero-shot Segmentation on Whole Slide Imaging
- 🍈Can SAM Segment Polyps?
0.前言
假如,我们有一个缺陷检测的任务(😭真的有)
一般方法分两种
| 方法 | 问题 |
|---|---|
| 图像处理+机器学习:图像采集,图像预处理,图像分析,缺陷检测,缺陷分类。图像分析一般包括图像降维,特征提取。基于形状,颜色,纹理,使用机器学习方法,例如贝叶斯,SVM,决策树,EM等进行分类 | 1️⃣ 耦合,图像采集过程依赖合适的稳定的光照环境,合适的工业相机参数,严重依赖图像质量。2️⃣只能解决已知缺陷特定缺陷,对于生产线上的各种未知可能不能提供任何预测。 |
| 深度学习: rnn系列 yolo系列 自编码 | 1️⃣数据收集与标注成本过于高昂2️⃣落地困难 |
一般缺陷检测都会存在问题(😭主要是我要面对的问题):
⭕️没有采集设备 ⭕️没有样本 ⭕️缺陷种类无法穷尽
咋整⁉️
SAM横空出世
Segment Anything Model的核心愿景:
减少对于特定任务的专业建模知识要求,减少训练计算需求,减少自己标注掩码的需求.也就是我不咋会,不咋标,不咋训,就把目标分出来,完美适配我的需求。
Segment Anything Model已经实现的功能:
⭐ SAM已经学会了物体的概念
⭐ 可以为图像或视频中的物体生成掩码,甚至是没遇见过的
⭐ 通用性很强,无论是水下照片还是细胞显微镜
1.SAM原论文
论文下载地址
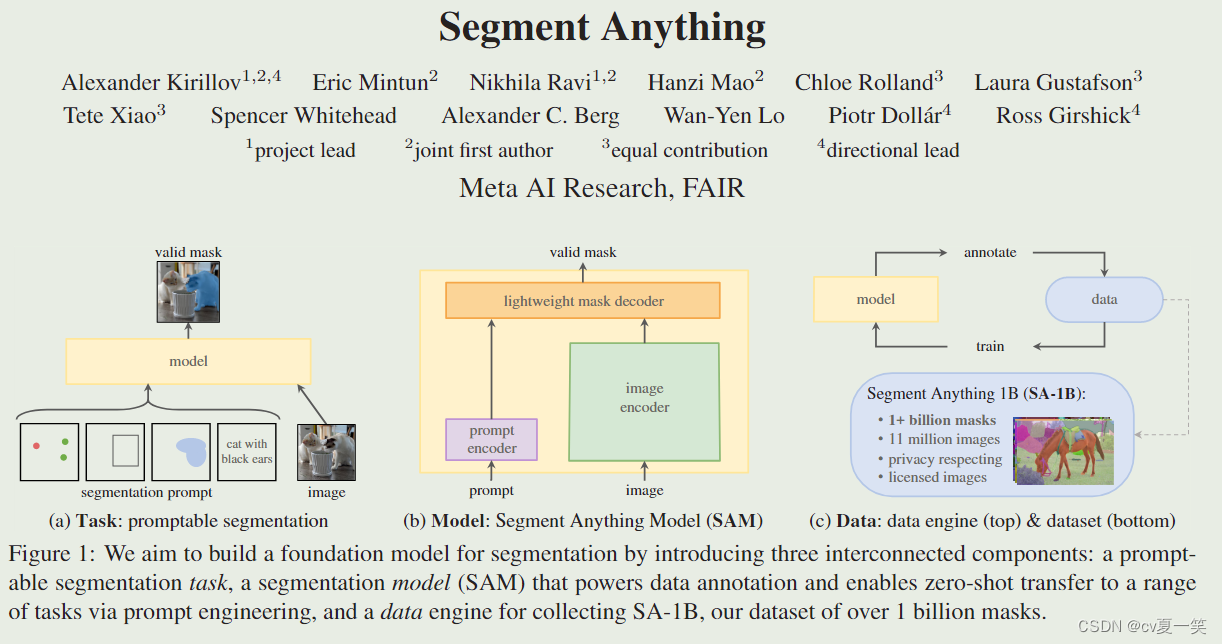
图片来自原文章
1️⃣名词:提示分割,分割一切模型,数据标注,零样本,分割一切模型的数据集
作者提出了一个cv方向的任务Task,启发与nlp的prompt机制,叫做提示性分割(promptable segmentation),实现这个任务的模型Model叫做分割一切模型(Segment Anything Model SAM),训练这个模型的数据集Data叫(SA-1B Segment Anything-1 Billion)。
SAM功能数据标注(data annotation),其他任务零样本迁移(zero-shot transfer)
2️⃣Introduction
摘自原文:Large language models pre-trained on web-scale datasets are revolutionizing NLP with strong zero-shot and few-shot generalization [10]. These “foundation models” [8] can generalize to tasks and data distributions beyond those seen during training. This capability is often implemented withprompt engineering in which hand-crafted text is used to prompt the language model to generate a valid textual response for the task at hand. When scaled and trained with abundant text corpora from the web, these models’ zero and few-shot performance compares surprisingly well to (even matching in some cases) fine-tuned models. Empirical trends show this behavior improving with model scale, dataset size, and total training compute.
🟨 模型规模,数据集,计算量影响着模型表现,所以要做大模型。
摘自原文: In this work, our goal is to build a foundation model for image segmentation. That is, we seek to develop a promptable model and pre-train it on a broad dataset using a task that enables powerful generalization. With this model, we aim to solve a range of downstream segmentation problems on new data distributions using prompt engineering.
🟨目的通过提示机制解决下游分割问题
3️⃣Task: promptable segmentation
摘自原文:
performing well at this task is challenging and requires specialized modeling and training loss choices
🟨损失函数选择的focal loss 和dice loss
downstream tasks can be solved by engineering appropriate prompts.For example, if one has a bounding box detector for cats, cat instance segmentation can be solved by providing the detector’s box output as a prompt to our model.
to perform instance segmentation, a promptable segmentation model is combined with an existing object detector.
🟨下游任务可以通过提示机制解决,例如,如果有一个猫的边界盒检测器,猫的实例分割可以通过提供检测器的盒子输出作为SAM的输入提示。(这里给出了使用SAM,二创SAM的思想)
🟨或者,为了进行实例分割,一个可提示的分割模型与现有的物体检测器相结合。
We anticipate that composable system design, powered by techniques such as prompt engineering, will enable a wider variety of applications than systems trained specifically for a fixed set of tasks.
🟨可组合的系统设计将比专门为固定任务集训练的系统实现更广泛的应用。(这里给出了SAM的意义,泛化)
4️⃣ Model: Segment Anything Model
摘自原文:The promptable segmentation task and the goal of real-world use impose constraints on the model architecture. In particular,the model must support flexible prompts, needs to compute masks in amortized real-time to allow interactive use, and must be ambiguity-aware.Surprisingly, we find that a simple design satisfies all three constraints: a powerful image encoder computes an image embedding, a prompt encoder embeds prompts, and then the two information sources are combined in a lightweight mask decoder that predicts segmentation masks. We refer to this model as the Segment Anything Model, or SAM (see Fig. 1b). By separating SAM into an image encoder and a fast prompt encoder / mask decoder, the same image embedding can be reused (and its cost amortized) with different prompts. Given an image embedding, the prompt encoder and mask decoder predict a mask from a prompt in ∼50ms in a web browser. We focus on point, box, and mask prompts, and also present initial results with free-form text prompts. To make SAM ambiguity-aware, we design it to predict multiple masks for a single prompt allowing SAM to naturally handle ambiguity, such as the shirt vs. person example.
🟨模型必须支持灵活提示,实时计算,交互使用,必须具有模糊性。
🟨图像编码器和提示编码器结合到轻量级解码器中
🟨相同的图像嵌入表示可以通过不同的提示重复使用(并摊销其成本)
🟨给定一个图像向量(也就是将图像embedding之后),提示编码器和掩码解码器可以在50毫秒内从网络浏览器的提示中预测出一个掩码
🟨点、框、掩码和文本的提示
🟨单个提示可以有多个掩码——SAM的模糊性。
5️⃣ Data: data engine & dataset
摘自原文: Data engine (§4). To achieve strong generalization to new data distributions, we found it necessary to train SAM on a large and diverse set of masks, beyond any segmentation dataset that already exists. While a typical approach for foundation models is to obtain data online [82], masks are not naturally abundant and thus we need an alternative strategy. Our solution is to build a “data engine”, i.e., we co-develop our model with model-in-the-loop dataset annotation (see Fig. 1c). Our data engine has three stages:assisted-manual, semi-automatic, and fully automatic. In the first stage, SAM assists annotators in annotating masks, similar to a classic interactive segmentation setup. In the second stage, SAM can automatically generate masks for a subset of objects by prompting it with likely object locations and annotators focus on annotating the remaining objects, helping increase mask diversity. In the final stage, we prompt SAM with a regular grid of foreground points, yielding on average ∼100 high-quality masks per image.Dataset (§5). Our final dataset, SA-1B, includes more than1B masks from 11M licensed and privacy-preserving images (see Fig. 2). SA-1B, collected fully automatically using the final stage of our data engine, has 400× more masks than any existing segmentation dataset [66, 44, 117, 60], and as we verify extensively, the masks are of high quality and diversity. Beyond its use in training SAM to be robust and general, we hope SA-1B becomes a valuable resource for research aiming to build new foundation models.
Responsible AI (§6). We study and report on potential fairness concerns and biases when using SA-1B and SAM. Images in SA-1B span a geographically and economically diverse set of countries and we found that SAM performs similarly across different groups of people. Together, we hope this will make our work more equitable for real-world use cases. We provide model and dataset cards in the appendix.
🟨SAM使用数据集进行训练,标注着使用SAM交互式注释图像,反过来更新SAM。属实是闭环成长了。
🟨使用这种方法,通过模型辅助注释者,半自动半注释,模型全自动分割掩码这三个等级,造就了SAM数据集SA-1B达到1100万张图像,超过10亿个有效的高质量掩码, 比现有的分割数据集多400多倍,比COCO完全手动基于多边形的掩码注释快6.5倍。
🟨SA-1B数据集不仅能获取的更快 更多 更方便,也 更平均,来自不同国家地区 不同收入
2.代码实战
1️⃣ 配环境
官方要求
python>=3.8, as well as pytorch>=1.7 and torchvision>=0.8.
2️⃣装包
pip install opencv-python pycocotools-windows matplotlib onnxruntime onnx
我的是,有的会用不到,不影响。
Package Version
----------------------- ---------
absl-py 1.4.0
beautifulsoup4 4.11.2
brotlipy 0.7.0
cachetools 5.3.0
certifi 2022.12.7
cffi 1.15.1
chardet 5.1.0
charset-normalizer 3.0.1
click 8.1.3
colorama 0.4.6
coloredlogs 15.0.1
cryptography 38.0.4
cycler 0.11.0
Cython 0.29.34
filelock 3.9.0
Flask 2.2.3
flatbuffers 23.3.3
flit_core 3.6.0
gdown 4.6.3
google-auth 2.16.1
google-auth-oauthlib 0.4.6
grpcio 1.51.1
humanfriendly 10.0
idna 3.4
imageio 2.25.1
importlib-metadata 6.0.0
itk 5.3.0
itk-core 5.3.0
itk-filtering 5.3.0
itk-io 5.3.0
itk-numerics 5.3.0
itk-registration 5.3.0
itk-segmentation 5.3.0
itsdangerous 2.1.2
Jinja2 3.1.2
kiwisolver 1.4.4
Markdown 3.4.1
MarkupSafe 2.1.2
matplotlib 3.2.1
mkl-fft 1.3.1
mkl-random 1.2.2
mkl-service 2.4.0
monai 1.1.0
mpmath 1.3.0
networkx 3.0
nibabel 5.0.1
numpy 1.23.5
oauthlib 3.2.2
onnx 1.13.1
onnxruntime 1.14.1
opencv-python 4.7.0.68
packaging 23.0
pandas 1.5.3
Pillow 9.3.0
pip 22.3.1
protobuf 3.20.3
psutil 5.9.4
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycocotools-windows 2.0.0.2
pycparser 2.21
pyOpenSSL 22.0.0
pyparsing 3.0.9
pyreadline3 3.4.1
PySocks 1.7.1
python-dateutil 2.8.2
pytorch-ignite 0.4.2
pytz 2022.7.1
PyWavelets 1.4.1
PyYAML 6.0
requests 2.28.2
requests-oauthlib 1.3.1
rsa 4.9
scikit-image 0.19.3
scipy 1.10.0
seaborn 0.12.2
segment-anything 1.0
setuptools 65.6.3
SimpleITK 2.2.1
six 1.16.0
soupsieve 2.4
sympy 1.11.1
tensorboard 2.12.0
tensorboard-data-server 0.7.0
tensorboard-plugin-wit 1.8.1
tifffile 2023.2.3
torch 1.13.1
torchaudio 0.13.1
torchvision 0.14.1
tqdm 4.64.1
typing_extensions 4.4.0
urllib3 1.26.14
Werkzeug 2.2.3
wheel 0.37.1
win-inet-pton 1.1.0
wincertstore 0.2
zipp 3.14.0
3️⃣下载权重版本
我用的vit_l, 即使是l,精确度完全可以接受,很不错的,记住下载路径一会填写代码里面
- default or vit_h: ViT-H SAM model.
- vit_l: ViT-L SAM model.
- vit_b: ViT-B SAM model.
预训练模型下载地址
4️⃣代码
import numpy as np
import cv2 as cv2
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
# 权重路径
sam = sam_model_registry["vit_l"](checkpoint="./sam_vit_l_0b3195.pth")
mask_generator = SamAutomaticMaskGenerator(sam)
image = cv2.imread("./11.png")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
masks = mask_generator.generate(image)
# 这里只取了第一个掩码,他会返回一个列表,“不同于nlp返回一个结果,sam会返回多个近似值”
mask = (masks[1]["segmentation"] * 255.0).astype(np.uint8)
mask = np.array(mask)
print(mask)
print(mask.shape())
print(image.shape())
cv2.namedWindow("image", cv2.WINDOW_NORMAL)
cv2.namedWindow("mask", cv2.WINDOW_NORMAL)
cv2.imshow("image", image)
cv2.imshow("mask", mask)
cv2.imwrite("C://Users//rg16x//Desktop//seg_result/11.png", mask)
cv2.waitKey(0)
masks输出是一个列表包含多个掩码及每个掩码的信息,我们这里只取到seg掩码
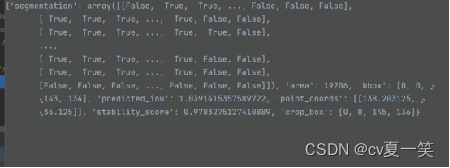
5️⃣会有报错
问题不大 留言吧。
3.SAM相关论文
🍏Segmenting anything also Detect anything
原文下载地址❗❗❗ 本篇为预印本,预印本文章尚未经过同行评审,因此可能存在错误或不完整的信息,仅供个人学术研究和交流使用,不应用于商业用途,预印本文章可能会在最终发表时进行修改和修订。

左为原图,中为SAM分割图,右为检测框图。Segmenting anything also Detect anything 是将SAM嵌入到目标检测任务中,当做目标检测的下游模型,以SAM分割的高细粒度结果指导目标检测中低细粒度的边界框的生成,也就是,SAM分出所有的鱼,🐋🐬🐟🐠🐡🐙🐟 ,这叫高细粒度,而检测模型更细致,只要求检测分红小章鱼🐙,这叫低细粒度,进而言,先检测到所有鱼,再在其中检测粉红小章鱼,会更准确。
补充粒度,粗粒度,细粒度,高细粒度,低细粒度概念:
粒度是用来描述数据的分类、分组、汇总等的精细程度或抽象程度。数据的粒度越细,表示对数据的处理越详细、精细,可以得到更加细致的信息。
高粒度和低粒度是相对的概念。高粒度通常表示将任务或问题分解为更细微的部分,以获得更多的细节和信息。例如,在图像分类任务中,将图像分解为更小的图像块或像素,则具有更高的粒度,因为它提供了更多的细节信息。低粒度表示将任务或问题分解为更大的部分,以获得更高的效率和适用于大规模问题。例如,在图像分类任务中,将图像分解为更大的图像区域,则具有更低的粒度,因为它提供了更少的细节信息,但可以更快地处理大量的图像数据。
高细粒度指的是对物体进行相对宏观的分类,通常只需要关注物体的一些基本特征,如整体形状、大小等。举个例子,对于犬类和猫类的分类问题,相对于鸟类分类来说就属于低细粒度分类,因为犬类和猫类在外观上相对容易区分,不需要非常细致的观察和分析就能进行分类。
低细粒度指的是对物体进行更加细致、准确的分类,通常需要关注物体的细节特征,如颜色、形态等。举个例子,细粒度分类问题中的鸟类分类就属于高细粒度分类,因为鸟类的种类相对较多,而且很多种鸟在外观上非常相似,因此需要非常细致的观察和分析才能准确分类。
Segmenting anything also Detect anything的贡献点有三
摘自原文:1. To improve the accuracy of object detection annotation bounding box generation, we suggest utilizing a pixel-level classification model named SAM as a guide. 2. We propose high fine grain fill-in augmentation (HFGFA) using SAM, which reduces image augmentation information redundancy, resolves data imbalance and small object problems. 3. We propose to use SAM to guide the development of the open world object detection (OWOD) task, breaking the closed world assumption
- 用SAM作分类模型指导检测任务:对应上面示例图就是先用SAM高维度检测所有鱼,再用检测模型精确检测紫色大丑鱼。
- 高细粒度填充增强数据,减少了图像增强信息的冗余,解决了数据不平衡和小对象问题:就是将SAM抠出来的掩码和随机一张背景结合成新图像,增加了训练数据集的多样性和复杂性,并提高了模型的通用性和性能。
- 应用于开放世界。开放世界:在没有明确监督的情况下识别未知实例,在不忘记先前实例的情况下升级知识。
写不完,根本写不完,先到这吧,后面




![[架构之路-190]-《软考-系统分析师》-4-据通信与计算机网络-5-图解CRC计算方法与步骤](https://img-blog.csdnimg.cn/6da120259ec7433581c7e7a634f21c8f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcXFfNTI1MTQ3NTA=,size_20,color_FFFFFF,t_70,g_se,x_16#pic_center)