文章目录
- 常见编码的比较,各个编码中各字符占用(字节数):
- 简体中文编码发展史,编码出现时间和涵盖范围
- UTF-8、unicode与GBK编码转化
- 一问一答
- 其他
- ASCII表
- 参考文档
常见编码的比较,各个编码中各字符占用(字节数):
| 编码 | 英文 | 中文(简体) | 中文(繁体) |
|---|---|---|---|
| ASCII | 1 | 不支持 | 不支持 |
| Unicode | 4 | 4 | 4 |
| UTF-8 | 1 | 3 | 3 |
| UTF-16 | 2 | 4 | 4 |
| UTF-32 | 4 | 4 | 4 |
| GB2312 | 1 | 2 | 不支持 |
| BIG5 | 1 | 不支持 | 2 |
| GBK | 1 | 2 | 2 |
| GB18030 | 1 | 2 | 2 |
| 150-8859-1 | 1 | 不支持 | 不支持 |
- 比如UTF-32 编码,英文,中文长度相同。说明这种编码为等长度编码,优点是解码速度快,缺点是浪费存储空间。
- UTF-8 是可变编码,涵盖了所有的Unicode字符,所以UTF-8存储某些编码的时候需要4个字节。UTF-8 完全兼容ASCII编码,UTF-32是不兼容的,因为UTF-8表示ASCII只需要一个字节。
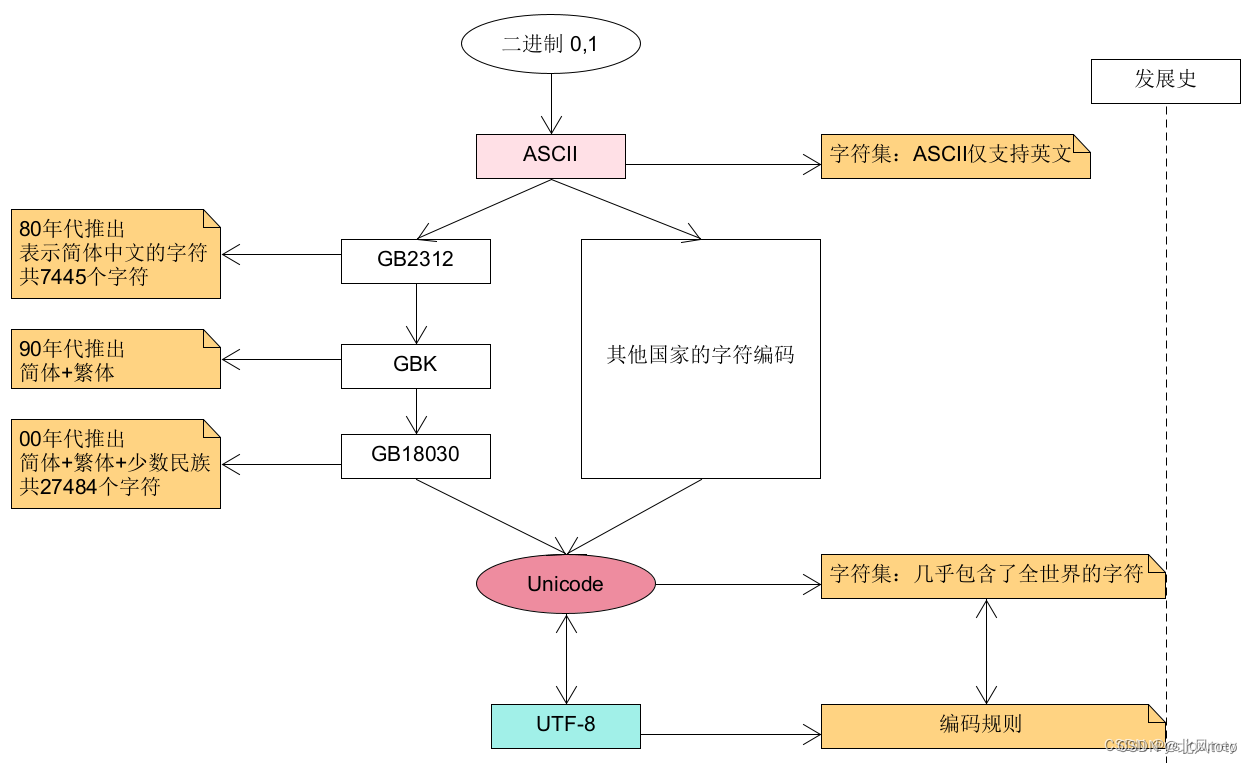
简体中文编码发展史,编码出现时间和涵盖范围
UTF-8、unicode与GBK编码转化
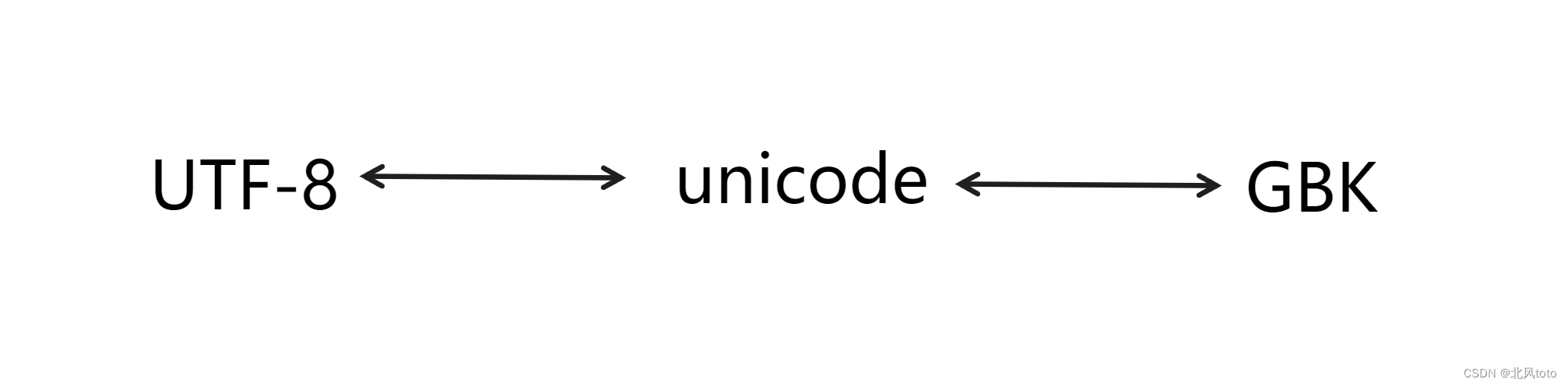
- unicode是一个编码规范,并不是一个编码实现方式(不理解这句话的可以看看后面的详细解释)
- UTF-8 和 GBK 编码通过unicode规范进行转换
- UTF-8涵盖了所有unicode字符,但是GBK 只考虑中文,在unicode中的一小部分的字符的编码。因为编码范围不同,所以如果UTF-8使用了GBK范围之外的编码必定会产生乱码。
一问一答
1. Unicode占几个字符?
Unicode是一个编码规范,并不是计算机内的一个具体的编码。ASCII编码也是编码规范,并不是计算机中具体的编码方式。Unicode 编码是一个二进制字符集,其只规定了字符的二进制代码,却没有规定这些二进制代码应该如何存储。
2. 什么是编码规范?
这里作者用口语化方式给大家解释解释,比如65代表’A’,但是在不同的编码中二进制的值是一样的,但是长度未必一样。比如二进制 “01000001” 和 “000001000001” 都是表示65,但是第二个二进制前面多了4个0,就是这种区别代表了编码实现方式。
3. utf-8和Unicode的关系
utf-8编码是基于Unicode标准实现的
4. 基于Unicode标准实现的编码一定容纳了所有Unicode规范的字符么?
不一定,Unicode是规范了世界上所有存在的文字符号,但是编码具体实现的过程之中,可能并不会实现所有的文字符号,这样的好处是可以节省存储空间和计算速度。比如编码可以之实现0~127的编码,那么编码就可以直接使用1个字节的空间存储就够了。
5. UTF-8的值可以直接对应Unicode的值么?
不行,需要算法转换
6. UTF-32的值可以直接对应Unicode的值么?
可以,所以效率贼高。这也是为什么UTF-32也被大量应用
其他
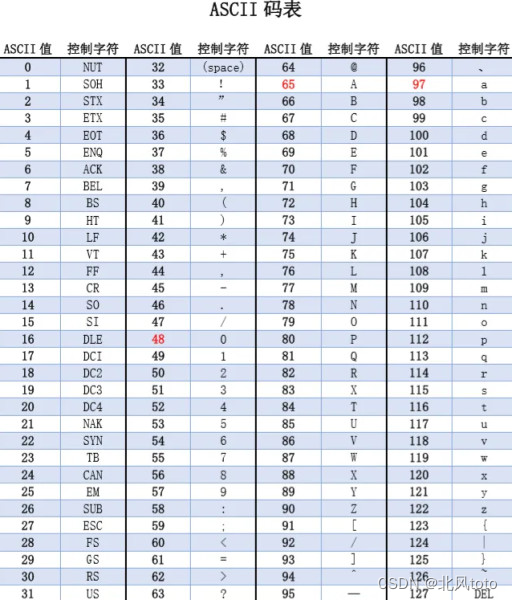
ASCII表
参考文档
- 各种字符编码详解【图文教程】
- 一文读懂字符编码ASCII、Unicode与UTF-8
- Unicode 和 UTF-8 详解
- Unicode编码详解(四):UTF-16编码




![[C++基础]-类和对象(下)](https://img-blog.csdnimg.cn/e5d6a950e31b44a3a5d3b90c2853fd4c.png)