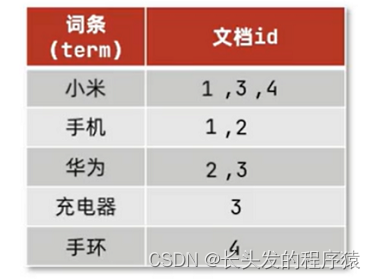
#01
QueryCoord 组件介绍

QueryCoord 是 Milvus 中查询集群的中心调度节点,在用户将一个 Collection Load 到内存中时,QueryCoord 负责将该 Collection 的 Segment 调度到 QueryNode 集群中,以支持后续的查询。
QueryCoord 最核心的操作有4种:
-
Load:将资源加载到 QueryNode 中
-
Release:将资源从 QueryNode 释放
-
Handoff:使用新的 Segment C 替换旧的 Segment A,B
-
Balance:在 QueryNodes 之间移动 Segment
此外,在 Milvus v2.1.0 我们加入了内存多副本的功能,通过增加 Segment 在内存中的副本数量来提升性能,提高可用性。
#02
为什么必须重构
在 Milvus v2.1.x 中,我们遇到了很多与 QueryCoord 相关的问题,其中不少问题无法在现有的设计上彻底解决,也有不少问题由于此前的设计耦合,在修复时很容易引入其它问题。 此前,有两类问题是最为常见,也最为棘手的:
-
QueryCoord 在某个操作之后长时间无响应
-
QueryCoord 有时无法通过重启恢复服务
我们在 Milvus v2.1.x 的开发过程中花费了大量的时间去解决无响应相关的问题。这个问题并不只是代码的问题,从根本来说是 QueryCoord 试图提供的接口语义过于强大,以至于根本无法简单实现我们期望的语义。
根本原因
此前的 QueryCoord,试图为每一个接口都提供最终完成的语义,只要请求到达 QueryCoord,即使后续出现错误,QueryCoord 也会试图最终将这些请求完成。
此外,QueryCoord 会记录每个 Segment 所处的节点位置,并将这一信息持久化。当发生 Balance 之类的操作时,根据 RPC 是否成功来决定是否要修改记录的位置信息。
我们很快意识到这一做法是无法做到准确的,因为 RPC 会有 false failure,QueryCoord 主动跟踪资源位置,并以 RPC 结果作为资源位置变化的依据,是必定会发生资源泄漏的。
为了达成这种最终完成的语义,QueryCoord 选择实现了一个完全串行的 scheduler,将每一种请求视作一类 task,可以认为这个 task scheduler 就是一个 WAL applier,而请求就是 WAL 中的 record,QueryCoord 会将所有 task 持久化,并在重启时重放这些 task。
这一套机制像由若干小齿轮连接起来的精密器件,容错率是很低的:
-
由于完全串行执行,当某一个请求无法执行,或执行慢时,后续的所有请求都会被阻塞
-
由于持久化了所有的 task,一个无法完成的请求会持续阻塞整个系统,即使重启也无法恢复
-
一个有副作用的请求失败时(如 Load),无法保证接口的原子性
以 Load 请求为例,如果在 Load 了部分 Segment 后,请求无法继续执行。
在这一套机制下就无法做出正确的处理。如果多次重试,则会让后续请求的阻塞更长时间;如果直接丢弃请求,则可能无法释放已经 Load 成功的 Segment。
#03
重构思路
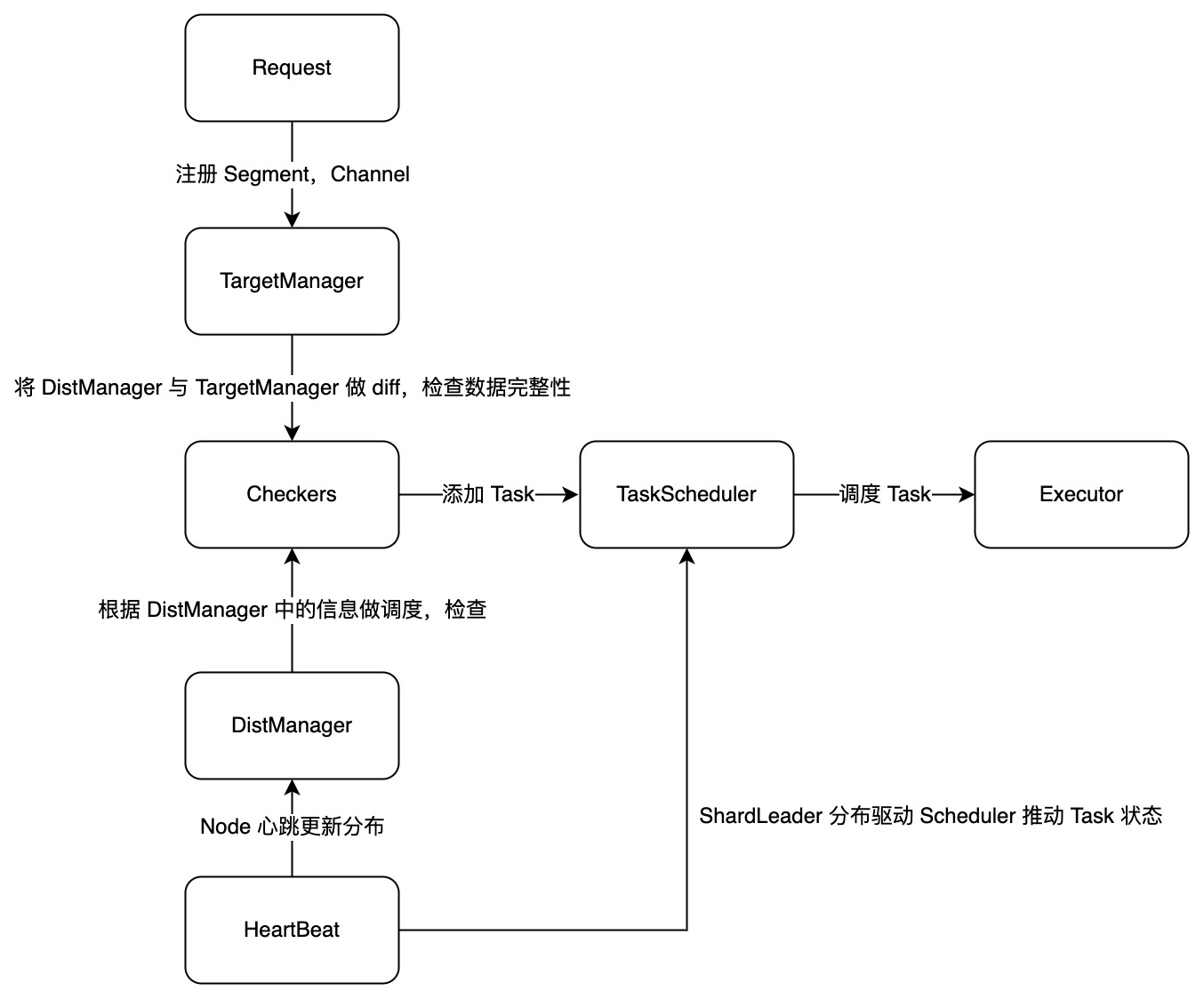
QueryCoord 的本质是一个资源调度中心,我们需要把 Segment 和 Channel 调度到 QueryNode 集群中来支持查询。
同时也要很好的支持内存多副本,在副本数量与预设值不同时能进行相应的上下线操作。新的 QueryCoord 设计参考了 Placement Driver[1] 等业内成熟系统,我们有一些基本的出发点:
-
QueryCoord 必须感知真实的资源分布情况
-
资源上下线操作是否完成不能以 RPC 是否成功作为判断条件
-
启动时依赖的持久化信息需要尽量少
-
需要一个组件不断根据分布对资源进行上下线调整
从这些点出发,重构后的 QueryCoord 作出了下面的调整:
心跳机制
依赖 RPC 的成功与否去判断资源的上下线是否成功是不可行的,RPC 存在 false failure,因此可能会导致资源泄露。
集群中资源的分布情况,最真实的来源就是节点本身报告自己持有哪些资源,因此必须加入一套心跳机制,在 QueryCoord 与 QueryNode 之间同步资源分布情况。
在加入心跳机制后,QueryCoord 不再去持久化资源的分布信息,而是在启动时询问所有的 QueryNode 来恢复出分布信息,这样可以避免脏数据对重启带来影响。
同时,依赖心跳汇报的资源分布信息来判断资源的上下线是否完成,是最准确的,在 Balance 这个操作中,我们需要对一个 Segment 进行先上后下,以保证 Balance 过程中不会影响服务的可用性,通过心跳机制,我们可以准确地判断上线操作是否真的已经完成,来决定是否进行下线操作。
抛弃最终完成语义
从系统自身的角度来看,最终完成语义是很难保证的,这一性质要求持久化所有请求,并在重启后进行重放。一些请求并不能保证总是可执行的,例如一个加载 Segment 的请求,可能在重启后这个 Segment 已经被 Compact,从而无法加载。
从用户的角度来看,当服务不可用时,用户通常期望可以通过重启去清理掉一些脏数据,让服务能够重新工作。抛弃最终完成的语义之后,QueryCoord 只对接口提供原子性保证,不再持久化请求,避免恢复时被一些无法完成的请求阻塞。
在做出上面的修改后,我们也不再需要一个全局串行的 scheduler,而是将请求的并发粒度降低到了 Collection 级别,并且需要进入 scheduler 的请求只有 Load/Release 两类。可以极大提高 QueryCoord 的响应速度。
资源分布检查
在一个分布式的环境中,任何网络请求都有失败的可能。一个对一批资源进行处理的请求甚至可能是部分成功的,我们希望系统具有更高的容错率,在任何情况下都有能够将资源副本数量调整到预设值的能力。
因此在新的 QueryCoord 中,我们加入了若干的资源检查器(Checker):
-
Balance Checker:检查集群的负载情况,并作出适当的资源调整,平衡集群负载
-
Channel Checker:检查集群中各个 Channel 的分布情况,保证 Channel 的副本数量不多不少
-
Segment Checker:检查集群中各个 Segment 的分布情况,保证 Segment 的副本数量不多不少
在 Release 的情况下,检查器能够保证即使在 Release 实现存在 Bug 的情况下,也可以把泄露的资源释放掉。
#04
资源调度系统的设计感悟
得益于 Milvus 的架构设计,在这次重构中我们几乎重写了整个 QueryCoord,但依然能够无缝的替换掉原来的 QueryCoord。在新的 QueryCoord 上线后,Milvus 系统:
-
Query 集群更加健壮,稳定
-
彻底解决 Load/Release 等请求无响应的问题
-
保证了 Query 相关服务在重启后能够恢复
-
QueryCoord 更加容易维护,排查问题更加容易
而我个人也从这次重构中收获良多,在资源调度系统的设计上,与代码实现上获得了许多感悟:
-
分布信息作为调度的输入,必须是真实的,也就是各节点上报的信息汇总
-
简单,清晰的语义比看上去强大的复杂语义更强大, 简单粗暴往往意味着高容错
-
原子性是一个非常有力的性质,系统在各类操作有了原子性保证后会更容易维护,在并发的情况下,为了保证原子性有时需要很小心
在 QueryCoord 的后续演进中,我们会继续强化 QueryCoord 的可用性与 Query 集群的性能。
参考资料
[1]
Placement Driver: https://docs.pingcap.com/tidb/stable/tidb-architecture#placement-driver-pd-server



![[MAUI] 开篇-初识MAUI](https://img-blog.csdnimg.cn/339276249a30429fa909b447ccf5e3d7.png)