1. 简介
收集数据的能力不断增强,使我们有可能收集大量的异构数据。在可用的异构数据中,时间序列代表着尚未被充分探索的信息母体。当前的数据挖掘技术在分析时间序列时存在多个缺点,尤其是在应同时分析多个时间序列(即多维时间序列)以从数据中提取知识时。
2. K-MDTSC和k-Shape
论文: https://www.mdpi.com/2079-9292/10/10/1166
2.1 K-Means
K-means是一种从统计学中诞生的经典聚类算法。它创建基于中心的集群,例如集群中的点更接近(因此更相似)它们所属的集群的质心(即集群的中心),而不是其他集群的质心。在k -means中,用户指定一个参数k,表示所需集群的数量。然后,从输入点开始,k -means将它们分组到k个簇中,将它们分配到最近的质心。然后,它返回每个群集和各自的质心。
首先,k -means在输入数据空间中随机抽取k个点,并将其作为聚类的初始质心。然后将所有输入点分配到与各自质心距离最短(通常为欧氏距离)的聚类中。一旦K-means将所有点分配到一个集群中,新的质心将被计算出来并与之前的质心进行比较。如果质心不变,算法将停止并返回生成的聚类和质心。否则,算法将重新启动,根据新的质心将所有点重新分配到集群。虽然传统的K-means代表了一种简单而高效的将点分组的算法,但它在距离定义方面有一些众所周知的局限性和一些众所周知的关键问题,如创建空簇。最重要的是,K-means不容易处理时间序列。
2.2 k-Shape
k-Shape是一种基于K-means的时间序列聚类算法。为了处理时间序列,k-Shape采用基于形状的距离来评估两条曲线之间的相似度。此外,基于形状的距离使用互相相关距离来识别两条曲线之间的最小距离,即使它们没有正确对齐。为此,它首先移动其中的一个,以确定到最小距离的最佳对齐。然后,为了处理时间序列固有的扭曲,k-Shape使用了一个z归一化过程。k-Shape通过用单个序列的自相关的几何平均值归一化互相关距离来计算基于形状的距离。
虽然k-Shape可以识别时间序列簇,即使它们没有对齐,但它本身不能处理多维时间序列。实际上,k-Shape只得到一维时间序列的输入。在这里,我们将其调整为多维时间序列,以应对这种约束。
已知多维时间序列XN(z),其中N表示维数,我们将X(z)定义为一维时间序列,将所有维数连接如下:
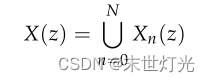
最后,我们将X(z)时间序列作为k-Shape的输入。
2.3 K-MDTSC
我们将K-MDTSC基于传统的K-means算法。首先,我们定义了一个广义的距离概念来处理时间序列,特别是多维时间序列。
给定一对多维时间序列XN(z)和YN(z),其中z表示z个样本中的样本,N表示维数,我们定义广义距离如下:
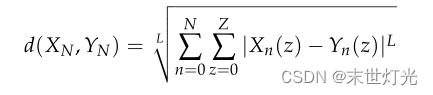
其中L表示公制距离。对于我们的实现,我们依赖于L = 2,即欧氏距离。我们使用距离d(.)在Kmeans算法中找到最近的质心。注意,我们的广义距离假设XN(z)和YN(z)是同步的多维时间序列。
3. 其他方法
论文:A multivariate time series clustering approach for crime trends prediction | IEEE Conference Publication | IEEE Xplore
利用单维时间序列的聚类思想,给多维时间序列的各个维度赋予特定的权值,每个行向量作为一个时间点。由于MTS样本长度不等,样本之间的相似度使用动态时间弯曲(Dynamic Time Warping, DTW)度量,最佳匹配路径上每一对时间点的多维向量之间的距离利用闵可夫斯基参数模型计算。该算法需要领域知识为各个变量赋予权值,且DTW距离度量方法的计算量较大。
论文:基于变量相关性的多元时间序列特征表示 - 中国知网
提出基于变量相关性的MTS特征表示方法,通过协方差反映系统中各个参数的相关关系,将MTS样本转化为协方差矩阵;MTS集所有的协方差矩阵拼接为综合协方差矩阵,对该协方差矩阵进行主成分分析得到各MTS的特征矩阵。该方法可以将数值型不等长MTS数据集转变为大小相同的特征矩阵集合,处理结果可用于聚类分析。
论文:Interaction-Based Clustering of Multivariate Time Series | Proceedings of the 2009 Ninth IEEE International Conference on Data Mining
提出了一种基于参数交互关系的MTS聚类方法,指出MTS中的任一维变量都可以被其他解释变量近似线性组合表示,且将一维线性关系纳入了考虑范畴,假定这些变量间的线性相关关系可以用来进行聚类,其不足之处在于模型计算时间会随着样本数量变大而增加,也不能处理非数值型变量。
论文:Structure-Based Statistical Features and Multivariate Time Series Clustering | IEEE Conference Publication | IEEE Xplore
将每一维时间序列转化为一个统计特征数组,MTS样本由各维变量统计特征数组拼接成的向量来表示。该算法可以处理不等长时间序列,但要求各维选取的统计特征必须一致导致其在处理混合型MTS数据集时会遇到困难。
论文:https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/el.2016.0701
针对MTS数据集存在的样本之间不等长、数据类型多样和噪声等问题,提出了一种基于协方差矩阵与测地线距离(geodesic-based distance)的MTS聚类算法。该算法首先将MTS样本转化为协方差矩阵;然后将协方差矩阵从黎曼空间映射到欧氏空间;最后对矩阵集进行聚类。如果使用基于距离的聚类算法,上述映射过程可以省略,协方差矩阵之间的距离度量方法使用测地线距离。
论文:https://www.researchgate.net/publication/273063437_A_Model-Based_Multivariate_Time_Series_Clustering_Algorithm
提出了一种基于模型的多维时间序列聚类算法——MUTSCA〈LR〉(Multivariate Time Series Clustering Algorithm 〈Lift Ratio〉),该聚类算法假设目标数据集由一系列概率分布模型系统生成,不同的系统将生成相异的多维时间序列。该算法先将连续型数值符号化;然后在符号化样本上计算由LR(Lift Ratio)向量表示的时序模式,将时序模式累加生成用来表示MTS样本的模型向量;最后对模型向量集进行聚类。它不需要特定的领域知识,同时可以处理包含数值和非数值型变量的混合型MTS数据集。


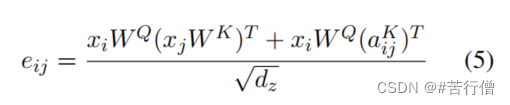
![[附源码]计算机毕业设计JAVA小超市进销存管理系统](https://img-blog.csdnimg.cn/aa29b8e1bd3044b1ba62320d4533be9c.png)