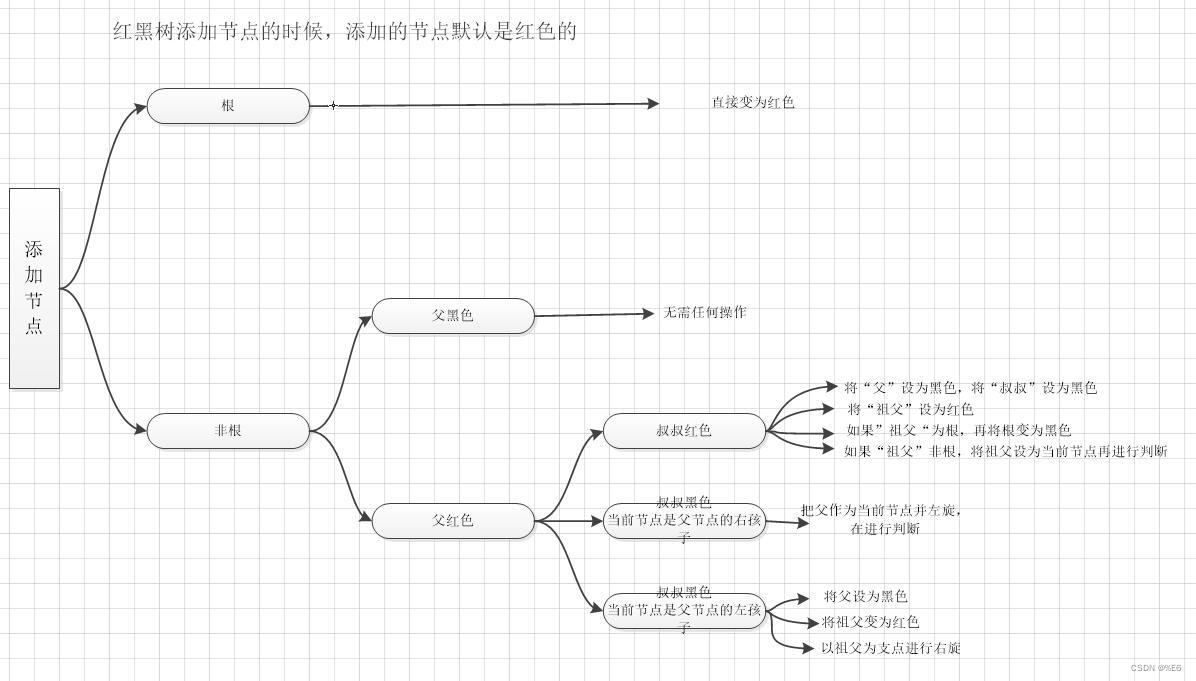
未来已来,大模型依据压缩模型的方式,可以在普通的PC上运行.
LLaMA
Facebook的LLaMA 模型和Georgi Gerganov 的llama.cpp的结合。 LLaMA,这是一组包含 7B 到 65B 参数的基础语言模型。我们在数万亿个令牌上训练我们的模型,并表明可以仅使用公开可用的数据集来训练最先进的模型,而无需诉诸专有和不可访问的数据集。特别是,LLaMA-13B 在大多数基准测试中都优于 GPT-3 (175B),而 LLaMA-65B 可与最佳模型 Chinchilla-70B 和 PaLM-540B 竞争。我们将所有模型发布给研究社区。
论文
4位量化是一种减小模型大小的技术,因此它们可以在功能较弱的硬件上运行。它还减少了磁盘上的模型大小——7B 模型减少到 4GB,13B 模型减少到不到 8GB。 它完全有效!今晚我用它在我的笔记本电脑上运行 7B LLaMA 模型,然后今天早上升级到 13B 模型——Facebook 声称可以与 GPT-3 竞争的模型。
论文地址:Large language models are having their Stable Diffusion moment right now.
步骤
1.下载模型: 1) 种子下载方式 2) 签署的方式
搭建步骤
$ git clone https://github.com/ggerganov/llama.cpp
$ cd llama.cpp
$ docker pull ubuntu
$ sudo docker run -it -d -v ~/Desktop:/workspace --name llama imageid
$ sudo docker exec -it llama bash
$ apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev libsqlite3-dev wget libbz2-dev cmake python3.10 vim gcc
$ apt install cmake python3.10 vim gcc python3-pip
# 下载模型 7B model/13B model/30B model/ 65B model bittorrennt(种子)
aria2c --select-file 21-23,25,26 'magnet:?xt=urn:btih:b8287ebfa04f879b048d4d4404108cf3e8014352&dn=LLaMA'
下载到models路径下
$ ls ./models
13B
30B
65B
7B
llama.sh
tokenizer.model
tokenizer_checklist.chk
$ pip3 install torch numpy sentencepiece -i https://pypi.tuna.tsinghua.edu.cn/simple
$ python convert-pth-to-ggml.py models/7B/ 1
$ make
$ ./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin 2
$ ./quantize ./models/13B/ggml-model-f16.bin ./models/13B/ggml-model-q4_0.bin 2
# 这将生成型号/7B/ggml-model-q4_0.bin-3.9GB文件。这是我们将用于运行模型的文件。
运行7B模型
# 创建了ggml-model-q4_0.bin文件后,我们现在可以运行该模型了。
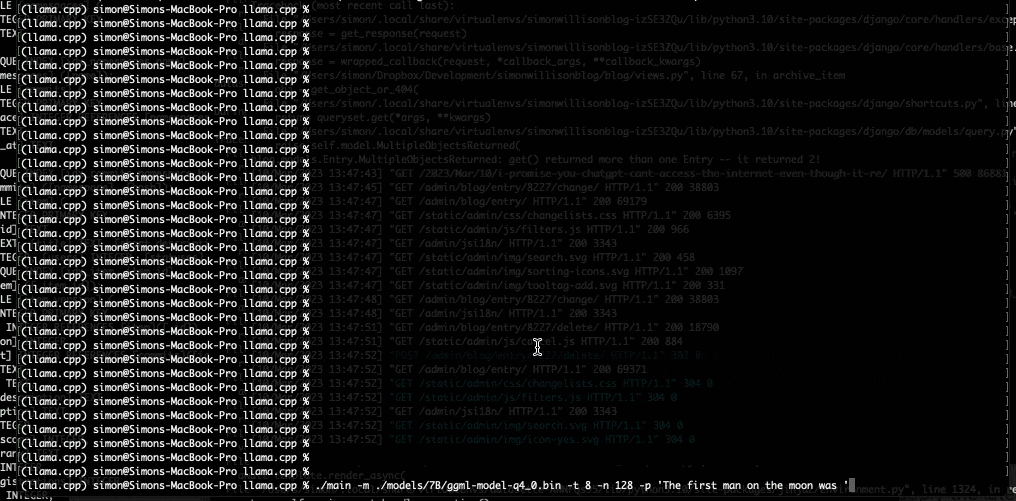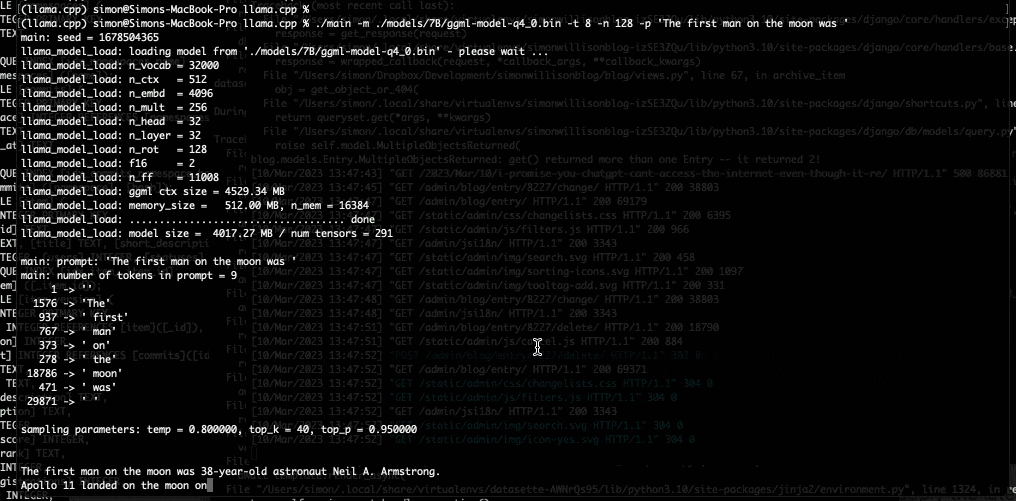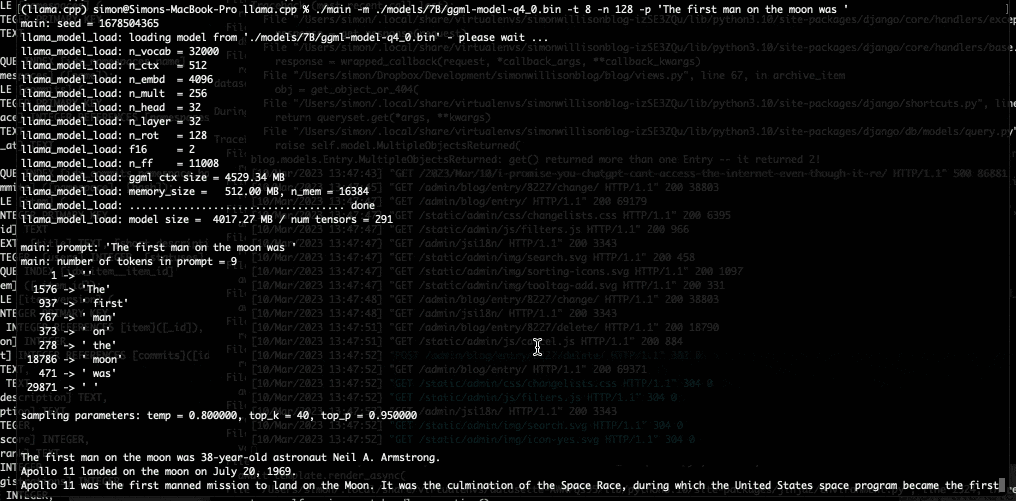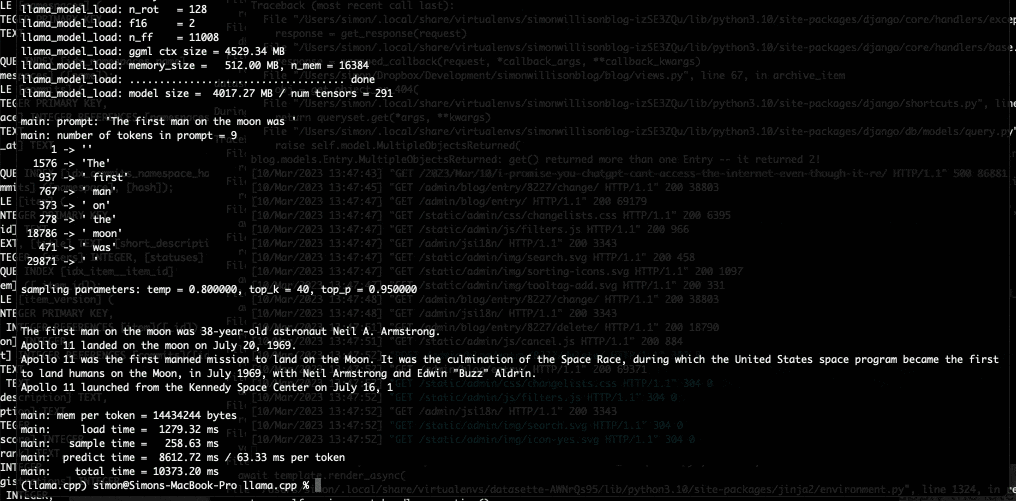
$ ./main -m ./models/7B/ggml-model-q4_0.bin \
-t 8 \
-n 128 \
-p 'The first man on the moon was '
# ./main --help shows the options. -m is the model. -t is the number of threads to use. -n is the number of tokens to generate. -p is the prompt.
$ usage: ./main [options]
options:
-h, --help show this help message and exit
-s SEED, --seed SEED RNG seed (default: -1)
-t N, --threads N number of threads to use during computation (default: 4)
-p PROMPT, --prompt PROMPT
prompt to start generation with (default: random)
-n N, --n_predict N number of tokens to predict (default: 128)
--top_k N top-k sampling (default: 40)
--top_p N top-p sampling (default: 0.9)
--temp N temperature (default: 0.8)
-b N, --batch_size N batch size for prompt processing (default: 8)
-m FNAME, --model FNAME
model path (default: models/llama-7B/ggml-model.bin)
我的第一个提示是第一个登上月球的人是-我得到了这个:
-p 'def open_and_return_content(filename):'
def open_and_return_content(filename):
"""
Opens file (returning the content) and performs basic sanity checks
"""
if os.path.isfile(filename):
with open(filename) as f:
content = f.read()
return content
else:
print('WARNING: file "{}" does not exist'.format(filename), file=sys.stderr)
return ''
def get_file_info(filename, fullpath):
"""
Get file information (i.e., permission, owner, group, size)
"""
运行13B模型
参考建议运行13B没那么简单. 在运行任何转换之前,13B文件夹包含以下文件:
154B checklist.chk
12G consolidated.00.pth
12G consolidated.01.pth
101B params.json
转化脚本
$ convert-pth-to-ggml.py models/13B/ 1
12G ggml-model-f16.bin
12G ggml-model-f16.bin.1
$ ./quantize ./models/13B/ggml-model-f16.bin ./models/13B/ggml-model-q4_0.bin 2
$ ./quantize ./models/13B/ggml-model-f16.bin.1 ./models/13B/ggml-model-q4_0.bin.1 2
Then to run a prompt:
./main \
-m ./models/13B/ggml-model-q4_0.bin \
-t 8 \
-n 128 \
-p 'Some good pun names for a coffee shop run by beavers:-'
结果如下: Some good pun names for a coffee shop run by beavers:
- Beaver & Cat Coffee
- Beaver & Friends Coffee
- Beaver & Tail Coffee
- Beavers Beaver Coffee
- Beavers Are Friends Coffee
- Beavers Are Friends But They Are Not Friends With Cat Coffee
- Bear Coffee
- Beaver Beaver
- Beaver Beaver's Beaver
- Beaver Beaver Beaver
- Beaver Beaver Beaver
- Beaver Beaver Beaver Beaver
- Beaver Beaver Beaver Beaver
- Be
部署参考
- Georgi 是保加利亚索非亚的一名开源开发人员(根据他的 GitHub 个人资料)。他之前发布了whisper.cpp,这是 OpenAI 的 Whisper 自动语音识别模型到 C++ 的端口。该项目使 Whisper 适用于大量新用例。其他模型实例
-
教程:Large language models are having their Stable Diffusion moment
-
LLaMA FAQ
-
llama英文教程1
- llama英文教程2